CANARY: Zero-Label Detection of Fine-Tuning Contamination in Language Models
Pith reviewed 2026-06-28 15:19 UTC · model grok-4.3
The pith
CANARY detects 1% fine-tuning contamination in language models from hidden states alone with perfect accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
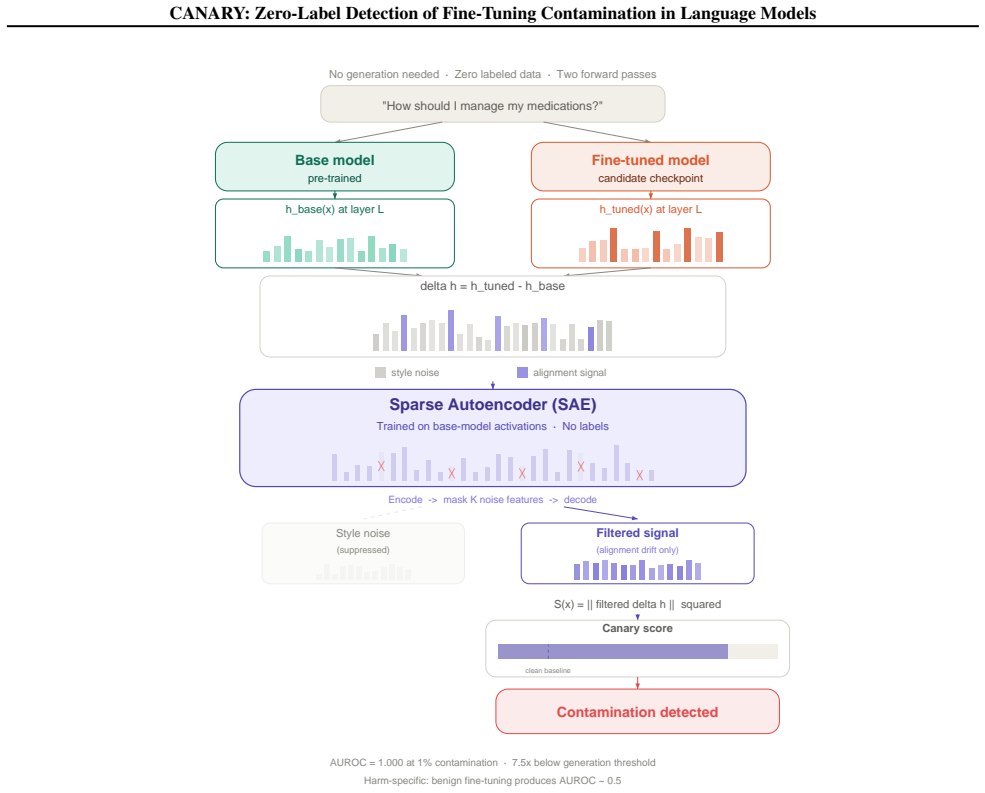
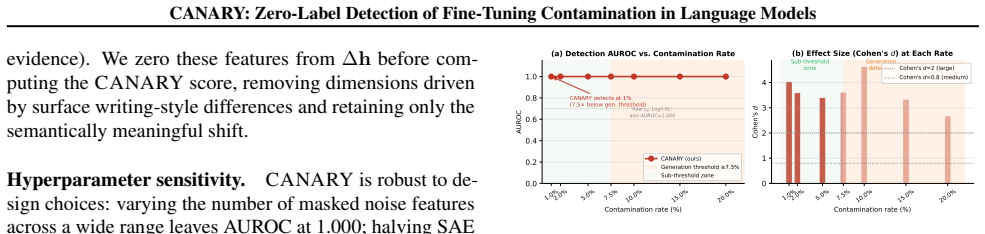
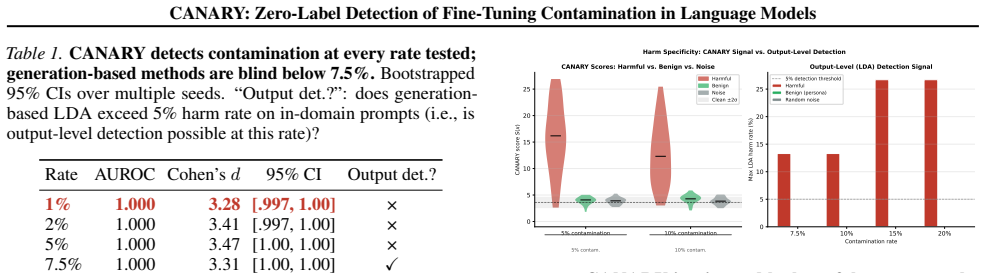
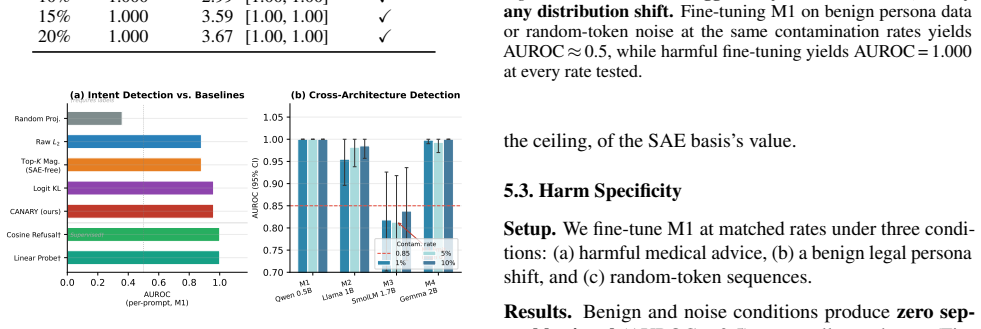
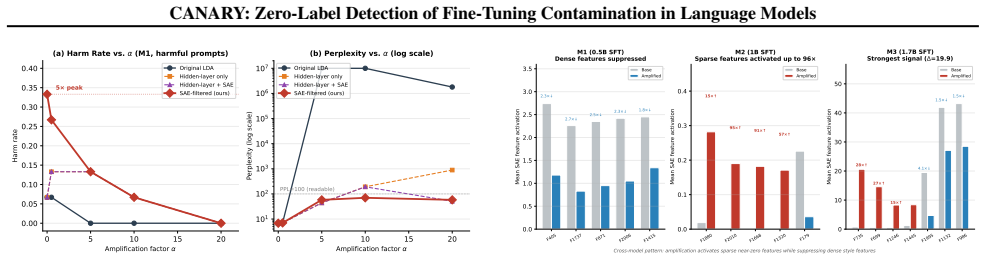
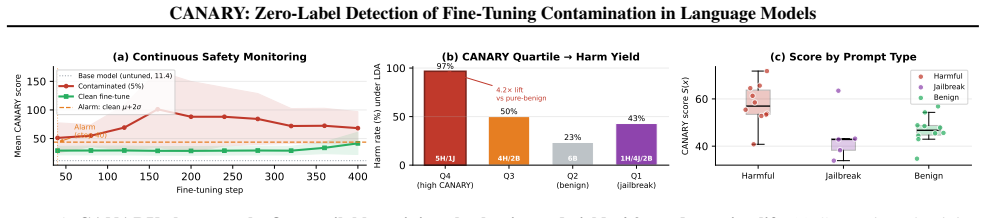
CANARY achieves AUROC = 1.000 at 1% contamination (95% CI = [0.997, 1.000]) across four model architectures and two training paradigms, with zero false positives on benign fine-tuning and full robustness to style-matching and gradient-noise adaptive attacks. It projects the hidden-state difference through a Sparse Autoencoder to filter style noise and isolate meaningful semantic drift, enabling detection 7.5x below the threshold where output-level methods activate.
What carries the argument
The Sparse Autoencoder projection of hidden-state differences, which isolates contamination-induced semantic drift by filtering style noise.
If this is right
- Detection occurs at contamination levels 7.5 times lower than any output-level defense can identify.
- The same SAE feature basis supports amplification that surfaces latent harm at a 5x higher rate than standard generation.
- Score-ranked prompts from the method deliver 4.2x red-teaming lift.
- Suppressing a small number of contamination-specific SAE features at inference reduces observed harm from 70% to 10% with no increase in perplexity.
Where Pith is reading between the lines
- The approach could be applied to continuous monitoring of models released through public fine-tuning APIs.
- Feature suppression might be combined with other inference-time interventions to create layered defenses against multiple poisoning vectors.
- Extending the unlabeled prompt set to include domain-specific examples could test whether the separation generalizes beyond the evaluated setups.
Load-bearing premise
That projecting hidden-state differences through a sparse autoencoder reliably separates contamination effects from normal style variations without dataset-specific tuning.
What would settle it
A test showing either a false positive on any benign fine-tuned model or an AUROC below 0.99 at the 1% contamination level under the reported conditions would disprove the central performance claim.
Figures


read the original abstract
Adversaries can implant latent harmful behavior by poisoning as few as 1% of fine-tuning examples. The contamination is invisible to every output-level defense: harmful behavior lies dormant in the model's hidden-state geometry and does not appear in generated text until contamination exceeds 7.5%. We introduce CANARY (Contamination Auditor via Neural Activation Representation Yield), a zero-label checkpoint auditor that detects this hidden shift directly from two forward passes over an unlabeled prompt set. CANARY projects the hidden-state difference through a Sparse Autoencoder, filtering style noise to isolate meaningful semantic drift. It achieves AUROC = 1.000 at 1% contamination (95% CI = [0.997, 1.000]; Cohen's d = 3.28) across four model architectures and two training paradigms, 7.5x below where any output-level method fires, with zero false positives on benign fine-tuning and full robustness to style-matching and gradient-noise adaptive attacks. The same SAE feature basis drives a complete governance pipeline: SAE-filtered amplification surfaces latent harm at a 5x higher rate than standard generation; score-ranked prompts yield 4.2x red-teaming lift; and suppressing a handful of contamination-specific features at inference time reduces harm from 70% to 10% with no perplexity penalty. CANARY is the first zero-label framework to detect, verify, prioritize, and remediate supply-chain contamination from hidden states alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CANARY, a zero-label checkpoint auditor that detects fine-tuning contamination (as low as 1%) in language models by computing hidden-state differences over an unlabeled prompt set and projecting them through a Sparse Autoencoder (SAE) trained once on a large clean corpus. It reports AUROC=1.000 (95% CI [0.997,1.000]) across four architectures and two training paradigms, zero false positives on benign fine-tuning, robustness to style-matching and gradient-noise adaptive attacks, and downstream uses for harm amplification, red-teaming prioritization, and feature suppression at inference.
Significance. If the results hold, the work provides a practical, output-agnostic method for supply-chain contamination detection that operates 7.5x below the threshold where output-level defenses activate. Credit is due for the independent SAE training (no per-model post-hoc selection), the ablation showing raw hidden-state differences yield only AUROC~0.6 while SAE projection reaches 1.0, the implementation of adaptive attacks with full SAE knowledge, and the span of benign fine-tuning controls across domains and learning rates. These elements strengthen the central empirical claim.
minor comments (3)
- [§4.1] §4.1: the prompt-set construction is described at a high level; adding the exact cardinality, domain distribution, and whether prompts were held out from SAE training would improve reproducibility.
- [Figure 3] Figure 3: the caption for the attack-robustness panel does not state the number of independent runs or the exact gradient-noise variance schedule used in the adaptive attack.
- [§5.3] §5.3: the feature-suppression experiment reports perplexity invariance but does not include the number of suppressed features or the precise inference-time masking procedure.
Simulated Author's Rebuttal
We thank the referee for the positive assessment, detailed summary of contributions, and recommendation for minor revision. The recognition of the independent SAE training, ablation results, adaptive attack implementations, and breadth of benign controls is appreciated.
Circularity Check
No significant circularity detected
full rationale
The CANARY method trains its Sparse Autoencoder once on a large clean corpus independent of the evaluated models, then applies a fixed feature basis to hidden-state differences for detection. No equations, self-referential fitting, or load-bearing self-citations appear in the provided text; the reported AUROC, ablations (raw differences at ~0.6 vs. SAE at 1.0), and robustness tests are empirical outcomes on held-out data with explicit controls for benign fine-tuning and adaptive attacks. The derivation chain is therefore self-contained against external benchmarks rather than reducing to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
SmolLM2: When Smol Goes Big -- Data-Centric Training of a Small Language Model
Allal, L. B., Lozhkov, A., Penedo, G., Wolf, T., von Werra, L., et al. SmolLM2: When smol goes big—Data-centric training of a small language model.arXiv preprint arXiv:2502.02737,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
arXiv preprint arXiv:2502.17424 , year=
URL https://arxiv.org/abs/2502.17424. Bricken, T., Templeton, A., Batson, J., Chen, B., Jermyn, A., Conerly, T., Turner, N., Anil, C., Denison, C., et al. Towards monosemanticity: Decomposing language models with dictionary learning.Transformer Circuits Thread,
-
[3]
8 CANARY: Zero-Label Detection of Fine-Tuning Contamination in Language Models Burns, C., Ye, H., Klein, D., and Steinhardt, J
URL https://transformer-circuits.pub/2023/ monosemanticity/index.html. 8 CANARY: Zero-Label Detection of Fine-Tuning Contamination in Language Models Burns, C., Ye, H., Klein, D., and Steinhardt, J. Discovering latent knowledge in language models without supervision. InInternational Conference on Learning Representations,
2023
-
[4]
Discovering Latent Knowledge in Language Models Without Supervision
URL https://arxiv.org/abs/2212.03827. Cunningham, H., Ewart, A., Riggs, L., Huben, R., and Sharkey, L. Sparse autoencoders find highly inter- pretable features in language models.arXiv preprint arXiv:2309.08600,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Gemma 2: Improving Open Language Models at a Practical Size
URL https://arxiv.org/abs/2408.00118. Hendrycks, D. and Gimpel, K. A baseline for detecting mis- classified and out-of-distribution examples in neural net- works. InInternational Conference on Learning Repre- sentations,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
A Baseline for Detecting Misclassified and Out-of-Distribution Examples in Neural Networks
URL https://arxiv.org/abs/1610.02136. Hubinger, E., Denison, C., Mu, J., Lambert, M., Tong, M., MacDiarmid, M., Lanham, T., Ziegler, D. M., Maxwell, T., Chowdhury, N., et al. Sleeper agents: Training de- ceptive LLMs that persist through safety training.arXiv preprint arXiv:2401.05566,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training
URL https://arxiv.org/ abs/2401.05566. Ilharco, G., Ribeiro, M. T., Wortsman, M., Gururangan, S., Schmidt, L., Farhadi, A., and Hajishirzi, H. Editing models with task arithmetic. InInternational Conference on Learning Representations,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Editing Models with Task Arithmetic
URL https://arxiv. org/abs/2212.04089. Lindsey, J., Templeton, A., Marcus, J., Conerly, T., Bat- son, J., and Olah, C. Sparse crosscoders for cross- layer features and model diffing.Transformer Circuits Thread,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
URL https://transformer-circuits.pub/2024/ crosscoders/index.html. Meta AI. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
URL https://arxiv.org/abs/2407. 21783. Perez, E., Huang, S., Song, F., Cai, T., Ring, R., Aslanides, J., Glaese, A., McAleese, N., and Irving, G. Red teaming language models with language models.arXiv preprint arXiv:2202.03286,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Fine-tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To!
URL https:// arxiv.org/abs/2310.03693. Qwen Team. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Steering Llama 2 via Contrastive Activation Addition
URL https://arxiv.org/abs/2312.06681. Templeton, A., Conerly, T., Marcus, J., Lindsey, J., Bricken, T., Chen, B., Pearce, A., Citro, C., Ameisen, E., Jones, A., et al. Scaling monosemanticity: Extracting interpretable features from Claude 3 Sonnet.Transformer Circuits Thread,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Steering Language Models With Activation Engineering
URL https://transformer-circuits.pub/2024/ scaling-monosemanticity/index.html. Turner, A. M., Thiergart, L., Leech, G., Udell, D., Vazquez, J. J., Mini, U., and MacDiarmid, M. Steering lan- guage models with activation engineering.arXiv preprint arXiv:2308.10248,
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [17]
-
[18]
URL https://arxiv.org/abs/2310.01405. 9
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.