Trust-Aware Predictive Emissions Monitoring for Gas Turbine Fleets with Limited Labelled Data
Pith reviewed 2026-06-28 02:01 UTC · model grok-4.3
The pith
Trust scores calibrated on few labelled turbines can flag which NOx predictions to trust across an entire unlabelled fleet.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
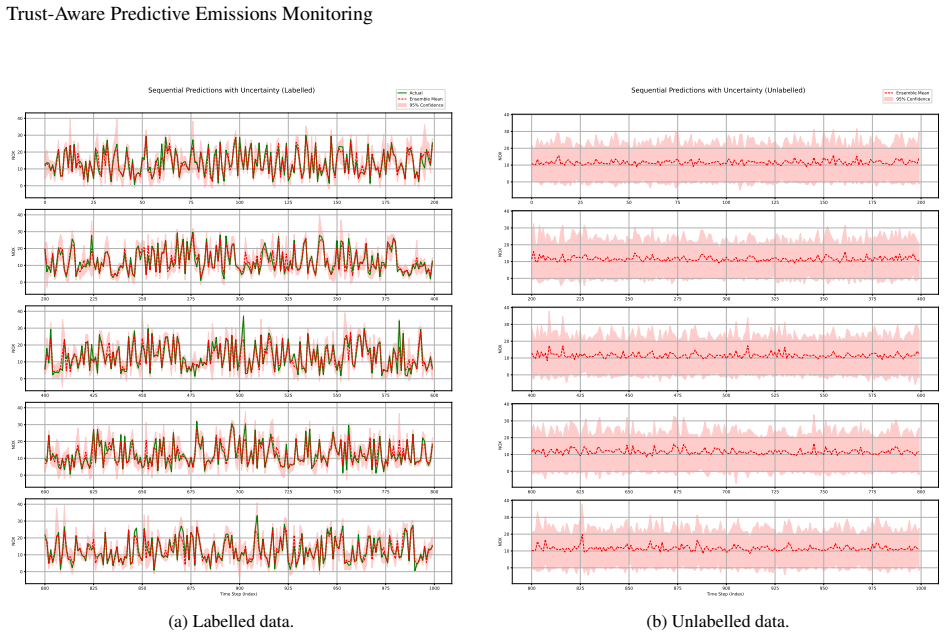
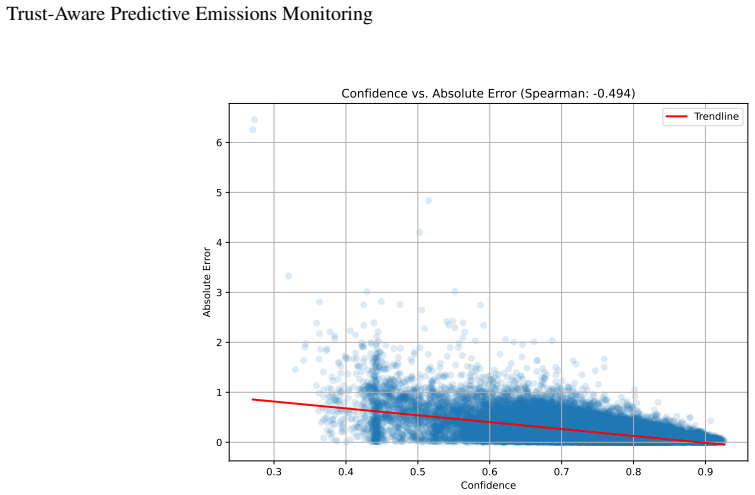
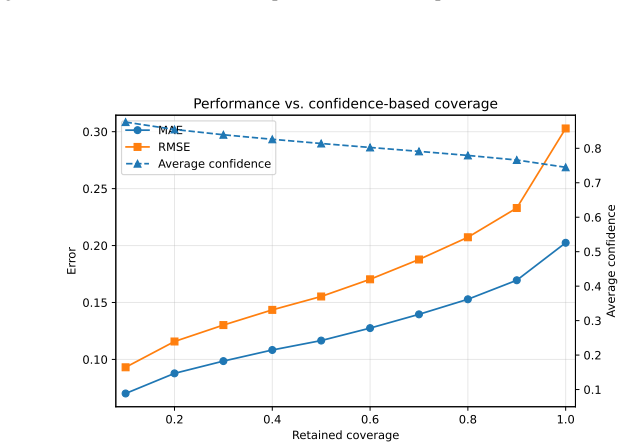
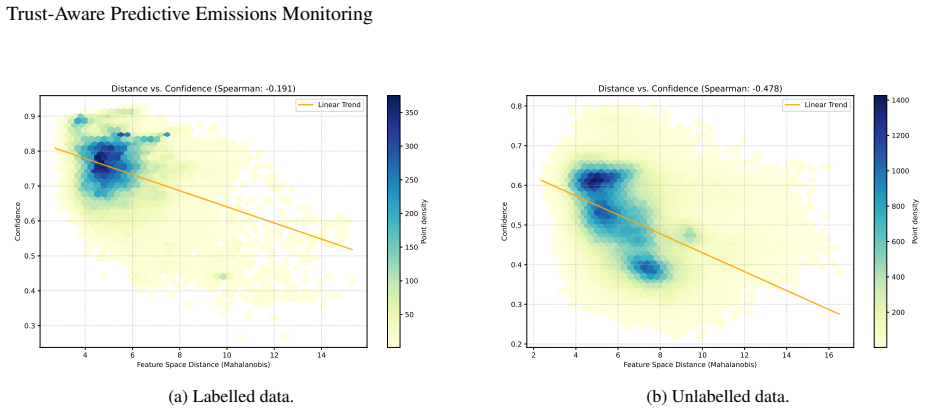
A trust-aware probabilistic framework that fuses multi-head recurrent prediction with learned confidence estimation, ensemble uncertainty quantification, auxiliary feature prediction, feature-space distance analysis, and operating-range diagnostics produces interpretable per-sample trust scores; these scores are meaningfully related to prediction error on unlabelled turbines, support confidence-based filtering that reduces MAE from 0.202 to 0.070 on the highest-confidence decile, and respond appropriately to distributional shift by assigning higher uncertainty and lower confidence to unlabelled and out-of-distribution samples.
What carries the argument
The trust-aware probabilistic framework that integrates a multi-head recurrent prediction model with multiple calibrated uncertainty and confidence signals to output per-sample trust scores.
If this is right
- Filtering predictions by trust score reduces mean absolute error from 0.202 on the full set to 0.070 on the top 10 percent.
- Unlabelled and out-of-distribution samples receive measurably higher uncertainty and lower trust scores.
- The framework supplies per-sample reliability indicators that can guide cautious use during fleet-wide deployment of predictive emissions monitoring.
- Trust scores remain interpretable after calibration on the limited labelled data alone.
Where Pith is reading between the lines
- The same multi-signal trust construction could be applied to other fleet monitoring tasks where labels are expensive but sensor data are abundant.
- Running the calibrated trust scores on turbines from a different manufacturer or geographic region would test whether the distributional-shift response generalizes.
- Embedding the trust scores into an automated alerting system could reduce false regulatory triggers by de-emphasizing low-trust forecasts.
Load-bearing premise
Trust scores calibrated exclusively on the labelled subset will correctly indicate prediction reliability for unlabelled turbines whose operating data may follow different distributions.
What would settle it
Collect actual emissions measurements on a held-out set of unlabelled turbines and test whether predictions with low trust scores show systematically higher error than those with high trust scores.
Figures
read the original abstract
Machine learning-based predictive emissions monitoring systems offer a practical alternative to direct emissions measurement, but their deployment across gas turbine fleets is challenging when emissions labels are available for only a small subset of assets. In this work, a trust-aware probabilistic framework is proposed for fleet-level gas turbine NOx prediction under limited labelled supervision. The framework combines a multi-head recurrent prediction model with learned confidence estimation, ensemble-based uncertainty quantification, auxiliary feature prediction, feature-space distance analysis, and operating-range diagnostics. These signals are calibrated on labelled data to produce interpretable per-sample trust scores, providing indicators of prediction reliability on unlabelled turbines, supporting the identification of predictions that should be treated with greater caution during fleet-level deployment. Confidence-based filtering reduces MAE from 0.202 at full coverage to 0.070 for the highest-confidence 10\% of predictions, demonstrating that confidence estimates are meaningfully related to prediction error. Unlabelled and out-of-distribution samples exhibit increased uncertainty and reduced confidence, indicating that the framework responds appropriately to distributional shift. The results show that the proposed trust framework provides actionable reliability information for emissions prediction on unlabelled turbines, supporting more transparent and trustworthy deployment of PEMS across industrial fleets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a trust-aware probabilistic framework for NOx emissions prediction in gas turbine fleets under limited labelled supervision. It integrates a multi-head recurrent model with learned confidence estimation, ensemble uncertainty, auxiliary feature prediction, feature-space distance, and operating-range diagnostics. These signals are calibrated on the labelled subset to yield per-sample trust scores intended to indicate reliability for unlabelled turbines. The abstract reports that confidence filtering reduces MAE from 0.202 (full coverage) to 0.070 (top 10% confidence) and that unlabelled/OOD samples receive lower confidence.
Significance. If the trust scores were shown to correlate with actual prediction error on unlabelled turbines under distributional shift, the work would offer a practical mechanism for selective, risk-aware deployment of PEMS models across industrial fleets. The current evidence, however, leaves the generalization of the calibration untested.
major comments (2)
- [Abstract] Abstract: the central claim that trust scores supply actionable reliability indicators for unlabelled turbines rests on calibration performed exclusively against the labelled subset; the reported MAE reduction is measured on labelled data, and no ground-truth emissions exist for the unlabelled fleet, so the mapping from trust score to actual error under shift remains unverified.
- [Abstract] Abstract: the observation that unlabelled/OOD samples exhibit increased uncertainty and reduced confidence is consistent with evaluation on labelled data only and does not constitute a direct test of whether high-trust predictions on shifted data have low error.
minor comments (1)
- The manuscript provides no details on model architecture, training procedure, calibration method, or statistical significance testing, which limits assessment of reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which correctly identify that our evidence for trust-score reliability is derived from labelled-data calibration. We agree that the abstract claims require clarification to avoid overstating what has been directly verified. We will revise the abstract and add discussion of this limitation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that trust scores supply actionable reliability indicators for unlabelled turbines rests on calibration performed exclusively against the labelled subset; the reported MAE reduction is measured on labelled data, and no ground-truth emissions exist for the unlabelled fleet, so the mapping from trust score to actual error under shift remains unverified.
Authors: We agree. The MAE reduction (0.202 to 0.070) and trust-score calibration are demonstrated exclusively on the labelled subset. No ground truth exists for the unlabelled fleet, so direct verification of the trust-to-error mapping under shift is not possible. We will revise the abstract to state that trust scores are calibrated on labelled data to produce reliability indicators intended for unlabelled turbines, and that lower confidence on unlabelled/OOD samples indicates the framework responds to shift, without claiming verified error reduction on unlabelled data. We will also add a limitations paragraph discussing this point. revision: yes
-
Referee: [Abstract] Abstract: the observation that unlabelled/OOD samples exhibit increased uncertainty and reduced confidence is consistent with evaluation on labelled data only and does not constitute a direct test of whether high-trust predictions on shifted data have low error.
Authors: This observation is accurate. The increased uncertainty and reduced confidence on unlabelled/OOD samples are measured via the model's internal signals after calibration on labelled data; they do not constitute a direct test of prediction error on shifted data. We will revise the abstract wording to describe this as evidence that the framework appropriately down-weights predictions under shift, rather than as a direct test of error on unlabelled turbines. revision: yes
Circularity Check
Trust calibration fitted on labelled data; MAE reduction on high-confidence subset is evaluation on calibration data
specific steps
-
fitted input called prediction
[Abstract]
"These signals are calibrated on labelled data to produce interpretable per-sample trust scores, providing indicators of prediction reliability on unlabelled turbines... Confidence-based filtering reduces MAE from 0.202 at full coverage to 0.070 for the highest-confidence 10% of predictions, demonstrating that confidence estimates are meaningfully related to prediction error. Unlabelled and out-of-distribution samples exhibit increased uncertainty and reduced confidence, indicating that the framework responds appropriately to distributional shift."
Calibration occurs solely on labelled data; the MAE reduction is then shown for high-confidence predictions. Since error can only be measured where labels exist, the filtering result is computed on the labelled set, making the 'demonstration' a statement about how well the fitted trust model matches its own training distribution rather than an independent test of reliability on unlabelled turbines.
full rationale
The framework calibrates multiple signals exclusively on the labelled subset to produce trust scores, then reports that confidence filtering reduces MAE from 0.202 to 0.070 on the top 10% as evidence that the scores indicate reliability for unlabelled turbines. Because ground-truth emissions labels exist only for the labelled turbines, the MAE-vs-confidence curve is necessarily computed on the same labelled distribution used for calibration; the reported improvement therefore demonstrates in-sample fit rather than out-of-distribution error correlation on the unlabelled fleet. No additional external validation or ground-truth comparison on unlabelled samples is described, so the central claim that the scores supply actionable reliability information for unlabelled turbines reduces to the calibration step itself.
Axiom & Free-Parameter Ledger
free parameters (1)
- trust-score calibration mapping
axioms (1)
- domain assumption The ensemble uncertainty, feature-space distance, auxiliary prediction error, and operating-range diagnostics are valid proxies for prediction error on unseen turbines.
Reference graph
Works this paper leans on
-
[1]
Aslan, E. (2024). Prediction and comparative analysis of emissions from gas turbines using random search optimization and different machine learning-based algorithms.Bulletin of the Polish Academy of Sciences. Technical Sciences72
2024
-
[2]
Blatz, J., Fitzgerald, E., Foster, G., Gandrabur, S., Goutte, C., Kulesza, A., et al. (2004). Confidence estimation for machine translation. InColing 2004: Proceedings of the 20th international conference on computational linguistics. 315–321 [Dataset] Corbière, C., Thome, N., Bar-Hen, A., Cord, M., and Pérez, P. (2019). Addressing failure prediction by l...
2004
-
[3]
Learning Confidence for Out-of-Distribution Detection in Neural Networks
DeVries, T. and Taylor, G. W. (2018). Learning confidence for out-of-distribution detection in neural networks.arXiv preprint arXiv:1802.04865 Dos Santos Coelho, L., Hultmann Ayala, H. V ., and Cocco Mariani, V . (2024). Co and nox emissions prediction in gas turbine using a novel modeling pipeline based on the combination of deep forest regressor and fea...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1016/j.fuel.2023.129366 2018
-
[4]
Hackney, R., Sadasivuni, S., Rogerson, J., and Bulat, G. (2016). Predictive emissions monitoring system for small siemens dry low emissions combustors: validation and application. InTurbo Expo: Power for Land, Sea, and Air (American Society of Mechanical Engineers), vol. 49767, V04BT04A032
2016
-
[5]
Hoque, K. E., Hossain, T., Haque, A. M., Miah, M. A. K., and Haque, M. A. (2024). Nox emission predictions in gas turbines through integrated data-driven machine learning approaches.Journal of Energy Resources Technology146, 071201. doi:10.1115/1.4065200 Hüllermeier, E. and Waegeman, W. (2021). Aleatoric and epistemic uncertainty in machine learning: An i...
-
[6]
Kaya, H., Tüfekci, P., and Uzun, E. (2019). Predicting co and nox emissions from gas turbines: novel data and a benchmark pems.Turkish Journal of Electrical Engineering and Computer Sciences27, 4783–4796
2019
-
[7]
Lakshminarayanan, B., Pritzel, A., and Blundell, C. (2017). Simple and scalable predictive uncertainty estimation using deep ensembles.Advances in neural information processing systems30
2017
-
[8]
Lee, K., Lee, H., Lee, K., and Shin, J. (2017). Training confidence-calibrated classifiers for detecting out-of-distribution samples.arXiv preprint arXiv:1711.09325
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[9]
Lee, K., Lee, K., Lee, H., and Shin, J. (2018). A simple unified framework for detecting out-of-distribution samples and adversarial attacks. InAdvances in Neural Information Processing Systems, eds. S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett (Curran Associates, Inc.), vol. 31
2018
-
[10]
Liu, Z. and Karimi, I. A. (2020). Gas turbine performance prediction via machine learning.Energy192, 116627. doi:https://doi.org/10.1016/j.energy.2019.116627
-
[11]
Mo, D., Lin, Y ., Liu, Y ., Wang, Y ., Qin, Z., and Han, X. (2025). A review of recent advances in the application of machine learning algorithms for gas turbine combustion.Propulsion and Energy1, 20 [Dataset] Moon, J., Kim, J., Shin, Y ., and Hwang, S. (2020). Confidence-aware learning for deep neural networks
2025
-
[12]
Potts, R., Hackney, R., and Leontidis, G. (2023). Tabular machine learning methods for predicting gas turbine emissions. Machine Learning and Knowledge Extraction5, 1055–1075
2023
-
[13]
Wang, K., Ma, Q., Shen, C., and Lu, J. (2025). Application of uncertainty to out-of-distribution detection for autonomous driving perception safety.IEEE Transactions on Intelligent Transportation Systems
2025
-
[14]
Zhao, Z., Alzubaidi, L., Zhang, J., Duan, Y ., and Gu, Y . (2024). A comparison review of transfer learning and self-supervised learning: Definitions, applications, advantages and limitations.Expert Systems with Applications242, 122807 14
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.