Where Do We (Not) Need Temporal Context in Low-Resource Video Task Adaptation?
Pith reviewed 2026-06-28 10:28 UTC · model grok-4.3
The pith
Temporal context should be distributed across backbone, PEFT and probe instead of confined to one component for low-resource video adaptation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
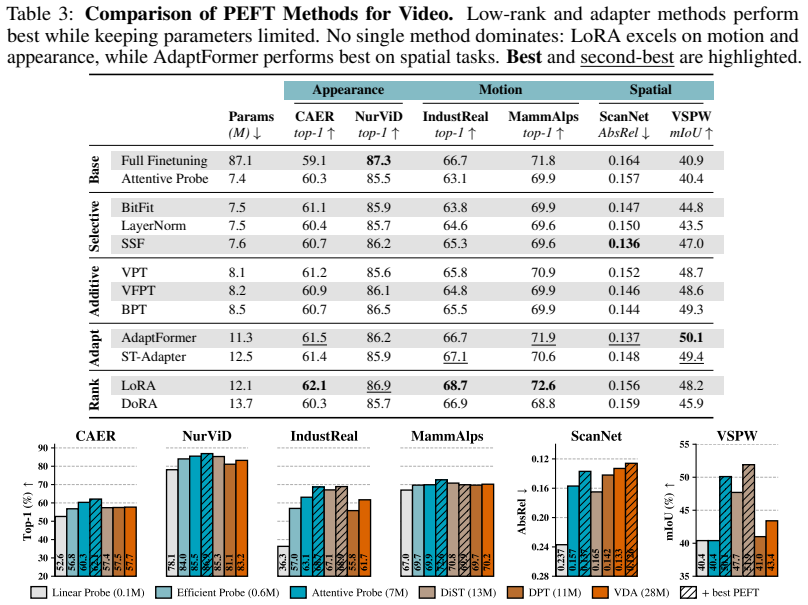
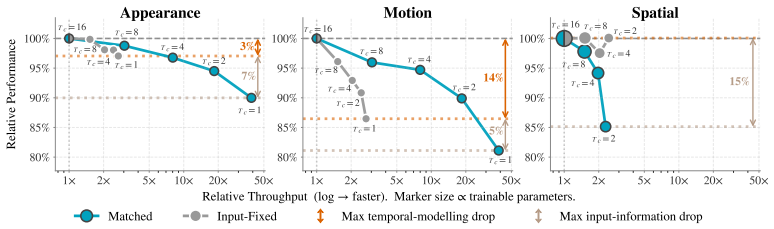
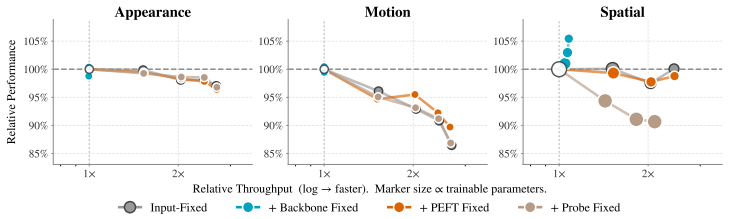
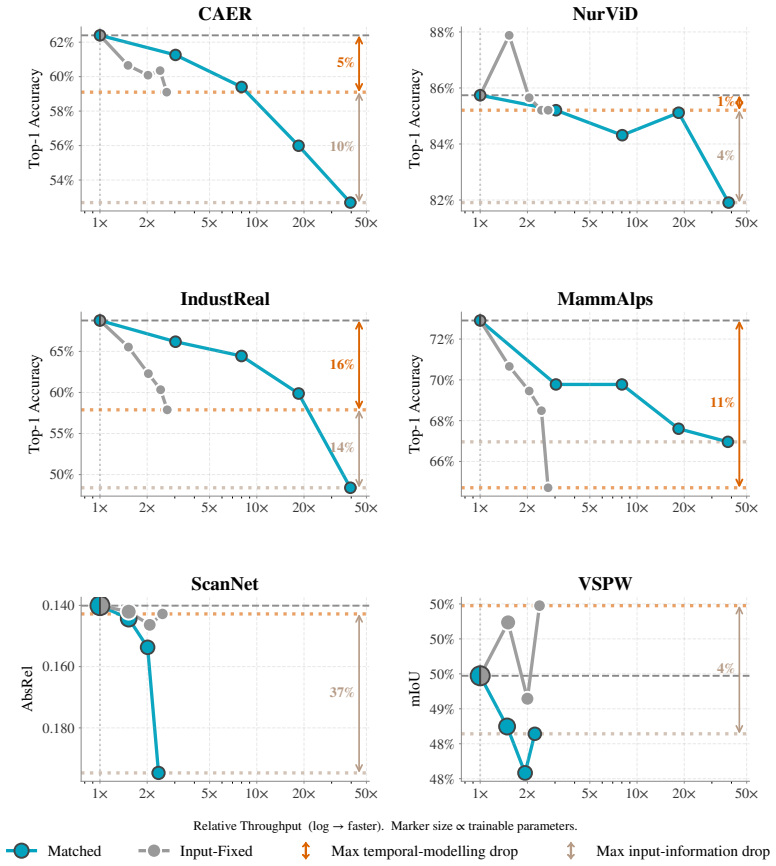
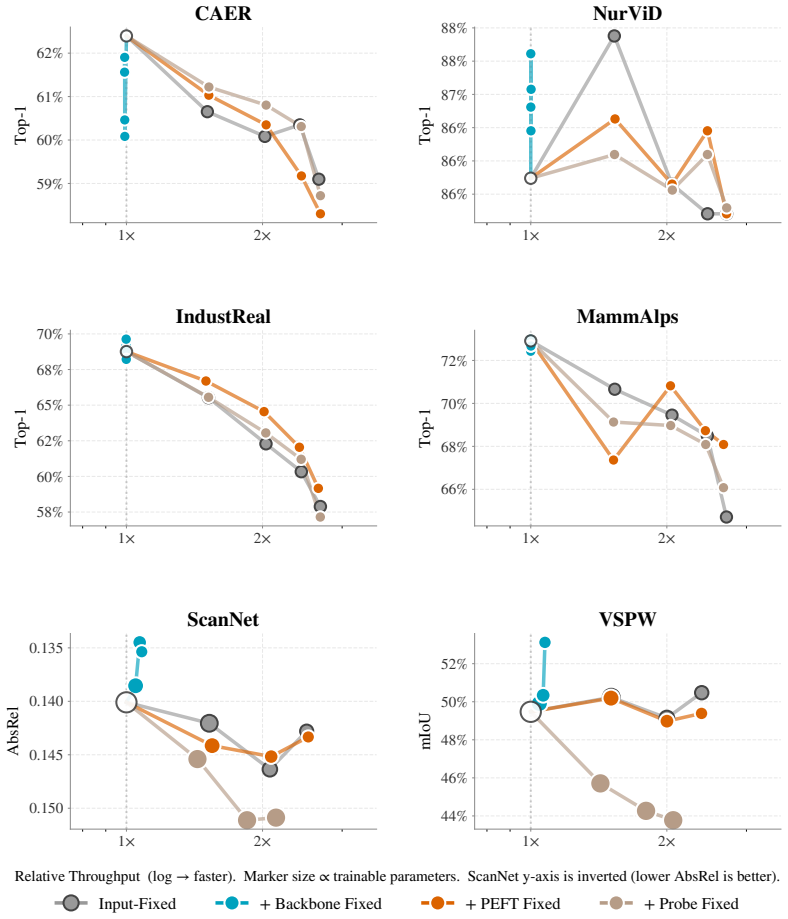
Systematic comparison of PEFT and probing strategies shows that temporal context allocation across the backbone, the adapter modules and the probe determines adaptation effectiveness in low-resource video settings, with the best placement depending on whether tasks emphasize appearance, motion or spatial density.
What carries the argument
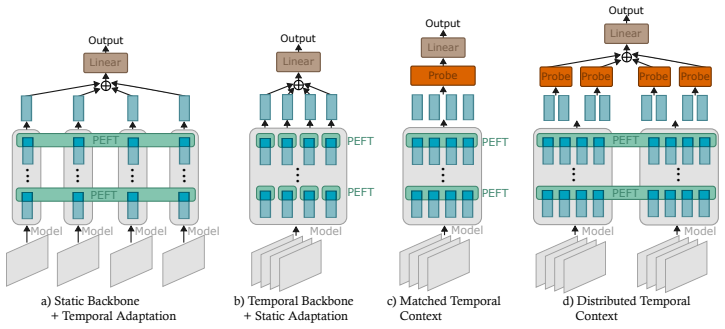
Distribution of temporal reasoning across backbone, PEFT adapter and task probe during model adaptation.
If this is right
- Confining temporal reasoning to only one model component reduces adaptation performance across the tested task categories.
- Different task types benefit from temporal context placed in different locations among backbone, PEFT and probe.
- Direct comparison of image-pretrained and video-pretrained representations under the same PEFT regimes reveals setting-specific differences.
- In data-scarce conditions, selective temporal allocation improves parameter-efficient adaptation more than uniform placement.
Where Pith is reading between the lines
- Designers of future video foundation models could expose separate temporal modules at each stage to allow task-specific allocation.
- The allocation principle may extend to other temporal modalities such as audio or time-series sensor data.
- Similar studies on larger-scale models or additional low-resource regimes could test whether the observed patterns persist.
Load-bearing premise
The chosen appearance-focused, motion-focused and spatially dense tasks together with the tested low-resource regimes are representative enough for the allocation conclusions to generalize.
What would settle it
Re-running the adaptation experiments on a new video dataset or task type outside the evaluated set and finding that the previously optimal temporal allocations no longer produce the best results.
Figures
read the original abstract
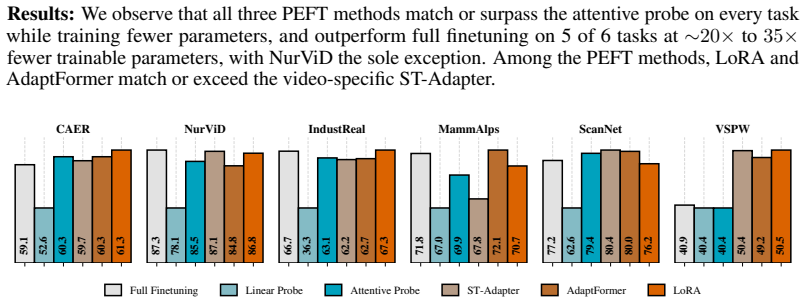
Parameter-efficient fine-tuning (PEFT) and probing enable adaptation of foundation models using only a small number of trainable parameters, making it attractive for video understanding where annotation and computation are expensive. However, video PEFT has focused on adapting image-pretrained models, while standard PEFT methods can also be applied to video representations. These settings are rarely compared and both confine temporal reasoning to a single component of the model, leaving open how temporal context should be distributed across backbone, PEFT and probe. In this work we provide a systematic study of model adaptation strategies for video understanding. We evaluate methods across appearance-focused, motion-focused and spatially dense settings, with a particular focus on scenarios with limited data where parameter-efficiency is most beneficial. Our results provide new insights into PEFT and probing across settings and demonstrate the importance of temporal context allocation for effective video adaptation
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a systematic empirical study of parameter-efficient fine-tuning (PEFT) and probing strategies for adapting foundation models to low-resource video understanding tasks. It compares image-pretrained and video models, evaluates adaptation across appearance-focused, motion-focused, and spatially dense settings, and examines how temporal context should be allocated among the backbone, PEFT modules, and probe.
Significance. If the empirical results hold under broader validation, the work supplies actionable guidance on temporal context allocation for efficient video adaptation in data-scarce regimes, an area where annotation and compute costs are high. It bridges PEFT literature from images to video and highlights setting-dependent differences in adaptation effectiveness.
major comments (1)
- [Evaluation and Results sections] The central claim that the study demonstrates the 'importance of temporal context allocation' for effective video adaptation rests on the representativeness of the selected appearance-focused, motion-focused, and spatially dense tasks plus the specific low-resource regimes. The manuscript provides no explicit diversity arguments, controls for motion-versus-appearance emphasis, or cross-dataset validation to show these choices generalize beyond the evaluated models and datasets; this directly affects whether the allocation insights are setting-specific or broadly applicable.
minor comments (1)
- [Abstract] The abstract states that the study supplies 'new insights' and 'demonstrate[s] the importance' of temporal allocation but contains no quantitative results, error bars, dataset sizes, or exclusion criteria, which delays assessment of claim strength until the full text is read.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our empirical study. We address the major comment point by point below.
read point-by-point responses
-
Referee: [Evaluation and Results sections] The central claim that the study demonstrates the 'importance of temporal context allocation' for effective video adaptation rests on the representativeness of the selected appearance-focused, motion-focused, and spatially dense tasks plus the specific low-resource regimes. The manuscript provides no explicit diversity arguments, controls for motion-versus-appearance emphasis, or cross-dataset validation to show these choices generalize beyond the evaluated models and datasets; this directly affects whether the allocation insights are setting-specific or broadly applicable.
Authors: We acknowledge that the manuscript does not include explicit cross-dataset validation, additional controls isolating motion-versus-appearance emphasis, or formal diversity arguments for task selection. The evaluated tasks were chosen as standard benchmarks representative of the three categories (appearance-focused, motion-focused, and dense), following categorizations common in prior video understanding literature. We will revise the Evaluation section to add a dedicated paragraph providing these justifications, citing relevant prior works on task categorization, and explicitly framing the temporal allocation insights as setting-dependent rather than claiming broad generalizability. This addresses the concern through added discussion without new experiments. revision: partial
Circularity Check
No significant circularity in empirical evaluation study
full rationale
This is an empirical study that evaluates PEFT, probing, and temporal context allocation across appearance-focused, motion-focused, and spatially dense video tasks in low-resource regimes. No equations, derivations, or self-referential reductions are present; claims rest on experimental comparisons rather than any fitted parameter renamed as prediction or self-citation chain that collapses to the input. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard i.i.d. train/val/test splits and task definitions in video understanding benchmarks are sufficient to draw allocation conclusions.
Reference graph
Works this paper leans on
-
[1]
Vivit: A video vision transformer
Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lu ˇci´c, and Cordelia Schmid. Vivit: A video vision transformer. InIEEE/CVF International Conference on Computer Vision (ICCV), pages 6836–6846, 2021
2021
-
[2]
Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Mojtaba Komeili, Matthew J. Muckley, Ammar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, Sergio Arnaud, Abha Gejji, Ada Martin, Francois Robert Hogan, Daniel Dugas, Piotr Bojanowski, Vasil Khalidov, Patrick Labatut, Francisco Massa, Marc Szafraniec, Kapil Krishnakumar, Yong Li, X...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Revisiting feature prediction for learning visual representations from video.Transactions on Machine Learning Research, 2024
Adrien Bardes, Quentin Garrido, Jean Ponce, Xinlei Chen, Michael Rabbat, Yann LeCun, Mido Assran, and Nicolas Ballas. Revisiting feature prediction for learning visual representations from video.Transactions on Machine Learning Research, 2024
2024
-
[4]
Strong baselines for parameter- efficient few-shot fine-tuning
Samyadeep Basu, Shell Hu, Daniela Massiceti, and Soheil Feizi. Strong baselines for parameter- efficient few-shot fine-tuning. InAAAI Conference on Artificial Intelligence (AAAI), pages 11024–11031, 2024
2024
-
[5]
Peft-bench: A parameter- efficient fine-tuning methods benchmark
Robert Belanec, Branislav Pecher, Ivan Srba, and Maria Bielikova. Peft-bench: A parameter- efficient fine-tuning methods benchmark. InConference of the European Chapter of the Association for Computational Linguistics (EACL), pages 3035–3054, 2026
2026
-
[6]
Is space-time attention all you need for video understanding? InInternational Conference on Machine Learning (ICML), pages 813–824
Gedas Bertasius, Heng Wang, and Lorenzo Torresani. Is space-time attention all you need for video understanding? InInternational Conference on Machine Learning (ICML), pages 813–824. PMLR, 2021
2021
-
[7]
On the Opportunities and Risks of Foundation Models
Rishi Bommasani, Drew A. Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S. Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, Erik Brynjolfsson, S. Buch, Dallas Card, Rodrigo Castellon, Niladri S. Chatterji, Annie S. Chen, Kathleen A. Creel, Jared Davis, Dora Demszky, Chris Donahue, Moussa Koulako Bala Doumbouya, Esin Du...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InIEEE/CVF International Conference on Computer Vision (ICCV), pages 9650–9660, 2021. 10
2021
-
[9]
João Carreira, Dilara Gokay, Michael King, Chuhan Zhang, Ignacio Rocco, Aravindh Mahen- dran, Thomas Albert Keck, Joseph Heyward, Skanda Koppula, Etienne Pot, Goker Erdogan, Yana Hasson, Yi Yang, Klaus Greff, Guillaume Le Moing, Sjoerd van Steenkiste, Daniel Zoran, Drew A. Hudson, Pedro V’elez, Luisa F. Polan’ia, Luke Friedman, Chris Duvarney, Ross Gorosh...
-
[10]
Vl-jepa: Joint embedding predictive architecture for vision-language
Delong Chen, Mustafa Shukor, Theo Moutakanni, Willy Chung, Jade Yu, Tejaswi Kasarla, Yejin Bang, Allen Bolourchi, Yann LeCun, and Pascale Fung. Vl-jepa: Joint embedding predictive architecture for vision-language. InInternational Conference on Learning Representations (ICLR), 2026
2026
-
[11]
Adaptformer: Adapting vision transformers for scalable visual recognition
Shoufa Chen, Chongjian Ge, Zhan Tong, Jiangliu Wang, Yibing Song, Jue Wang, and Ping Luo. Adaptformer: Adapting vision transformers for scalable visual recognition. InAdvances in Neural Information Processing Systems (NeurIPS), pages 16664–16678, 2022
2022
-
[12]
Video depth anything: Consistent depth estimation for super-long videos
Sili Chen, Hengkai Guo, Shengnan Zhu, Feihu Zhang, Zilong Huang, Jiashi Feng, and Bingyi Kang. Video depth anything: Consistent depth estimation for super-long videos. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 22831–22840, 2025
2025
-
[13]
Context autoencoder for self-supervised representation learning.International Journal of Computer Vision (IJCV), 132(1):208–223, 2024
Xiaokang Chen, Mingyu Ding, Xiaodi Wang, Ying Xin, Shentong Mo, Yunhao Wang, Shumin Han, Ping Luo, Gang Zeng, and Jingdong Wang. Context autoencoder for self-supervised representation learning.International Journal of Computer Vision (IJCV), 132(1):208–223, 2024
2024
-
[14]
Randaugment: Practical automated data augmentation with a reduced search space
Ekin D Cubuk, Barret Zoph, Jonathon Shlens, and Quoc V Le. Randaugment: Practical automated data augmentation with a reduced search space. InIEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 702–703, 2020
2020
-
[15]
Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner
Angela Dai, Angel X. Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017
2017
-
[16]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 248–255, 2009
2009
-
[17]
Parameter- efficient fine-tuning of large-scale pre-trained language models.Nature Machine Intelligence, 5 (3):220–235, 2023
Ning Ding, Yujia Qin, Guang Yang, Fuchao Wei, Zonghan Yang, Yusheng Su, Shengding Hu, Yulin Chen, Chi-Min Chan, Weize Chen, Jing Yi, Weilin Zhao, Xiaozhi Wang, Zhiyuan Liu, Hai-Tao Zheng, Jianfei Chen, Yang Liu, Jie Tang, Juanzi Li, and Maosong Sun. Parameter- efficient fine-tuning of large-scale pre-trained language models.Nature Machine Intelligence, 5 ...
2023
-
[18]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations (ICLR), 2021
2021
-
[19]
Scalable pre-training of large autoregressive image models
Alaaeldin El-Nouby, Michal Klein, Shuangfei Zhai, Miguel Angel Bautista, Vaishaal Shankar, Alexander Toshev, Joshua M Susskind, and Armand Joulin. Scalable pre-training of large autoregressive image models. InInternational Conference on Machine Learning (ICML), pages 12371–12384. PMLR, 2024
2024
-
[20]
Mammalps: A multi-view video behavior monitoring dataset of wild mammals in the swiss alps
Valentin Gabeff, Haozhe Qi, Brendan Flaherty, Gencer Sumbul, Alexander Mathis, and Devis Tuia. Mammalps: A multi-view video behavior monitoring dataset of wild mammals in the swiss alps. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13854–13864, 2025
2025
-
[21]
something something
Raghav Goyal, Samira Ebrahimi Kahou, Vincent Michalski, Joanna Materzynska, Susanne Westphal, Heuna Kim, Valentin Haenel, Ingo Fruend, Peter Yianilos, Moritz Mueller-Freitag, Florian Hoppe, Christian Thurau, Ingo Bax, and Roland Memisevic. The" something something" video database for learning and evaluating visual common sense. InIEEE International Confer...
2017
-
[22]
Sun, Skanda Koppula, Dilara Gokay, Joseph Heyward, Etienne Pot, and Andrew Zisserman
Yana Hasson, Pauline Luc, Liliane Momeni, Maks Ovsjanikov, Guillaume Le Moing, Alina Kuznetsova, Ira Ktena, Jennifer J. Sun, Skanda Koppula, Dilara Gokay, Joseph Heyward, Etienne Pot, and Andrew Zisserman. Scivid: Cross-domain evaluation of video models in scientific applications. InIEEE/CVF International Conference on Computer Vision (ICCV), pages 21800–...
2025
-
[23]
Parameter-efficient transfer learning for nlp
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for nlp. InInternational Conference on Machine Learning (ICML), pages 2790–2799. PMLR, 2019
2019
-
[24]
Lora: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. In International Conference on Learning Representations (ICLR), 2022
2022
-
[25]
Nurvid: A large expert-level video database for nursing procedure activity understanding
Ming Hu, Lin Wang, Siyuan Yan, Don Ma, Qingli Ren, Peng Xia, Wei Feng, Peibo Duan, Lie Ju, and Zongyuan Ge. Nurvid: A large expert-level video database for nursing procedure activity understanding. InAdvances in Neural Information Processing Systems (NeurIPS), pages 18146–18164, 2023
2023
-
[26]
Visual prompt tuning
Menglin Jia, Luming Tang, Bor-Chun Chen, Claire Cardie, Serge Belongie, Bharath Hariharan, and Ser-Nam Lim. Visual prompt tuning. InEuropean Conference on Computer Vision (ECCV), pages 709–727. Springer, 2022
2022
-
[27]
Fact: Factor-tuning for lightweight adaptation on vision transformer
Shibo Jie and Zhi-Hong Deng. Fact: Factor-tuning for lightweight adaptation on vision transformer. InAAAI Conference on Artificial Intelligence (AAAI), pages 1060–1068, 2023
2023
-
[28]
Convolutional bypasses are better vision transformer adapters
Shibo Jie, Zhi-Hong Deng, Shixuan Chen, and Zhijuan Jin. Convolutional bypasses are better vision transformer adapters. InEuropean Conference on Artificial Intelligence (ECAI). IOS Press, 2024
2024
-
[29]
The Kinetics Human Action Video Dataset
Will Kay, João Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijaya- narasimhan, Fabio Viola, Tim Green, Trevor Back, Apostol Natsev, Mustafa Suleyman, and Andrew Zisserman. The kinetics human action video dataset.arXiv preprint arXiv:1705.06950, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[30]
Do better imagenet models transfer better? InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2661–2671, 2019
Simon Kornblith, Jonathon Shlens, and Quoc V Le. Do better imagenet models transfer better? InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2661–2671, 2019
2019
-
[31]
Hmdb: a large video database for human motion recognition
Hildegard Kuehne, Hueihan Jhuang, Estíbaliz Garrote, Tomaso Poggio, and Thomas Serre. Hmdb: a large video database for human motion recognition. InIEEE International Conference on Computer Vision (ICCV), pages 2556–2563, 2011
2011
-
[32]
Context-aware emotion recognition networks
Jiyoung Lee, Seungryong Kim, Sunok Kim, Jungin Park, and Kwanghoon Sohn. Context-aware emotion recognition networks. InIEEE/CVF International Conference on Computer Vision (ICCV), pages 10143–10152, 2019
2019
-
[33]
The power of scale for parameter-efficient prompt tuning
Brian Lester, Rami Al-Rfou, and Noah Constant. The power of scale for parameter-efficient prompt tuning. InConference on Empirical Methods in Natural Language Processing (EMNLP), pages 3045–3059, 2021
2021
-
[34]
Prefix-tuning: Optimizing continuous prompts for generation
Xiang Lisa Li and Percy Liang. Prefix-tuning: Optimizing continuous prompts for generation. InAnnual Meeting of the Association for Computational Linguistics (ACL), pages 4582–4597, 2021
2021
-
[35]
Xinhao Li, Zhenpeng Huang, Jing Wang, Kunchang Li, and Limin Wang. Videoeval: Compre- hensive benchmark suite for low-cost evaluation of video foundation model.arXiv preprint arXiv:2407.06491, 2024
-
[36]
Scaling & shifting your features: A new baseline for efficient model tuning
Dongze Lian, Daquan Zhou, Jiashi Feng, and Xinchao Wang. Scaling & shifting your features: A new baseline for efficient model tuning. InAdvances in Neural Information Processing Systems (NeurIPS), pages 109–123, 2022. 12
2022
-
[37]
Frozen clip models are efficient video learners
Ziyi Lin, Shijie Geng, Renrui Zhang, Peng Gao, Gerard De Melo, Xiaogang Wang, Jifeng Dai, Yu Qiao, and Hongsheng Li. Frozen clip models are efficient video learners. InEuropean Conference on Computer Vision (ECCV), pages 388–404. Springer, 2022
2022
-
[38]
Dora: Weight-decomposed low-rank adaptation
Shih-Yang Liu, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu-Chiang Frank Wang, Kwang-Ting Cheng, and Min-Hung Chen. Dora: Weight-decomposed low-rank adaptation. In International Conference on Machine Learning (ICML). PMLR, 2024
2024
-
[39]
From static to dynamic: Exploring self-supervised image-to-video representation transfer learning
Yang Liu, Qianqian Xu, Peisong Wen, Siran Dai, Xilin Zhao, and Qingming Huang. From static to dynamic: Exploring self-supervised image-to-video representation transfer learning. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026
2026
-
[40]
Gen Luo, Minglang Huang, Yiyi Zhou, Xiaoshuai Sun, Guannan Jiang, Zhiyu Wang, and Rongrong Ji. Towards efficient visual adaption via structural re-parameterization.arXiv preprint arXiv:2302.08106, 2023
-
[41]
Lessons and insights from a unifying study of parameter-efficient fine- tuning (peft) in visual recognition
Zheda Mai, Ping Zhang, Cheng-Hao Tu, Hong-You Chen, Quang-Huy Nguyen, Li Zhang, and Wei-Lun Chao. Lessons and insights from a unifying study of parameter-efficient fine- tuning (peft) in visual recognition. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14845–14857, 2025
2025
-
[42]
Vspw: A large-scale dataset for video scene parsing in the wild
Jiaxu Miao, Yunchao Wei, Yu Wu, Chen Liang, Guangrui Li, and Yi Yang. Vspw: A large-scale dataset for video scene parsing in the wild. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4133–4143, 2021
2021
-
[43]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel HAZIZA, Francisco Massa, Alaaeldin El-Nouby, Mido Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herve Jegou, Julien Mairal, Patrick L...
2024
-
[44]
St-adapter: Parameter- efficient image-to-video transfer learning
Junting Pan, Ziyi Lin, Xiatian Zhu, Jing Shao, and Hongsheng Li. St-adapter: Parameter- efficient image-to-video transfer learning. InAdvances in Neural Information Processing Systems (NeurIPS), pages 26462–26477, 2022
2022
-
[45]
Dual-path adaptation from image to video transformers
Jungin Park, Jiyoung Lee, and Kwanghoon Sohn. Dual-path adaptation from image to video transformers. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2203–2213, 2023
2023
-
[46]
Adapterfusion: Non-destructive task composition for transfer learning
Jonas Pfeiffer, Aishwarya Kamath, Andreas Rücklé, Kyunghyun Cho, and Iryna Gurevych. Adapterfusion: Non-destructive task composition for transfer learning. InConference of the European Chapter of the Association for Computational Linguistics (EACL), pages 487–503, 2021
2021
-
[47]
Frame2freq: Spectral adapters for fine-grained video understanding.IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026
Thinesh Thiyakesan Ponbagavathi, Constantin Seibold, and Alina Roitberg. Frame2freq: Spectral adapters for fine-grained video understanding.IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026
2026
-
[48]
Attention, please! revisiting attentive probing through the lens of efficiency
Bill Psomas, Dionysis Christopoulos, Eirini Baltzi, Ioannis Kakogeorgiou, Tilemachos Aravanis, Nikos Komodakis, Konstantinos Karantzalos, Yannis Avrithis, and Giorgos Tolias. Attention, please! revisiting attentive probing through the lens of efficiency. InInternational Conference on Learning Representations (ICLR), 2026
2026
-
[49]
Disentangling spatial and temporal learning for efficient image-to-video transfer learning
Zhiwu Qing, Shiwei Zhang, Ziyuan Huang, Yingya Zhang, Changxin Gao, Deli Zhao, and Nong Sang. Disentangling spatial and temporal learning for efficient image-to-video transfer learning. InIEEE/CVF International Conference on Computer Vision (ICCV), pages 13934–13944, 2023
2023
-
[50]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InInterna- tional Conference on Machine Learning (ICML), pages 8748–8763. PMLR, 2021. 13
2021
-
[51]
Vision transformers for dense prediction
René Ranftl, Alexey Bochkovskiy, and Vladlen Koltun. Vision transformers for dense prediction. InIEEE/CVF International Conference on Computer Vision (ICCV), pages 12179–12188, 2021
2021
-
[52]
Imagenet-21k pretraining for the masses
Tal Ridnik, Emanuel Ben-Baruch, Asaf Noy, and Lihi Zelnik-Manor. Imagenet-21k pretraining for the masses. InAdvances in Neural Information Processing Systems (NeurIPS), 2021
2021
-
[53]
Schoonbeek, Tim Houben, Hans Onvlee, Peter H.N
Tim J. Schoonbeek, Tim Houben, Hans Onvlee, Peter H.N. de With, and Fons van der Sommen. Industreal: A dataset for procedure step recognition handling execution errors in egocentric videos in an industrial-like setting. InIEEE/CVF Winter Conference on Applications of Com- puter Vision (WACV), pages 4365–4374, 2024
2024
-
[54]
Laion-5b: An open large-scale dataset for training next generation image-text models
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, Patrick Schramowski, Srivatsa Kundurthy, Katherine Crowson, Ludwig Schmidt, Robert Kaczmarczyk, and Jenia Jitsev. Laion-5b: An open large-scale dataset for training next generation image-text models....
2022
-
[55]
Oriane Siméoni, Huy V . V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seung Eun Yi, Michael Ramamonjisoa, Francisco Massa, Daniel HAZIZA, Luca Wehrstedt, Jianyuan Wang, Timothée Darcet, Théo Moutakanni, Leonel Sentana, Claire Roberts, Andrea Vedaldi, Jamie Tolan, John Brandt, Camille Couprie, Juli...
2026
-
[56]
How severe is benchmark-sensitivity in video self-supervised learning? InEuropean Conference on Computer Vision (ECCV), pages 632–652
Fida Mohammad Thoker, Hazel Doughty, Piyush Bagad, and Cees GM Snoek. How severe is benchmark-sensitivity in video self-supervised learning? InEuropean Conference on Computer Vision (ECCV), pages 632–652. Springer, 2022
2022
-
[57]
Fida Mohammad Thoker, Letian Jiang, Chen Zhao, Piyush Bagad, Hazel Doughty, Bernard Ghanem, and Cees GM Snoek. Severe++: Evaluating benchmark sensitivity in generalization of video representation learning.arXiv preprint arXiv:2504.05706, 2025
-
[58]
Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training
Zhan Tong, Yibing Song, Jue Wang, and Limin Wang. Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[59]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alab- dulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, Olivier H’enaff, Jeremiah Harmsen, Andreas Steiner, and Xiaohua Zhai. Siglip 2: Multilingual vision- language encoders with improved semantic understanding, localization, and dense features...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[60]
Canonical rank adaptation: An efficient fine-tuning strategy for vision transformers
Lokesh Veeramacheneni, Moritz Wolter, Hilde Kuehne, and Juergen Gall. Canonical rank adaptation: An efficient fine-tuning strategy for vision transformers. InInternational Conference on Machine Learning (ICML). PMLR, 2025
2025
-
[61]
Internvideo-next: Towards world-understanding video models
Chenting Wang, Yuhan Zhu, Yicheng Xu, Jiange Yang, Ziang Yan, Yali Wang, Yi Wang, and Limin Wang. Internvideo-next: Towards world-understanding video models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 16966–16976, 2026
2026
-
[62]
Videomae v2: Scaling video masked autoencoders with dual masking
Limin Wang, Bingkun Huang, Zhiyu Zhao, Zhan Tong, Yinan He, Yi Wang, Yali Wang, and Yu Qiao. Videomae v2: Scaling video masked autoencoders with dual masking. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14549–14560, 2023
2023
-
[63]
InternVideo: General Video Foundation Models via Generative and Discriminative Learning
Yi Wang, Kunchang Li, Yizhuo Li, Yinan He, Bingkun Huang, Zhiyu Zhao, Hongjie Zhang, Jilan Xu, Yi Liu, Zun Wang, Sen Xing, Guo Chen, Junting Pan, Jiashuo Yu, Yali Wang, Limin Wang, and Yu Qiao. Internvideo: General video foundation models via generative and discriminative learning.arXiv preprint arXiv:2212.03191, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[64]
Internvideo2: Scaling foundation models for 14 multimodal video understanding
Yi Wang, Kunchang Li, Xinhao Li, Jiashuo Yu, Yinan He, Guo Chen, Baoqi Pei, Rongkun Zheng, Zun Wang, Yansong Shi, Tianxiang Jiang, Songze Li, Jilan Xu, Hongjie Zhang, Yifei Huang, Yu Qiao, Yali Wang, and Limin Wang. Internvideo2: Scaling foundation models for 14 multimodal video understanding. InEuropean Conference on Computer Vision (ECCV), pages 396–416...
2024
-
[65]
Attention to the burstiness in visual prompt tuning! InIEEE/CVF International Conference on Computer Vision (ICCV), pages 4253–4263, 2025
Yuzhu Wang, Manni Duan, and Shu Kong. Attention to the burstiness in visual prompt tuning! InIEEE/CVF International Conference on Computer Vision (ICCV), pages 4253–4263, 2025
2025
-
[66]
Difffit: Unlocking transferability of large diffusion models via simple parameter-efficient fine-tuning
Enze Xie, Lewei Yao, Han Shi, Zhili Liu, Daquan Zhou, Zhaoqiang Liu, Jiawei Li, and Zhenguo Li. Difffit: Unlocking transferability of large diffusion models via simple parameter-efficient fine-tuning. InIEEE/CVF International Conference on Computer Vision (ICCV), pages 4230– 4239, 2023
2023
-
[67]
V-petl bench: A unified visual parameter- efficient transfer learning benchmark
Yi Xin, Siqi Luo, Xuyang Liu, Yuntao Du., Haodi Zhou, Xinyu Cheng, Christina Luoluo Lee, Junlong Du, Haozhe Wang, MingCai Chen, Ting Liu, Guimin Hu, Zhongwei Wan, Rongchao Zhang, Aoxue Li, Mingyang Yi, and Xiaohong Liu. V-petl bench: A unified visual parameter- efficient transfer learning benchmark. InAdvances in Neural Information Processing Systems (Neu...
2024
-
[68]
Yi Xin, Jianjiang Yang, Siqi Luo, Yuntao Du, Qi Qin, Kangrui Cen, Yangfan He, Zhiwei Zhang, Bin Fu, Xiaokang Yang, Guangtao Zhai, Ming-Hsuan Yang, and Xiaohong Liu. Parameter- efficient fine-tuning for pre-trained vision models: A survey and benchmark.arXiv preprint arXiv:2402.02242, 2024
-
[69]
Aim: Adapting image models for efficient video action recognition
Taojiannan Yang, Yi Zhu, Yusheng Xie, Aston Zhang, Chen Chen, and Mu Li. Aim: Adapting image models for efficient video action recognition. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[70]
VideoGLUE: Video general understanding evaluation of foundation models.Transactions on Machine Learning Research, 2024
Liangzhe Yuan, Nitesh Bharadwaj Gundavarapu, Long Zhao, Hao Zhou, Yin Cui, Lu Jiang, Xuan Yang, Menglin Jia, Tobias Weyand, Luke Friedman, Mikhail Sirotenko, Huisheng Wang, Florian Schroff, Hartwig Adam, Ming-Hsuan Yang, Ting Liu, and Boqing Gong. VideoGLUE: Video general understanding evaluation of foundation models.Transactions on Machine Learning Resea...
2024
-
[71]
Bitfit: Simple parameter-efficient fine- tuning for transformer-based masked language-models
Elad Ben Zaken, Yoav Goldberg, and Shauli Ravfogel. Bitfit: Simple parameter-efficient fine- tuning for transformer-based masked language-models. InAnnual Meeting of the Association for Computational Linguistics (ACL), 2022
2022
-
[72]
Visual fourier prompt tuning
Runjia Zeng, Cheng Han, Qifan Wang, Chunshu Wu, Tong Geng, Lifu Huang, Ying N Wu, and Dongfang Liu. Visual fourier prompt tuning. InAdvances in Neural Information Processing Systems (NeurIPS), pages 5552–5585, 2024
2024
-
[73]
A Large-scale Study of Representation Learning with the Visual Task Adaptation Benchmark
Xiaohua Zhai, Joan Puigcerver, Alexander Kolesnikov, Pierre Ruyssen, Carlos Riquelme, Mario Lucic, Josip Djolonga, André Susano Pinto, Maxim Neumann, Alexey Dosovitskiy, Lucas Beyer, Olivier Bachem, Michael Tschannen, Marcin Michalski, Olivier Bousquet, Sylvain Gelly, and Neil Houlsby. A large-scale study of representation learning with the visual task ad...
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[74]
mixup: Beyond empirical risk minimization
Hongyi Zhang, Moustapha Cisse, Yann N Dauphin, and David Lopez-Paz. mixup: Beyond empirical risk minimization. InInternational Conference on Learning Representations (ICLR), 2018
2018
-
[75]
Adalora: Adaptive budget allocation for parameter- efficient fine-tuning
Qingru Zhang, Minshuo Chen, Alexander Bukharin, Nikos Karampatziakis, Pengcheng He, Yu Cheng, Weizhu Chen, and Tuo Zhao. Adalora: Adaptive budget allocation for parameter- efficient fine-tuning. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[76]
Low-resource vision challenges for foundation models
Yunhua Zhang, Hazel Doughty, and Cees GM Snoek. Low-resource vision challenges for foundation models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 21956–21966, 2024
2024
-
[77]
Dynamic tuning towards parameter and inference efficiency for vit adaptation
Wangbo Zhao, Jiasheng Tang, Yizeng Han, Yibing Song, Kai Wang, Gao Huang, Fan Wang, and Yang You. Dynamic tuning towards parameter and inference efficiency for vit adaptation. In Advances in Neural Information Processing Systems (NeurIPS), pages 114765–114796, 2024
2024
-
[78]
Random erasing data augmentation
Zhun Zhong, Liang Zheng, Guoliang Kang, Shaozi Li, and Yi Yang. Random erasing data augmentation. InAAAI Conference on Artificial Intelligence (AAAI), pages 13001–13008, 2020. 15
2020
-
[79]
Recurrent video masked autoencoders
Daniel Zoran, Nikhil Parthasarathy, Yi Yang, Drew A Hudson, João Carreira, and Andrew Zisserman. Recurrent video masked autoencoders. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 17744–17755, 2026. A Experiment Details A.1 Backbone All experiments use a InternVideo-Next [61] ViT-B backbone with patch size 14 and input res...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.