Leveraging Morphology for Historical Script Metrological Analysis
Pith reviewed 2026-06-27 17:15 UTC · model grok-4.3
The pith
A transformer architecture learns character prototypes from line-level transcriptions to produce scalable paleographic measurements.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
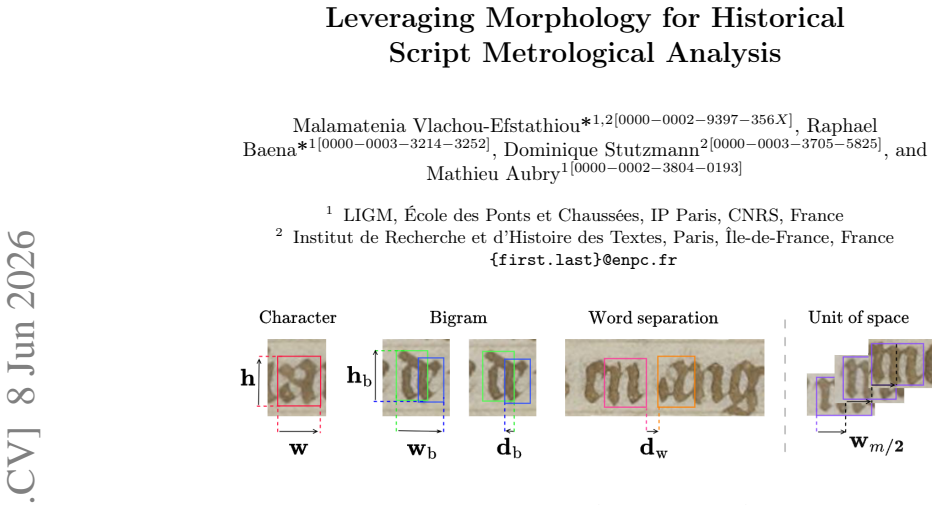
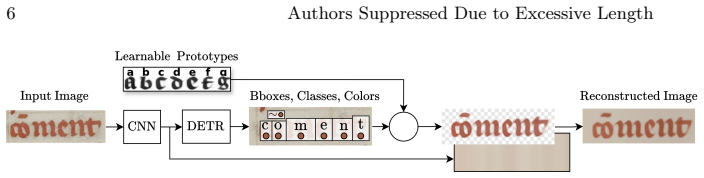
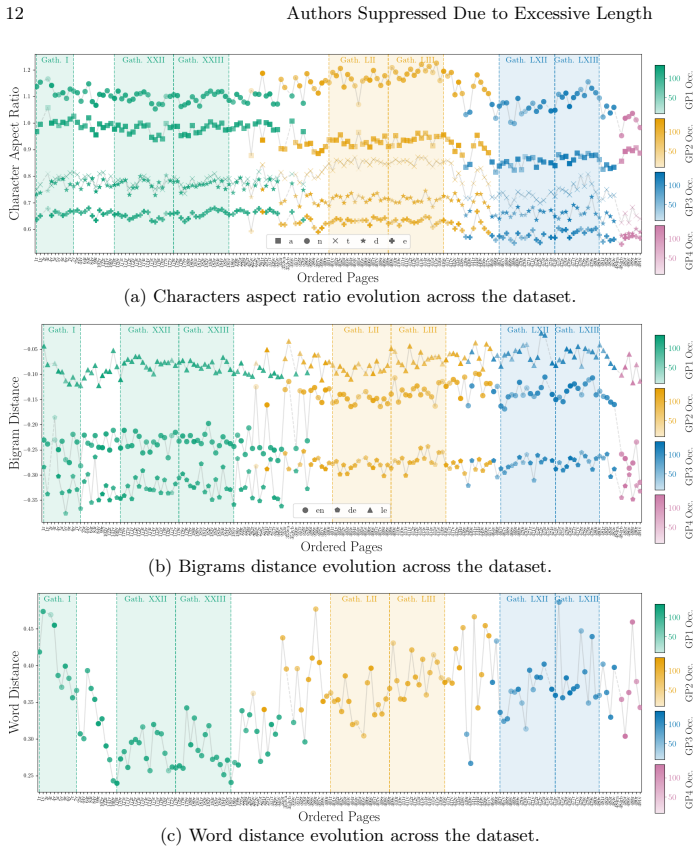
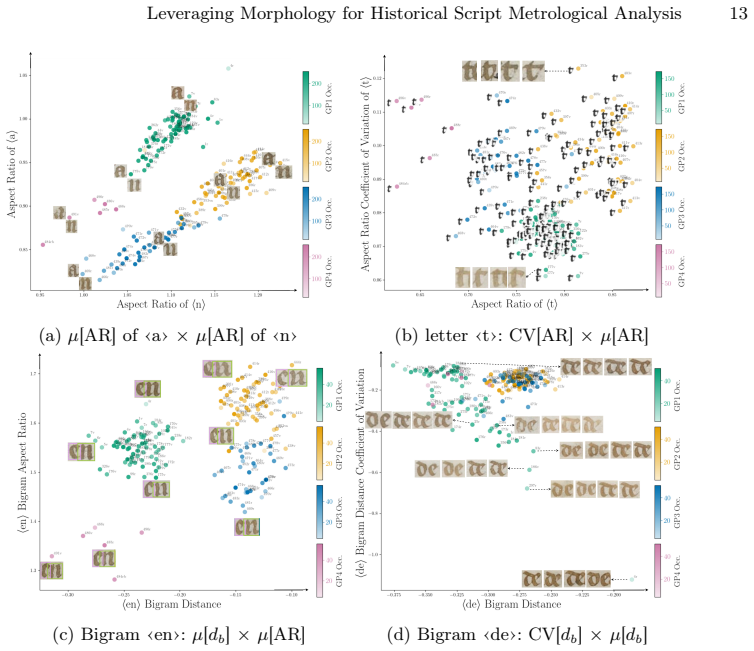
A transformer-based detection architecture together with a prototype-based line reconstruction module learns prototypical characters and their occurrence, deformation, and positioning from line-level transcriptions alone; this produces accurate character bounding boxes and enables automatic paleographic measurements of characters, bi-grams, and spaces that differentiate graphical profiles and reveal subtle variations across the four hands in the extended Paris, BnF, fr. 2813 codex.
What carries the argument
Prototype-based line reconstruction module that learns character prototypes and their deformations and positions from line transcriptions.
If this is right
- Accurate character bounding boxes become available without character-level supervision.
- Automatic measurements on characters, bi-grams, and spaces differentiate graphical profiles of different scribes.
- Subtle variations within a single hand can be quantified and visualized across pages.
- The approach scales to hundreds of pages while requiring only one column of text per page for training.
- Paleographic analysis gains a frugal, scalable route from existing line transcriptions.
Where Pith is reading between the lines
- The same prototype learning could be applied to other manuscript collections to create comparable metrological databases across centuries or regions.
- Integration into existing handwritten text recognition pipelines might allow metrological outputs with no extra annotation step.
- The measurements could support quantitative tracking of script change over time within a single scribe's output.
Load-bearing premise
Character prototypes learned solely from line-level transcriptions produce bounding boxes and derived measurements that are both accurate and paleographically relevant without character-level supervision or additional validation.
What would settle it
Comparison of the model's predicted character bounding boxes against expert annotations on held-out pages of the codex, checking whether measurement-derived distinctions between the four known hands disappear or bounding-box error exceeds a small threshold.
Figures


read the original abstract
Advances in handwritten text recognition have enabled large-scale transcription of historical documents, but still provide limited access to interpretable visual measurements for paleography, the study of historical scripts. In this paper, our main insight is that morphological script analysis, in particular the capacity to learn character prototypes from line-level transcriptions, enables the definition of scalable, meaningful, and stable paleographic measurements. More precisely, we leverage a transformer-based detection architecture together with a prototype-based line reconstruction module to learn prototypical characters and their occurrence, deformation, and positioning. Our contributions are twofold. First, we introduce a deep architecture and learning methodology that enables efficient character modeling with only line-level transcription supervision, significantly improving over the Learnable Typewriter baseline and enabling accurate character bounding box prediction, unlocking its potential for paleographic measurements. Second, we introduce and demonstrate the paleographical relevance of automatic measurements enabled by our architecture for characters, bi-grams, and spaces between graphical units. For this demonstration, we extend the annotations of the codex Paris, BnF, fr. 2813, commissioned in the late fourteenth century by Charles V and copied by four hands, to 160 pages. We visualize our measurements over these pages, showing how they enable us not only to differentiate graphical profiles, but also to discover and analyze subtle variations. This case study outlines the scalability of our approach and its frugality in terms of required training data, since a single column of text is sufficient to compute our measurements on each of the 160 pages. Data and code are publicly available at: https://malamatenia.github.io/morphology4metrology-analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a transformer-based detection architecture paired with a prototype-based line reconstruction module can learn character prototypes solely from line-level transcriptions, yielding accurate bounding-box predictions that enable scalable, stable paleographic measurements (for characters, bigrams, and inter-unit spaces). It reports improvement over the Learnable Typewriter baseline and demonstrates the measurements on 160 annotated pages of Paris, BnF fr. 2813, asserting that a single text column suffices for per-page analysis.
Significance. If the accuracy and paleographic relevance claims hold, the approach would supply a low-supervision route from HTR to quantitative metrology, allowing large-scale script profiling with minimal annotation. The public release of data and code is a clear reproducibility asset.
major comments (2)
- [Abstract and §3] Abstract and §3 (method): the central claim that the architecture produces 'accurate character bounding box prediction' rests on line-level supervision alone, yet no quantitative metrics (IoU, precision@0.5, or box-level error) against character-level ground truth are reported; only qualitative visualizations on one codex are described.
- [§5] §5 (case study): the assertion that the derived measurements are 'meaningful and stable' and enable differentiation of graphical profiles is supported only by visualizations; no statistical tests for measurement variance across hands/pages, no expert paleographer validation, and no comparison to manual metrology are provided.
minor comments (1)
- [Abstract] The abstract states 'significantly improving over the Learnable Typewriter baseline' without citing the specific table or figure that quantifies the improvement.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The two major comments correctly identify that the manuscript relies primarily on qualitative evidence for its central claims. We address each point below and will revise the manuscript to qualify claims, add available quantitative elements where feasible, and clarify evaluation scope.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method): the central claim that the architecture produces 'accurate character bounding box prediction' rests on line-level supervision alone, yet no quantitative metrics (IoU, precision@0.5, or box-level error) against character-level ground truth are reported; only qualitative visualizations on one codex are described.
Authors: The observation is correct: the manuscript reports no IoU, precision, or box-error metrics against character-level ground truth. The architecture is trained exclusively with line-level transcriptions, and the available annotations on the 160 pages consist of transcriptions rather than dense bounding-box ground truth. We will revise the abstract and §3 to remove the unqualified claim of 'accurate' prediction and instead describe the bounding boxes as an intermediate representation whose utility is demonstrated through the downstream metrological measurements. A short note on the absence of box-level metrics will be added. revision: yes
-
Referee: [§5] §5 (case study): the assertion that the derived measurements are 'meaningful and stable' and enable differentiation of graphical profiles is supported only by visualizations; no statistical tests for measurement variance across hands/pages, no expert paleographer validation, and no comparison to manual metrology are provided.
Authors: We agree that the case study currently offers only visual evidence. We will add simple statistical summaries (e.g., per-hand and per-page variance of character widths and inter-unit spaces) to §5. However, expert paleographer validation and direct comparison against manual metrology are not present in the current study and would require new annotations and collaboration outside the scope of this work. revision: partial
- Expert paleographer validation of the automatic measurements and direct quantitative comparison against manual metrology on the same pages.
Circularity Check
No significant circularity; measurements are model outputs, not self-referential derivations.
full rationale
The paper presents a learned architecture (transformer detection + prototype reconstruction) trained on line-level transcriptions to produce character prototypes, bounding boxes, and derived metrological measurements. No equations, predictions, or uniqueness claims are shown that reduce these outputs to fitted inputs by construction, nor are there self-citations invoked as load-bearing premises for the central results. The measurements are explicitly described as direct outputs of the trained model applied to extended annotations on the Paris codex, with no renaming of known results or ansatz smuggling. The derivation chain is therefore self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
AIIA Notizie4, 34–38 (1999)
Aiolli, F., Simi, M., Sona, D., Sperduti, A., Starita, A., Zaccagnini, G.: Spi: A system for paleographic inspections. AIIA Notizie4, 34–38 (1999)
1999
-
[2]
IEEE Access9, 76674–76688 (2021)
Aradillas, J.C., Murillo-Fuentes, J.J., Olmos, P.M.: Boosting offline handwritten text recognition in historical documents with few labeled lines. IEEE Access9, 76674–76688 (2021)
2021
-
[3]
Advances in Neural Information Processing Systems37, 42388–42404 (2024)
Baena, R., Kalleli, S., Aubry, M.: General detection-based text line recognition. Advances in Neural Information Processing Systems37, 42388–42404 (2024)
2024
-
[4]
In: ACL Proceedings, vol.1
Berg-Kirkpatrick, T., Durrett, G., Klein, D.: Unsupervised transcription of historical documents. In: ACL Proceedings, vol.1. pp. 207–217 (2013)
2013
-
[5]
analyse sérielle de la densité de l’écriture dans les évangiles d’henri le lion
Bischoff, F.M.: Le rythme du scribe. analyse sérielle de la densité de l’écriture dans les évangiles d’henri le lion. Histoire & Mesure11(1/2), 53–91 (1996)
1996
-
[6]
In: ICDAR Proceedings
Bluche, T., Messina, R.: Gated convolutional recurrent neural networks for multi- lingual handwriting recognition. In: ICDAR Proceedings. pp. 646–651 (2017)
2017
-
[7]
In: 2016 12th IAPR DAS Workshop
Bluche, T., Stutzmann, D., Kermorvant, C.: Automatic handwritten character segmentation for paleographical character shape analysis. In: 2016 12th IAPR DAS Workshop. pp. 42–47. IEEE (2016)
2016
-
[8]
Digital Medievalist1(2005)
Ciula, A.: Digital palaeography: using the digital representation of medieval script to support palaeographic analysis. Digital Medievalist1(2005)
2005
-
[9]
Cambridge University Press (2003)
Derolez, A.: The palaeography of Gothic manuscript books: From the twelfth to the early sixteenth century. Cambridge University Press (2003)
2003
-
[10]
arXiv preprint arXiv:2104.07787 (2021) 16 Authors Suppressed Due to Excessive Length
Diaz, D.H., Qin, S., Ingle, R., Fujii, Y., Bissacco, A.: Rethinking text line recognition models. arXiv preprint arXiv:2104.07787 (2021) 16 Authors Suppressed Due to Excessive Length
arXiv 2021
-
[11]
In: Proceedings of the 2011 workshop on historical document imaging and processing
Fischer, A., Frinken, V., Fornés, A., Bunke, H.: Transcription alignment of latin manuscripts using hidden markov models. In: Proceedings of the 2011 workshop on historical document imaging and processing. pp. 29–36 (2011)
2011
-
[12]
ductus et rapport modulaire
Gilissen, L.: III. ductus et rapport modulaire. Scriptorium29(2), 235–244 (1975)
1975
-
[13]
In: Proceedings of the 23rd ICML
Graves, A., Fernández, S., Gomez, F., Schmidhuber, J.: Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks. In: Proceedings of the 23rd ICML. pp. 369–376 (2006)
2006
-
[14]
Neural Networks18(5–6), 602–610 (2005)
Graves, A., Schmidhuber, J.: Framewise phoneme classification with bidirectional lstm and other neural network architectures. Neural Networks18(5–6), 602–610 (2005)
2005
-
[15]
Codicology and palaeography in the digital age pp
Gurrado, M.: «graphoskop», uno strumento informatico per l’analisi paleografica quantitativa. Codicology and palaeography in the digital age pp. 251–259 (2009)
2009
-
[16]
In: Mesure et histoire médiévale
Gurrado, M., Stutzmann, D.: Mesure et histoire des écritures médiévales. In: Mesure et histoire médiévale. XLIIIe Congrès de la SHMESP, Histoire ancienne et médiévale, vol. 123, pp. 153–166. PUPS (2013)
2013
-
[17]
The Art Bulletin66(1), 97–117 (1984)
Hedeman, A.D.: Valois legitimacy: Editorial changes in charles v’s grandes chroniques de france. The Art Bulletin66(1), 97–117 (1984)
1984
-
[18]
In: 2018 ICFHR Proceedings
Jenckel, M., Bukhari, S.S., Dengel, A.: Transcription free lstm ocr model evaluation. In: 2018 ICFHR Proceedings. pp. 122–126 (2018)
2018
-
[19]
Pattern Recognition129, 108766 (2022)
Kang, L., Riba, P., Rusiñol, M., Fornés, A., Villegas, M.: Pay attention to what you read: non-recurrent handwritten text-line recognition. Pattern Recognition129, 108766 (2022)
2022
-
[20]
In: Proceedings of the AAAI Conference on AI
Li, M., Lv, T., Chen, J., Cui, L., Lu, Y., Florencio, D., Zhang, C., Li, Z., Wei, F.: Trocr: Transformer-based optical character recognition with pre-trained models. In: Proceedings of the AAAI Conference on AI. vol. 37, pp. 13094–13102 (2023)
2023
-
[21]
Pattern Recognition158, 110967 (2025)
Li, Y., Chen, D., Tang, T., Shen, X.: Htr-vt: Handwritten text recognition with vision transformer. Pattern Recognition158, 110967 (2025)
2025
-
[22]
Heritage Science11, article 38 (2023)
Mamatsis, A.R., Mamatsi, E., Chalatsis, C., et al.: A novel methodology for writer (hand) identification: Establishing rigas feraios wrote two important greek documents discovered in romania. Heritage Science11, article 38 (2023)
2023
-
[23]
McGillivray, M.: Statistical analysis of digital paleographic data: what can it tell us? Digital Studies/Le champ numérique (11) (2005)
2005
-
[24]
In: ICDAR Proceedings
Michael, J., Labahn, R., Grüning, T., Zöllner, J.: Evaluating sequence-to-sequence models for handwritten text recognition. In: ICDAR Proceedings. pp. 1286–1293 (2019)
2019
-
[25]
In: Proceedings of the IEEE/CVF ICCV
Monnier, T., Vincent, E., Ponce, J., Aubry, M.: Unsupervised layered image de- composition into object prototypes. In: Proceedings of the IEEE/CVF ICCV. pp. 8640–8650 (2021)
2021
-
[26]
Gazette du livre médiéval56(1), 5–20 (2011)
Muzerelle, D.: À la recherche d’algorithmes experts en écritures médiévales. Gazette du livre médiéval56(1), 5–20 (2011)
2011
-
[27]
l’écriture entre histoire et science
Muzerelle, D., Gurrado, M.: Analyse d’images et paléographie systématique. l’écriture entre histoire et science. Gazette du livre médiéval56-57(2011)
2011
-
[28]
jahrhunderts und ihre schrift
Oeser, W.: Raoulet d’orléans und henri du trévou, zwei französische berufschreiber des 14. jahrhunderts und ihre schrift. Archiv für Diplomatik42, 395–418 (1996)
1996
-
[29]
statistique et paléographie: peut-on utiliser le rapport modulaire dans l’expertise des écritures médiévales? Scriptorium29(2), 198–234 (1975)
Ornato, E.: Ii. statistique et paléographie: peut-on utiliser le rapport modulaire dans l’expertise des écritures médiévales? Scriptorium29(2), 198–234 (1975)
1975
-
[30]
In: Ornato, E
Ornato, E.: L’histoire du livre et les méthodes quantitatives: bilan de vingt ans de recherche. In: Ornato, E. (ed.) La face cachée du livre médiéval. Viella, Roma (1997) Leveraging Morphology for Historical Script Metrological Analysis 17
1997
-
[31]
In: ICDAR Proceedings
Peng, D., Jin, L., Wu, Y., Wang, Z., Cai, M.: A fast and accurate fully convolutional network for end-to-end handwritten chinese text segmentation and recognition. In: ICDAR Proceedings. pp. 25–30 (2019)
2019
-
[32]
Doctoral dissertation, Università Ca’ Foscari Venezia (2014)
Peretto, M.: Raoulet d’Orléans e la copia di manoscritti a Parigi nella seconda metà del XIV secolo. Doctoral dissertation, Università Ca’ Foscari Venezia (2014)
2014
-
[33]
PloS one16(4), e0249769 (2021)
Popović, M., Dhali, M.A., Schomaker, L.: Artificial intelligence based writer iden- tification generates new evidence for the unknown scribes of the dead sea scrolls exemplified by the great isaiah scroll (1qisaa). PloS one16(4), e0249769 (2021)
2021
-
[34]
Bibliothèque de l’École des chartes132(1), 101–110 (1974)
Poulle, E.: Paléographie et méthodologie: vers l’analyse scientifique des écritures médiévales. Bibliothèque de l’École des chartes132(1), 101–110 (1974)
1974
-
[35]
Puigcerver, J.: Are multidimensional recurrent layers really necessary for handwrit- ten text recognition? In: ICDAR Proceedings. pp. 67–72 (2017)
2017
-
[36]
Stanford University Press (1997)
Saenger, P.: Space between words: The origins of silent reading. Stanford University Press (1997)
1997
-
[37]
Shi, B., Bai, X., Yao, C.: An end-to-end trainable neural network for image-based sequencerecognitionanditsapplicationtoscenetextrecognition.IEEETransactions on Pattern Analysis and Machine Intelligence39(11), 2298–2304 (2016)
2016
-
[38]
In: ICDAR Proceedings
Siglidis, I., Gonthier, N., Gaubil, J., Monnier, T., Aubry, M.: The learnable type- writer: A generative approach to text analysis. In: ICDAR Proceedings. pp. 297—-
-
[39]
LNCC, Springer (2024)
2024
-
[40]
In: ICDAR Proceedings
Sinha, A., Jenckel, M., Bukhari, S.S., Dengel, A.: Unsupervised ocr model evaluation using gan. In: ICDAR Proceedings. pp. 1256–1261 (2019)
2019
-
[41]
Advances in Neural Information Processing Systems34, 5494–5505 (2021)
Smirnov, D., Gharbi, M., Fisher, M., Guizilini, V., Efros, A., Solomon, J.M.: Mari- onette: Self-supervised sprite learning. Advances in Neural Information Processing Systems34, 5494–5505 (2021)
2021
-
[42]
Les mutations du XIIe siècle et la datation des écritures par le profil scribal collectif
Stutzmann, D.: Conjuguer diplomatique, paléographie et édition électronique. Les mutations du XIIe siècle et la datation des écritures par le profil scribal collectif. In: Digital diplomatics. The computer as a tool for the diplomatist, pp. 271–290. No. 14 in Archiv für Diplomatik. Beiheft, Böhlau, Köln (2014)
2014
-
[43]
In: Words in the Middle Ages/Les Mots au Moyen Âge, pp
Stutzmann, D.: Words as graphic and linguistic structures: Word spacing in psalm 101 domine exaudi orationem meam (eleventh-fifteenth centuries). In: Words in the Middle Ages/Les Mots au Moyen Âge, pp. 21–59 (2020)
2020
-
[44]
In: DH2015 Global Digital Humanities (2015)
Stutzmann, D., Bluche, T., Lavrentiev, A., Leydier, Y., Kermorvant, C.: From text and image to historical resource: Text-image alignment for digital humanists. In: DH2015 Global Digital Humanities (2015)
2015
-
[45]
2813 - grandes chroniques de france (Apr 2025), https://doi.org/10.5281/zenodo.15282371
Vlachou Efstathiou, M.: Dataset for bnf, fr. 2813 - grandes chroniques de france (Apr 2025), https://doi.org/10.5281/zenodo.15282371
-
[46]
Scriptorium (forthcoming in 2026), https://malamatenia
Vlachou-Efstathiou, M.: Interpretable deep learning for palaeographic variability analysis; revisiting the scribal hands of Charles V’ grandes Chroniques de France (paris, bnf, fr., 2813). Scriptorium (forthcoming in 2026), https://malamatenia. github.io/bnf-fr-2813/
2026
-
[47]
In: ICDAR Proceed- ings
Vlachou-Efstathiou, M., Siglidis, I., Stutzmann, D., Aubry, M.: An interpretable deep learning approach for morphological script type analysis. In: ICDAR Proceed- ings. pp. 3–21. Springer (2024)
2024
-
[48]
In: 2016 ICFHR Proceedings
Voigtlaender, P., Doetsch, P., Ney, H.: Handwriting recognition with large multi- dimensional long short-term memory recurrent neural networks. In: 2016 ICFHR Proceedings. pp. 228–233 (2016)
2016
-
[49]
IEEE Transactions on Pattern Analysis and Machine Intelligence21(12), 1280–1296 (1999)
Xu, Y., Nagy, G.: Prototype extraction and adaptive ocr. IEEE Transactions on Pattern Analysis and Machine Intelligence21(12), 1280–1296 (1999)
1999
-
[50]
In: ICDAR Proceedings
Yin, F., Wang, Q.F., Zhang, X.Y., Liu, C.L.: Icdar 2013 chinese handwriting recognition competition. In: ICDAR Proceedings. pp. 1464–1470 (2013) 18 Authors Suppressed Due to Excessive Length
2013
-
[51]
Pattern Recognition p
Yu, M.M., Zhang, H., Yin, F., Liu, C.L.: An approach for handwritten chinese text recognition unifying character segmentation and recognition. Pattern Recognition p. 110373 (2024)
2024
-
[52]
Scrittura e civiltà 12, 135–176 (1988)
Zamponi, S.: Elisione e sovrapposizione nella littera textualis. Scrittura e civiltà 12, 135–176 (1988)
1988
-
[53]
arxiv preprint arXiv:2203.03605 (2022)
Zhang, H., Li, F., Liu, S., Zhang, L., Su, H., Zhu, J., Ni, L.M., Shum, H.Y.: Dino: Detr with improved denoising anchor boxes for end-to-end object detection. arxiv preprint arXiv:2203.03605 (2022)
Pith/arXiv arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.