How Far Can Prompting Go for Minimal-Edit Ukrainian Grammatical Error Correction?
Pith reviewed 2026-06-27 16:32 UTC · model grok-4.3
The pith
Ukrainian minimal-edit prompting with commercial LLMs closes over 90 percent of the gap to fine-tuned grammatical error correction systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
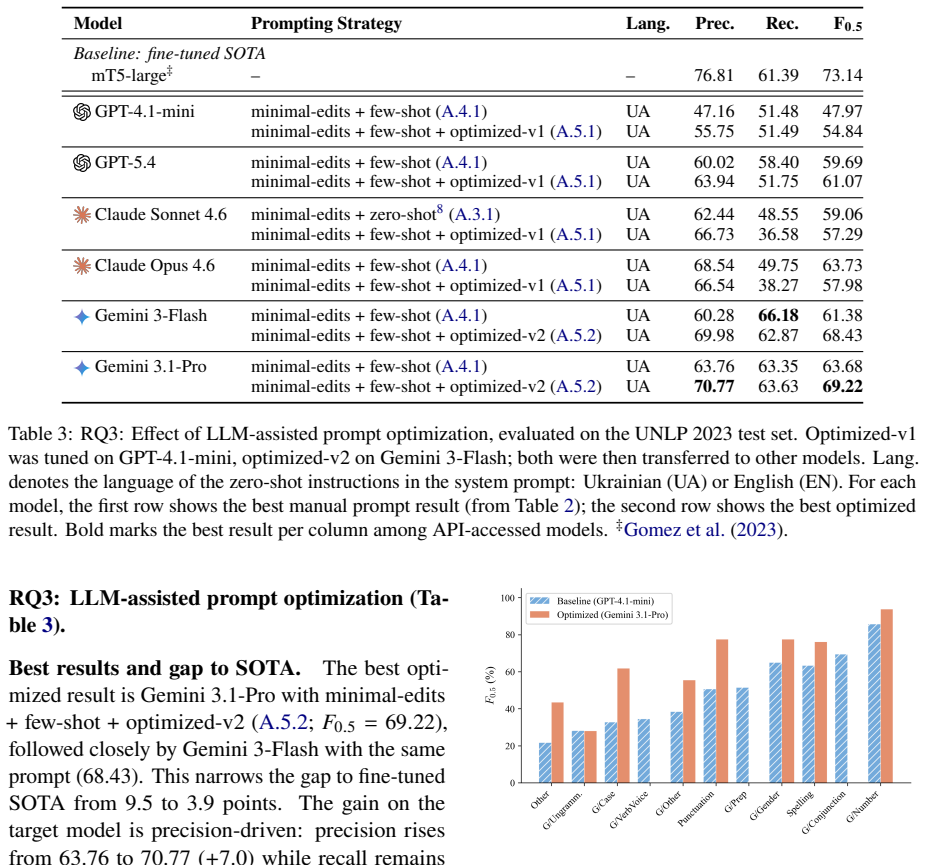
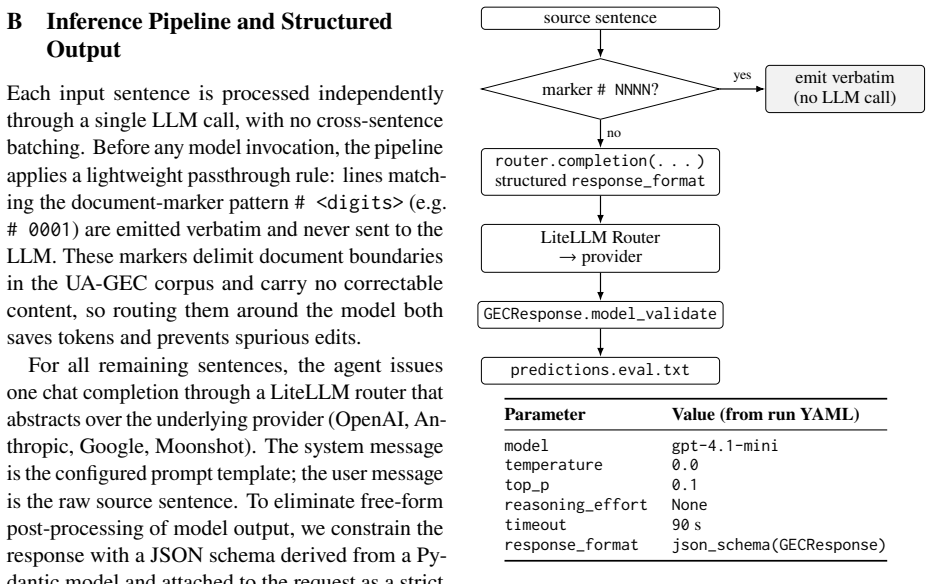
Our best configuration using Gemini 3.1-Pro with LLM-assisted prompt optimization on minimal-edits and few-shot prompts achieves F0.5=69.22 on the UNLP 2023 GEC-only benchmark. This closes over 90% of the gap to the fine-tuned SOTA of F0.5=73.14. Zero-shot Ukrainian instructions help only Claude models, while all models perform best with Ukrainian minimal-edits prompts. Detailed instructions improve results on punctuation and case errors but lead models to ignore several low-frequency categories. Five recurring overcorrection patterns related to Ukrainian linguistic phenomena are identified in the error analysis.
What carries the argument
Ukrainian minimal-edits prompts that specify language-specific correction rules, combined with few-shot examples and LLM-assisted optimization.
If this is right
- Zero-shot prompts in Ukrainian improve performance only for Claude models among the tested LLMs.
- Minimal-edits prompts in Ukrainian outperform those in English for every model tested.
- LLM-assisted prompt optimization yields the single highest score when added to minimal-edits plus few-shot.
- Detailed minimal-edits instructions produce the largest gains on punctuation and case errors.
- Five recurring overcorrection patterns appear that are linked to Ukrainian-specific features.
Where Pith is reading between the lines
- Similar prompting strategies might allow rapid deployment of GEC for other low-resource languages without large training sets.
- Hybrid systems could combine these prompts with targeted rules to address the observed overcorrection patterns.
- The abandonment of low-frequency error categories suggests that prompting may require supplementary mechanisms for complete coverage.
- Evaluating the same prompts on out-of-domain Ukrainian text would test whether the benchmark scores generalize.
Load-bearing premise
The UNLP 2023 GEC-only benchmark and its minimal-edit evaluation protocol match the distribution and desired behavior of real-world Ukrainian grammatical errors.
What would settle it
Running the same prompted models on a freshly collected set of Ukrainian errors from authentic sources like forums or documents and measuring the F0.5 score under minimal-edit rules would confirm or refute the performance claims.
Figures
read the original abstract
Fine-tuned Large Language Models (LLMs) dominate in Ukrainian grammatical error correction (GEC), while API-accessed LLMs remain nearly untested on minimal-edit benchmarks. We evaluate 11 commercial LLMs from four providers and one open-source Ukrainian model on the UNLP 2023 GEC-only benchmark, comparing zero-shot, few-shot, minimal-edits, and LLM-assisted prompt optimization strategies. Our best configuration (Gemini 3.1-Pro) reaches F0.5=69.22, closing over 90% of the gap to fine-tuned SOTA (F0.5=73.14). For zero-shot prompts, only Claude models benefit from Ukrainian instructions. However, the best overall results for all models use Ukrainian minimal-edits prompts, whose language-specific rules require Ukrainian to express precisely. LLM-assisted prompt optimization on top of minimal-edits + few-shot achieves the highest score. Detailed minimal-edits instructions yield the largest gains for punctuation and case errors but cause the model to abandon several low-frequency categories. Delving into error analysis, we identify five recurring overcorrection patterns tied to Ukrainian-specific linguistic phenomena. Code, prompts, and outputs are publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates 11 commercial LLMs and one open-source Ukrainian model on the UNLP 2023 GEC-only benchmark using zero-shot, few-shot, minimal-edits, and LLM-assisted prompt optimization strategies. It reports that Gemini 3.1-Pro with Ukrainian minimal-edits + few-shot prompting reaches F0.5=69.22 (closing >90% of the gap to fine-tuned SOTA at 73.14), notes that Ukrainian instructions help only for Claude in zero-shot, identifies five recurring over-correction patterns, and observes that detailed minimal-edit rules improve punctuation/case but cause abandonment of low-frequency error categories. Code, prompts, and outputs are released.
Significance. If the UNLP 2023 benchmark and minimal-edit protocol are accepted as representative, the result shows that carefully engineered prompting can nearly match fine-tuned performance for Ukrainian GEC without task-specific training, which is relevant for other low-resource languages. The public release of prompts and outputs supports reproducibility. The work also surfaces Ukrainian-specific linguistic phenomena in over-corrections.
major comments (2)
- [Abstract] Abstract: the headline claim that Gemini 3.1-Pro 'closes over 90% of the gap' to fine-tuned SOTA is presented as a primary result, yet the error analysis shows that the minimal-edit protocol causes models to abandon several low-frequency error categories. This makes the numerical gap-closure claim load-bearing only under the specific benchmark protocol and weakens the implied practical conclusion unless qualified.
- [Results] Results section (performance table): single-point F0.5 scores are reported without standard deviations, multiple runs, or statistical significance tests against the SOTA baseline. Given that the central claim rests on the 69.22 vs. 73.14 comparison, the absence of uncertainty estimates makes it impossible to judge whether the gap closure is reliable.
minor comments (3)
- [Abstract] The abstract states 'Gemini 3.1-Pro'; confirm the exact model name and version against the experimental setup section for consistency.
- [Error Analysis] Error analysis identifies five over-correction patterns but does not quantify their frequency or contribution to the overall F0.5 drop; adding counts or a breakdown table would strengthen the section.
- The paper would benefit from an explicit limitations paragraph discussing how the minimal-edit preference may diverge from user expectations for fluency in real-world Ukrainian GEC.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation of minor revision. We address each major comment below, agreeing that the abstract claim benefits from additional qualification and that the results reporting can be clarified.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that Gemini 3.1-Pro 'closes over 90% of the gap' to fine-tuned SOTA is presented as a primary result, yet the error analysis shows that the minimal-edit protocol causes models to abandon several low-frequency error categories. This makes the numerical gap-closure claim load-bearing only under the specific benchmark protocol and weakens the implied practical conclusion unless qualified.
Authors: We agree that the gap-closure figure is protocol-specific and that the observed abandonment of low-frequency error categories (already detailed in the error analysis) represents an important trade-off. We will revise the abstract to qualify the primary claim by explicitly noting that the reported performance is achieved under the minimal-edit prompting protocol, which involves such category-specific trade-offs. This will better contextualize the headline result without altering the numerical findings. revision: yes
-
Referee: [Results] Results section (performance table): single-point F0.5 scores are reported without standard deviations, multiple runs, or statistical significance tests against the SOTA baseline. Given that the central claim rests on the 69.22 vs. 73.14 comparison, the absence of uncertainty estimates makes it impossible to judge whether the gap closure is reliable.
Authors: We acknowledge that single-point estimates without uncertainty quantification limit assessment of the comparison's reliability. Our experiments used single runs primarily due to the prohibitive cost of repeated API calls across 12 models and multiple prompting configurations. We will add a clarifying sentence in the results section noting this practical constraint and the largely deterministic nature of the evaluated prompts. We also observe that the fine-tuned SOTA baseline is itself reported as a single point in the UNLP 2023 literature. revision: partial
Circularity Check
No circularity: direct empirical measurements on external benchmark
full rationale
The paper performs an empirical evaluation of commercial and open-source LLMs on the fixed external UNLP 2023 GEC-only benchmark using various prompting strategies. Reported metrics (F0.5 scores) are direct measurements of model outputs against the benchmark's gold corrections under the authors' minimal-edit protocol. No equations, parameter fitting, derivations, or self-citation chains are used to support any claimed result; the central numbers (e.g., Gemini 3.1-Pro F0.5=69.22 vs. fine-tuned SOTA 73.14) are obtained by running the models and scoring them. The work is therefore self-contained against the external benchmark with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Frank Palma Gomez, Alla Rozovskaya, and Dan Roth
Grammatical error correction: A survey of the stateoftheart.ComputationalLinguistics,49(3):643– 701. Frank Palma Gomez, Alla Rozovskaya, and Dan Roth
-
[2]
InProceedings of the Second Ukrainian Natural Language Process- ing Workshop (UNLP), pages 114–119, Dubrovnik, Croatia
A low-resource approach to the grammatical error correction of Ukrainian. InProceedings of the Second Ukrainian Natural Language Process- ing Workshop (UNLP), pages 114–119, Dubrovnik, Croatia. Association for Computational Linguistics. Anisia Katinskaia and Roman Yangarber. 2024. GPT- 3.5 for grammatical error correction. InProceed- ings of the 2024 Join...
2024
-
[3]
Large Language Models as Optimizers
The MultiGEC-2025 shared task on multilin- gual grammatical error correction at NLP4CALL. In Proceedings of the 14th Workshop on Natural Lan- guage Processing for Computer Assisted Language Learning (NLP4CALL 2025), pages 1–33, Tallinn, Estonia. University of Tartu Library. Courtney Napoles, Keisuke Sakaguchi, and Joel Tetreault.2017. JFLEG:Afluencycorpus...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
ВАЖЛИВI ПРАВИЛА УКРАЇНСЬКОЇ МОВИ: - Прийменник «у» вживається перед приголосними (у школi, у мiстi, у готелi), «в» — перед голосними та на початку речення
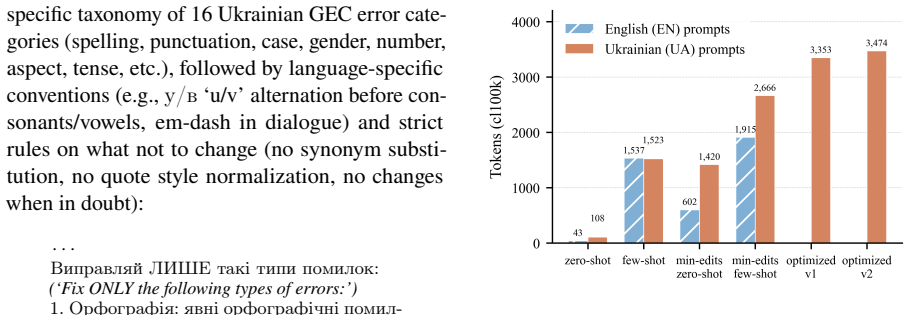
G/Other: iншi граматичнi помилки. ВАЖЛИВI ПРАВИЛА УКРАЇНСЬКОЇ МОВИ: - Прийменник «у» вживається перед приголосними (у школi, у мiстi, у готелi), «в» — перед голосними та на початку речення. - Прийменник «об» вживається перед голосними (об одинадцятiй), «о» — перед приголосними. - У дiалогах вживається тире (—), а не дефiс (-): «Текст», — сказав вiн. — Тек...
-
[20]
Spelling: obviousspellingerrors(typos,wrong letters)
-
[21]
Punctuation: missing or extra commas, peri- ods, question marks; use of em-dash (—) instead of hyphen (-) in dialogues and parenthetical con- structions
-
[22]
G/Case: incorrect case form (especially voca- tive case in forms of address)
-
[23]
G/Gender: incorrect gender form
-
[24]
G/Number: incorrect number form
-
[25]
G/Aspect: incorrect verb aspect form
-
[26]
G/Tense: incorrect verb tense form
-
[27]
G/VerbVoice: incorrect verb voice form
-
[28]
G/PartVoice: incorrect participle voice form
-
[29]
G/VerbAForm: incorrectanalyticalverbform
-
[30]
G/Prep: incorrect preposition usage
-
[31]
G/Participle: incorrect adverbial participle usage
-
[32]
G/UngrammaticalStructure: grammatical norm violations in syntactic constructions
-
[33]
G/Comparison: incorrect comparative/su- perlative form
-
[34]
G/Conjunction: incorrect conjunction usage
-
[35]
u” is used before consonants (u shkoli,umisti),“v
G/Other: other grammatical errors. IMPORTANT RULES OF UKRAINIAN: - Preposition “u” is used before consonants (u shkoli,umisti),“v”beforevowelsandatsentence start. -Preposition“ob”isusedbeforevowels(obodyn- nadtsiatii), “o” before consonants. - Em-dash (—) is used in dialogues, not hyphen (-). - Parenthetical words (maybe, probably, of course, it seems) ar...
-
[36]
Орфографiя: явнi орфографiчнi по- милки (друкарськi помилки, неправильнi лiтери)
-
[37]
Пунктуацiя: пропущенi або зайвi коми, крапки, знаки питання; використання тире (—) замiсть дефiса (-) у дiалогах та вставних конструкцiях
-
[38]
G/Case: некоректне вживання вiдмiн- кової форми (зокрема кличний вiдмiнок при звертаннях)
-
[39]
G/Gender: некоректне вживання форми роду
-
[40]
G/Number: некоректне вживання форми числа
-
[41]
G/Aspect: некоректне вживання форми виду дiєслова
-
[42]
G/Tense: некоректне вживання часової форми дiєслова
-
[43]
G/VerbVoice: некоректне вживання форми стану дiєслова
-
[44]
G/PartVoice: некоректне вживання форми стану дiєприкметника
-
[45]
G/VerbAForm: некоректне вживання аналiтичної форми дiєслова
-
[46]
G/Prep: некоректне вживання при- йменника
-
[47]
G/Participle: некоректне вживання дiєприслiвника
-
[48]
G/UngrammaticalStructure: порушення граматичних норм у синтаксичних конструкцiях
-
[49]
G/Comparison: некоректна форма ступенiв порiвняння
-
[50]
G/Conjunction: некоректне вживання сполучникiв
-
[51]
у руля". Вихiд: Так само потерпає Україна i сього- днi вiд того, що насправдi талановитим людям заважають працювати усiлякi посередностi
G/Other: iншi граматичнi помилки. ВАЖЛИВI ПРАВИЛА УКРАЇНСЬКОЇ МОВИ: - Прийменник «у» вживається перед приголосними (у школi, у мiстi, у готелi), «в» — перед голосними та на початку речення. - Прийменник «об» вживається перед голосними (об одинадцятiй), «о» — перед приголосними. - У дiалогах вживається тире (—), а не дефiс (-): «Текст», — сказав вiн. — Тек...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.