LAUKIN: A Multi-jurisdictional Common Law Contract Dataset
Pith reviewed 2026-06-27 06:49 UTC · model grok-4.3
The pith
LAUKIN reveals that drafting conventions diverge across common law jurisdictions, making legal equivalence classification non-trivial.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
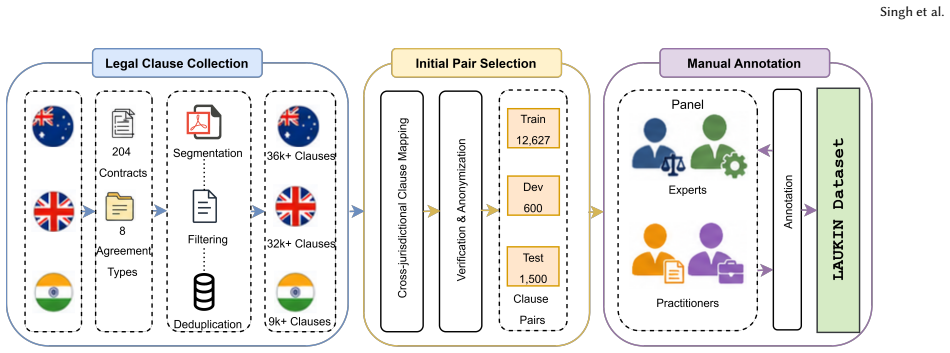
LAUKIN comprises 14,727 clause pairs from 204 contracts across eight agreement types in three jurisdictions, with 3,000 pairs labelled by legal experts as Equivalent or Not Equivalent. Twelve models evaluated across four techniques achieve a best macro-F1 of 65.11 percent, and analysis shows that despite shared legal heritage the drafting conventions differ enough to make cross-jurisdictional equivalence a difficult task.
What carries the argument
The LAUKIN dataset of cross-jurisdictional clause pairs, constructed via multi-stage retrieval and reranking then expert labelling for boolean legal equivalence.
If this is right
- Current NLP models cannot reliably determine legal equivalence of clauses across Australia, UK and India.
- The divergence in drafting means cross-jurisdictional review requires jurisdiction-aware approaches.
- The unlabelled pairs open the door to semi-supervised learning experiments in legal text.
- Single-jurisdiction datasets are inadequate for multinational contract work.
Where Pith is reading between the lines
- Adding explicit jurisdiction identifiers to models might raise performance above the current 65 percent ceiling.
- The construction method could be replicated for contracts involving civil-law jurisdictions to test broader patterns.
- Low performance may indicate that legal equivalence depends on obligation-level semantics beyond clause text matching.
Load-bearing premise
The multi-stage retrieval and reranking pipeline produces clause pairs whose legal equivalence experts can judge without systematic bias introduced by the matching process.
What would settle it
A re-annotation study by independent experts that finds substantial disagreement with the original labels due to retrieval bias, or any model that exceeds 80 percent macro-F1 on the existing test split.
Figures

read the original abstract
Multinational companies increasingly require cross-jurisdictional contract review, yet existing legal NLP datasets are largely restricted to a single jurisdiction. We introduce LAUKIN (Legal equivalence dataset of Australia, UK, and INdia), a dataset of clause pairs (AU-UK, UK-IN, IN-AU) labelled for boolean legal equivalence. We develop a novel multi-stage retrieval and reranking pipeline to construct the initial clause pair mapping, with a subset of clause pairs subsequently annotated by legal experts as Equivalent or Not Equivalent. The dataset comprises 14,727 clause pairs from 204 contracts across 8 agreement types, of which 3,000 are manually labelled: 900 train, 600 dev, and 1,500 test. We evaluate 12 models across 4 techniques, achieving a best macro-F1 of 65.11%, establishing LAUKIN as a challenging benchmark. Results reveal that, despite shared legal heritage, drafting conventions diverge significantly across jurisdictions, making cross-jurisdictional equivalence classification non-trivial. LAUKIN also includes 11,727 unlabelled training pairs to support future semi-supervised learning research in legal NLP.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LAUKIN, a dataset of 14,727 clause pairs drawn from 204 contracts across Australia, UK, and India (8 agreement types). A multi-stage retrieval and reranking pipeline generates candidate pairs; 3,000 of them receive expert binary labels for legal equivalence and are split 900/600/1,500. Twelve models across four techniques are evaluated, with the best macro-F1 reaching 65.11 %. The authors conclude that drafting conventions diverge substantially across jurisdictions, rendering cross-jurisdictional equivalence classification non-trivial, and release the remaining 11,727 pairs for semi-supervised research.
Significance. If the labeled subset is shown to be representative and free of retrieval-induced bias, LAUKIN would constitute a useful benchmark for an under-served multi-jurisdictional legal-NLP setting and would supply concrete evidence of practical drafting divergence. The provision of a large unlabeled pool is a positive feature for future semi-supervised work.
major comments (3)
- [§3] §3 (multi-stage retrieval and reranking pipeline): no error analysis, precision/recall figures, or negative-sampling protocol is supplied for the initial mapping step. Because the 3,000 expert-labeled pairs are drawn exclusively from the output of this pipeline, any lexical or surface-similarity bias in the retriever directly undermines the claim that the observed 65.11 % macro-F1 and the “significant divergence” conclusion reflect real cross-jurisdictional practice rather than an artifact of the construction heuristic.
- [Annotation protocol] Annotation protocol (construction and labeling paragraphs): inter-annotator agreement is not reported for the 3,000 expert labels. Without IAA or a documented blinding procedure, the reliability of the ground-truth labels that support all experimental results cannot be assessed.
- [Dataset description and §5] Dataset description and §5 (experimental results): no distributional comparison is provided between the 3,000 labeled pairs and the 11,727 unlabeled pairs, nor any test confirming that the retrieval pipeline did not systematically under-sample semantically equivalent but lexically divergent clauses. This validation is load-bearing for the benchmark claim and the generalization to “real cross-jurisdictional practice.”
minor comments (2)
- [Abstract and §4] The abstract states 14,727 total pairs while the body reports 3,000 labeled + 11,727 unlabeled; a single consolidated table would eliminate any arithmetic ambiguity.
- [§5] Model names, hyper-parameters, and exact prompting templates for the four techniques should be listed in an appendix or table to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the LAUKIN dataset paper. We address each major comment below, indicating planned revisions to improve clarity on dataset construction and validation.
read point-by-point responses
-
Referee: [§3] §3 (multi-stage retrieval and reranking pipeline): no error analysis, precision/recall figures, or negative-sampling protocol is supplied for the initial mapping step. Because the 3,000 expert-labeled pairs are drawn exclusively from the output of this pipeline, any lexical or surface-similarity bias in the retriever directly undermines the claim that the observed 65.11 % macro-F1 and the “significant divergence” conclusion reflect real cross-jurisdictional practice rather than an artifact of the construction heuristic.
Authors: We agree that the absence of quantitative analysis for the retrieval pipeline leaves open the possibility of surface-similarity bias. The pipeline combined BM25 retrieval with a cross-encoder reranker to surface candidate pairs across jurisdictions, but we did not report precision/recall or error analysis for the initial mapping step. We will revise §3 to include a limitations subsection discussing potential biases, the negative-sampling strategy employed, and the rationale for focusing expert effort on the resulting candidates rather than exhaustive search. revision: yes
-
Referee: [Annotation protocol] Annotation protocol (construction and labeling paragraphs): inter-annotator agreement is not reported for the 3,000 expert labels. Without IAA or a documented blinding procedure, the reliability of the ground-truth labels that support all experimental results cannot be assessed.
Authors: The 3,000 pairs were labeled by legal experts with domain knowledge of the relevant jurisdictions. We will expand the annotation protocol description to detail the blinding procedures used and the overall labeling workflow. However, inter-annotator agreement was not computed during the original annotation process. revision: partial
-
Referee: [Dataset description and §5] Dataset description and §5 (experimental results): no distributional comparison is provided between the 3,000 labeled pairs and the 11,727 unlabeled pairs, nor any test confirming that the retrieval pipeline did not systematically under-sample semantically equivalent but lexically divergent clauses. This validation is load-bearing for the benchmark claim and the generalization to “real cross-jurisdictional practice.”
Authors: We acknowledge that representativeness of the labeled subset relative to the full pool is important for the benchmark claim. The 3,000 pairs were drawn via stratified random sampling from the pipeline output. We will add a distributional comparison (by agreement type, clause length, and jurisdiction pair) between the labeled and unlabeled sets in the dataset description. We will also add a limitations paragraph noting that lexically divergent but semantically equivalent clauses may be under-represented due to the retrieval approach. revision: yes
- Inter-annotator agreement for the 3,000 expert labels
Circularity Check
No circularity: dataset construction and empirical evaluation are self-contained.
full rationale
The paper introduces a new dataset via multi-stage retrieval plus expert annotation and reports baseline model performance (macro-F1 65.11%). No equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the described chain. The divergence claim is an empirical observation on the collected pairs rather than a reduction to the construction pipeline by definition. The contribution is data release and external benchmarking, which does not trigger any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Legal experts can consistently determine boolean equivalence of clauses across jurisdictions
Reference graph
Works this paper leans on
-
[1]
Mousumi Akter, Erion Çano, Erik Weber, Dennis Dobler, and Ivan Habernal
-
[2]
Surveys58, 7 (2025), 1–32
A comprehensive survey on legal summarization: Challenges and future directions.Comput. Surveys58, 7 (2025), 1–32
2025
-
[3]
Farid Ariai, Joel Mackenzie, and Gianluca Demartini. 2025. Natural language pro- cessing for the legal domain: A survey of tasks, datasets, models, and challenges. Comput. Surveys58, 6 (2025), 1–37. LAUKIN: A Multi-jurisdictional Common Law Contract Dataset
2025
-
[4]
Katy Barnett. 2024. Reflections on the principles of remoteness in contract in com- parative law.International Journal for the Semiotics of Law-Revue internationale de Sémiotique juridique37, 5 (2024), 1587–1616
2024
-
[5]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners.Advances in neural information processing systems33 (2020), 1877–1901
2020
-
[6]
Gordon V Cormack, Charles LA Clarke, and Stefan Buettcher. 2009. Reciprocal rank fusion outperforms condorcet and individual rank learning methods. In Proceedings of the 32nd international ACM SIGIR conference on Research and development in information retrieval. 758–759
2009
-
[7]
Yi Feng, Chuanyi Li, and Vincent Ng. 2024. Legal case retrieval: A survey of the state of the art. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 6472–6485
2024
-
[8]
Jia-Hong Huang, Chao-Chun Yang, Yixian Shen, Alessio M Pacces, and Evangelos Kanoulas. 2024. Optimizing numerical estimation and operational efficiency in the legal domain through large language models. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management. 4554–4562
2024
-
[9]
Daniel N Kluttz and Deirdre K Mulligan. 2019. Automated decision support technologies and the legal profession.Berkeley Technology Law Journal34, 3 (2019), 853–890
2019
-
[10]
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. Large Language Models are Zero-Shot Reasoners. InAdvances in Neural Information Processing Systems
2022
-
[11]
Manasi Kumar and Maren Heidemann. 2022. Contract law in common law countries: A study in divergence.Liverpool Law Review43, 2 (2022), 133–147
2022
-
[12]
J Richard Landis and Gary G Koch. 1977. The measurement of observer agreement for categorical data.biometrics(1977), 159–174
1977
-
[13]
OpenRouter. 2023. OpenRouter: The Unified Interface For LLMs. https: //openrouter.ai. Accessed: 2026-05-26
2023
-
[14]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback.Advances in neural information processing systems35 (2022), 27730–27744
2022
-
[15]
Madhav Saxena. 2023. Comparative Study between Contract of Indemnity and Guarantee vis-a-vis Provisions of UK and India.Issue 3 Int’l JL Mgmt. & Human. 6 (2023), 1366
2023
-
[16]
Amrita Singh, Aditya Joshi, Jiaojiao Jiang, and Hye-young Paik. 2025. A survey of classification tasks and approaches for legal contracts.Artificial Intelligence Review58, 12 (2025), 380
2025
-
[17]
Amrita Singh, H Suhan Karaca, Aditya Joshi, Hye-young Paik, and Jiaojiao Jiang
-
[18]
Generalist Transformer-based Models for Legal Contract Classification
Evaluating Customized vs. Generalist Transformer-based Models for Legal Contract Classification. InProceedings of the 2nd Workshop on Customizable NLP: Progress and Challenges in Customizing NLP for a Domain, Application, Group, or Individual (CustomNLP4U)
-
[19]
Onyinye Ucheagwu-Okoye and Chidimma Stella Nwakoby. 2025. LEGAL PRAC- TICE AND LEGAL EDUCATION IN THE 21ST CENTURY: HARNESSING AI FOR EFFICIENCY, SPEED AND ACCURACY.Chukwuemeka Odumegwu Ojukwu University Law Journal9, 1 (2025)
2025
-
[20]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems35 (2022), 24824–24837
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.