SignNet-1M: Large-Scale Multilingual Sign Language Video Dataset with Downstream Benchmarks
Pith reviewed 2026-06-26 00:36 UTC · model grok-4.3
The pith
Training on the SignNet-1M dataset improves sign language model generalization to viewpoint, background, identity and artifact shifts while preserving in-distribution accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
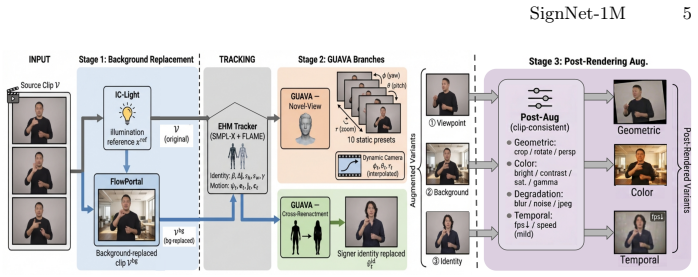
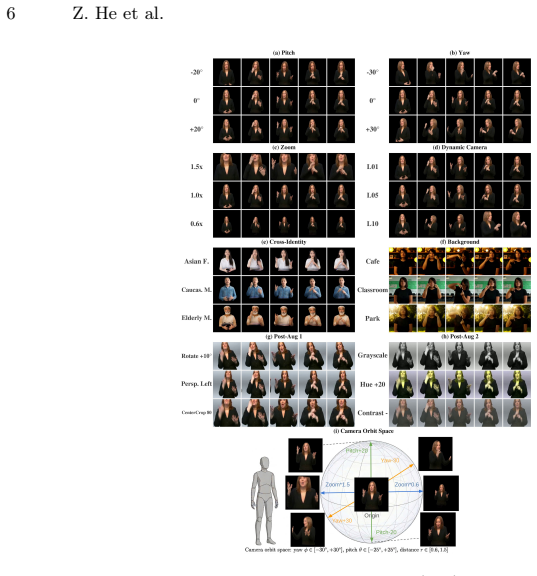
SignNet-1M synthesizes realistic variations along three axes: novel-view rendering via 3D Gaussian Splatting, scene and identity editing via diffusion models that preserve sign motion and linguistic content, and post-rendering augmentations that emulate capture and compression artifacts; training on the resulting dataset improves generalization under cross-view, cross-background, cross-identity and post-rendering shifts while maintaining strong in-distribution performance.
What carries the argument
The three-axis augmentation pipeline that generates novel views with 3D Gaussian Splatting, replaces backgrounds and signers via diffusion editing, and applies video-level corruptions while keeping linguistic content fixed.
If this is right
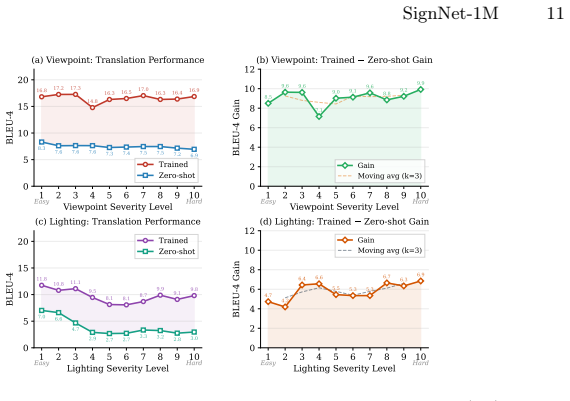
- Models trained on SignNet-1M generalize better to unseen viewpoints than models trained on the source data alone.
- The same models also improve on cross-background and cross-identity test splits.
- Post-rendering corruptions further increase robustness to typical in-the-wild video degradations.
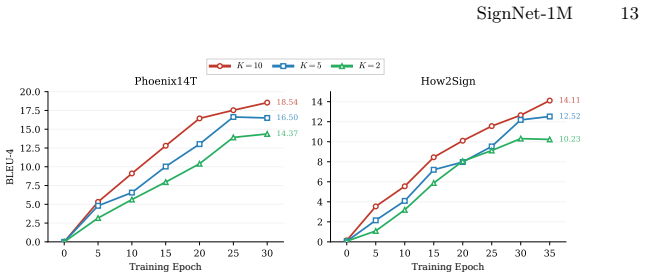
- Ablations that isolate each augmentation axis quantify the contribution of view synthesis, identity editing and artifact simulation.
- Unified benchmarks for translation and recognition are supplied for ASL, CSL and DGS.
Where Pith is reading between the lines
- The same augmentation approach could be applied to other video domains that suffer from limited viewpoint or identity diversity.
- If the linguistic-content preservation claim holds, the method could scale to even larger multilingual collections without new manual annotation.
- Real-world sign-language translation systems might reach usable reliability sooner by training on similarly augmented data rather than waiting for exhaustive real-world collection.
Load-bearing premise
The synthetic variations produced by 3D Gaussian Splatting, diffusion-based editing, and post-rendering corruptions accurately emulate real-world distribution shifts without distorting linguistic content or sign motion.
What would settle it
A test set of real-world sign videos that exhibit natural shifts in view, background, signer identity and recording quality on which models trained with SignNet-1M show no improvement over models trained only on the original data.
Figures

read the original abstract
Sign language models are typically trained on datasets captured under constrained conditions, with limited viewpoint, background, and signer-identity diversity, leading to poor robustness under real-world distribution shifts. We introduce SignNet-1M, a large-scale augmented dataset spanning ASL, CSL, and German Sign Language (DGS). SignNet-1M synthesizes realistic variations along three axes: (i) novel-view rendering (rotation and zoom) via 3D Gaussian Splatting (3DGS), (ii) scene/identity editing via diffusion models for background replacement and signer substitution while preserving sign motion and linguistic content, and (iii) post-rendering augmentations that emulate capture and compression artifacts (e.g., pose/temporal perturbations and video-level corruptions) to better match in-the-wild recordings. Beyond data release, we provide a unified benchmark suite across downstream tasks (e.g., translation and recognition) and ablations that isolate each augmentation component. Experiments across backbones show that training with SignNet-1M consistently improves generalization under cross-view, cross-background, cross-identity, and post-rendering shifts, while maintaining strong in-distribution performance. The dataset, full augmentation pipeline, and benchmark are available at https://signnet.chatsign.ai/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SignNet-1M, a large-scale multilingual sign language video dataset (ASL, CSL, DGS) generated by augmenting existing data along three axes: novel-view synthesis via 3D Gaussian Splatting, scene/identity editing via diffusion models (with claimed preservation of motion and linguistic content), and post-rendering corruptions to simulate real-world artifacts. It supplies a unified benchmark suite for downstream tasks such as translation and recognition, along with ablations, and reports that training on SignNet-1M yields consistent generalization gains under cross-view, cross-background, cross-identity, and post-rendering shifts while preserving in-distribution performance. The dataset, pipeline, and benchmarks are released publicly.
Significance. If the central empirical claims hold, the work addresses a recognized limitation in sign-language modeling (limited viewpoint/identity/background diversity) by releasing a large augmented resource and reproducible pipeline; the public availability of data and code is a clear strength that supports further community evaluation and extension.
major comments (2)
- [augmentation pipeline and experiments sections] The headline result (consistent gains under the four distribution shifts) is load-bearing on the assumption that 3DGS, diffusion editing, and post-rendering operations leave linguistic content, handshape semantics, and motion kinematics unchanged. No quantitative validation of this assumption (e.g., 3D hand-pose reconstruction error, gloss-level agreement, or native-signer semantic-equivalence ratings) is supplied in the augmentation or experiments sections, so it is impossible to rule out that reported gains arise from model exploitation of augmentation artifacts rather than improved robustness.
- [abstract and experiments sections] The abstract and experiments description assert 'consistent improvements across backbones' and 'ablations that isolate each augmentation component,' yet supply no numerical values, baseline comparisons, error bars, or statistical controls. Without these details the magnitude and reliability of the claimed generalization benefit cannot be assessed.
minor comments (1)
- [abstract] The abstract would be strengthened by a single sentence summarizing the scale of SignNet-1M (number of videos or hours) and the size of the reported gains.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for explicit validation of linguistic preservation in the augmentation pipeline and for more detailed numerical reporting of results. We address each major comment below and outline planned revisions.
read point-by-point responses
-
Referee: [augmentation pipeline and experiments sections] The headline result (consistent gains under the four distribution shifts) is load-bearing on the assumption that 3DGS, diffusion editing, and post-rendering operations leave linguistic content, handshape semantics, and motion kinematics unchanged. No quantitative validation of this assumption (e.g., 3D hand-pose reconstruction error, gloss-level agreement, or native-signer semantic-equivalence ratings) is supplied in the augmentation or experiments sections, so it is impossible to rule out that reported gains arise from model exploitation of augmentation artifacts rather than improved robustness.
Authors: We agree this is a substantive gap. The current manuscript relies on design choices (motion-conditioned diffusion, 3DGS geometry preservation, and targeted post-rendering) but does not report quantitative checks such as 3D hand-pose error, gloss agreement, or human semantic ratings. In revision we will add a new subsection with these metrics on sampled subsets: (i) 3D hand-pose reconstruction error using a standard estimator between original and augmented clips, (ii) gloss-level agreement via a pre-trained recognizer, and (iii) a small-scale native-signer equivalence study. This will directly address the possibility of artifact exploitation. revision: yes
-
Referee: [abstract and experiments sections] The abstract and experiments description assert 'consistent improvements across backbones' and 'ablations that isolate each augmentation component,' yet supply no numerical values, baseline comparisons, error bars, or statistical controls. Without these details the magnitude and reliability of the claimed generalization benefit cannot be assessed.
Authors: The full experiments section contains tables reporting per-backbone accuracies, ablation results isolating each augmentation axis, baseline comparisons, and error bars computed over three random seeds. However, the abstract and the high-level narrative in the experiments section are written as summaries without inline numbers or explicit references to statistical controls. We will revise the abstract to include key quantitative gains (e.g., average improvement under cross-view shift) and update the experiments text to cite specific table entries and note the use of multiple seeds. revision: partial
Circularity Check
Empirical dataset release with no derivation chain or fitted predictions
full rationale
The paper presents SignNet-1M as a new augmented dataset for sign language, generated via 3DGS, diffusion editing, and post-rendering, then evaluates it empirically on downstream tasks across backbones. No equations, parameter fits, uniqueness theorems, or self-citations are invoked as load-bearing steps in any derivation. The central claim (consistent generalization gains) rests on experimental results rather than any reduction of outputs to inputs by construction. This is a standard empirical contribution whose validity can be checked externally via the released data and benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Augmentations via 3DGS, diffusion editing, and post-rendering preserve sign motion and linguistic content
Reference graph
Works this paper leans on
-
[1]
Deep Residual Learning for Image Recognition
Camgoz, N.C., Hadfield, S., Koller, O., Ney, H., Bowden, R.: Neural sign language translation. In: CVPR. pp. 7784–7793 (2018).https://doi.org/10.1109/CVPR. 2018.00812
-
[2]
In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp
Camgoz, N.C., Koller, O., Hadfield, S., Bowden, R.: Sign language transformers: Joint end-to-end sign language recognition and translation. In: CVPR. pp. 10023– 10033 (2020).https://doi.org/10.1109/CVPR42600.2020.01004
-
[3]
JMLR25(70), 1–53 (2024)
Chung, H.W., Hou, L., Longpre, S., Zoph, B., Tay, Y., Fedus, W., Li, Y., Wang, X., Dehghani, M., Brahma, S., et al.: Scaling instruction-finetuned language models. JMLR25(70), 1–53 (2024)
2024
-
[4]
Frerix, T., Niesner, M., and Cremers, D
Cubuk, E.D., Zoph, B., Shlens, J., Le, Q.V.: RandAugment: Practical automated data augmentation with a reduced search space. In: CVPRW. pp. 3008–3017 (2020).https://doi.org/10.1109/CVPRW50498.2020.00359
-
[5]
In: CVPR
Duarte, A., Palaskar, S., Ventura, L., Ghadiyaram, D., DeHaan, K., Metze, F., Tor- res, J., Giro-i Nieto, X.: How2sign: A large-scale multimodal dataset for continuous american sign language. In: CVPR. pp. 2735–2744 (2021)
2021
-
[6]
arXiv preprint arXiv:2511.18346 (2025)
Gao, W., Fan, J., Zeng, J., Yang, S.: FlowPortal: Residual-corrected flow for training-free video relighting and background replacement. arXiv preprint arXiv:2511.18346 (2025)
arXiv 2025
-
[7]
In: ICLR (2020)
Hendrycks, D., Mu, N., Cubuk, E.D., Zoph, B., Gilmer, J., Lakshminarayanan, B.: AugMix: A simple data processing method to improve robustness and uncertainty. In: ICLR (2020)
2020
-
[8]
In: NeurIPS (2017)
Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., Hochreiter, S.: GANs trained by a two time-scale update rule converge to a local nash equilibrium. In: NeurIPS (2017)
2017
-
[9]
In: ICLR (2022)
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W.: LoRA: Low-rank adaptation of large language models. In: ICLR (2022)
2022
-
[10]
Hwang, E.J., Cho, S., Lee, J., Park, J.C.: An efficient gloss-free sign language translation using spatial configurations and motion dynamics with LLMs. In: Proc. Nations Am. Chapter Assoc. Comput. Linguistics. pp. 3901–3920 (2025).https: //doi.org/10.18653/v1/2025.naacl-long.197
-
[11]
arXiv preprint arXiv:2303.07399 (2023)
Jiang, T., Lu, P., Zhang, L., Ma, N., Han, R., Lyu, C., Li, Y., Chen, K.: RTM- Pose: Real-time multi-person pose estimation based on MMPose. arXiv preprint arXiv:2303.07399 (2023)
arXiv 2023
-
[12]
3D Gaussian Splatting for Real -Time Radiance Field Rendering,
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. ACM TOG42(4), 139:1–139:14 (2023).https: //doi.org/10.1145/3592433
-
[13]
In: ICCV
Khachatryan, L., Movsisyan, A., Tadevosyan, V., Henschel, R., Wang, Z., Navasardyan, S., Shi, H.: Text2video-zero: Text-to-image diffusion models are zero- shot video generators. In: ICCV. pp. 15954–15964 (2023)
2023
-
[14]
ACM Transactions on Graphics, (Proc
Li, T., Bolkart, T., Black, M.J., Li, H., Romero, J.: Learning a model of facial shape and expression from 4D scans. ACM TOG36(6), 194:1–194:17 (2017).https: //doi.org/10.1145/3130800.3130813
-
[15]
In: ICLR (2025)
Li, Z., Zhou, W., Zhao, W., Wu, K., Hu, H., Li, H.: Uni-sign: Toward unified sign language understanding at scale. In: ICLR (2025)
2025
-
[16]
In: Text Summarization Branches Out, Proc
Lin, C.Y.: ROUGE: A package for automatic evaluation of summaries. In: Text Summarization Branches Out, Proc. ACL Workshop. pp. 74–81 (2004)
2004
-
[17]
In: CVPR
Liu, S., Zhang, Y., Li, W., Lin, Z., Jia, J.: Video-p2p: Video editing with cross- attention control. In: CVPR. pp. 8599–8608 (2024) 16 Z. He et al
2024
-
[18]
Mukushev, M., Ubingazhibov, A., Kydyrbekova, A., Imashev, A., Kimmelman, V., et al.: Fluentsigners-50: A signer independent benchmark dataset for sign lan- guageprocessing.PLOSONE17(9),e0273649(2022).https://doi.org/10.1371/ journal.pone.0273649
2022
-
[19]
In: Proc
Papineni, K., Roukos, S., Ward, T., Zhu, W.J.: BLEU: A method for automatic evaluation of machine translation. In: Proc. ACL. pp. 311–318 (2002)
2002
-
[20]
FBNet: Hardware-Aware Efficient ConvNet De- sign via Differentiable Neural Architec- ture Search
Pavlakos, G., Choutas, V., Ghorbani, N., Bolkart, T., Osman, A.A.A., Tzionas, D., Black, M.J.: Expressive body capture: 3D hands, face, and body from a single im- age. In: CVPR. pp. 10975–10985 (2019).https://doi.org/10.1109/CVPR.2019. 01123
-
[21]
In: Proc
Popović, M.: chrF: Character n-gram F-score for automatic MT evaluation. In: Proc. Workshop on Statistical Machine Translation (WMT). pp. 392–395 (2015)
2015
-
[22]
In: ICML
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., et al.: Learning transferable visual models from natural language supervision. In: ICML. pp. 8748–8763 (2021)
2021
-
[23]
In: SC (2020)
Rajbhandari, S., Rasley, J., Ruwase, O., He, Y.: ZeRO: Memory optimizations toward training trillion parameter models. In: SC (2020)
2020
-
[24]
Rasley, J., Rajbhandari, S., Ruwase, O., He, Y.: DeepSpeed: System optimizations enable training deep learning models with over 100 billion parameters. In: KDD. pp. 3505–3506 (2020)
2020
-
[25]
Shi, B., Brentari, D., Shakhnarovich, G., Livescu, K.: Open-domain sign lan- guage translation learned from online video. In: Proc. Conf. Empirical Methods Nat. Lang. Process. pp. 6365–6379 (2022).https://doi.org/10.18653/v1/2022. emnlp-main.427
-
[26]
signasl.org(2024), commercially licensed ASL video corpus; the ASL50K subset used in this work was obtained under license
SignASL.org: SignASL: American sign language video dictionary.https://www. signasl.org(2024), commercially licensed ASL video corpus; the ASL50K subset used in this work was obtained under license
2024
-
[27]
In: NeurIPS (2022)
Tong, Z., Song, Y., Wang, J., Wang, L.: VideoMAE: Masked autoencoders are data-efficient learners for self-supervised video pre-training. In: NeurIPS (2022)
2022
-
[28]
arXiv preprint arXiv:1812.01717 (2019)
Unterthiner, T., van Steenkiste, S., Kurach, K., Marinièr, R., Michalski, M., Gelly, S.: FVD: A new metric for video generation. arXiv preprint arXiv:1812.01717 (2019)
Pith/arXiv arXiv 2019
-
[29]
In: NeurIPS (2023)
Uthus, D., Tanzer, G., Georg, M.: YouTube-ASL: A large-scale, open-domain American Sign Language–English parallel corpus. In: NeurIPS (2023)
2023
-
[30]
IEEE Transactions on Image Processing 13(4), 600–612 (Apr 2004)
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: From error visibility to structural similarity. IEEE TIP13(4), 600–612 (2004). https://doi.org/10.1109/TIP.2003.819861
-
[31]
In: The Twelfth International Conference on Learning Representations (2024)
Wong, R., Camgoz, N.C., Bowden, R.: Sign2gpt: Leveraging large language models for gloss-free sign language translation. In: The Twelfth International Conference on Learning Representations (2024)
2024
-
[32]
In: ICCV
Wu, J.Z., Ge, Y., Wang, X., Lei, S.W., Gu, Y., Shi, Y., Hsu, W., Shan, Y., Qie, X., Shou, M.Z.: Tune-a-video: One-shot tuning of image diffusion models for text- to-video generation. In: ICCV. pp. 7623–7633 (2023)
2023
-
[33]
m T 5: A Massively Multilingual Pre-trained Text-to-Text Transformer
Xue, L., Constant, N., Roberts, A., Kale, M., Al-Rfou, R., Siddhant, A., Barua, A., Raffel, C.: mT5: A massively multilingual pre-trained text-to-text transformer. In: Proc. Nations Am. Chapter Assoc. Comput. Linguistics. pp. 483–498 (2021). https://doi.org/10.18653/v1/2021.naacl-main.41
-
[34]
In: Proceedings of the IEEE/CVF International Confer- ence on Computer Vision Workshops (ICCVW)
Yang, Z., Zeng, A., Yuan, C., Li, Y.: Effective whole-body pose estimation with two-stages distillation. In: Proceedings of the IEEE/CVF International Confer- ence on Computer Vision Workshops (ICCVW). pp. 4210–4220 (2023),https: SignNet-1M 17 //openaccess.thecvf.com/content/ICCV2023W/CV4Metaverse/papers/Yang_ Effective _ Whole - Body _ Pose _ Estimation ...
2023
-
[35]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yin, A., Zhong, T., Tang, L., Jin, W., Jin, T., Zhao, Z.: Gloss attention for gloss- free sign language translation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 2551–2562 (2023)
2023
-
[36]
Constructing a multi-hop QA dataset for comprehensive evaluation of reasoning steps,
Yin, K., Read, J.: Better sign language translation with STMC-transformer. In: Proceedings of the 28th International Conference on Computational Linguistics (COLING). pp. 5975–5989 (2020).https://doi.org/10.18653/v1/2020.coling- main.525,https://aclanthology.org/2020.coling-main.525/
-
[37]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Yun, S., Han, D., Oh, S.J., Chun, S., Choe, J., Yoo, Y.: CutMix: Regularization strategy to train strong classifiers with localizable features. In: ICCV. pp. 6023– 6032 (2019).https://doi.org/10.1109/ICCV.2019.00612
-
[38]
Zhang, D., Liu, Y., Lin, L., Zhu, Y., Li, Y., Qin, M., Li, Y., Wang, H.: EHM- Tracker: Official ehm tracking implementation for GUAVA.https://github.com/ Pixel-Talk/EHM-Tracker(2025), software release
2025
-
[39]
Zhang, D., Liu, Y., Lin, L., Zhu, Y., Li, Y., Qin, M., Li, Y., Wang, H.: Guava: Generalizable upper body 3d gaussian avatar (2025)
2025
-
[40]
In: ICLR (2018)
Zhang, H., Cisse, M., Dauphin, Y.N., Lopez-Paz, D.: mixup: Beyond empirical risk minimization. In: ICLR (2018)
2018
-
[41]
In: ICLR (2025)
Zhang, L., Rao, A., Agrawala, M.: Scaling in-the-wild training for diffusion-based illumination harmonization and editing by imposing consistent light transport. In: ICLR (2025)
2025
-
[42]
arXiv preprint arXiv:2401.03407 (2024)
Zheng, P., Gao, D., Fan, D.P., Liu, L., et al.: Bilateral reference for high-resolution dichotomous image segmentation. arXiv preprint arXiv:2401.03407 (2024)
arXiv 2024
-
[43]
In: CVPR
Zhou, H., Zhou, W., Qi, W., Pu, J., Li, H.: Improving sign language translation with monolingual data by sign back-translation. In: CVPR. pp. 1316–1325 (2021)
2021
-
[44]
CVIU227, 103597 (2023).https://doi.org/10
Zou, Y., Choi, J., Wang, Q., Huang, J.: Learning representational invariances for data-efficient action recognition. CVIU227, 103597 (2023).https://doi.org/10. 1016/j.cviu.2022.103597
arXiv 2023
-
[45]
Zuo, R., Wei, F., Mak, B.: Towards online continuous sign language recognition and translation. In: EMNLP (2024) A Additional Implementation Details A.1 Augmentation Hyperparameters Table 6 summarizes the concrete settings used in our released augmentation pipeline.We report thechoicesthat materiallyaffectthe generateddata distribu- tion; unless otherwise...
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.