When Summaries Distort Decisions: Information Fidelity in LLM-Compressed Financial Analysis
Pith reviewed 2026-06-30 07:38 UTC · model grok-4.3
The pith
LLM compression of financial filings and transcripts can alter the investment decisions supported by the originals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
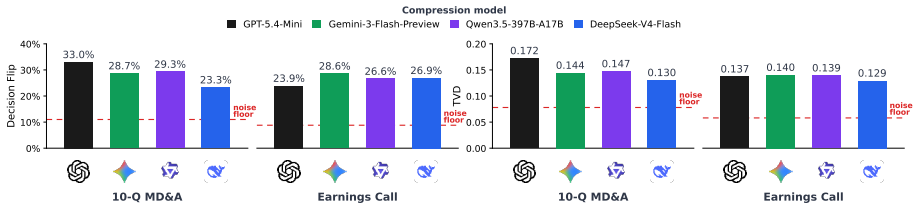
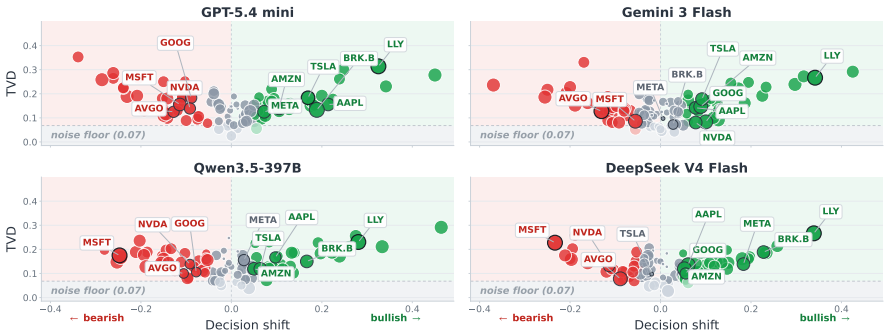
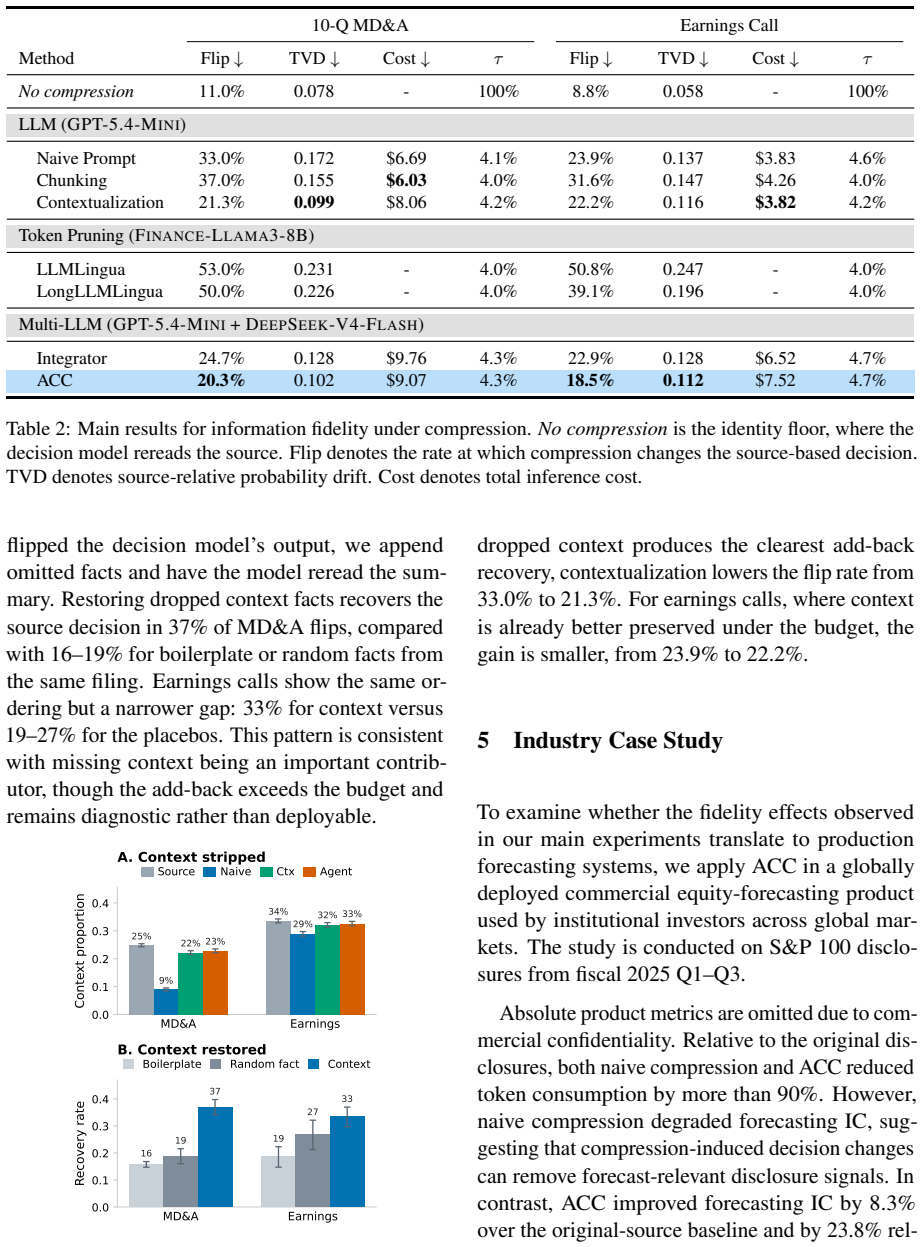
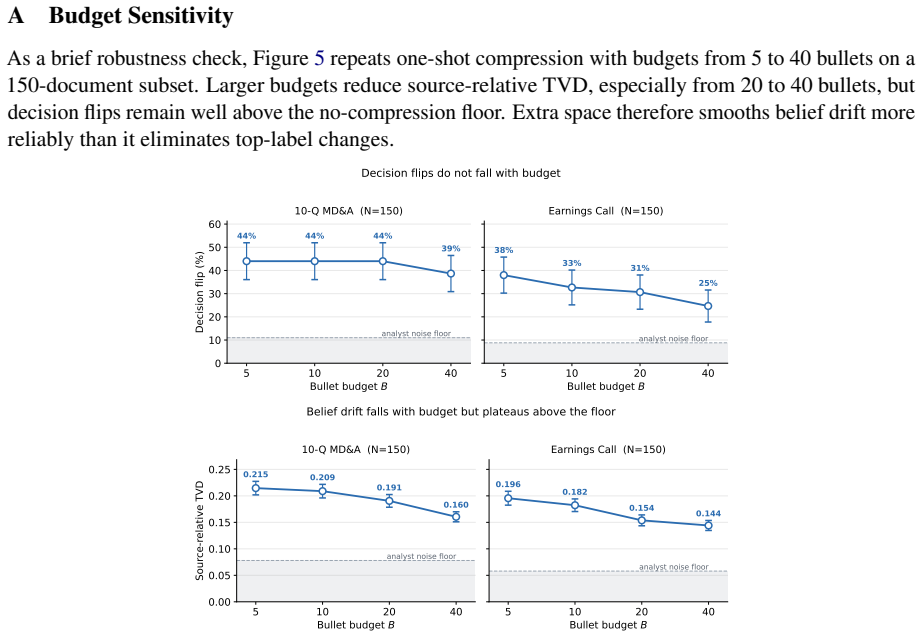
The paper claims that across financial filings and earnings-call transcripts, LLM-based compression can produce fluent and factually plausible compressed contexts that nevertheless alter downstream decisions. It frames the problem as information fidelity, where compression loses fidelity precisely when it changes the investment judgment supported by the original source. Two diagnostic patterns are identified: decontextualization, in which salient evidence is retained but separated from necessary caveats, and model dependency, in which different compressors produce different views of the same source. The authors then introduce Agentic Context Compression, which generates multiple candidate co
What carries the argument
Information fidelity, defined as the property that compression preserves the decision induced by the original source material rather than merely preserving facts or fluency.
If this is right
- Financial compression should be evaluated by its effect on decisions, not only by efficiency or factuality.
- Fidelity losses may recur across intermediate steps and amplify in agentic decision systems.
- Generating multiple compressions and auditing disagreements against the original can reduce decision alteration.
- Different compressor models expose different views of the same source, so model choice affects fidelity.
Where Pith is reading between the lines
- The same decision-preservation test could be applied to summarization in legal or medical domains where context qualifiers matter.
- Longer chains of agentic steps would likely increase the chance that small fidelity losses compound into larger decision shifts.
- Human verification of compressed contexts might become a required step for high-stakes financial reports.
Load-bearing premise
The investment decision induced by the original source material can be reliably and consistently determined independently of any compression process.
What would settle it
A controlled study in which independent human analysts derive identical investment decisions from the raw filings and transcripts but derive different decisions from the LLM-compressed versions would support the claim; if analysts instead derive the same decision from both original and compressed versions, the claim would be falsified.
Figures

read the original abstract
Financial decision-makers face more information than they can directly inspect, making context compression necessary. Yet when large language models (LLMs) compress financial source material, they can alter the investment judgment supported by the original source. We frame this problem as information fidelity: compression loses fidelity when it changes the decision induced by the source. In agentic systems, such losses may recur across intermediate steps and amplify throughout the decision process. Across financial filings and earnings-call transcripts, we find that LLM-based compression can produce fluent and factually plausible compressed contexts that nevertheless alter downstream decisions. We analyze two diagnostic patterns associated with fidelity loss: decontextualization, where salient evidence is retained but separated from the caveats and contextual qualifiers needed for correct interpretation, and model dependency, where different compressors expose different views of the same source. We then propose Agentic Context Compression, which generates multiple candidate compressions and audits their disagreements against the original source. Our results suggest that financial compression should be evaluated not only by efficiency or factuality, but also by its ability to preserve decision-relevant context.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript defines information fidelity as the degree to which LLM compression of financial source material (filings and earnings-call transcripts) preserves the investment decision induced by the uncompressed original. It reports that LLM compressors can generate fluent, factually plausible summaries that nevertheless change downstream decisions, attributes this to decontextualization (retaining evidence while stripping qualifiers) and model dependency (different compressors yielding divergent views), and proposes Agentic Context Compression, which generates multiple candidate summaries and audits their disagreements against the source to detect fidelity loss.
Significance. If the measurement of decision change is shown to be reliable, the work usefully reframes compression evaluation in agentic financial systems away from isolated factuality or fluency metrics toward preservation of decision-relevant context. The constructive proposal of auditing multiple compressions is a practical step that could be adopted in pipelines where fidelity matters. The empirical focus on real financial documents adds relevance, though the strength of the contribution hinges on the robustness of the decision-elicitation protocol.
major comments (2)
- [Experimental Setup] Experimental Setup (likely §3 or §4): The central claim requires a stable baseline decision D_original that can be compared to D_compressed. No inter-evaluator agreement statistics, test-retest consistency, or variance across human/LLM judges on the same original documents are reported. Without these, observed decision shifts cannot be confidently attributed to compression rather than baseline subjectivity in interpreting financial qualifiers and forward-looking statements.
- [Results] Results (likely §5): The abstract and main findings state that compression alters decisions, yet the manuscript supplies no error bars, statistical significance tests, or baseline compressors (e.g., extractive or rule-based) against which the magnitude of fidelity loss is compared. This weakens the quantitative support for the claim that LLM compression specifically induces the observed changes.
minor comments (2)
- [Introduction] The term 'information fidelity' is introduced without a formal definition or equation; a precise operationalization (e.g., decision divergence rate) would aid reproducibility.
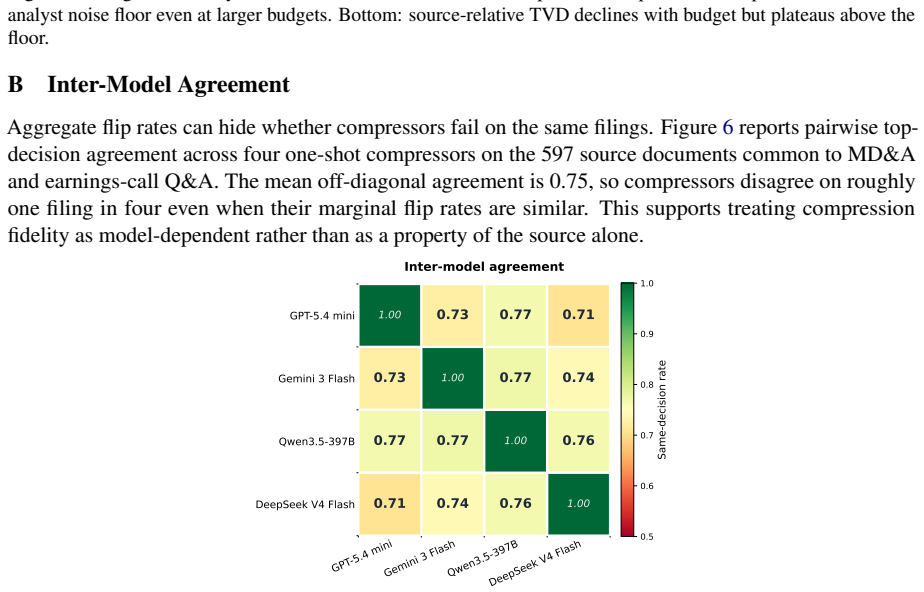
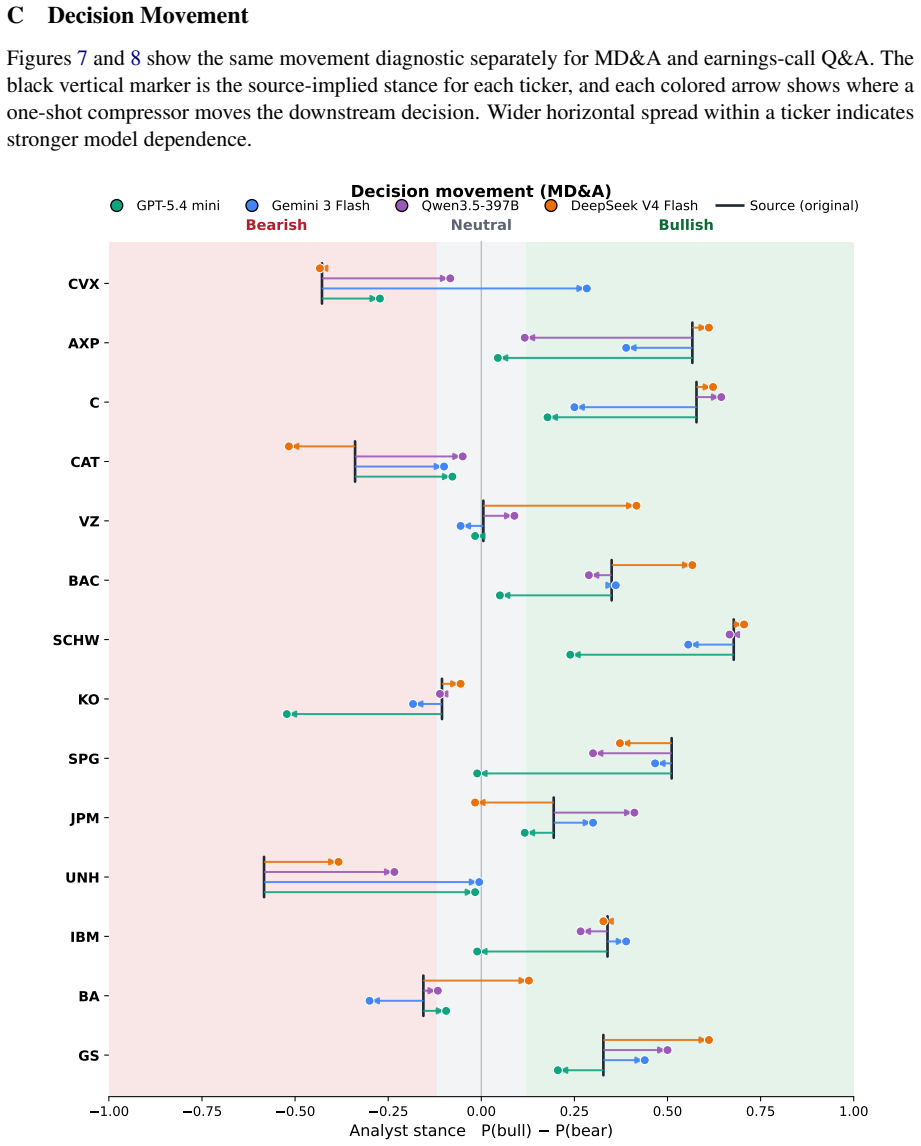
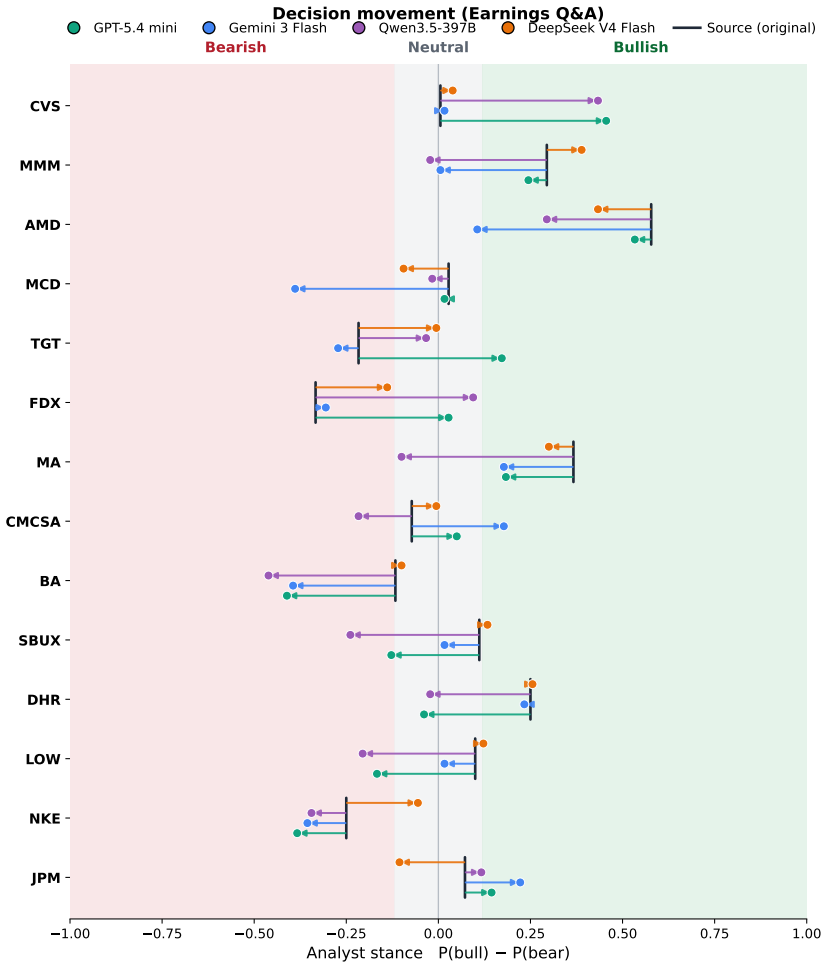
- [Figures/Tables] Figure captions and table headers should explicitly state the number of documents, evaluators, and compressor models used so that effect sizes can be interpreted without returning to the text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the need for greater rigor in validating the stability of our decision-elicitation protocol and in quantifying the effects. We address each major comment below.
read point-by-point responses
-
Referee: [Experimental Setup] Experimental Setup (likely §3 or §4): The central claim requires a stable baseline decision D_original that can be compared to D_compressed. No inter-evaluator agreement statistics, test-retest consistency, or variance across human/LLM judges on the same original documents are reported. Without these, observed decision shifts cannot be confidently attributed to compression rather than baseline subjectivity in interpreting financial qualifiers and forward-looking statements.
Authors: We agree that stability metrics for the baseline decision are necessary to attribute changes to compression. Our protocol used a single LLM judge at temperature 0 to promote determinism, but we did not report agreement or variance statistics. We will add a new subsection reporting test-retest consistency (repeated elicitations on originals) and variance across multiple LLM judges, which will allow readers to assess baseline subjectivity. revision: yes
-
Referee: [Results] Results (likely §5): The abstract and main findings state that compression alters decisions, yet the manuscript supplies no error bars, statistical significance tests, or baseline compressors (e.g., extractive or rule-based) against which the magnitude of fidelity loss is compared. This weakens the quantitative support for the claim that LLM compression specifically induces the observed changes.
Authors: We concur that error bars, significance testing, and non-LLM baselines would strengthen the quantitative claims. We will revise the results to include bootstrap-derived confidence intervals, paired statistical tests on decision-change rates, and an extractive baseline (TF-IDF sentence selection) to benchmark the magnitude of LLM-induced fidelity loss against simpler methods. revision: yes
Circularity Check
Empirical measurement of decision shifts; no derivations or fitted predictions
full rationale
The paper frames fidelity as an observable change in downstream investment decisions after LLM compression of filings/transcripts and reports empirical patterns (decontextualization, model dependency) plus a proposed auditing method. No equations, parameter fitting, or self-citation chains appear in the abstract or described content; the measurement pipeline compares decisions on original vs. compressed text without reducing any result to its own inputs by construction. This is a standard empirical study whose central claim does not collapse into self-definition or renaming.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Investment decisions can be consistently induced from source financial material and compared across compressed versions to quantify fidelity loss.
Reference graph
Works this paper leans on
-
[1]
Mohamed, Amr and Geng, Mingmeng and Vazirgiannis, Michalis and Shang, Guokan , editor =. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , month = jul, year =. doi:10.18653/v1/2025.acl-long.371 , pages =
-
[2]
The Fourteenth International Conference on Learning Representations , year =
Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models , author =. The Fourteenth International Conference on Learning Representations , year =
-
[3]
LLMs Corrupt Your Documents When You Delegate
Laban, Philippe and Schnabel, Tobias and Neville, Jennifer , year =. 2604.15597 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Min, Sewon and Krishna, Kalpesh and Lyu, Xinxi and Lewis, Mike and Yih, Wen-tau and Koh, Pang and Iyyer, Mohit and Zettlemoyer, Luke and Hajishirzi, Hannaneh , editor =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , month = dec, year =. doi:10.18653/v1/2023.emnlp-main.741 , pages =
-
[5]
, booktitle =
Wei, Jerry and Yang, Chengrun and Song, Xinying and Lu, Yifeng and Hu, Nathan and Huang, Jie and Tran, Dustin and Peng, Daiyi and Liu, Ruibo and Huang, Da and Du, Chao and Le, Quoc V. , booktitle =. 2024 , url =
2024
-
[6]
Zhang, Yusen and Zhang, Nan and Liu, Yixin and Fabbri, Alexander and Liu, Junru and Kamoi, Ryo and Lu, Xiaoxin and Xiong, Caiming and Zhao, Jieyu and Radev, Dragomir and McKeown, Kathleen and Zhang, Rui , editor =. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies...
-
[7]
Lei, Yuanyuan and Song, Kaiqiang and Cho, Sangwoo and Wang, Xiaoyang and Huang, Ruihong and Yu, Dong , editor =. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , month = jun, year =. doi:10.18653/v1/2024.naacl-long.291 , pages =
-
[8]
Aghaebe, Favour Yahdii and Apekey, Tanefa and Williams, Elizabeth and Moosavi, Nafise Sadat , year =. 2601.04889 , archivePrefix =
-
[9]
Glasserman, Paul and Lin, Caden , year =. 2309.17322 , archivePrefix =
-
[10]
Nakagawa, Kei and Hirano, Masanori and Fujimoto, Yugo , booktitle =. 2024 , archivePrefix =. doi:10.1109/BigData62323.2024.10826008 , url =
-
[11]
Lee, Hoyoung and Seo, Junhyuk and Park, Suhwan and Lee, Junhyeong and Ahn, Wonbin and Choi, Chanyeol and Lopez-Lira, Alejandro and Lee, Yongjae , booktitle =. 2025 , isbn =. doi:10.1145/3768292.3770375 , url =
-
[12]
Kong, Yaxuan and Lee, Hoyoung and Hwang, Yoontae and Lopez-Lira, Alejandro and Levy, Bradford and Mehta, Dhagash and Wen, Qingsong and Choi, Chanyeol and Lee, Yongjae and Zohren, Stefan , year =. 2602.14233 , archivePrefix =
-
[13]
doi:10.1145/3701716.3715289 , url =
Loukas, Lefteris and Billert, Fabian and Fergadiotis, Manos and Malakasiotis, Prodromos and Androutsopoulos, Ion , booktitle =. doi:10.1145/3701716.3715289 , url =
-
[14]
2026 , eprint =
Beyond Semantic Similarity: Rethinking Retrieval for Agentic Search via Direct Corpus Interaction , author =. 2026 , eprint =
2026
-
[15]
Jiang, Huiqiang and Wu, Qianhui and Lin, Chin-Yew and Yang, Yuqing and Qiu, Lili , editor =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , month = dec, year =. doi:10.18653/v1/2023.emnlp-main.825 , pages =
-
[16]
Jiang, Huiqiang and Wu, Qianhui and Luo, Xufang and Li, Dongsheng and Lin, Chin-Yew and Yang, Yuqing and Qiu, Lili , editor =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , month = aug, year =. doi:10.18653/v1/2024.acl-long.91 , pages =
-
[17]
Mayilvaghanan, Kawin and Gupta, Siddhant and Kumar, Ayush , year =. 2508.13124 , archivePrefix =
-
[18]
ACON: Optimizing Context Compression for Long-horizon LLM Agents
Kang, Minki and Chen, Wei-Ning and Han, Dongge and Inan, Huseyin A. and Wutschitz, Lukas and Chen, Yanzhi and Sim, Robert and Rajmohan, Saravan , year =. 2510.00615 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
2021 , eprint =
Choi, Eunsol and Palomaki, Jennimaria and Lamm, Matthew and Kwiatkowski, Tom and Das, Dipanjan and Collins, Michael , journal =. 2021 , eprint =
2021
-
[20]
Gunjal, Anisha and Durrett, Greg , year =. 2406.20079 , archivePrefix =
- [21]
-
[22]
2025 , eprint =
Trienes, Jan and Schl. 2025 , eprint =
2025
-
[23]
Zhukova, Anastasia and Ruas, Terry and Hamborg, Felix and Donnay, Karsten and Gipp, Bela , year =. 2508.02540 , archivePrefix =
-
[24]
FinGround: Detecting and Grounding Financial Hallucinations via Atomic Claim Verification
Guo, Dongxin and Wu, Jikun and Yiu, Siu Ming , year =. 2604.23588 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Ning, Yucheng and Lin, Xixun and Fang, Fang and Cao, Yanan , year =. 2510.22967 , archivePrefix =
-
[26]
Alessa, Abeer and Somane, Param and Lakshminarasimhan, Akshaya and Skirzynski, Julian and McAuley, Julian and Echterhoff, Jessica , year =. 2507.03194 , archivePrefix =
-
[27]
Peters, Uwe and Chin-Yee, Benjamin , year =. 2504.00025 , archivePrefix =
-
[28]
Frame In, Frame Out: Measuring Framing Bias in LLM-Generated News Summaries
Pastorino, Valeria and Moosavi, Nafise Sadat , year =. 2505.05406 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Zhang, Tinghui and Wang, Yifan and Wang, Daisy Zhe , year =. 2508.15813 , archivePrefix =
-
[30]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[31]
Publications Manual , year = "1983", publisher =
1983
-
[32]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[33]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[34]
Dan Gusfield , title =. 1997
1997
-
[35]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[36]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.