TSM-Bench: Detecting LLM-Generated Text in Real-World Wikipedia Editing Practices
Pith reviewed 2026-06-28 22:50 UTC · model grok-4.3
The pith
SOTA detectors lose 10-40% accuracy on task-specific machine-generated text from real Wikipedia editing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
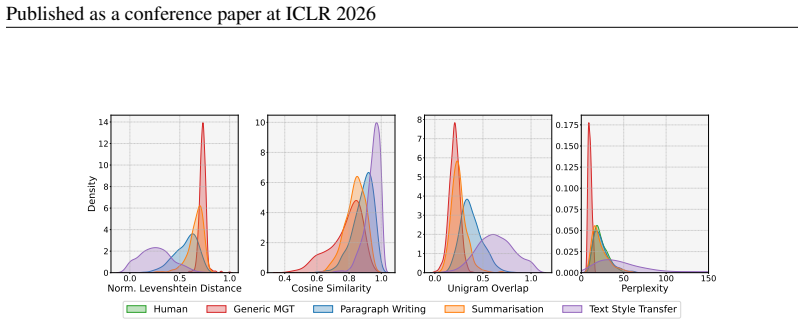
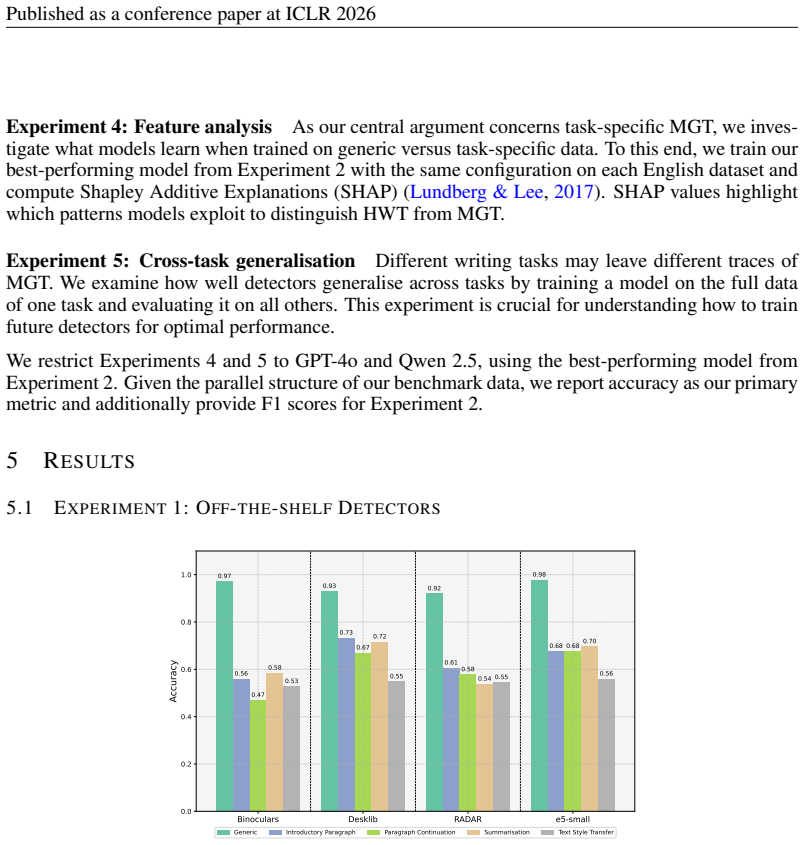
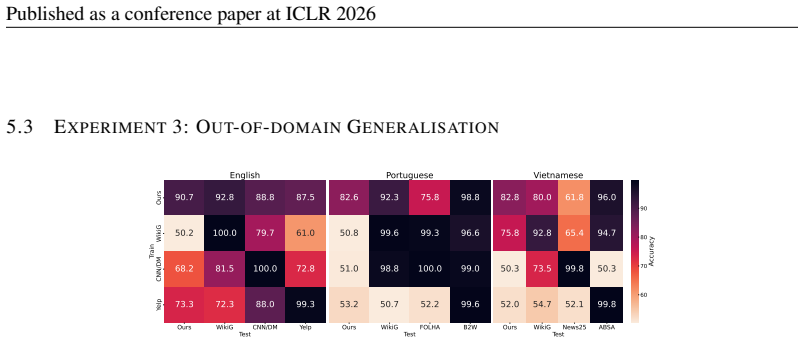
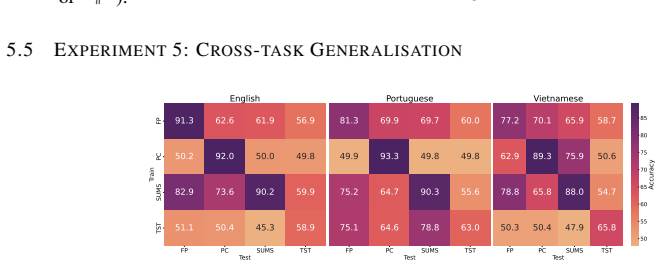
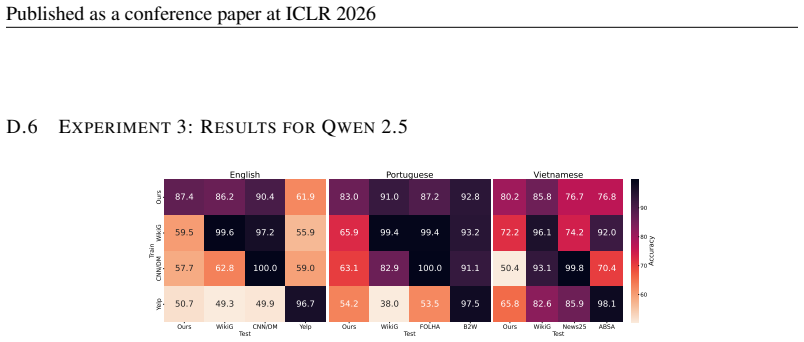
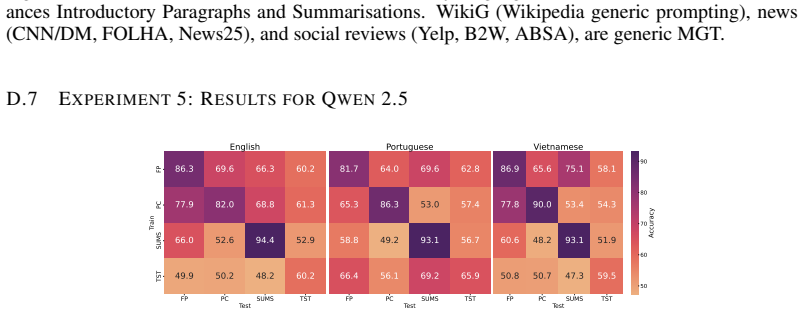
A range of SOTA MGT detectors struggle to identify task-specific MGT reflecting real-world editing on Wikipedia, with average detection accuracy dropping by 10--40% compared to prior benchmarks, and a generalisation asymmetry exists: fine-tuning on task-specific data enables generalisation to generic data even across domains but not vice versa.
What carries the argument
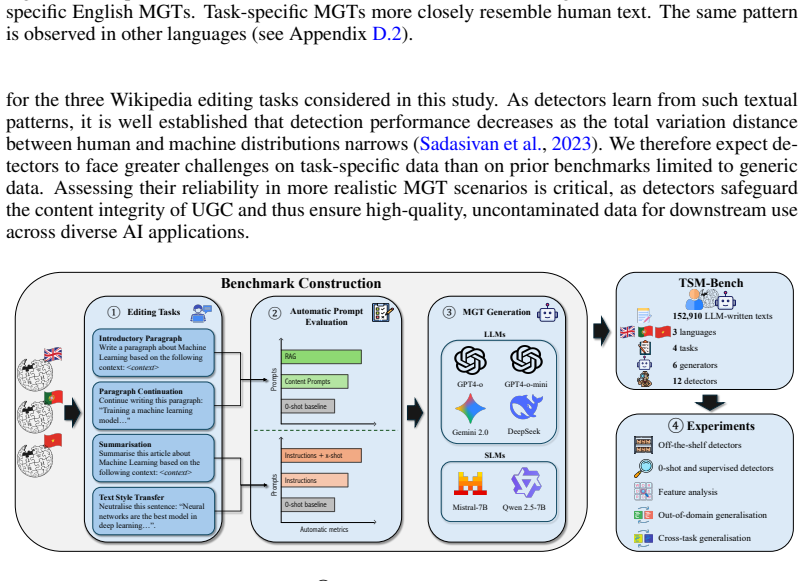
TSM-Bench, a multilingual multi-generator multi-task benchmark built from common Wikipedia editing tasks such as summarisation and expansion.
If this is right
- Models fine-tuned exclusively on generic MGT overfit to superficial artefacts of machine generation.
- Fine-tuning on task-specific data enables generalisation to generic data even across domains.
- Most current detectors remain unreliable for automated detection in real-world UGC platforms.
- TSM-Bench supplies a foundation for developing and evaluating more reliable future detectors.
Where Pith is reading between the lines
- Detector training pipelines for UGC platforms should shift priority toward task-constrained examples rather than broad generic corpora.
- The observed asymmetry suggests that evaluation on generic benchmarks alone is insufficient to certify detectors for practical deployment.
- Comparable detection gaps may appear on other collaborative platforms that rely on constrained writing tasks.
Load-bearing premise
The task-specific MGT instances constructed for TSM-Bench accurately reflect how Wikipedia editors actually employ LLMs in practice.
What would settle it
Direct observation or logging of LLM-assisted edits on Wikipedia that produces text distributions measurably different from the benchmark's task-specific generations.
Figures

read the original abstract
Automatically detecting machine-generated text (MGT) is critical to maintaining the knowledge integrity of user-generated content (UGC) platforms such as Wikipedia. Existing detection benchmarks primarily focus on \textit{generic} text generation tasks (e.g., ``Write an article about machine learning.''). However, editors frequently employ LLMs for specific writing tasks (e.g., summarisation). These \textit{task-specific} MGT instances tend to resemble human-written text more closely due to their constrained task formulation and contextual conditioning. In this work, we show that a range of SOTA MGT detectors struggle to identify task-specific MGT reflecting real-world editing on Wikipedia. We introduce \textsc{TSM-Bench}, a multilingual, multi-generator, and \textit{multi-task} benchmark for evaluating MGT detectors on common, real-world Wikipedia editing tasks. Our findings demonstrate that (\textit{i}) average detection accuracy drops by 10--40\% compared to prior benchmarks, and (\textit{ii}) a generalisation asymmetry exists: fine-tuning on task-specific data enables generalisation to generic data -- even across domains -- but not vice versa. We demonstrate that models fine-tuned exclusively on generic MGT overfit to superficial artefacts of machine generation. Our results suggest that, in contrast to prior benchmarks, most detectors remain unreliable for automated detection in real-world contexts such as UGC platforms. \textsc{TSM-Bench} therefore provides a critical foundation for developing and evaluating future models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TSM-Bench, a multilingual, multi-generator, multi-task benchmark for MGT detection focused on common Wikipedia editing tasks such as summarization and expansion. It claims that SOTA detectors exhibit 10-40% lower accuracy on these task-specific instances than on prior generic benchmarks, demonstrates a generalization asymmetry (fine-tuning on task-specific data transfers to generic data across domains, but not vice versa), and concludes that existing detectors remain unreliable for real-world UGC platforms like Wikipedia.
Significance. If the constructed tasks accurately mirror real-world LLM-assisted editing workflows, the reported accuracy drops and asymmetry would provide concrete evidence that current detectors overfit to generic generation artifacts and would establish TSM-Bench as a necessary resource for developing detectors suitable for UGC integrity. The work also supplies an empirical basis for preferring task-specific fine-tuning in detector training.
major comments (2)
- [Introduction / Benchmark Construction] Introduction and benchmark construction section: The central claim that TSM-Bench reflects 'real-world Wikipedia editing practices' and that the observed 10-40% accuracy drop therefore indicates unreliability 'in real-world contexts such as UGC platforms' is load-bearing, yet the manuscript supplies no edit-log analysis, editor survey, or distributional comparison between the chosen tasks/prompts and actual editor LLM usage to ground this premise.
- [Results / Generalization Experiments] Results section on generalization: The reported asymmetry (task-specific fine-tuning generalizes to generic data but not vice versa) and the claim that generic-only models 'overfit to superficial artefacts' are presented as key findings, but the manuscript does not report the precise statistical tests, confidence intervals, or ablation controls used to establish that the asymmetry is not an artifact of the particular task set or data splits.
minor comments (2)
- [Abstract / Results Tables] The abstract states quantitative drops without accompanying error bars or per-detector breakdowns; adding these to the main results tables would improve interpretability.
- [Benchmark Description] Notation for the multi-task categories (e.g., summarization vs. expansion) should be defined once with explicit examples of the Wikipedia-specific conditioning used.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond to each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Introduction / Benchmark Construction] Introduction and benchmark construction section: The central claim that TSM-Bench reflects 'real-world Wikipedia editing practices' and that the observed 10-40% accuracy drop therefore indicates unreliability 'in real-world contexts such as UGC platforms' is load-bearing, yet the manuscript supplies no edit-log analysis, editor survey, or distributional comparison between the chosen tasks/prompts and actual editor LLM usage to ground this premise.
Authors: We agree that stronger empirical grounding would be valuable. The tasks were chosen based on common Wikipedia editing activities described in prior literature on collaborative editing workflows. We did not perform a new edit-log analysis or editor survey. In revision we will add a subsection detailing the task selection rationale with supporting citations, moderate phrasing from 'real-world Wikipedia editing practices' to 'common task-specific Wikipedia editing tasks', and note the absence of direct usage statistics as a limitation. A full distributional study lies outside the current scope. revision: partial
-
Referee: [Results / Generalization Experiments] Results section on generalization: The reported asymmetry (task-specific fine-tuning generalizes to generic data but not vice versa) and the claim that generic-only models 'overfit to superficial artefacts' are presented as key findings, but the manuscript does not report the precise statistical tests, confidence intervals, or ablation controls used to establish that the asymmetry is not an artifact of the particular task set or data splits.
Authors: We appreciate this observation. The asymmetry was consistent across multiple random seeds and data partitions, but we did not report formal tests or intervals. In the revised version we will add confidence intervals for all accuracy figures, paired statistical tests (e.g., McNemar or t-tests) with p-values, and ablation results across alternative splits and task subsets to confirm robustness. revision: yes
Circularity Check
No circularity; empirical benchmark results independent of inputs
full rationale
The paper introduces TSM-Bench as a new multi-task dataset of LLM generations for Wikipedia editing tasks and reports detector performance metrics on it. These are direct empirical measurements (accuracy drops, generalization tests) obtained by running existing detectors on the constructed data; no derivation reduces a claimed result to a fitted parameter, self-defined quantity, or self-citation chain. The central claims rest on observable performance numbers rather than any equation or premise that is true by construction from the benchmark itself. The representativeness assumption is a validity concern but does not create circularity in the reported results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URLhttps://aclanthology.org/ 2024.acl-long.674
Association for Computational Linguistics. URLhttps://aclanthology.org/ 2024.acl-long.674. Emdemor. News of the brazilian newspaper, 2023. URLhttps://huggingface.co/ datasets/emdemor/news-of-the-brazilian-newspaper. Accessed: 2025-05-10. Alexander Fabbri, Chien-Sheng Wu, Wenhao Liu, and Caiming Xiong. QAFactEval: Improved QA-based factual consistency eval...
-
[2]
Retrieval-Augmented Generation for Large Language Models: A Survey
URLhttps://arxiv.org/abs/2312.10997. Demian Gholipour Ghalandari, Chris Hokamp, Nghia The Pham, John Glover, and Georgiana Ifrim. A large-scale multi-document summarization dataset from the Wikipedia current events portal. In Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault (eds.),Proceedings of the 58th Annual Meeting of the Association for...
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
doi: 10.18653/v1/2020.acl-main.120
Association for Computational Linguistics. doi: 10.18653/v1/2020.acl-main.120. URL https://aclanthology.org/2020.acl-main.120/. Biyang Guo, Xin Zhang, Ziyuan Wang, Minqi Jiang, Jinran Nie, Yuxuan Ding, Jianwei Yue, and Yu- peng Wu. How close is chatgpt to human experts? comparison corpus, evaluation, and detection,
-
[4]
URLhttps://arxiv.org/abs/2301.07597. Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. Hanxi Guo, Siyuan Cheng, Xiaolong Jin, Zhuo Zhang, Kaiyuan Zhang, Guanho...
-
[5]
A Unified Approach to Interpreting Model Predictions
Association for Computational Linguistics. doi: 10.18653/v1/2024.naacl-long.179. URL https://aclanthology.org/2024.naacl-long.179/. Scott Lundberg and Su-In Lee. A unified approach to interpreting model predictions, 2017. URL https://arxiv.org/abs/1705.07874. Dominik Macko, Robert Moro, Adaku Uchendu, Jason Lucas, Michiharu Yamashita, Matúš Piku- liak, Iv...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2024.naacl-long.179 2024
-
[6]
{title}", the article should at least have 250 words. CNN/DM Write a news article given the following highlights:
Each entry includes a title and the main article body, along with additional metadata. SOCIALREVIEWS YelpThe Yelp dataset (Zhang et al., 2015) is a large-scale collection of approximately 700,000 business reviews written on the Yelp platform. It covers businesses across eight metropolitan areas in the United States and Canada. B2WB2W-Reviews01 (Real et al...
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.