NavWM: A Unified Navigation World Model for Foresight-Driven Planning
Pith reviewed 2026-06-26 00:40 UTC · model grok-4.3
The pith
NavWM unifies perception, generation and control into one world model that uses visual foresight for closed-loop navigation planning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
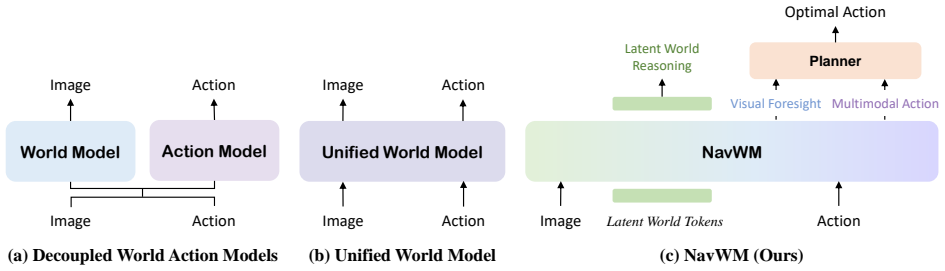
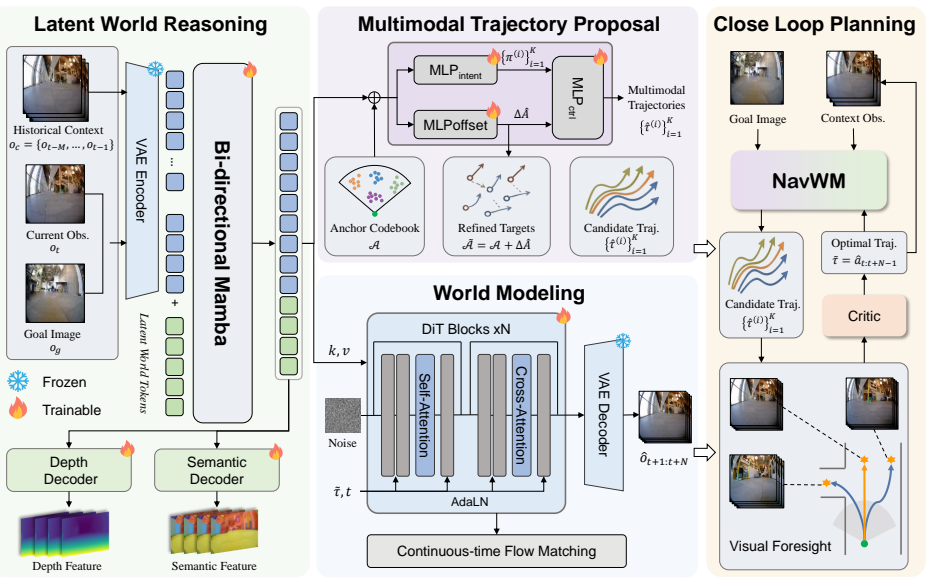
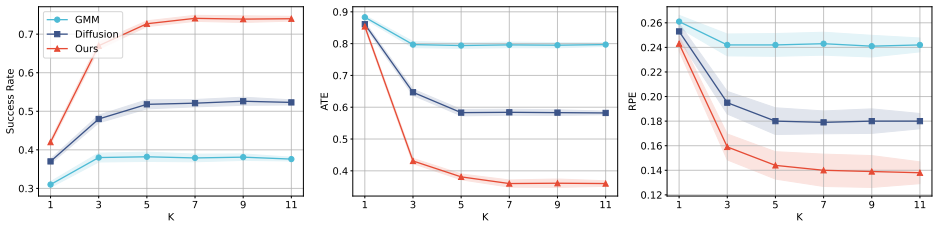
NavWM is a unified navigation world model that integrates latent world reasoning, multimodal action prediction and controllable visual generation. It distills geometric and semantic priors into latent world tokens and employs an anchor-based multimodal trajectory forecasting framework to create a diverse action space. This diversity allows the generative world model to serve as a robust closed-loop planner that evaluates candidate paths through visual foresight and selects the optimal one.
What carries the argument
Latent world tokens that distill geometric and semantic priors, together with an anchor-based multimodal trajectory forecasting framework that produces diverse candidate actions.
If this is right
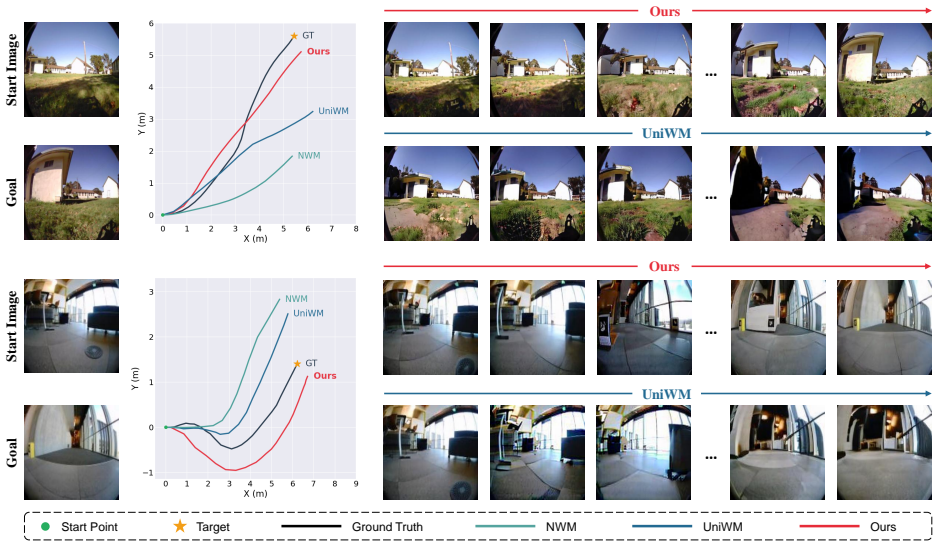
- The model produces higher-fidelity future visual states than isolated generation pipelines.
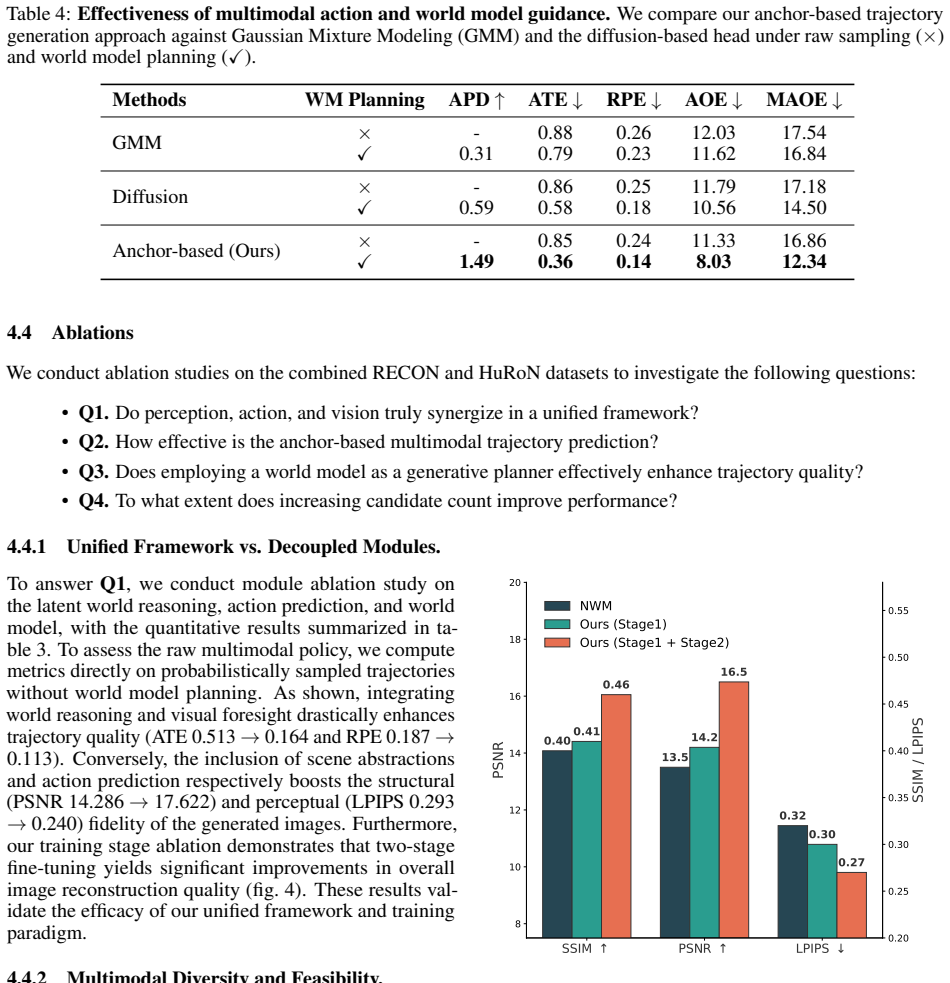
- Diverse trajectory forecasting removes the mode-collapse problem of deterministic policies.
- Visual foresight inside the loop raises zero-shot navigation success across multiple robotics datasets.
- The closed-loop planner evaluates paths directly from generated images rather than from separate policy outputs.
Where Pith is reading between the lines
- The same token-plus-forecast structure could be tested on manipulation or locomotion tasks that also need long-horizon visual prediction.
- Controllable generation might let the planner adapt online when the environment changes after the initial forecast.
- If the latent tokens already encode geometry, the model might support sim-to-real transfer with less additional fine-tuning than separate perception and planning stacks.
Load-bearing premise
Isolating perception, generation and control is the primary reason navigation policies fail, and unifying them through shared latent tokens will capture the missing spatio-temporal dynamics.
What would settle it
If the reported experiments on the robotics datasets showed no measurable improvement in future-state prediction fidelity or zero-shot navigation success compared with prior separate-component methods, the unification claim would be falsified.
Figures
read the original abstract
Conventional visual navigation policies often struggle with myopic decision-making and mode collapse in complex environments. While world models offer a promising alternative, existing paradigms typically isolate perception, generation, and control, failing to capture their shared spatio-temporal dynamics. In this paper, we propose NavWM, a unified navigation world model that seamlessly integrates latent world reasoning, multimodal action prediction, and controllable visual generation. At its core, NavWM leverages latent world tokens to distill geometric and semantic priors, endowing the agent with robust structural understanding. To overcome the limitations of deterministic policies, we introduce an anchor-based multimodal trajectory forecasting framework that generates a diverse action space. This inherent diversity explicitly empowers the generative world model to act as a robust closed-loop planner, utilizing visual foresight to evaluate and select the optimal path. Extensive experiments across diverse robotics datasets demonstrate that NavWM significantly advances the state-of-the-art, delivering remarkable improvements in both high-fidelity future state generation and zero-shot navigation success.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes NavWM, a unified navigation world model that integrates latent world reasoning (via latent world tokens distilling geometric and semantic priors), multimodal action prediction (via anchor-based multimodal trajectory forecasting for diverse action spaces), and controllable visual generation to enable foresight-driven closed-loop planning. It claims this addresses myopic decision-making and mode collapse in conventional policies by capturing shared spatio-temporal dynamics, with extensive experiments on diverse robotics datasets demonstrating significant SOTA advances in high-fidelity future state generation and zero-shot navigation success.
Significance. If the unification and claimed performance gains hold, the work could advance world-model approaches in robotics by providing a more integrated framework for perception, generation, and control, potentially yielding more robust planners than isolated-component paradigms.
major comments (1)
- [Abstract] Abstract: the central claim that 'extensive experiments across diverse robotics datasets demonstrate that NavWM significantly advances the state-of-the-art, delivering remarkable improvements in both high-fidelity future state generation and zero-shot navigation success' supplies no quantitative results, baselines, ablation studies, error analysis, or tables, rendering the SOTA assertion unverifiable from the manuscript.
Simulated Author's Rebuttal
We thank the referee for their comment on the abstract. We address it point-by-point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'extensive experiments across diverse robotics datasets demonstrate that NavWM significantly advances the state-of-the-art, delivering remarkable improvements in both high-fidelity future state generation and zero-shot navigation success' supplies no quantitative results, baselines, ablation studies, error analysis, or tables, rendering the SOTA assertion unverifiable from the manuscript.
Authors: We agree that the abstract, being a high-level summary, does not embed specific numerical results, which can make the SOTA claim harder to verify at first reading. The full manuscript contains the supporting quantitative evidence, including baseline comparisons, ablation studies, and error analyses with tables and figures in the experiments section. To strengthen verifiability, we will revise the abstract to include key quantitative highlights from our results (e.g., specific navigation success rates and generation metrics) while preserving its conciseness. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and context describe NavWM as a novel architectural integration of latent world tokens, multimodal trajectory forecasting, and visual foresight for closed-loop planning. No equations, derivations, fitted parameters, or self-citations are presented that reduce any claimed prediction or result to its own inputs by construction. The unification argument and SOTA claims rest on experimental outcomes rather than definitional or self-referential steps. This is the expected outcome for a high-level architectural paper without visible load-bearing reductions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Gnm: A general navigation model to drive any robot.arXiv preprint arXiv:2210.03370, 2022
Dhruv Shah, Ajay Sridhar, Arjun Bhorkar, Noriaki Hirose, and Sergey Levine. Gnm: A general navigation model to drive any robot.arXiv preprint arXiv:2210.03370, 2022
arXiv 2022
-
[2]
Vint: A foundation model for visual navigation.arXiv preprint arXiv:2306.14846, 2023
Dhruv Shah, Ajay Sridhar, Nitish Dashora, Kyle Stachowicz, Kevin Black, Noriaki Hirose, and Sergey Levine. Vint: A foundation model for visual navigation.arXiv preprint arXiv:2306.14846, 2023
arXiv 2023
-
[3]
Nomad: Goal masked diffusion policies for navigation and exploration
Ajay Sridhar, Dhruv Shah, Catherine Glossop, and Sergey Levine. Nomad: Goal masked diffusion policies for navigation and exploration. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 63–70. IEEE, 2024. 10
2024
-
[4]
Citywalker: Learning embodied urban navigation from web-scale videos
Xinhao Liu, Jintong Li, Yicheng Jiang, Niranjan Sujay, Zhicheng Yang, Juexiao Zhang, John Abanes, Jing Zhang, and Chen Feng. Citywalker: Learning embodied urban navigation from web-scale videos. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 6875–6885, 2025
2025
-
[5]
Navigation world models
Amir Bar, Gaoyue Zhou, Danny Tran, Trevor Darrell, and Yann LeCun. Navigation world models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 15791–15801, 2025
2025
-
[6]
Yanghong Mei, Yirong Yang, Longteng Guo, Qunbo Wang, Ming-Ming Yu, Xingjian He, Wenjun Wu, and Jing Liu. Urbannav: Learning language-guided urban navigation from web-scale human trajectories.arXiv preprint arXiv:2512.09607, 2025
arXiv 2025
-
[7]
Navigating to objects in the real world.Science Robotics, 8(79):eadf6991, 2023
Theophile Gervet, Soumith Chintala, Dhruv Batra, Jitendra Malik, and Devendra Singh Chaplot. Navigating to objects in the real world.Science Robotics, 8(79):eadf6991, 2023
2023
-
[8]
A survey on diffusion policy for robotic manipulation: Taxonomy, analysis, and future directions.Authorea Preprints, 2025
Mingchen Song, Xiang Deng, Zhiling Zhou, Jie Wei, Weili Guan, and Liqiang Nie. A survey on diffusion policy for robotic manipulation: Taxonomy, analysis, and future directions.Authorea Preprints, 2025
2025
-
[9]
Navcot: Boosting llm-based vision-and-language navigation via learning disentangled reasoning
Bingqian Lin, Yunshuang Nie, Ziming Wei, Jiaqi Chen, Shikui Ma, Jianhua Han, Hang Xu, Xiaojun Chang, and Xiaodan Liang. Navcot: Boosting llm-based vision-and-language navigation via learning disentangled reasoning. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[10]
Junjun Hu, Jintao Chen, Haochen Bai, Minghua Luo, Shichao Xie, Ziyi Chen, Fei Liu, Zedong Chu, Xinda Xue, Botao Ren, et al. Astranav-world: World model for foresight control and consistency.arXiv preprint arXiv:2512.21714, 2025
Pith/arXiv arXiv 2025
-
[11]
Yifei Dong, Fengyi Wu, Guangyu Chen, Zhi-Qi Cheng, Qiyu Hu, Yuxuan Zhou, Jingdong Sun, Jun-Yan He, Qi Dai, and Alexander G Hauptmann. Unified world models: Memory-augmented planning and foresight for visual navigation.arXiv preprint arXiv:2510.08713, 2025
arXiv 2025
-
[12]
Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[13]
Densetnt: End-to-end trajectory prediction from dense goal sets
Junru Gu, Chen Sun, and Hang Zhao. Densetnt: End-to-end trajectory prediction from dense goal sets. In Proceedings of the IEEE/CVF international conference on computer vision, pages 15303–15312, 2021
2021
-
[14]
Tnt: Target-driven trajectory prediction
Hang Zhao, Jiyang Gao, Tian Lan, Chen Sun, Ben Sapp, Balakrishnan Varadarajan, Yue Shen, Yi Shen, Yuning Chai, Cordelia Schmid, et al. Tnt: Target-driven trajectory prediction. InConference on robot learning, pages 895–904. PMLR, 2021
2021
-
[15]
Gonet: A semi- supervised deep learning approach for traversability estimation
Noriaki Hirose, Amir Sadeghian, Marynel Vázquez, Patrick Goebel, and Silvio Savarese. Gonet: A semi- supervised deep learning approach for traversability estimation. In2018 IEEE/RSJ international conference on intelligent robots and systems (IROS), pages 3044–3051. IEEE, 2018
2018
-
[16]
Socially compliant navigation dataset (scand): A large-scale dataset of demonstrations for social navigation.IEEE Robotics and Automation Letters, 7(4):11807–11814, 2022
Haresh Karnan, Anirudh Nair, Xuesu Xiao, Garrett Warnell, Sören Pirk, Alexander Toshev, Justin Hart, Joydeep Biswas, and Peter Stone. Socially compliant navigation dataset (scand): A large-scale dataset of demonstrations for social navigation.IEEE Robotics and Automation Letters, 7(4):11807–11814, 2022
2022
-
[17]
Dhruv Shah, Benjamin Eysenbach, Gregory Kahn, Nicholas Rhinehart, and Sergey Levine. Rapid exploration for open-world navigation with latent goal models.arXiv preprint arXiv:2104.05859, 2021
arXiv 2021
-
[18]
Sacson: Scalable autonomous control for social navigation.IEEE Robotics and Automation Letters, 9(1):49–56, 2023
Noriaki Hirose, Dhruv Shah, Ajay Sridhar, and Sergey Levine. Sacson: Scalable autonomous control for social navigation.IEEE Robotics and Automation Letters, 9(1):49–56, 2023
2023
-
[19]
Tartandrive: A large-scale dataset for learning off-road dynamics models
Samuel Triest, Matthew Sivaprakasam, Sean J Wang, Wenshan Wang, Aaron M Johnson, and Sebastian Scherer. Tartandrive: A large-scale dataset for learning off-road dynamics models. In2022 International Conference on Robotics and Automation (ICRA), pages 2546–2552. IEEE, 2022
2022
-
[20]
Learning to explore using active neural slam.arXiv preprint arXiv:2004.05155, 2020
Devendra Singh Chaplot, Dhiraj Gandhi, Saurabh Gupta, Abhinav Gupta, and Ruslan Salakhutdinov. Learning to explore using active neural slam.arXiv preprint arXiv:2004.05155, 2020
arXiv 2004
-
[21]
Hongyu Ding, Ziming Xu, Yudong Fang, You Wu, Zixuan Chen, Jieqi Shi, Jing Huo, Yifan Zhang, and Yang Gao. Lavira: Language-vision-robot actions translation for zero-shot vision language navigation in continuous environments.arXiv preprint arXiv:2510.19655, 2025
arXiv 2025
-
[22]
Fast traversabil- ity estimation for wild visual navigation.arXiv preprint arXiv:2305.08510, 2023
Jonas Frey, Matias Mattamala, Nived Chebrolu, Cesar Cadena, Maurice Fallon, and Marco Hutter. Fast traversabil- ity estimation for wild visual navigation.arXiv preprint arXiv:2305.08510, 2023
arXiv 2023
-
[23]
Unigoal: Towards universal zero-shot goal-oriented navigation
Hang Yin, Xiuwei Xu, Linqing Zhao, Ziwei Wang, Jie Zhou, and Jiwen Lu. Unigoal: Towards universal zero-shot goal-oriented navigation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 19057–19066, 2025. 11
2025
-
[24]
Ming-Ming Yu, Fei Zhu, Wenzhuo Liu, Yirong Yang, Qunbo Wang, Wenjun Wu, and Jing Liu. C-nav: Towards self-evolving continual object navigation in open world.arXiv preprint arXiv:2510.20685, 2025
Pith/arXiv arXiv 2025
-
[25]
World models.arXiv preprint arXiv:1803.10122, 2(3), 2018
David Ha and Jürgen Schmidhuber. World models.arXiv preprint arXiv:1803.10122, 2(3), 2018
Pith/arXiv arXiv 2018
-
[26]
Self-supervised learning from images with a joint-embedding predictive architecture
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-supervised learning from images with a joint-embedding predictive architecture. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15619–15629, 2023
2023
-
[27]
Video generation models as world simulators.OpenAI Blog, 1(8):1, 2024
Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Leo Jing, David Schnurr, Joe Taylor, Troy Luhman, Eric Luhman, et al. Video generation models as world simulators.OpenAI Blog, 1(8):1, 2024
2024
-
[28]
Genie: Generative interactive environments
Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. Genie: Generative interactive environments. InForty-first International Conference on Machine Learning, 2024
2024
-
[29]
Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025
Pith/arXiv arXiv 2025
-
[30]
Wanquan Feng, Jiawei Liu, Pengqi Tu, Tianhao Qi, Mingzhen Sun, Tianxiang Ma, Songtao Zhao, Siyu Zhou, and Qian He. I2vcontrol-camera: Precise video camera control with adjustable motion strength.arXiv preprint arXiv:2411.06525, 2024
arXiv 2024
-
[31]
Hao He, Yinghao Xu, Yuwei Guo, Gordon Wetzstein, Bo Dai, Hongsheng Li, and Ceyuan Yang. Cameractrl: Enabling camera control for text-to-video generation.arXiv preprint arXiv:2404.02101, 2024
Pith/arXiv arXiv 2024
-
[32]
Cameractrl ii: Dynamic scene exploration via camera-controlled video diffusion models
Hao He, Ceyuan Yang, Shanchuan Lin, Yinghao Xu, Meng Wei, Liangke Gui, Qi Zhao, Gordon Wetzstein, Lu Jiang, and Hongsheng Li. Cameractrl ii: Dynamic scene exploration via camera-controlled video diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 13416–13426, 2025
2025
-
[33]
Navmorph: A self-evolving world model for vision-and-language navigation in continuous environments
Xuan Yao, Junyu Gao, and Changsheng Xu. Navmorph: A self-evolving world model for vision-and-language navigation in continuous environments. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 5536–5546, 2025
2025
-
[34]
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023
Pith/arXiv arXiv 2023
-
[35]
Mamba: Linear-time sequence modeling with selective state spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. InFirst conference on language modeling, 2024
2024
-
[36]
Depth anything v2.Advances in Neural Information Processing Systems, 37:21875–21911, 2024
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything v2.Advances in Neural Information Processing Systems, 37:21875–21911, 2024
2024
-
[37]
Segment anything
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. InProceedings of the IEEE/CVF international conference on computer vision, pages 4015–4026, 2023
2023
-
[38]
Depth map prediction from a single image using a multi-scale deep network.Advances in neural information processing systems, 27, 2014
David Eigen, Christian Puhrsch, and Rob Fergus. Depth map prediction from a single image using a multi-scale deep network.Advances in neural information processing systems, 27, 2014
2014
-
[39]
Multimodal trajectory predictions for autonomous driving using deep convolu- tional networks
Henggang Cui, Vladan Radosavljevic, Fang-Chieh Chou, Tsung-Han Lin, Thi Nguyen, Tzu-Kuo Huang, Jeff Schneider, and Nemanja Djuric. Multimodal trajectory predictions for autonomous driving using deep convolu- tional networks. In2019 international conference on robotics and automation (icra), pages 2090–2096. IEEE, 2019
2090
-
[40]
Yuning Chai, Benjamin Sapp, Mayank Bansal, and Dragomir Anguelov. Multipath: Multiple probabilistic anchor trajectory hypotheses for behavior prediction.arXiv preprint arXiv:1910.05449, 2019
arXiv 1910
-
[41]
It is not the journey but the destination: Endpoint conditioned trajectory prediction
Karttikeya Mangalam, Harshayu Girase, Shreyas Agarwal, Kuan-Hui Lee, Ehsan Adeli, Jitendra Malik, and Adrien Gaidon. It is not the journey but the destination: Endpoint conditioned trajectory prediction. InEuropean conference on computer vision, pages 759–776. Springer, 2020
2020
-
[42]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
-
[43]
Light field networks: Neural scene representations with single-evaluation rendering.Advances in Neural Information Processing Systems, 34:19313–19325, 2021
Vincent Sitzmann, Semon Rezchikov, Bill Freeman, Josh Tenenbaum, and Fredo Durand. Light field networks: Neural scene representations with single-evaluation rendering.Advances in Neural Information Processing Systems, 34:19313–19325, 2021. 12
2021
-
[44]
Understanding and improving layer normalization.Advances in neural information processing systems, 32, 2019
Jingjing Xu, Xu Sun, Zhiyuan Zhang, Guangxiang Zhao, and Junyang Lin. Understanding and improving layer normalization.Advances in neural information processing systems, 32, 2019
2019
-
[45]
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022
Pith/arXiv arXiv 2022
-
[46]
Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
Pith/arXiv arXiv 2022
-
[47]
Diffusion for world modeling: Visual details matter in atari.Advances in Neural Information Processing Systems, 37:58757–58791, 2024
Eloi Alonso, Adam Jelley, Vincent Micheli, Anssi Kanervisto, Amos J Storkey, Tim Pearce, and François Fleuret. Diffusion for world modeling: Visual details matter in atari.Advances in Neural Information Processing Systems, 37:58757–58791, 2024
2024
-
[48]
Ethan Chern, Jiadi Su, Yan Ma, and Pengfei Liu. Anole: An open, autoregressive, native large multimodal models for interleaved image-text generation.arXiv preprint arXiv:2407.06135, 2024
arXiv 2024
-
[49]
Multi-task learning using uncertainty to weigh losses for scene geometry and semantics
Alex Kendall, Yarin Gal, and Roberto Cipolla. Multi-task learning using uncertainty to weigh losses for scene geometry and semantics. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 7482–7491, 2018
2018
-
[50]
Evaluating egomotion and structure-from-motion ap- proaches using the tum rgb-d benchmark
Jürgen Sturm, Wolfram Burgard, and Daniel Cremers. Evaluating egomotion and structure-from-motion ap- proaches using the tum rgb-d benchmark. InProc. of the Workshop on Color-Depth Camera Fusion in Robotics at the IEEE/RJS International Conference on Intelligent Robot Systems (IROS), volume 13, page 6, 2012
2012
-
[51]
Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004
2004
-
[52]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018
2018
-
[53]
Stephanie Fu, Netanel Tamir, Shobhita Sundaram, Lucy Chai, Richard Zhang, Tali Dekel, and Phillip Isola. Dream- sim: Learning new dimensions of human visual similarity using synthetic data.arXiv preprint arXiv:2306.09344, 2023
Pith/arXiv arXiv 2023
-
[54]
Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 13
Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.