Divide and Contrast: Learning Robust Temporal Features without Augmentation
Pith reviewed 2026-05-21 05:13 UTC · model grok-4.3
The pith
Di-COT learns robust temporal features by contrasting substructures within time windows without augmentation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
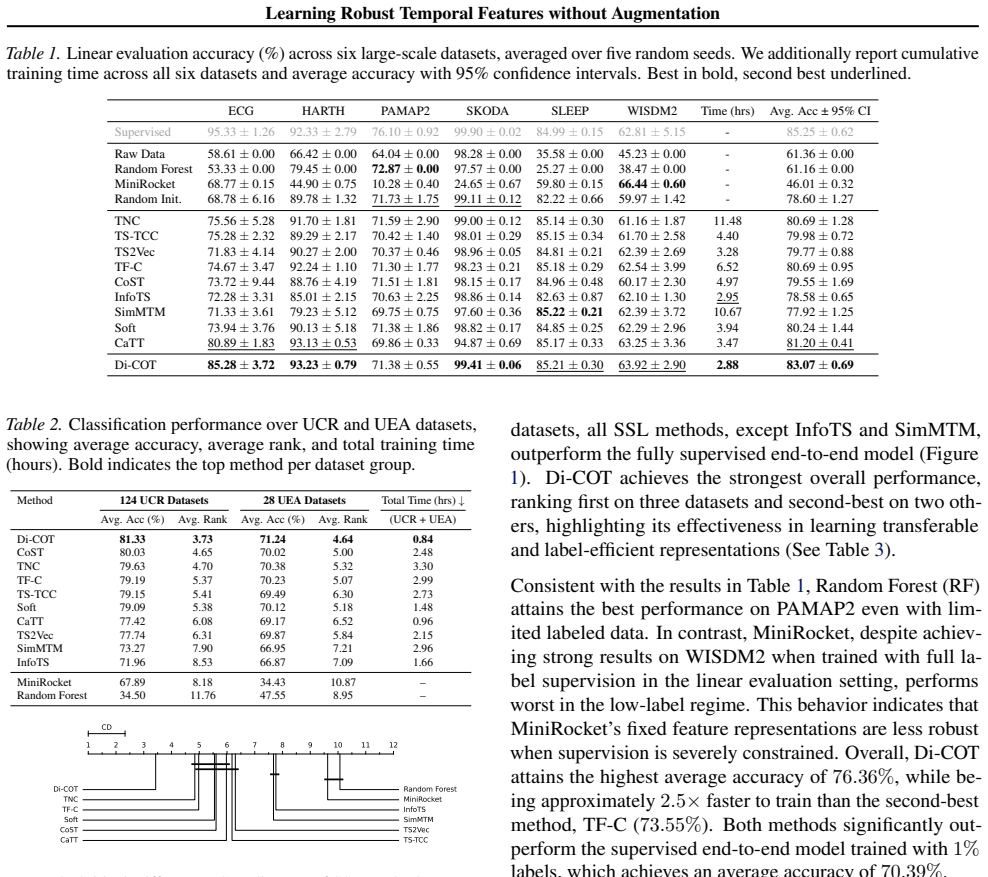
Di-COT stochastically partitions each window into a small number of overlapping sub-blocks per iteration, enabling efficient and meaningful contrast while mitigating false positives during temporal transitions. To improve scalability, the framework adopts a contrastive objective whose computation depends on the batch size and the number of sub-blocks, making loss computation independent of sequence length. Extensive experiments demonstrate that Di-COT learns semantically structured and transferable representations, achieving state-of-the-art performance on classification, clustering, kNN, and cross-dataset transfer, while substantially reducing training time.
What carries the argument
Stochastic partitioning of each time window into a small number of overlapping sub-blocks used as positive pairs for contrastive learning within the window.
Load-bearing premise
That stochastically partitioning each window into a small number of overlapping sub-blocks per iteration produces informative positive pairs that mitigate false positives during temporal transitions and yield better representations than timestep-level or augmentation-based contrast.
What would settle it
Running Di-COT and a timestep-level contrast baseline on a dataset with known abrupt temporal transitions and comparing the downstream classification or clustering accuracy to see if the sub-block approach loses its reported advantage.
Figures






read the original abstract
Self-supervised learning for time-series representation aims to reduce reliance on labeled data while maintaining strong downstream performance, yet many existing approaches incur high computational costs or rely on assumptions that do not hold across diverse temporal dynamics. In this work, we introduce Divide and Contrast (Di-COT), an unsupervised framework that avoids data augmentation and multiple encoder passes by contrasting informative substructures within a window rather than individual timesteps. Di-COT stochastically partitions each window into a small number of overlapping sub-blocks per iteration, enabling efficient and meaningful contrast while mitigating false positives during temporal transitions. To further improve scalability, we adopt a contrastive objective whose computation depends on the batch size and the number of sub-blocks, making loss computation independent of sequence length. Extensive experiments on six large-scale real-world datasets, as well as the UCR and UEA benchmarks, demonstrate that Di-COT learns semantically structured and transferable representations, achieving state-of-the-art performance on classification, clustering, $k$NN, and cross-dataset transfer, while substantially reducing training time. The source code is publicly available at https://github.com/sfi-norwai/Di-COT.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Divide and Contrast (Di-COT), an unsupervised self-supervised learning framework for time-series representation learning. It avoids data augmentation and multiple encoder passes by stochastically partitioning each input window into a small number of overlapping sub-blocks per iteration and contrasting these substructures. The contrastive objective is designed so that loss computation depends only on batch size and number of sub-blocks, making it independent of sequence length. The manuscript reports state-of-the-art results on classification, clustering, kNN, and cross-dataset transfer across six large-scale real-world datasets plus UCR/UEA benchmarks, together with substantially reduced training time; source code is released.
Significance. If the performance claims and efficiency gains hold under rigorous controls, the work offers a practically useful advance for scalable contrastive learning on long or non-stationary time series. The public code release and breadth of downstream tasks (classification, clustering, transfer) are positive factors that would support adoption and further research.
major comments (2)
- [§3.2] §3.2 (sub-block partitioning): the central claim that stochastic overlapping sub-block partitioning reliably produces semantically meaningful positive pairs while mitigating temporal-transition false positives is load-bearing for all reported gains in robustness and transfer; the manuscript provides no ablation that isolates this mechanism on explicitly non-stationary series with known transition points, leaving the skeptic concern unaddressed.
- [§5] §5 (experiments): the abstract and results tables assert SOTA performance, yet the text supplies insufficient detail on baseline implementations, hyper-parameter search budgets, statistical significance testing, or exact train/validation splits; without these controls the magnitude of the reported improvements cannot be confidently attributed to the proposed method rather than experimental setup.
minor comments (2)
- [Figure 2] Figure 2 and §4.1: the diagram of sub-block sampling would benefit from an explicit statement of the overlap ratio distribution and the precise sampling procedure used at each iteration.
- [§4.3] §4.3: the notation for the contrastive loss could be clarified by explicitly indexing the sub-block embeddings and confirming that the loss is indeed independent of original sequence length.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation of minor revision. We address each major comment below and outline the changes we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (sub-block partitioning): the central claim that stochastic overlapping sub-block partitioning reliably produces semantically meaningful positive pairs while mitigating temporal-transition false positives is load-bearing for all reported gains in robustness and transfer; the manuscript provides no ablation that isolates this mechanism on explicitly non-stationary series with known transition points, leaving the skeptic concern unaddressed.
Authors: We agree that a targeted ablation isolating the sub-block partitioning on synthetic non-stationary series with explicit transition points would provide stronger evidence for the mechanism. Although the six real-world datasets used in the paper contain non-stationary dynamics and temporal transitions (as reflected in the strong transfer and robustness results), we will add a new ablation study using controlled synthetic data with known change points in the revised manuscript to directly address this concern. revision: yes
-
Referee: [§5] §5 (experiments): the abstract and results tables assert SOTA performance, yet the text supplies insufficient detail on baseline implementations, hyper-parameter search budgets, statistical significance testing, or exact train/validation splits; without these controls the magnitude of the reported improvements cannot be confidently attributed to the proposed method rather than experimental setup.
Authors: We thank the referee for this observation. In the revised manuscript we will expand Section 5 and add a dedicated appendix that details: (i) exact baseline implementations and any modifications made, (ii) the hyper-parameter search ranges, budgets, and selection criteria, (iii) statistical significance tests (including p-values from paired t-tests or Wilcoxon signed-rank tests across multiple runs), and (iv) precise train/validation/test split definitions for every dataset. These additions will improve reproducibility and allow clearer attribution of gains to Di-COT. revision: yes
Circularity Check
No circularity; empirical method validated by external benchmarks
full rationale
The paper proposes Di-COT as a contrastive framework that partitions windows into overlapping sub-blocks to generate positive pairs without augmentation or multiple encoder passes. Central claims of semantically structured representations and SOTA results on classification, clustering, kNN, and transfer are presented as outcomes of experiments across six real-world datasets plus UCR/UEA benchmarks, not as quantities derived by construction from fitted parameters or prior self-citations. No equations, self-definitional loops, or load-bearing self-citations appear in the abstract or described method; the loss independence from sequence length is a direct consequence of the chosen objective (batch size and sub-block count), which is an explicit design choice rather than a renamed fit. The derivation chain is therefore self-contained against external validation.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Di-COT stochastically partitions each window into a small number of overlapping sub-blocks per iteration... Temporally adjacent sub-blocks are treated as positive pairs... LCE = −1/Bk ∑ log[exp(Sj,p*(j)) / ∑ exp(Sj,p)]
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery and 8-tick period forcing unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
loss computation independent of sequence length... k ≪ T by design
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
Learning Representations by Back-Propagating Errors , author =. Nature , volume =
-
[3]
Proceedings of the 10th European Conference on Artificial Intelligence (ECAI) , pages =
Planning as Satisfiability , author =. Proceedings of the 10th European Conference on Artificial Intelligence (ECAI) , pages =
-
[4]
Artificial Intelligence , volume =
Collaborative Plans for Complex Group Action , author =. Artificial Intelligence , volume =
- [5]
-
[6]
Causality , author =
-
[7]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[8]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
- [9]
-
[10]
International conference on machine learning , pages=
A simple framework for contrastive learning of visual representations , author=. International conference on machine learning , pages=. 2020 , organization=
work page 2020
-
[11]
Representation Learning with Contrastive Predictive Coding
Representation learning with contrastive predictive coding , author=. arXiv preprint arXiv:1807.03748 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
International Conference on Learning Representations , year=
Unsupervised Representation Learning for Time Series with Temporal Neighborhood Coding , author=. International Conference on Learning Representations , year=
-
[13]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Momentum contrast for unsupervised visual representation learning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[14]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Ts2vec: Towards universal representation of time series , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[15]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Time series contrastive learning with information-aware augmentations , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[16]
Advances in neural information processing systems , volume=
Improved deep metric learning with multi-class n-pair loss objective , author=. Advances in neural information processing systems , volume=
-
[17]
A Wiley-Interscience Publication , year=
The finite difference method in partial differential equations , author=. A Wiley-Interscience Publication , year=
-
[18]
2006 IEEE computer society conference on computer vision and pattern recognition (CVPR'06) , volume=
Dimensionality reduction by learning an invariant mapping , author=. 2006 IEEE computer society conference on computer vision and pattern recognition (CVPR'06) , volume=. 2006 , organization=
work page 2006
-
[19]
Language Models are Few-Shot Learners
Language models are few-shot learners , author=. arXiv preprint arXiv:2005.14165 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[20]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Facenet: A unified embedding for face recognition and clustering , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[21]
Noise-contrastive estimation: A new estimation principle for unnormalized statistical models , author=. Proceedings of the thirteenth international conference on artificial intelligence and statistics , pages=. 2010 , organization=
work page 2010
-
[22]
International Conference on Learning Representations , year=
Representation Learning via Invariant Causal Mechanisms , author=. International Conference on Learning Representations , year=
-
[23]
European conference on computer vision , pages=
Decoupled contrastive learning , author=. European conference on computer vision , pages=. 2022 , organization=
work page 2022
-
[24]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
With a little help from my friends: Nearest-neighbor contrastive learning of visual representations , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[25]
Pattern Recognition Letters , volume=
Mixing up contrastive learning: Self-supervised representation learning for time series , author=. Pattern Recognition Letters , volume=. 2022 , publisher=
work page 2022
-
[26]
Advances in Neural Information Processing Systems , volume=
Self-supervised contrastive pre-training for time series via time-frequency consistency , author=. Advances in Neural Information Processing Systems , volume=
-
[27]
Knowledge-Based Systems , volume=
Timeclr: A self-supervised contrastive learning framework for univariate time series representation , author=. Knowledge-Based Systems , volume=. 2022 , publisher=
work page 2022
-
[28]
The Twelfth International Conference on Learning Representations , year=
Soft Contrastive Learning for Time Series , author=. The Twelfth International Conference on Learning Representations , year=
-
[29]
Advances in neural information processing systems , volume=
Unsupervised scalable representation learning for multivariate time series , author=. Advances in neural information processing systems , volume=
-
[30]
International Conference on Machine Learning , pages=
Neighborhood contrastive learning applied to online patient monitoring , author=. International Conference on Machine Learning , pages=. 2021 , organization=
work page 2021
-
[31]
International Conference on Machine Learning , pages=
Clocs: Contrastive learning of cardiac signals across space, time, and patients , author=. International Conference on Machine Learning , pages=. 2021 , organization=
work page 2021
-
[32]
Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence,
Time-Series Representation Learning via Temporal and Contextual Contrasting , author =. Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence,
-
[33]
Gerald Woo and Chenghao Liu and Doyen Sahoo and Akshat Kumar and Steven Hoi , booktitle=. Co. 2022 , url=
work page 2022
-
[34]
Advances in neural information processing systems , volume=
Bootstrap your own latent-a new approach to self-supervised learning , author=. Advances in neural information processing systems , volume=
-
[35]
Emerging Properties in Self-Supervised Vision Transformers , author=. 2021 , eprint=
work page 2021
-
[36]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Exploring simple siamese representation learning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[37]
Engineering Applications of Artificial Intelligence , volume=
Self-supervised learning with randomized cross-sensor masked reconstruction for human activity recognition , author=. Engineering Applications of Artificial Intelligence , volume=. 2024 , publisher=
work page 2024
-
[38]
SimMTM: A Simple Pre-Training Framework for Masked Time-Series Modeling , author=. 2023 , eprint=
work page 2023
-
[39]
A Transformer-based Framework for Multivariate Time Series Representation Learning , author=. 2020 , eprint=
work page 2020
-
[40]
A Time Series is Worth 64 Words: Long-term Forecasting with Transformers , author=. 2023 , eprint=
work page 2023
-
[41]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Self-supervised learning from images with a joint-embedding predictive architecture , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[42]
DINOv2: Learning Robust Visual Features without Supervision
Dinov2: Learning robust visual features without supervision , author=. arXiv preprint arXiv:2304.07193 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Sensors (Basel, Switzerland) , volume=
HARTH: A Human Activity Recognition Dataset for Machine Learning , author=. Sensors (Basel, Switzerland) , volume=. 2021 , number =
work page 2021
-
[44]
Bell System Technical Journal , volume=
The measurement of power spectra from the point of view of communications engineering—Part I , author=. Bell System Technical Journal , volume=. 1958 , publisher=
work page 1958
-
[45]
Computers in Cardiology , pages=
A new method for detecting atrial fibrillation using R-R intervals , author=. Computers in Cardiology , pages=
-
[46]
Goldberger, Ary and Amaral, Luís and Glass, Leon and Hausdorff, Jeffrey and Ivanov, Plamen and Mark, Roger and Mietus, Joseph and Moody, George and Peng, Chung-Kang and Stanley, H. , year =. PhysioBank, PhysioToolkit, and PhysioNet : Components of a New Research Resource for Complex Physiologic Signals , volume =. Circulation , doi =
-
[47]
Representation Learning: A Review and New Perspectives , author=. 2014 , eprint=
work page 2014
-
[48]
Davies, David L. and Bouldin, Donald W. , journal=. A Cluster Separation Measure , year=
-
[49]
Communications in Statistics , volume=
A dendrite method for cluster analysis , author=. Communications in Statistics , volume=. 1974 , publisher=
work page 1974
-
[50]
Journal of Computational and Applied Mathematics , volume=
Silhouettes: A graphical aid to the interpretation and validation of cluster analysis , author=. Journal of Computational and Applied Mathematics , volume=. 1987 , publisher=
work page 1987
-
[51]
Advances in Neural Information Processing Systems , volume=
Simmtm: A simple pre-training framework for masked time-series modeling , author=. Advances in Neural Information Processing Systems , volume=
-
[52]
TimeDRL: Disentangled Representation Learning for Multivariate Time-Series , author=. 2024 , eprint=
work page 2024
-
[53]
Jufang Duan and Wei Zheng and Yangzhou Du and Wenfa Wu and Haipeng Jiang and Hongsheng Qi , booktitle=. 2024 , url=
work page 2024
-
[54]
Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting , author=. 2021 , eprint=
work page 2021
-
[55]
IEEE/CAA Journal of Automatica Sinica , volume=
The UCR time series archive , author=. IEEE/CAA Journal of Automatica Sinica , volume=. 2019 , publisher=
work page 2019
-
[56]
The UEA multivariate time series classification archive, 2018 , author=. 2018 , eprint=
work page 2018
-
[57]
Paparrizos, John and Boniol, Paul and Palpanas, Themis and Tsay, Ruey S and Elmore, Aaron and Franklin, Michael J , journal=. 2022 , publisher=
work page 2022
-
[58]
The Elephant in the Room: Towards A Reliable Time-Series Anomaly Detection Benchmark , author=. NeurIPS 2024 , year=
work page 2024
- [59]
-
[60]
Proceedings of the IEEE foundations and new directions of data mining workshop , pages=
A novel anomaly detection scheme based on principal component classifier , author=. Proceedings of the IEEE foundations and new directions of data mining workshop , pages=. 2003 , organization=
work page 2003
-
[61]
IEEE Transactions on Information Technology in Biomedicine , volume=
Wearable assistant for Parkinson’s disease patients with the freezing of gait symptom , author=. IEEE Transactions on Information Technology in Biomedicine , volume=. 2009 , publisher=
work page 2009
-
[62]
Anomaly detection and localization for cyber-physical production systems with self-organizing maps , author=. IMPROVE--Innovative Modelling Approaches for Production Systems to Raise Validatable Efficiency: Intelligent Methods for the Factory of the Future , pages=. 2018 , publisher=
work page 2018
-
[63]
Robust anomaly detection for multivariate time series through stochastic recurrent neural network , author=. Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining , pages=. 2019 , organization=
work page 2019
-
[64]
2016 International Workshop on Cyber-Physical Systems for Smart Water Networks (CySWater) , pages=
SWaT: A water treatment testbed for research and training on ICS security , author=. 2016 International Workshop on Cyber-Physical Systems for Smart Water Networks (CySWater) , pages=. 2016 , publisher=
work page 2016
-
[65]
Detecting spacecraft anomalies using LSTMs and nonparametric dynamic thresholding , author=. Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining , pages=. 2018 , organization=
work page 2018
-
[66]
GECCO Industrial Challenge 2018 Dataset: A water quality dataset for the ‘Internet of Things: Online Anomaly Detection for Drinking Water Quality’ competition at the Genetic and Evolutionary Computation Conference 2018, Kyoto, Japan , author=. 2018 , howpublished=
work page 2018
-
[67]
PhysioBank, PhysioToolkit, and PhysioNet: Components of a new research resource for complex physiologic signals , author=. Circulation , volume=. 2000 , publisher=
work page 2000
-
[68]
Tao , title=. n.d. , note=
-
[69]
Proceedings of the European Conference on Artificial Intelligence (ECAI) , series=
Contrast All The Time: Learning Time Series Representation from Temporal Consistency , author=. Proceedings of the European Conference on Artificial Intelligence (ECAI) , series=. 2025 , url=
work page 2025
-
[70]
Data Mining and Knowledge Discovery , volume=
Series2vec: similarity-based self-supervised representation learning for time series classification , author=. Data Mining and Knowledge Discovery , volume=. 2024 , publisher=
work page 2024
-
[71]
Proceedings of the 27th ACM SIGKDD conference on knowledge discovery & data mining , pages=
Minirocket: A very fast (almost) deterministic transform for time series classification , author=. Proceedings of the 27th ACM SIGKDD conference on knowledge discovery & data mining , pages=
-
[72]
2012 16th international symposium on wearable computers , pages=
Introducing a new benchmarked dataset for activity monitoring , author=. 2012 16th international symposium on wearable computers , pages=. 2012 , organization=
work page 2012
-
[73]
Random forests , author=. Machine learning , volume=. 2001 , publisher=
work page 2001
-
[74]
ACM Transactions on Embedded Computing Systems (TECS) , volume=
Network-level power-performance trade-off in wearable activity recognition: A dynamic sensor selection approach , author=. ACM Transactions on Embedded Computing Systems (TECS) , volume=. 2012 , publisher=
work page 2012
-
[75]
AAAI workshop on activity context representation: techniques and languages , pages=
The impact of personalization on smartphone-based activity recognition , author=. AAAI workshop on activity context representation: techniques and languages , pages=. 2012 , organization=
work page 2012
-
[76]
Data Mining and Knowledge Discovery , volume=
Inceptiontime: Finding alexnet for time series classification , author=. Data Mining and Knowledge Discovery , volume=. 2020 , publisher=
work page 2020
-
[77]
Journal of Machine learning research , volume=
Statistical comparisons of classifiers over multiple data sets , author=. Journal of Machine learning research , volume=
-
[78]
2021 International Joint Conference on Neural Networks (IJCNN) , pages=
Fall detection with accelerometer data using residual networks adapted to multi-variate time series classification , author=. 2021 International Joint Conference on Neural Networks (IJCNN) , pages=. 2021 , organization=
work page 2021
-
[79]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Deep residual learning for image recognition , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[80]
2017 International joint conference on neural networks (IJCNN) , pages=
Time series classification from scratch with deep neural networks: A strong baseline , author=. 2017 International joint conference on neural networks (IJCNN) , pages=. 2017 , organization=
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.