Disentangled Latent Dynamics Manifold Fusion for Solving Parameterized PDEs
Pith reviewed 2026-05-21 11:33 UTC · model grok-4.3
The pith
Modeling PDE prediction as latent dynamic evolution separates parameter changes from time progression.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
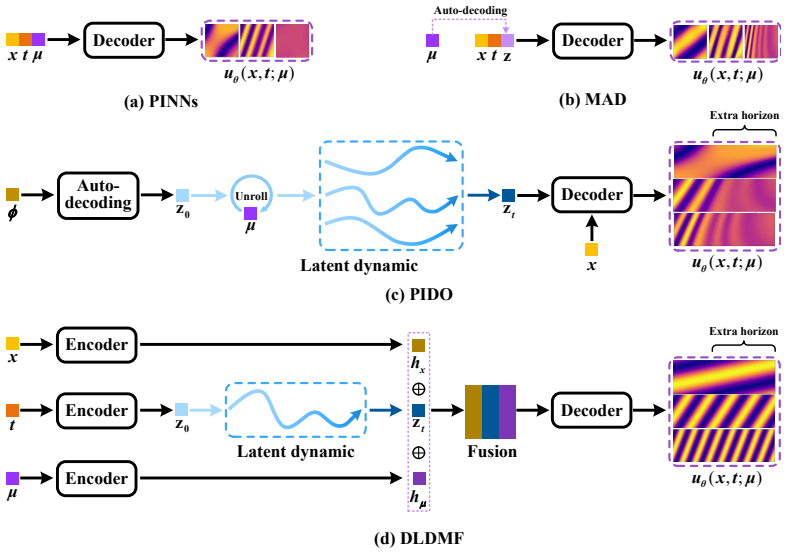
DLDMF explicitly separates space, time, and parameters by mapping PDE parameters directly to a continuous latent embedding through a feed-forward network. This embedding initializes and conditions a parameter-conditioned Neural ODE. A dynamic manifold fusion mechanism uses a shared decoder to combine spatial coordinates, parameter embeddings, and time-evolving latent states to reconstruct the spatiotemporal solution. By modeling prediction as latent dynamic evolution rather than static coordinate fitting, the approach reduces interference between parameter variation and temporal evolution while preserving a smooth and coherent solution manifold.
What carries the argument
The parameter-conditioned Neural ODE initialized by a feed-forward mapped latent embedding, combined with dynamic manifold fusion via a shared decoder.
If this is right
- Performs well on unseen parameter settings without retraining.
- Achieves long-term temporal extrapolation beyond the training time range.
- Outperforms state-of-the-art baselines in accuracy on benchmark problems.
- Maintains a smooth and coherent solution manifold across parameter variations.
- Reduces interference between parameter changes and time evolution in the model.
Where Pith is reading between the lines
- This separation might allow the same latent dynamics to apply to a wider range of physical systems by adjusting only the initial embedding.
- Future work could test if this approach scales to higher-dimensional or nonlinear PDEs with many parameters.
- It suggests that enforcing disentanglement in latent space could improve generalization in other time-dependent modeling tasks like fluid dynamics or climate simulation.
Load-bearing premise
A feed-forward network can map any PDE parameters to a latent embedding that allows a Neural ODE to evolve the solution stably without needing to decode the parameters again during testing or causing jumps in the solution space.
What would settle it
Running the model on a parameter value outside the training range and checking if the predicted solution matches the true PDE solution over an extended time period beyond training data; failure would show the mapping or evolution does not generalize.
Figures



read the original abstract
Generalizing neural surrogate models across different PDE parameters remains difficult because changes in PDE coefficients often make learning harder and optimization less stable. The problem becomes even more severe when the model must also predict beyond the training time range. Existing methods usually cannot handle parameter generalization and temporal extrapolation at the same time. Standard parameterized models treat time as just another input and therefore fail to capture intrinsic dynamics, while recent continuous-time latent methods often rely on expensive test-time auto-decoding for each instance, which is inefficient and can disrupt continuity across the parameterized solution space. To address this, we propose Disentangled Latent Dynamics Manifold Fusion (DLDMF), a physics-informed framework that explicitly separates space, time, and parameters. Instead of unstable auto-decoding, DLDMF maps PDE parameters directly to a continuous latent embedding through a feed-forward network. This embedding initializes and conditions a latent state whose evolution is governed by a parameter-conditioned Neural ODE. We further introduce a dynamic manifold fusion mechanism that uses a shared decoder to combine spatial coordinates, parameter embeddings, and time-evolving latent states to reconstruct the corresponding spatiotemporal solution. By modeling prediction as latent dynamic evolution rather than static coordinate fitting, DLDMF reduces interference between parameter variation and temporal evolution while preserving a smooth and coherent solution manifold. As a result, it performs well on unseen parameter settings and in long-term temporal extrapolation. Experiments on several benchmark problems show that DLDMF consistently outperforms state-of-the-art baselines in accuracy, parameter generalization, and extrapolation robustness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Disentangled Latent Dynamics Manifold Fusion (DLDMF), a physics-informed neural framework for solving parameterized PDEs. It explicitly disentangles space, time, and parameters by using a feed-forward network to map PDE parameters directly to a continuous latent embedding; this embedding initializes and conditions a parameter-conditioned Neural ODE whose evolution is decoded via a dynamic manifold fusion mechanism with a shared decoder that combines spatial coordinates, parameter embeddings, and time-evolving latent states. The central claim is that modeling prediction as latent dynamic evolution (rather than static fitting) reduces interference between parameter variation and temporal dynamics, preserves a smooth solution manifold, and yields improved accuracy, generalization to unseen parameters, and long-term temporal extrapolation on benchmark problems relative to state-of-the-art baselines.
Significance. If the empirical results and stability assumptions hold, the work could advance neural surrogates for parameterized PDEs by eliminating test-time auto-decoding while jointly addressing parameter generalization and temporal extrapolation. The explicit disentanglement via Neural ODEs and manifold fusion provides a concrete architectural template that may transfer to other scientific machine-learning tasks involving multi-scale physical systems.
major comments (2)
- [Method (parameter-to-latent mapping and Neural ODE conditioning)] The central architectural claim—that a feed-forward network produces a latent embedding that both initializes and stably conditions a parameter-conditioned Neural ODE across the solution manifold—lacks any explicit continuity enforcement (e.g., Lipschitz regularization, manifold penalties, or Jacobian constraints). This assumption is load-bearing for the generalization and long-term extrapolation results; without it, small parameter perturbations can induce divergent latent dynamics under integration.
- [Abstract and Experiments] The abstract asserts that 'experiments on several benchmark problems show that DLDMF consistently outperforms state-of-the-art baselines,' yet the provided text contains no quantitative error metrics, error bars, dataset specifications (number of parameter settings, time horizons, grid resolutions), or ablation studies isolating the dynamic manifold fusion component. These details are required to substantiate the central performance claims.
minor comments (1)
- [Method] The notation for the latent state z(t), parameter embedding e_p, and the fusion decoder could be formalized with explicit equations and a schematic diagram to clarify the information flow between the feed-forward mapper, Neural ODE, and shared decoder.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below, indicating where revisions will be made to strengthen the presentation and claims.
read point-by-point responses
-
Referee: [Method (parameter-to-latent mapping and Neural ODE conditioning)] The central architectural claim—that a feed-forward network produces a latent embedding that both initializes and stably conditions a parameter-conditioned Neural ODE across the solution manifold—lacks any explicit continuity enforcement (e.g., Lipschitz regularization, manifold penalties, or Jacobian constraints). This assumption is load-bearing for the generalization and long-term extrapolation results; without it, small parameter perturbations can induce divergent latent dynamics under integration.
Authors: We appreciate this observation regarding the need for explicit continuity enforcement. The feed-forward network with standard smooth activations (such as tanh) is continuous by construction, and the Neural ODE integration inherently produces continuous trajectories in latent space. However, we acknowledge that the original submission did not include explicit regularization such as Lipschitz constraints or manifold penalties on the parameter-to-latent mapping. To directly address the concern about stability under small parameter perturbations, we will incorporate a Lipschitz regularization term on the parameter embedding network in the revised manuscript. This term will be added to the overall loss function, with corresponding discussion in the method section and updated experimental protocols to verify its effect on generalization and extrapolation. revision: yes
-
Referee: [Abstract and Experiments] The abstract asserts that 'experiments on several benchmark problems show that DLDMF consistently outperforms state-of-the-art baselines,' yet the provided text contains no quantitative error metrics, error bars, dataset specifications (number of parameter settings, time horizons, grid resolutions), or ablation studies isolating the dynamic manifold fusion component. These details are required to substantiate the central performance claims.
Authors: We agree that the abstract would be strengthened by including concise quantitative support for the performance claims. While the full manuscript's Experiments section already reports relative L2 errors with standard deviations across multiple runs, specific dataset details (including the number of parameter settings, time horizons, and grid resolutions), and ablation studies on the dynamic manifold fusion component, these were not summarized in the abstract. We will revise the abstract to incorporate key quantitative metrics, error bar information, and brief references to the dataset specifications and ablations, ensuring the central claims are substantiated at the summary level without exceeding length constraints. revision: yes
Circularity Check
No circularity: DLDMF is an independent architectural proposal with no self-referential reductions
full rationale
The paper introduces DLDMF as a new framework that uses a feed-forward network to map PDE parameters to a latent embedding which initializes a parameter-conditioned Neural ODE, combined with a dynamic manifold fusion decoder. No equations, predictions, or core claims reduce by construction to fitted inputs, self-citations, or renamed known results. The derivation relies on the proposed separation of space/time/parameters and experimental validation on benchmarks rather than tautological definitions or load-bearing self-references. This is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- latent embedding dimension
- Neural ODE integration tolerances and step size
axioms (1)
- domain assumption PDE solutions lie on a smooth manifold that can be factored into independent spatial, temporal, and parametric components in latent space.
invented entities (1)
-
dynamic manifold fusion mechanism
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DLDMF maps PDE parameters directly to a continuous latent embedding through a feed-forward network. This embedding initializes and conditions a latent state whose evolution is governed by a parameter-conditioned Neural ODE.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
dynamic manifold fusion mechanism that uses a shared decoder to combine spatial coordinates, parameter embeddings, and time-evolving latent states
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Martín Abadi, Paul Barham, Jianmin Chen, Zhifeng Chen, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Geoffrey Irving, Michael Isard, et al.{TensorFlow}: A system for{Large-Scale}machine learning. In12th USENIX symposium on operating systems design and implementation (OSDI 16), pages 265–283, 2016
work page 2016
-
[2]
Learning Dynamical Systems from Partial Observations
IbrahimAyed, EmmanueldeBézenac, ArthurPajot, JulienBrajard, and PatrickGallinari. Learningdynamicalsystemsfrompartialobservations. arXiv preprint arXiv:1902.11136, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[3]
Nathan Baker, Frank Alexander, Timo Bremer, Aric Hagberg, Yannis Kevrekidis, HabibNajm, ManishParashar, AbaniPatra, JamesSethian, Stefan Wild, et al. Workshop report on basic research needs for scientific machine learning: Core technologies for artificial intelligence. Technical report, USDOE Office of Science (SC), Washington, DC (United States), 2019
work page 2019
-
[4]
Relational inductive biases, deep learning, and graph networks
Peter W Battaglia, Jessica B Hamrick, Victor Bapst, Alvaro Sanchez- Gonzalez, Vinicius Zambaldi, Mateusz Malinowski, Andrea Tacchetti, David Raposo, Adam Santoro, Ryan Faulkner, et al. Relational in- ductive biases, deep learning, and graph networks.arXiv preprint arXiv:1806.01261, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[5]
Atilim Gunes Baydin, Barak A Pearlmutter, Alexey Andreyevich Radul, andJeffreyMarkSiskind. Automaticdifferentiationinmachinelearning: a survey.Journal of Marchine Learning Research, 18:1–43, 2018
work page 2018
-
[6]
Message passing neural pde solvers
Johannes Brandstetter, Daniel E Worrall, and Max Welling. Message passing neural pde solvers. InInternational Conference on Learning Representations, 2021
work page 2021
-
[7]
NeRV: Neural representations for videos
Hao Chen, Bo He, Hanyu Wang, Yixuan Ren, Ser Nam Lim, and Abhinav Shrivastava. NeRV: Neural representations for videos. In Marc’Aurelio Ranzato, Alina Beygelzimer, Yann Dauphin, Percy Liang, and Jenn Wortman Vaughan, editors,Advances in Neural Information Processing Systems, volume 34, pages 21557–21568. Curran Associates, Inc., 2021. 31
work page 2021
-
[8]
Chiaramonte, Kevin Thomas Carlberg, and Eitan Grinspun
Peter Yichen Chen, Jinxu Xiang, Dong Heon Cho, Yue Chang, G A Per- shing, Henrique Teles Maia, Maurizio M. Chiaramonte, Kevin Thomas Carlberg, and Eitan Grinspun. CROM: Continuous reduced-order mod- eling of PDEs using implicit neural representations. InInternational Conference on Learning Representations, 2023
work page 2023
-
[9]
Neural ordinary differential equations.Advances in Neural Information Processing Systems, 31, 2018
Ricky TQ Chen, Yulia Rubanova, Jesse Bettencourt, and David K Du- venaud. Neural ordinary differential equations.Advances in Neural Information Processing Systems, 31, 2018
work page 2018
-
[10]
Woojin Cho, Minju Jo, Haksoo Lim, Kookjin Lee, Dongeun Lee, Sanghyun Hong, and Noseong Park. Parameterized physics- informed neural networks for parameterized pdes.arXiv preprint arXiv:2408.09446, 2024
-
[11]
Miles Cranmer, Sam Greydanus, Stephan Hoyer, Peter Battaglia, David Spergel, and Shirley Ho. Lagrangian neural networks. InICLR 2020 Workshop, 2020
work page 2020
-
[12]
Lagrangian neural networks, 2020
Miles Cranmer, Sam Greydanus, Stephan Hoyer, Peter Battaglia, David Spergel, and Shirley Ho. Lagrangian neural networks, 2020
work page 2020
-
[13]
Emilien Dupont, Hyunjik Kim, S. M. Ali Eslami, Danilo Jimenez Rezende, and Dan Rosenbaum. From data to functa: Your data point is a function and you can treat it like one. In39th International Conference on Machine Learning (ICML), 2022
work page 2022
-
[14]
Multiplicative filter networks
Rizal Fathony, Anit Kumar Sahu, Devin Willmott, and J Zico Kolter. Multiplicative filter networks. InInternational Conference on Learning Representations, 2020
work page 2020
-
[15]
Deep learning-based reduced order models in cardiac electrophysiology
Stefania Fresca, Andrea Manzoni, Luca Dedè, and Alfio Quarteroni. Deep learning-based reduced order models in cardiac electrophysiology. PLoS ONE, 15(10), October 2020
work page 2020
-
[16]
Deep learning-based reduced order models in cardiac electrophysiology
Stefania Fresca, Andrea Manzoni, Luca Dedè, and Alfio Quarteroni. Deep learning-based reduced order models in cardiac electrophysiology. PLoS ONE, 15(10), October 2020. 32
work page 2020
-
[17]
Yihang Gao, Ka Chun Cheung, and Michael K. Ng. Svd-pinns: Transfer learning of physics-informed neural networks via singular value decom- position. In2022 IEEE Symposium Series on Computational Intelligence (SSCI). IEEE, December 2022
work page 2022
-
[18]
E(n) equivariant graph neural networks
Víctor Garcia Satorras, Emiel Hoogeboom, and Max Welling. E(n) equivariant graph neural networks. InProceedings of the 38th Interna- tional Conference on Machine Learning, volume 139 ofProceedings of Machine Learning Research, pages 9323–9332. PMLR, 2021
work page 2021
-
[19]
Learning to optimize multigrid pde solvers
Daniel Greenfeld, Meirav Galun, Ronen Basri, Irad Yavneh, and Ron Kimmel. Learning to optimize multigrid pde solvers. InInternational Conference on Machine Learning, pages 2415–2423. PMLR, 2019
work page 2019
-
[20]
Hamiltonian neural networks.Advances in Neural Information Processing Systems, 32:15379–15389, 2019
Samuel Greydanus, Misko Dzamba, and Jason Yosinski. Hamiltonian neural networks.Advances in Neural Information Processing Systems, 32:15379–15389, 2019
work page 2019
-
[21]
Xiang Huang, Zhanhong Ye, Hongsheng Liu, Shi Ji, Zidong Wang, Kang Yang, Yang Li, Min Wang, Haotian Chu, Fan Yu, et al. Meta-auto- decoder for solving parametric partial differential equations.Advances in Neural Information Processing Systems, 35:23426–23438, 2022
work page 2022
-
[22]
Ameya D Jagtap and George Em Karniadakis. Extended physics- informed neural networks (xpinns): A generalized space-time domain decomposition based deep learning framework for nonlinear partial differential equations.Communications in Computational Physics, 28(5):2002–2041, 2020
work page 2002
-
[23]
Ameya D Jagtap, Ehsan Kharazmi, and George Em Karniadakis. Con- servative physics-informed neural networks on discrete domains for con- servation laws: Applications to forward and inverse problems.Computer Methods in Applied Mechanics and Engineering, 365:113028, 2020
work page 2020
-
[24]
Physics-informed machine learning.Nature Reviews Physics, 3(6):422–440, 2021
George Em Karniadakis, Ioannis G Kevrekidis, Lu Lu, Paris Perdikaris, Sifan Wang, and Liu Yang. Physics-informed machine learning.Nature Reviews Physics, 3(6):422–440, 2021
work page 2021
-
[25]
Multi-task learning using uncertaintytoweighlossesforscenegeometryandsemantics
Alex Kendall, Yarin Gal, and Roberto Cipolla. Multi-task learning using uncertaintytoweighlossesforscenegeometryandsemantics. InProceed- 33 ings of the IEEE conference on computer vision and pattern recognition, pages 7482–7491, 2018
work page 2018
-
[26]
Aditi Krishnapriyan, Amir Gholami, Shandian Zhe, Robert Kirby, and Michael W Mahoney. Characterizing possible failure modes in physics- informed neural networks.Advances in Neural Information Processing Systems, 34, 2021
work page 2021
-
[27]
Nonlinear reconstruction for operator learning of pdes with discontinuities
Samuel Lanthaler, Roberto Molinaro, Patrik Hadorn, and Siddhartha Mishra. Nonlinear reconstruction for operator learning of pdes with discontinuities. InThe Eleventh International Conference on Learning Representations, 2022
work page 2022
-
[28]
Deep conservation: A latent- dynamics model for exact satisfaction of physical conservation laws
Kookjin Lee and Kevin T Carlberg. Deep conservation: A latent- dynamics model for exact satisfaction of physical conservation laws. InProceedings of the AAAI Conference on Artificial Intelligence, vol- ume 35, pages 277–285, 2021
work page 2021
-
[29]
Kookjin Lee, Nathaniel Trask, and Panos Stinis. Machine learning struc- ture preserving brackets for forecasting irreversible processes.Advances in Neural Information Processing Systems, 34, 2021
work page 2021
-
[30]
Adaptive finite element methods: A review.Applied Mechanics Reviews, 50(10):581–591, 1997
Long Yuan Li and Peter Bettess. Adaptive finite element methods: A review.Applied Mechanics Reviews, 50(10):581–591, 1997
work page 1997
-
[31]
Fourier neural operator for parametric partial differential equations
Zongyi Li, Nikola Borislavov Kovachki, Kamyar Azizzadenesheli, Kaushik Bhattacharya, Andrew Stuart, Anima Anandkumar, et al. Fourier neural operator for parametric partial differential equations. In International Conference on Learning Representations, 2020
work page 2020
-
[32]
Xu Liu, Xiaoya Zhang, Wei Peng, Weien Zhou, and Wen Yao. A novel meta-learning initialization method for physics-informed neural networks.Neural Computing and Applications, pages 1–24, 2022
work page 2022
-
[33]
Lu Lu, Pengzhan Jin, Guofei Pang, Zhongqiang Zhang, and George Em Karniadakis. Learning nonlinear operators via deeponet based on the universal approximation theorem of operators.Nature machine intelli- gence, 3(3):218–229, 2021. 34
work page 2021
-
[34]
Deep lagrangian net- works: Using physics as model prior for deep learning
Michael Lutter, Christian Ritter, and Jan Peters. Deep lagrangian net- works: Using physics as model prior for deep learning. InInternational Conference on Learning Representations, 2018
work page 2018
-
[35]
Olver.Introduction to partial differential equations
Peter J. Olver.Introduction to partial differential equations. Undergrad- uate Texts in Mathematics. Springer Cham, 2014
work page 2014
-
[36]
Deepsdf: Learning continuous signed distance functions for shape representation
Jeong Joon Park, Peter Florence, Julian Straub, Richard Newcombe, and Steven Lovegrove. Deepsdf: Learning continuous signed distance functions for shape representation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 165–174, 2019
work page 2019
-
[37]
DeepSDF: Learning continuous signed distance functions for shape representation
Jeong Joon Park, Peter Florence, Julian Straub, Richard Newcombe, and Steven Lovegrove. DeepSDF: Learning continuous signed distance functions for shape representation. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 165–174, June 2019
work page 2019
-
[38]
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Brad- bury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. PyTorch: An imperative style, high-performance deep learning library.Advances in neural information processing sys- tems, 32, 2019
work page 2019
-
[39]
Kailash C Patidar. Nonstandard finite difference methods: recent trends and further developments.Journal of Difference Equations and Appli- cations, 22(6):817–849, 2016
work page 2016
-
[40]
Snode: Spectral discretization of neural odes for system identification
Alessio Quaglino, Marco Gallieri, Jonathan Masci, and Jan Koutník. Snode: Spectral discretization of neural odes for system identification. InInternational Conference on Learning Representations, 2019
work page 2019
-
[41]
On thespec- tral bias of neural networks
Nasim Rahaman, Aristide Baratin, Devansh Arpit, Felix Draxler, Min Lin, FredHamprecht, Yoshua Bengio, and AaronCourville. On thespec- tral bias of neural networks. InInternational Conference on Machine Learning, pages 5301–5310. PMLR, 2019
work page 2019
-
[42]
Maziar Raissi, Paris Perdikaris, and George E Karniadakis. Physics- informed neural networks: A deep learning framework for solving for- ward and inverse problems involving nonlinear partial differential equa- tions.Journal of Computational Physics, 378:686–707, 2019. 35
work page 2019
-
[43]
KeithRuddandSilviaFerrari. Aconstrainedintegration(cint)approach to solving partial differential equations using artificial neural networks. Neurocomputing, 155:277–285, 2015
work page 2015
-
[44]
An Overview of Multi-Task Learning in Deep Neural Networks
Sebastian Ruder. An overview of multi-task learning in deep neural networks.arXiv preprint arXiv:1706.05098, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[45]
Aleksei Sholokhov, Yuying Liu, Hassan Mansour, and Saleh Nabi. Physics-informed neural ode (pinode): embedding physics into models using collocation points.Scientific Reports, 13(1):10166, 2023
work page 2023
-
[46]
Khemraj Shukla, Ameya D Jagtap, and George Em Karniadakis. Paral- lel physics-informed neural networks via domain decomposition.Journal of Computational Physics, 447:110683, 2021
work page 2021
-
[47]
Vincent Sitzmann, Julien Martel, Alexander Bergman, David Lindell, and Gordon Wetzstein. Implicit neural representations with periodic activation functions.Advances in Neural Information Processing Sys- tems, 33:7462–7473, 2020
work page 2020
-
[48]
StyleGAN-V: A continuous video generator with the price, image qual- ity and perks of StyleGAN2
Ivan Skorokhodov, Sergey Tulyakov, and Mohamed Elhoseiny. StyleGAN-V: A continuous video generator with the price, image qual- ity and perks of StyleGAN2. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3626–3636, June 2022
work page 2022
-
[49]
A Srirekha, Kusum Bashetty, et al. Infinite to finite: an overview of finite element analysis.Indian Journal of Dental Research, 21(3):425, 2010
work page 2010
-
[50]
Gilbert Strang. On the construction and comparison of difference schemes.SIAM journal on numerical analysis, 5(3):506–517, 1968
work page 1968
-
[51]
Hamiltonian generative networks
Peter Toth, Danilo J Rezende, Andrew Jaegle, Sébastien Racanière, Aleksandar Botev, and Irina Higgins. Hamiltonian generative networks. InInternational Conference on Learning Representations, 2019
work page 2019
-
[52]
Honghui Wang, Yifan Pu, Shiji Song, and Gao Huang. Advancing gen- eralization in pinns through latent-space representations.IEEE Trans- actions on Neural Networks and Learning Systems, 2025. 36
work page 2025
-
[53]
Sifan Wang and Paris Perdikaris. Long-time integration of parametric evolution equations with physics-informed deeponets.Journal of Com- putational Physics, 475:111855, 2023
work page 2023
-
[54]
SifanWang, ShyamSankaran, andParisPerdikaris. Respectingcausality is all you need for training physics-informed neural networks.arXiv preprint arXiv:2203.07404, 2022
-
[55]
Understanding and mit- igating gradient flow pathologies in physics-informed neural networks
Sifan Wang, Yujun Teng, and Paris Perdikaris. Understanding and mit- igating gradient flow pathologies in physics-informed neural networks. SIAM Journal on Scientific Computing, 43(5):A3055–A3081, 2021
work page 2021
-
[56]
Sifan Wang, Hanwen Wang, and Paris Perdikaris. Learning the solu- tion operator of parametric partial differential equations with physics- informed deeponets.Science advances, 7(40):eabi8605, 2021
work page 2021
-
[57]
Sifan Wang, Xinling Yu, and Paris Perdikaris. When and why pinns fail to train: A neural tangent kernel perspective.Journal of Computational Physics, 449:110768, 2022
work page 2022
-
[58]
Tianshu Wen, Kookjin Lee, and Youngsoo Choi. Reduced-order mod- eling for parameterized pdes via implicit neural representations.arXiv preprint arXiv:2311.16410, 2023
-
[59]
Jiachen Yao, Chang Su, Zhongkai Hao, Songming Liu, Hang Su, and Jun Zhu. Multiadam: Parameter-wise scale-invariant optimizer for mul- tiscale training of physics-informed neural networks. InProceedings of the 40th International Conference on Machine Learning, ICML’23. JMLR.org, 2023
work page 2023
-
[60]
Yuan Yin, Matthieu Kirchmeyer, Jean-Yves Franceschi, Alain Rako- tomamonjy, and Patrick Gallinari. Continuous pde dynamics forecasting with implicit neural representations.arXiv preprint arXiv:2209.14855, 2022
-
[61]
Bing Yu et al. The deep ritz method: a deep learning-based numerical algorithm for solving variational problems.Communications in Mathe- matics and Statistics, 6(1):1–12, 2018
work page 2018
-
[62]
Generating videos with dynamics-aware 37 implicit generative adversarial networks
Sihyun Yu, Jihoon Tack, Sangwoo Mo, Hyunsu Kim, Junho Kim, Jung- Woo Ha, and Jinwoo Shin. Generating videos with dynamics-aware 37 implicit generative adversarial networks. InInternational Conference on Learning Representations, 2022. 38 Appendix A. Additional Statistical Analysis on CDR Equations In this section, we provide additional statistical analysi...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.