Condensing Large-Scale Datasets Directly with Minimal Information Loss
Pith reviewed 2026-07-02 13:57 UTC · model grok-4.3
The pith
Directly minimizing the information gap between original and synthetic datasets enables higher-fidelity large-scale distillation than decoupled pipelines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The implicit dual-compression process from data to model and back to images in existing pipelines inherently induces severe information loss that creates a distribution shift compromising the RELABEL strategy. CIM overcomes these flaws by abandoning the dual-compression paradigm and instead explicitly quantifying and minimizing the information gap between the original and synthetic datasets through direct alignment of data distributions, ensuring high-fidelity information condensation.
What carries the argument
CIM, the metric-driven framework that directly aligns distributions of original and synthetic datasets to minimize information gap without dual compression.
If this is right
- Relabeling produces reliable labels once the distribution shift from dual compression is removed.
- Distillation of ImageNet-1K at IPC=10 completes in 80 minutes on one GPU with higher final accuracy.
- Cross-architecture generalization improves because the synthetic data retains more original information.
- The method outperforms prior approaches such as NRR-DD and DELT on the same benchmarks.
Where Pith is reading between the lines
- Direct distribution alignment may apply to other data reduction tasks where intermediate model compression creates similar shifts.
- The demonstration of how dual compression harms relabeling could prompt checks on other multi-stage pipelines in machine learning.
- Refining the information-gap metric itself could yield further gains in condensation quality.
Load-bearing premise
That the chosen metric accurately captures and allows reduction of the specific information losses that degrade the quality of synthetic data for downstream training.
What would settle it
Training a ResNet-18 on the CIM-distilled ImageNet-1K at IPC=10 and measuring Top-1 accuracy below 46 percent would indicate the alignment failed to reduce the claimed information loss.
Figures



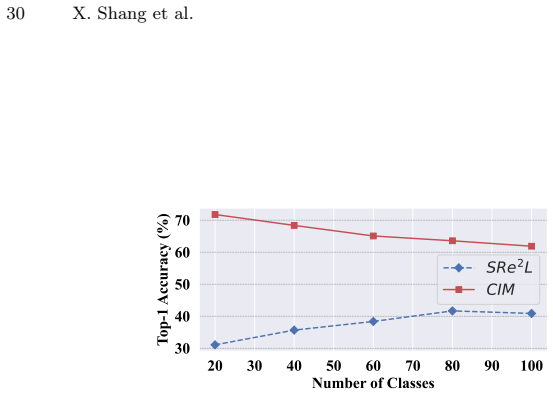
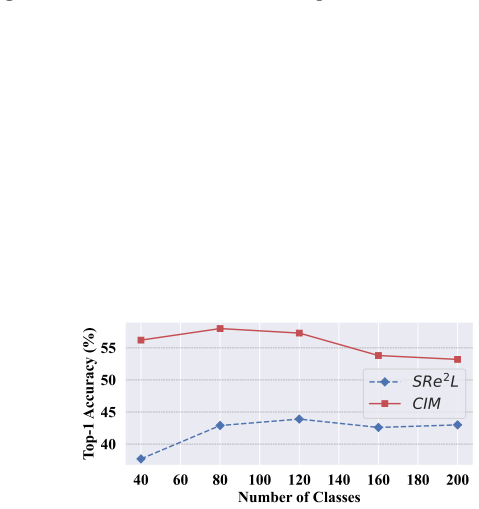














read the original abstract
Recent advancements in scaling dataset distillation rely heavily on decoupled information extraction pipelines, comprising SQUEEZE, RECOVER, and RELABEL stages. Despite their scalability to large-scale datasets, these methods suffer from prohibitive computational overhead and poor cross-architecture generalization. In this paper, we reveal the root cause of these bottlenecks: the implicit dual-compression process, from data to model and back to images, inherently induces severe information loss. Crucially, we empirically and theoretically demonstrate that this loss creates a distribution shift that fundamentally compromises the widely adopted RELABEL strategy, transforming the pre-trained model into an unreliable labeler that yields sub-optimal labels. To overcome these critical flaws, we propose CIM, a novel, metric-driven framework that abandons the flawed dual-compression paradigm. Instead, CIM explicitly quantifies and minimizes the information gap between the original and synthetic datasets. By directly aligning the data distributions, our approach ensures high-fidelity information condensation and inherently satisfies the prerequisites for effective relabeling. Extensive experiments demonstrate that CIM establishes a new state-of-the-art. Notably, it distills ImageNet-1K at an IPC=10 in merely 80 minutes on a single RTX-4090 GPU, achieving an unprecedented 48.7% Top-1 accuracy on ResNet-18 and significantly outperforming previous SOTA approaches, such as NRR-DD and DELT, by 2.6% and 2.9%, respectively. Our code is available at https://github.com/LINs-lab/CIM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies the dual-compression pipeline (SQUEEZE-RECOVER-RELABEL) in recent dataset distillation methods as the source of information loss and distribution shift that degrades the RELABEL stage. It proposes CIM, a metric-driven approach that directly quantifies and minimizes the information gap between original and synthetic datasets to achieve high-fidelity condensation without the flawed intermediate steps. Experiments on ImageNet-1K at IPC=10 report 48.7% Top-1 accuracy on ResNet-18 in 80 minutes on a single RTX-4090, outperforming NRR-DD and DELT.
Significance. If the claimed theoretical demonstration of distribution shift and the empirical results hold, CIM could substantially improve scalability and cross-architecture performance of dataset distillation for large-scale datasets. The reported single-GPU runtime and accuracy gains would represent a practical advance over prior decoupled pipelines.
minor comments (4)
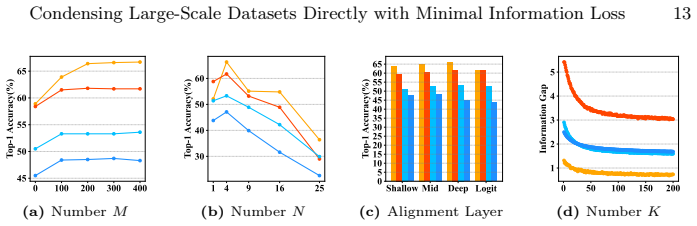
- §3: The definition of the information-gap metric should include an explicit statement of whether it is computed in feature space or pixel space and how the alignment loss is balanced against the condensation objective.
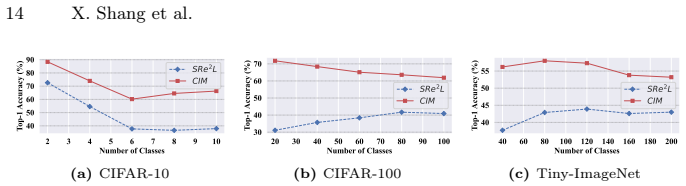
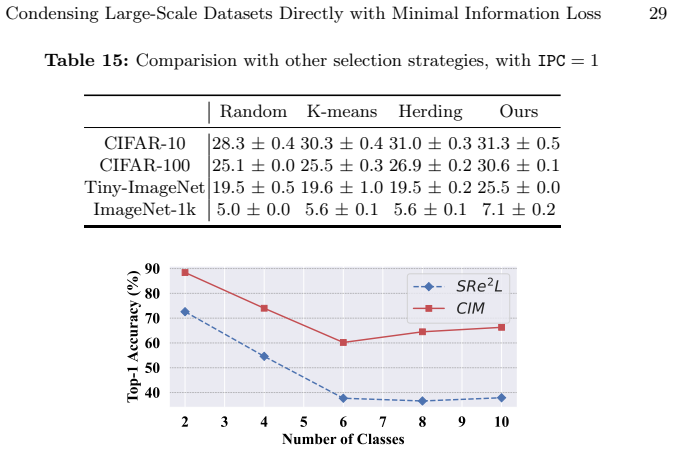
- Table 2: The cross-architecture transfer results lack error bars or multiple random seeds; reporting standard deviation over at least three runs would strengthen the generalization claim.
- §4.2: The theoretical argument for why direct alignment satisfies the prerequisites for relabeling is sketched at a high level; a short derivation or inequality showing that the minimized gap bounds the labeler mismatch would clarify the link.
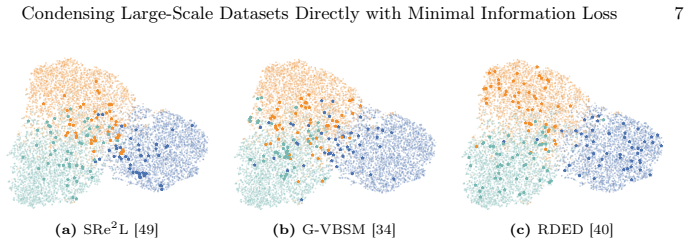
- Figure 4: The visualization of distribution shift would benefit from a quantitative metric (e.g., MMD or FID) alongside the qualitative plots to allow direct comparison with the CIM objective.
Simulated Author's Rebuttal
We thank the referee for the thorough summary of our work and the recommendation of minor revision. No specific major comments were raised in the report.
Circularity Check
No significant circularity detected
full rationale
The paper presents CIM as a direct metric-driven minimization of the information gap between original and synthetic datasets, explicitly abandoning the prior dual-compression pipeline. The SOTA performance numbers (48.7% Top-1 on ResNet-18) are reported as empirical outcomes of this alignment on ImageNet-1K, with the distribution-shift critique supported by separate empirical and theoretical demonstration. No equations, fitted parameters, or self-citations are shown reducing the central result to its own inputs by construction; the derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Cazenavette, G., Wang, T., Torralba, A., Efros, A.A., Zhu, J.Y.: Dataset distillation by matching training trajectories. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4750–4759 (2022)
2022
-
[2]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Cazenavette, G., Wang, T., Torralba, A., Efros, A.A., Zhu, J.Y.: Generalizing dataset distillation via deep generative prior. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3739–3748 (2023)
2023
-
[3]
Advances in Neural Information Processing Systems35, 14678–14690 (2022)
Chen, D., Kerkouche, R., Fritz, M.: Private set generation with discriminative information. Advances in Neural Information Processing Systems35, 14678–14690 (2022)
2022
-
[4]
arXiv preprint arXiv:2501.07575 (2025)
Cui, J., Li, Z., Ma, X., Bi, X., Luo, Y., Shen, Z.: Dataset distillation via committee voting. arXiv preprint arXiv:2501.07575 (2025)
-
[5]
Advances in Neural Information Processing Systems35, 810–822 (2022)
Cui, J., Wang, R., Si, S., Hsieh, C.J.: Dc-bench: Dataset condensation benchmark. Advances in Neural Information Processing Systems35, 810–822 (2022)
2022
-
[6]
In: International Conference on Machine Learning
Cui, J., Wang, R., Si, S., Hsieh, C.J.: Scaling up dataset distillation to imagenet-1k with constant memory. In: International Conference on Machine Learning. pp. 6565–6590. PMLR (2023)
2023
-
[7]
In: 2009 IEEE conference on computer vision and pattern recognition
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: Imagenet: A large-scale hierarchical image database. In: 2009 IEEE conference on computer vision and pattern recognition. pp. 248–255. Ieee (2009)
2009
-
[8]
Dong, T., Zhao, B., Lyu, L.: Privacy for free: How does dataset condensation help privacy? In: International Conference on Machine Learning. pp. 5378–5396. PMLR (2022)
2022
-
[9]
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., Houlsby, N.: An image is worth 16x16 words: Transformers for image recognition at scale (2021)
2021
-
[10]
Advances in neural information processing systems37, 119443–119465 (2024)
Du, J., Hu, J., Huang, W., Zhou, J.T., et al.: Diversity-driven synthesis: Enhanc- ing dataset distillation through directed weight adjustment. Advances in neural information processing systems37, 119443–119465 (2024)
2024
-
[11]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Du, J., Jiang, Y., Tan, V.Y., Zhou, J.T., Li, H.: Minimizing the accumulated trajectory error to improve dataset distillation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3749–3758 (2023) 16 X. Shang et al
2023
-
[12]
biometrics21, 768–769 (1965)
Forgy, E.W.: Cluster analysis of multivariate data: efficiency versus interpretability of classifications. biometrics21, 768–769 (1965)
1965
-
[13]
arXiv preprint arXiv:2310.05773 (2023)
Guo, Z., Wang, K., Cazenavette, G., Li, H., Zhang, K., You, Y.: Towards loss- less dataset distillation via difficulty-aligned trajectory matching. arXiv preprint arXiv:2310.05773 (2023)
-
[14]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 770–778 (2016)
2016
-
[15]
Huang, G., Liu, Z., van der Maaten, L., Weinberger, K.Q.: Densely connected convolutional networks (2018)
2018
-
[16]
In: International conference on machine learning
Ioffe, S., Szegedy, C.: Batch normalization: Accelerating deep network training by reducing internal covariate shift. In: International conference on machine learning. pp. 448–456. pmlr (2015)
2015
-
[17]
In: International Conference on Machine Learning
Kim, J.H., Kim, J., Oh, S.J., Yun, S., Song, H., Jeong, J., Ha, J.W., Song, H.O.: Dataset condensation via efficient synthetic-data parameterization. In: International Conference on Machine Learning. pp. 11102–11118. PMLR (2022)
2022
-
[18]
Krizhevsky, A., Hinton, G., et al.: Learning multiple layers of features from tiny images (2009)
2009
-
[19]
URl: https://www
Krizhevsky, A., Nair, V., Hinton, G.: Cifar-10 and cifar-100 datasets. URl: https://www. cs. toronto. edu/kriz/cifar. html6(1), 1 (2009)
2009
-
[20]
CS 231N7(7), 3 (2015)
Le, Y., Yang, X.: Tiny imagenet visual recognition challenge. CS 231N7(7), 3 (2015)
2015
-
[21]
Liu, H., Li, Y., Xing, T., Dalal, V., Li, L., He, J., Wang, H.: Dataset distillation via the wasserstein metric (2024)
2024
-
[22]
arXiv preprint arXiv:2311.18531 (2023)
Liu, H., Xing, T., Li, L., Dalal, V., He, J., Wang, H.: Dataset distillation via the wasserstein metric. arXiv preprint arXiv:2311.18531 (2023)
-
[23]
arXiv preprint arXiv:2302.14416 (2023)
Liu, Y., Gu, J., Wang, K., Zhu, Z., Jiang, W., You, Y.: Dream: Efficient dataset distillation by representative matching. arXiv preprint arXiv:2302.14416 (2023)
-
[24]
Advances in Neural Information Processing Systems35, 13877–13891 (2022)
Loo, N., Hasani, R., Amini, A., Rus, D.: Efficient dataset distillation using random feature approximation. Advances in Neural Information Processing Systems35, 13877–13891 (2022)
2022
-
[25]
Ma, N., Zhang, X., Zheng, H.T., Sun, J.: Shufflenet v2: Practical guidelines for efficient cnn architecture design (2018)
2018
-
[26]
Journal of machine learning research9(11) (2008)
Van der Maaten, L., Hinton, G.: Visualizing data using t-sne. Journal of machine learning research9(11) (2008)
2008
-
[27]
In: European conference on computer vision
Prabhu, A., Torr, P.H., Dokania, P.K.: Gdumb: A simple approach that questions our progress in continual learning. In: European conference on computer vision. pp. 524–540. Springer (2020)
2020
-
[28]
arXiv preprint arXiv:2104.10972 , year=
Ridnik, T., Ben-Baruch, E., Noy, A., Zelnik-Manor, L.: Imagenet-21k pretraining for the masses. arXiv preprint arXiv:2104.10972 (2021)
-
[29]
In: International Workshop on Continual Semi-Supervised Learning
Rosasco, A., Carta, A., Cossu, A., Lomonaco, V., Bacciu, D.: Distilled replay: Overcoming forgetting through synthetic samples. In: International Workshop on Continual Semi-Supervised Learning. pp. 104–117 (2021)
2021
-
[30]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Sajedi, A., Khaki, S., Amjadian, E., Liu, L.Z., Lawryshyn, Y.A., Plataniotis, K.N.: Datadam: Efficient dataset distillation with attention matching. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 17097–17107 (2023)
2023
-
[31]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Sandler,M.,Howard,A.,Zhu,M.,Zhmoginov,A.,Chen,L.C.:Mobilenetv2:Inverted residuals and linear bottlenecks. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 4510–4520 (2018) Condensing Large-Scale Datasets Directly with Minimal Information Loss 17
2018
-
[32]
Shang, X., Lu, Y., Huang, G., Wang, H.: Federated learning on heterogeneous and long-tailed data via classifier re-training with federated features. arXiv preprint arXiv:2204.13399 (2022)
-
[33]
In: International Conference on Learning Representations (2025)
Shang, X., Sun, P., Lin, T.: Gift: Unlocking full potential of labels in distilled dataset at near-zero cost. In: International Conference on Learning Representations (2025)
2025
-
[34]
arXiv preprint arXiv:2311.17950 (2023)
Shao, S., Yin, Z., Zhou, M., Zhang, X., Shen, Z.: Generalized large-scale data condensation via various backbone and statistical matching. arXiv preprint arXiv:2311.17950 (2023)
-
[35]
In: Advances in neural information processing systems (2024)
Shao, S., Zhou, Z., Chen, H., Shen, Z.: Elucidating the design space of dataset condensation. In: Advances in neural information processing systems (2024)
2024
-
[36]
CVPR (2025)
Shen, Z., Sherif, A., Yin, Z., Shao, S.: Delt: A simple diversity-driven earlylate training for dataset distillation. CVPR (2025)
2025
-
[37]
In: European Conference on Computer Vision
Shen, Z., Xing, E.: A fast knowledge distillation framework for visual recognition. In: European Conference on Computer Vision. pp. 673–690. Springer (2022)
2022
-
[38]
In: Thirty-seventh Conference on Neural Information Processing Systems (2023)
Shin, D., Shin, S., Moon, I.c.: Frequency domain-based dataset distillation. In: Thirty-seventh Conference on Neural Information Processing Systems (2023)
2023
-
[39]
In: International Conference on Machine Learning
Such, F.P., Rawal, A., Lehman, J., Stanley, K., Clune, J.: Generative teaching networks: Accelerating neural architecture search by learning to generate synthetic training data. In: International Conference on Machine Learning. pp. 9206–9216 (2020)
2020
-
[40]
arXiv preprint arXiv:2312.03526 (2023)
Sun, P., Shi, B., Yu, D., Lin, T.: On the diversity and realism of distilled dataset: An efficient dataset distillation paradigm. arXiv preprint arXiv:2312.03526 (2023)
-
[41]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2024)
Sun, P., Shi, B., Yu, D., Lin, T.: On the diversity and realism of distilled dataset: An efficient dataset distillation paradigm. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2024)
2024
-
[42]
CVPR (2025)
Tran, M.T., Le, T., Le, X.M., Do, T.T., Phung, D.: Enhancing dataset distillation via non-critical region refinement. CVPR (2025)
2025
-
[43]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wang, K., Zhao, B., Peng, X., Zhu, Z., Yang, S., Wang, S., Huang, G., Bilen, H., Wang, X., You, Y.: Cafe: Learning to condense dataset by aligning features. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 12196–12205 (2022)
2022
-
[44]
Wang, R., Cheng, M., Chen, X., Tang, X., Hsieh, C.J.: Rethinking architecture selection in differentiable nas (2021)
2021
-
[45]
Wang, T., Zhu, J.Y., Torralba, A., Efros, A.A.: Dataset distillation. arXiv preprint arXiv:1811.10959 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[46]
In: Proceedings of the 26th Annual International Conference on Machine Learning
Welling, M.: Herding dynamical weights to learn. In: Proceedings of the 26th Annual International Conference on Machine Learning. pp. 1121–1128 (2009)
2009
-
[47]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Xiong, Y., Wang, R., Cheng, M., Yu, F., Hsieh, C.J.: Feddm: Iterative distribution matching for communication-efficient federated learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 16323– 16332 (2023)
2023
-
[48]
arXiv preprint arXiv:2311.18838 (2023)
Yin, Z., Shen, Z.: Dataset distillation in large data era. arXiv preprint arXiv:2311.18838 (2023)
-
[49]
arXiv preprint arXiv:2306.13092 (2023)
Yin, Z., Xing, E., Shen, Z.: Squeeze, recover and relabel: Dataset condensation at imagenet scale from a new perspective. arXiv preprint arXiv:2306.13092 (2023)
-
[50]
arXiv preprint arXiv:2301.07014 (2023)
Yu, R., Liu, S., Wang, X.: Dataset distillation: A comprehensive review. arXiv preprint arXiv:2301.07014 (2023)
-
[51]
In: European Conference on Computer Vision
Yu, R., Liu, S., Ye, J., Wang, X.: Teddy: Efficient large-scale dataset distillation via taylor-approximated matching. In: European Conference on Computer Vision. pp. 1–17. Springer (2024) 18 X. Shang et al
2024
-
[52]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yun, S., Oh, S.J., Heo, B., Han, D., Choe, J., Chun, S.: Re-labeling imagenet: from single to multi-labels, from global to localized labels. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 2340–2350 (2021)
2021
-
[53]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhang, L., Zhang, J., Lei, B., Mukherjee, S., Pan, X., Zhao, B., Ding, C., Li, Y., Xu, D.: Accelerating dataset distillation via model augmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 11950–11959 (2023)
2023
-
[54]
ICLR (2025)
Zhang, X., Du, J., Liu, P., Zhou, J.T.: Breaking class barriers: Efficient dataset distillation via inter-class feature compensator. ICLR (2025)
2025
-
[55]
In: International Conference on Machine Learning (2021)
Zhao, B., Bilen, H.: Dataset condensation with differentiable siamese augmentation. In: International Conference on Machine Learning (2021)
2021
-
[56]
In: Proceed- ings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Zhao, B., Bilen, H.: Dataset condensation with distribution matching. In: Proceed- ings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 6514–6523 (2023)
2023
-
[57]
arXiv preprint arXiv:2006.05929 (2020)
Zhao, B., Mopuri, K.R., Bilen, H.: Dataset condensation with gradient matching. arXiv preprint arXiv:2006.05929 (2020)
-
[58]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhao, G., Li, G., Qin, Y., Yu, Y.: Improved distribution matching for dataset condensation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 7856–7865 (2023)
2023
-
[59]
Zhou, Y., Nezhadarya, E., Ba, J.: Dataset distillation using neural feature regression. Advances in Neural Information Processing Systems35, 9813–9827 (2022) Condensing Large-Scale Datasets Directly with Minimal Information Loss 19 A Limitations Although ourCIMsignificantly outperforms existing SOTA methods, its primary limitation, as discussed in Section...
2022
-
[60]
computing the scores s for all samplesxin data Tc presents a significant computational challenge
-
[61]
Therefore, we utilize a pre-selection strategy inspired by [41], which involves selecting a subset6 T ′ c ⊂ T c uniformly at random to serve as a proxy for the entire Tc
focusing solely on samples that closely align with the true label can lead to a lack of diversity. Therefore, we utilize a pre-selection strategy inspired by [41], which involves selecting a subset6 T ′ c ⊂ T c uniformly at random to serve as a proxy for the entire Tc. Such a pre-selection strategy not only promotes diversity in the data but also lessens ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.