VVitCutLER: Towards Unsupervised Object Detection and Segmentation in Videos
Pith reviewed 2026-05-20 22:26 UTC · model grok-4.3
The pith
Enforcing cross-frame region consistency in pseudo-labels stabilizes unsupervised video object detection and segmentation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
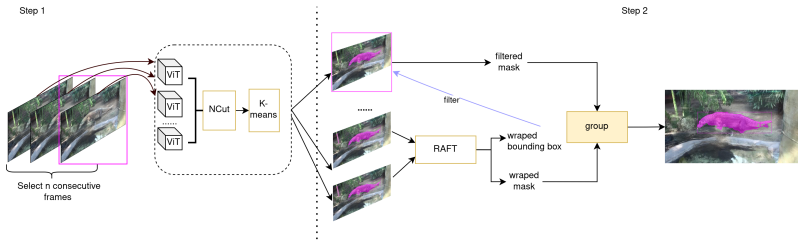
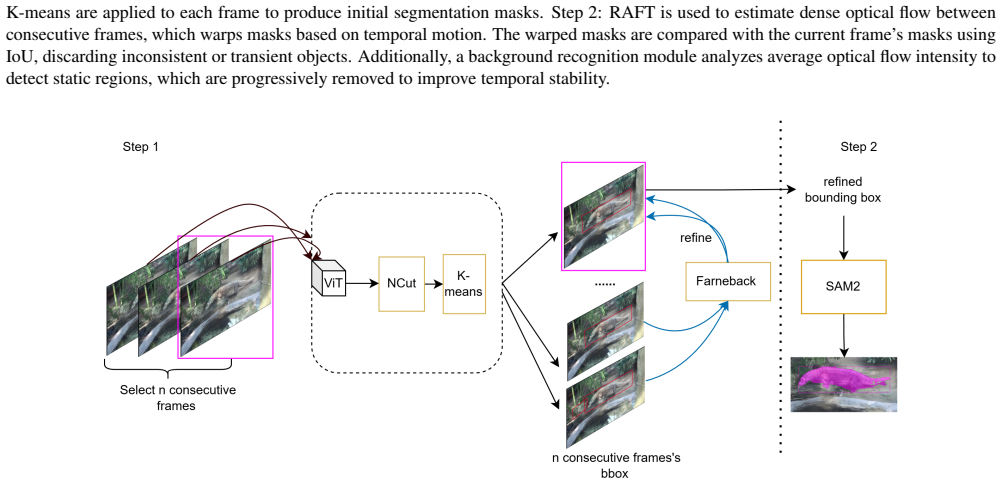
VitCut generates temporally stable pseudo-labels by enforcing cross-frame region consistency to limit error accumulation during field degradation, while a distillation decoder handles instance mask prediction; VVitCutLER then layers cross-frame feature aggregation on top to boost video-level robustness, yielding higher detection and segmentation performance with reduced temporal instability on standard benchmarks.
What carries the argument
VitCut, a pseudo-label generator that reduces error accumulation via cross-frame region consistency and uses a distillation decoder for instance mask prediction.
If this is right
- Detection and segmentation accuracy rises on video benchmarks when temporal consistency is added to pseudo-label generation.
- Flickering and drift in pseudo-labels decrease because region consistency is maintained across adjacent frames.
- Video-level robustness improves through the addition of cross-frame feature aggregation after VitCut.
- Unsupervised pixel-level understanding becomes more practical in real-world settings with motion blur and occlusions.
Where Pith is reading between the lines
- Similar consistency mechanisms could be tested on unsupervised video tracking or action recognition to check whether they reduce drift in those tasks as well.
- The framework might lower reliance on manual labels for applications such as traffic monitoring or robotic navigation if the stability gains hold across diverse datasets.
- Extending the cross-frame aggregation to longer sequences or multi-camera setups could reveal whether the same principles scale to more complex video environments.
Load-bearing premise
Enforcing cross-frame region consistency in the pseudo-label generator will reliably cut error accumulation and temporal drift without creating new biases that lower overall performance.
What would settle it
Running the method on a video benchmark where detection and segmentation scores match or fall below non-consistent baselines, or where temporal flicker increases rather than decreases, would show the central claim does not hold.
Figures









read the original abstract
Unsupervised pixel-level video understanding remains challenging in real-world scenarios, where motion blur, occlusion, and fast object dynamics often cause temporal drift and flickering pseudo-labels.We propose VVitCutLER, an unsupervised framework for video object detection and instance segmentation, which improves the quality of pseudo-labels through temporal consistency. Our core contribution is VitCut, a temporarily stable pseudo-label generator that reduces error accumulation during field degradation through cross-frame region consistency. Meanwhile, VitCut uses a distillation decoder to achieve effective instance mask prediction. Then, based on VitCut, VVitCutLER further integrates cross-frame feature aggregation to enhance video-level robustness. Extensive experiments on standard video benchmarks demonstrate that VVitCutLER significantly improves detection and segmentation performance while reducing temporal instability. These results highlight the importance of temporally consistent supervision for robust pixel-level video understanding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes VVitCutLER, an unsupervised framework for video object detection and instance segmentation. Its core contribution is VitCut, a pseudo-label generator that enforces cross-frame region consistency to produce temporally stable labels and reduce error accumulation from motion blur, occlusion, and fast dynamics. It incorporates a distillation decoder for instance mask prediction and adds cross-frame feature aggregation for video-level robustness. Experiments on standard video benchmarks are reported to demonstrate significant gains in detection/segmentation performance together with reduced temporal instability.
Significance. If the central claims are substantiated, the work could advance unsupervised pixel-level video understanding by showing how explicit temporal consistency mechanisms can mitigate drift and flickering in pseudo-labels. The emphasis on cross-frame consistency as a means to improve robustness in challenging real-world conditions is a relevant direction for the field.
major comments (2)
- [VitCut description] VitCut section: The claim that cross-frame region consistency reliably reduces error accumulation (rather than propagating initial pseudo-label noise) is load-bearing for the central contribution. The manuscript must provide concrete analysis or ablations showing that the matching mechanism correctly identifies corresponding regions under the occlusion and fast-motion cases explicitly listed as challenges; without this, the risk that consistency locks in or spreads errors remains unaddressed.
- [Experiments] Experiments section: Reported improvements in detection and segmentation must be accompanied by quantitative temporal-stability metrics (e.g., frame-to-frame mask IoU consistency or flicker scores) and direct comparisons against recent unsupervised video baselines; current claims of reduced instability rest on qualitative statements that are insufficient to support the headline result.
minor comments (2)
- [Abstract] Abstract: 'temporarily stable' is almost certainly a typo for 'temporally stable'.
- [Abstract] Abstract: The phrase 'during field degradation' is unclear; rephrase to specify whether feature, label, or another form of degradation is intended.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We have addressed each major comment below and revised the manuscript to incorporate additional analysis and quantitative evaluations where appropriate.
read point-by-point responses
-
Referee: [VitCut description] VitCut section: The claim that cross-frame region consistency reliably reduces error accumulation (rather than propagating initial pseudo-label noise) is load-bearing for the central contribution. The manuscript must provide concrete analysis or ablations showing that the matching mechanism correctly identifies corresponding regions under the occlusion and fast-motion cases explicitly listed as challenges; without this, the risk that consistency locks in or spreads errors remains unaddressed.
Authors: We appreciate the referee's emphasis on this critical aspect of our contribution. The cross-frame region consistency in VitCut is intended to enforce temporal coherence and thereby limit drift from motion blur, occlusion, and fast dynamics. To directly address the concern regarding potential error propagation, we have added new ablation studies and visualizations in the revised manuscript. These include quantitative matching accuracy metrics on challenging subsequences exhibiting occlusion and rapid motion, as well as qualitative examples demonstrating correct region correspondence. We also discuss cases where initial pseudo-label noise may be reinforced and how the overall framework mitigates this through the distillation decoder. revision: yes
-
Referee: [Experiments] Experiments section: Reported improvements in detection and segmentation must be accompanied by quantitative temporal-stability metrics (e.g., frame-to-frame mask IoU consistency or flicker scores) and direct comparisons against recent unsupervised video baselines; current claims of reduced instability rest on qualitative statements that are insufficient to support the headline result.
Authors: We agree that explicit quantitative metrics are necessary to substantiate claims of reduced temporal instability. In the revised manuscript, we now report frame-to-frame mask IoU consistency and a flicker score computed across video sequences on the evaluated benchmarks. We have also included direct comparisons against recent unsupervised video object detection and segmentation baselines. These additions provide empirical support for improved stability alongside the reported gains in detection and segmentation performance. revision: yes
Circularity Check
No significant circularity; derivation relies on novel architectural components and empirical evaluation
full rationale
The paper introduces VitCut as a new pseudo-label generator enforcing cross-frame region consistency plus a distillation decoder, then builds VVitCutLER by adding cross-frame feature aggregation. These are presented as independent design choices whose value is assessed via experiments on standard video benchmarks. No equations, fitted parameters, or self-citations are shown to reduce the central performance claims to tautological redefinitions or inputs by construction. The framework is self-contained against external benchmarks and does not invoke uniqueness theorems or prior self-work as load-bearing justification.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shahaf Arica, Or Rubin, Sapir Gershov, and Shlomi Laufer. Cuvler: Enhanced unsupervised object discoveries through exhaustive self-supervised transformers, 2024. 2, 3
work page 2024
-
[2]
Cascade r-cnn: Delving into high quality object detection, 2017
Zhaowei Cai and Nuno Vasconcelos. Cascade r-cnn: Delving into high quality object detection, 2017. 6
work page 2017
-
[3]
End-to- end object detection with transformers, 2020
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to- end object detection with transformers, 2020. 2
work page 2020
-
[4]
Emerg- ing properties in self-supervised vision transformers, 2021
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv ´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerg- ing properties in self-supervised vision transformers, 2021. 3
work page 2021
-
[5]
Ishan Dave, Rohit Gupta, Mamshad Nayeem Rizve, and Mubarak Shah. Tclr: Temporal contrastive learning for video representation.Computer Vision and Image Understanding, 219:103406, 2022. 3
work page 2022
-
[6]
Mevis: A large-scale benchmark for video segmentation with motion expressions, 2023
Henghui Ding, Chang Liu, Shuting He, Xudong Jiang, and Chen Change Loy. Mevis: A large-scale benchmark for video segmentation with motion expressions, 2023. 3
work page 2023
-
[7]
Henghui Ding, Chang Liu, Shuting He, Xudong Jiang, Philip H. S. Torr, and Song Bai. Mose: A new dataset for video object segmentation in complex scenes, 2023. 3
work page 2023
-
[8]
Henghui Ding, Chang Liu, Shuting He, Kaining Ying, Xudong Jiang, Chen Change Loy, and Yu-Gang Jiang. Mevis: A multi-modal dataset for referring motion expres- sion video segmentation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 47(12):11400–11416,
-
[9]
Henghui Ding, Kaining Ying, Chang Liu, Shuting He, Xudong Jiang, Yu-Gang Jiang, Philip H. S. Torr, and Song Bai. Mosev2: A more challenging dataset for video object segmentation in complex scenes, 2025. 3
work page 2025
-
[10]
Two-frame motion estimation based on polynomial expansion
Gunnar Farneb ¨ack. Two-frame motion estimation based on polynomial expansion. InScandinavian conference on Im- age analysis, pages 363–370. Springer, 2003. 4
work page 2003
-
[11]
Sergio Fernandez-Testa and Edwin Salcedo. Distributed in- telligent video surveillance for early armed robbery detection based on deep learning, 2024. 1
work page 2024
-
[12]
Rich feature hierarchies for accurate object detection and semantic segmentation, 2014
Ross Girshick, Jeff Donahue, Trevor Darrell, and Jitendra Malik. Rich feature hierarchies for accurate object detection and semantic segmentation, 2014. 2
work page 2014
-
[13]
Tokencut: Segmentation-free object discovery by clustering tokens
Jiawen Guo, Luming Xie, Zhe Lin, and Chen Change Loy. Tokencut: Segmentation-free object discovery by clustering tokens. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022. 3
work page 2022
-
[14]
Hadi Hadizadeh and Ivan V . Baji´c. Learned multimodal com- pression for autonomous driving, 2024. 1
work page 2024
-
[15]
Emanuela Haller and Marius Leordeanu. Unsupervised ob- ject segmentation in video by efficient selection of highly probable positive features, 2017. 3
work page 2017
-
[16]
Seq-nms for video object detection
Wei Han, Anna Khoreva, Eddy Ilg, Deqing Sun, Varun Jampani, Edward Adelson, Michael Black, Andreas Geiger, Alexey Dosovitskiy, and Thomas Brox. Seq-nms for video object detection. InICCV, 2016. 3
work page 2016
-
[17]
Kaiming He, Georgia Gkioxari, Piotr Doll ´ar, and Ross Gir- shick. Mask r-cnn, 2018. 2
work page 2018
-
[18]
Momentum contrast for unsupervised visual rep- resentation learning, 2020
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual rep- resentation learning, 2020. 3
work page 2020
-
[19]
Transvod: End-to-end video object detection with spatial- temporal transformers
Tao He, Ziyi Wu, Enze Xie, Ding Liang, and Chunhua Shen. Transvod: End-to-end video object detection with spatial- temporal transformers. InCVPR, 2022. 3
work page 2022
-
[20]
Uvis: Unsupervised video instance segmentation, 2024
Shuaiyi Huang, Saksham Suri, Kamal Gupta, Sai Saketh Rambhatla, Ser nam Lim, and Abhinav Shrivastava. Uvis: Unsupervised video instance segmentation, 2024. 7
work page 2024
-
[21]
T-cnn: Tubelets with convolutional neural networks for object detection from videos
Kai Kang, Wanli Ouyang, Hongsheng Li, and Xiaogang Wang. T-cnn: Tubelets with convolutional neural networks for object detection from videos. InICCV, 2017. 3
work page 2017
-
[22]
Mo- tion guided attention for video salient object detection, 2019
Haofeng Li, Guanqi Chen, Guanbin Li, and Yizhou Yu. Mo- tion guided attention for video salient object detection, 2019. 2
work page 2019
-
[23]
Focal loss for dense object detection, 2018
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Doll´ar. Focal loss for dense object detection, 2018. 2
work page 2018
-
[24]
Berg.SSD: Single Shot MultiBox Detector, page 21–37
Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, and Alexander C. Berg.SSD: Single Shot MultiBox Detector, page 21–37. Springer International Publishing, 2016. 2
work page 2016
-
[25]
Learning temporal cues by predicting ob- jects move for multi-camera 3d object detection, 2024
Seokha Moon, Hongbeen Park, Jungphil Kwon, Jaekoo Lee, and Jinkyu Kim. Learning temporal cues by predicting ob- jects move for multi-camera 3d object detection, 2024. 1
work page 2024
-
[26]
Thuy C. Nguyen, Tuan N. Tang, Nam LH. Phan, Chuong H. Nguyen, Masayuki Yamazaki, and Masao Yamanaka. 1st place solution for youtubevos challenge 2021:video instance segmentation, 2021. 5
work page 2021
-
[27]
Tubetk: Adopting tubes to track multi-object in a one-step training model, 2020
Bo Pang, Yizhuo Li, Yifan Zhang, Muchen Li, and Cewu Lu. Tubetk: Adopting tubes to track multi-object in a one-step training model, 2020. 2
work page 2020
-
[28]
The 2017 DAVIS Challenge on Video Object Segmentation
Jordi Pont-Tuset, Federico Perazzi, Sergi Caelles, Pablo Ar- bel´aez, Alexander Sorkine-Hornung, and Luc Van Gool. The 2017 davis challenge on video object segmentation. arXiv:1704.00675, 2017. 5
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[29]
Sam 2: Segment anything in images and videos,
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junt- ing Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao- Yuan Wu, Ross Girshick, Piotr Doll´ar, and Christoph Feicht- enhofer. Sam 2: Segment anything in images and videos,
-
[30]
You only look once: Unified, real-time object de- tection, 2016
Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. You only look once: Unified, real-time object de- tection, 2016. 2
work page 2016
-
[31]
Faster r-cnn: Towards real-time object detection with region proposal networks, 2016
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks, 2016. 2
work page 2016
-
[32]
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, San- jeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, and Li Fei-Fei. Imagenet large scale visual recognition challenge,
-
[33]
Flowcut: Unsupervised video instance segmentation via temporal mask matching,
Alp Eren Sari and Paolo Favaro. Flowcut: Unsupervised video instance segmentation via temporal mask matching,
-
[34]
Yolov: Making still image object detectors great at video object detection,
Yuheng Shi, Naiyan Wang, and Xiaojie Guo. Yolov: Making still image object detectors great at video object detection,
-
[35]
Practical video object detection via feature selection and aggregation, 2024
Yuheng Shi, Tong Zhang, and Xiaojie Guo. Practical video object detection via feature selection and aggregation, 2024. 3
work page 2024
-
[36]
V o, Simon Roburin, Spyros Gidaris, Andrei Bursuc, Patrick P ´erez, Renaud Mar- let, and Jean Ponce
Oriane Sim ´eoni, Gilles Puy, Huy V . V o, Simon Roburin, Spyros Gidaris, Andrei Bursuc, Patrick P ´erez, Renaud Mar- let, and Jean Ponce. Localizing objects with self-supervised transformers and no labels, 2021. 3
work page 2021
-
[37]
Raft: Recurrent all-pairs field transforms for optical flow, 2020
Zachary Teed and Jia Deng. Raft: Recurrent all-pairs field transforms for optical flow, 2020. 4, 1
work page 2020
-
[38]
Zhan Tong, Yibing Song, Jue Wang, and Limin Wang. Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training, 2022. 3
work page 2022
-
[39]
Xudong Wang, Rohit Girdhar, Stella X. Yu, and Ishan Misra. Cut and learn for unsupervised object detection and instance segmentation, 2023. 2, 3, 5
work page 2023
-
[40]
Videocutler: Surprisingly simple unsuper- vised video instance segmentation, 2023
Xudong Wang, Ishan Misra, Ziyun Zeng, Rohit Girdhar, and Trevor Darrell. Videocutler: Surprisingly simple unsuper- vised video instance segmentation, 2023. 3, 7
work page 2023
-
[41]
Simple online and realtime tracking with a deep association metric,
Nicolai Wojke, Alex Bewley, and Dietrich Paulus. Simple online and realtime tracking with a deep association metric,
-
[42]
Sequence level semantics aggregation for video ob- ject detection, 2019
Haiping Wu, Yuntao Chen, Naiyan Wang, and Zhaoxiang Zhang. Sequence level semantics aggregation for video ob- ject detection, 2019. 2, 3, 5
work page 2019
-
[43]
Segmenting moving objects via an object-centric layered representation,
Junyu Xie, Weidi Xie, and Andrew Zisserman. Segmenting moving objects via an object-centric layered representation,
-
[44]
Liang Yan, Qing Wang, Song Ma, Jian Wang, and Chong Yu. Solve the puzzle of instance segmentation in videos: A weakly supervised framework with spatio-temporal collabo- ration.IEEE Transactions on Circuits and Systems for Video Technology, 33(1):393–406, 2023. 3
work page 2023
-
[45]
Self-supervised video object segmentation by motion grouping
Charig Yang, Hala Lamdouar, Erika Lu, Andrew Zisserman, and Weidi Xie. Self-supervised video object segmentation by motion grouping. InICCV, 2021. 7
work page 2021
-
[46]
Unsupervised moving object detection via contextual information separation
Yanchao Yang, Antonio Loquercio, Davide Scaramuzza, and Stefano Soatto. Unsupervised moving object detection via contextual information separation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 879–888, 2019. 3
work page 2019
-
[47]
Bytetrack: Multi-object tracking by associating every detection box, 2022
Yifu Zhang, Peize Sun, Yi Jiang, Dongdong Yu, Fucheng Weng, Zehuan Yuan, Ping Luo, Wenyu Liu, and Xinggang Wang. Bytetrack: Multi-object tracking by associating every detection box, 2022. 3
work page 2022
-
[48]
Flow-guided feature aggregation for video object de- tection, 2017
Xizhou Zhu, Yujie Wang, Jifeng Dai, Lu Yuan, and Yichen Wei. Flow-guided feature aggregation for video object de- tection, 2017. 2, 3
work page 2017
-
[49]
Deformable detr: Deformable transformers for end-to-end object detection, 2021
Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. Deformable detr: Deformable transformers for end-to-end object detection, 2021. 2
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.