X+Slides: Benchmarking Audience-Conditioned Slide Generation
Pith reviewed 2026-06-26 20:36 UTC · model grok-4.3
The pith
A new benchmark shows current slide generators recover only a partial share of the information different audiences need from the same source.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Audience-conditioned slide generation must be measured with source-grounded probes that carry audience-specific utility weights, because existing systems recover only an incomplete portion of the information each audience type needs; at a threshold of 0.7, the best observed Audience Coverage is 0.714 for one system, 0.594 for another, and 0.853 for a NotebookLM ablation that still exhibits grounding shortfalls.
What carries the argument
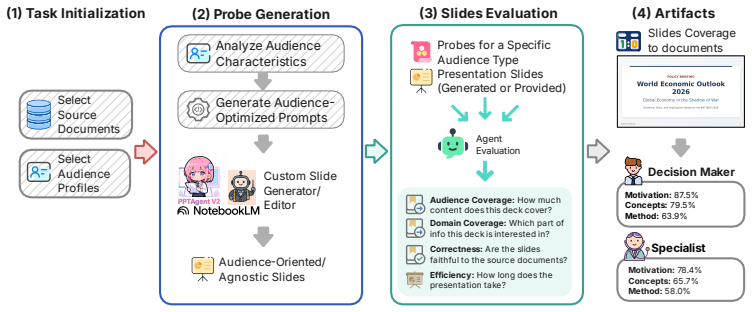
Dynamic evaluation framework of 8,133 deduplicated source-grounded probes with audience-specific utility weights, used to compute Audience Coverage, Domain-wise Coverage, Efficiency, and Correctness.
If this is right
- Audience Coverage quantifies the fraction of essential information conveyed to a specific listener group.
- Systems must be assessed on source grounding rather than visual quality or topic breadth alone.
- NotebookLM-style ablations can reach higher coverage numbers but still differ in how claims trace back to the source.
- Four complementary metrics together give a fuller picture than completeness checks used in prior benchmarks.
Where Pith is reading between the lines
- Future generators could incorporate audience type as an explicit input when selecting which source details to emphasize.
- The probe-weighting method could be adapted to evaluate other audience-sensitive outputs such as reports or summaries.
- Extending the benchmark to live presentation feedback might reveal whether coverage scores predict real listener comprehension.
Load-bearing premise
Audience-specific utility weights assigned to the same source-grounded probes accurately capture real-world differences in what different audiences need from the same source material.
What would settle it
A direct comparison in which target audiences rate the practical utility of generated slides and the ratings fail to correlate with the benchmark's weighted Audience Coverage scores.
Figures








read the original abstract
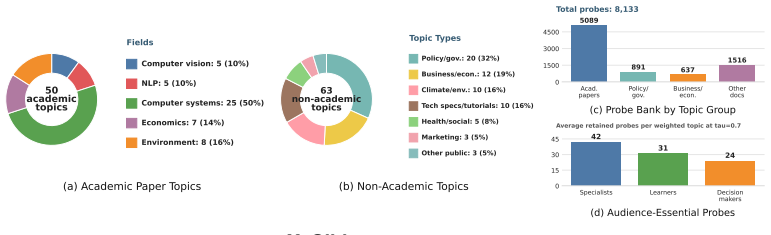
Automatically generating slide decks from source documents is an important application of large language models (LLMs). Existing benchmarks primarily assess slide completeness and technical depth, while overlooking the target audience as a critical real-world factor. For instance, specialists demand rigorous proofs, whereas decision-makers prioritize actionable conclusions. To bridge this gap, we introduce X+Slides, a benchmark specifically designed for audience-conditioned slide generation. Built on a diverse corpus spanning 113 topics and seven presentation scenes, X+Slides employs a dynamic evaluation framework constructed from 8,133 deduplicated, source-grounded probes. By assigning audience-specific utility weights to the same source-grounded probes, X+Slides reports four complementary metrics: Audience Coverage measures how much audience-essential information is conveyed, Domain-wise Coverage shows which information types are covered, Efficiency measures delivered utility per unit of attention cost, and Correctness verifies whether slide claims are supported by the source. Experiments on DeepPresenter, SlideTailor, and NotebookLM show that current systems can recover a substantial but still incomplete part of audience-essential information: at $\tau_A=0.7$, DeepPresenter reaches a best Audience Coverage of 0.714, SlideTailor reaches 0.594, and the NotebookLM ablation reaches 0.853 while showing clear grounding differences. These results indicate that visual quality and broad topic coverage should not be treated as evidence support without source-grounded evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces X+Slides, a benchmark for audience-conditioned slide generation from source documents. It constructs a corpus over 113 topics and seven scenes, defines 8,133 deduplicated source-grounded probes, assigns audience-specific utility weights to those probes, and reports four metrics (Audience Coverage, Domain-wise Coverage, Efficiency, Correctness). Experiments on DeepPresenter, SlideTailor, and a NotebookLM ablation report Audience Coverage values of 0.714, 0.594, and 0.853 at τ_A=0.7 and conclude that existing systems recover only a partial fraction of audience-essential information, so visual quality and broad topic coverage are insufficient without source-grounded, audience-weighted evaluation.
Significance. If the utility-weight assignment procedure and probe validation are made reproducible and externally validated, the benchmark would supply a concrete, audience-differentiated evaluation framework that existing slide-generation papers largely lack. The reported coverage gaps would then constitute a falsifiable, quantitative demonstration that generic completeness metrics are inadequate.
major comments (2)
- [Abstract] Abstract: the Audience Coverage metric is defined as the sum of audience-specific utility weights on recovered probes, yet the abstract (and, from the provided description, the methods) gives no account of how those weights were assigned, what inter-rater protocol was used, or any external validation against real audience responses (specialists vs. decision-makers). Because the comparative claims rest directly on the numerical differences produced by these weights, the omission renders the reported scores (0.714, 0.594, 0.853) uninterpretable as evidence of incomplete audience conditioning.
- [Benchmark construction] Benchmark construction (implied in abstract): the paper states that 8,133 probes are “deduplicated, source-grounded,” but supplies no description of probe generation, deduplication criteria, or any validation that the probes actually capture audience-essential information rather than author-chosen content. This construction step is load-bearing for all four metrics.
minor comments (2)
- [Abstract] The symbol τ_A is used without definition in the abstract; a brief parenthetical or footnote would clarify the threshold.
- [Abstract] The phrase “treated as evidence support” appears to be a minor phrasing error; “treated as evidence of support” or “treated as supporting evidence” would be clearer.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important gaps in the description of our benchmark construction and metric definitions. We address each major comment below and will incorporate the requested details into a revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the Audience Coverage metric is defined as the sum of audience-specific utility weights on recovered probes, yet the abstract (and, from the provided description, the methods) gives no account of how those weights were assigned, what inter-rater protocol was used, or any external validation against real audience responses (specialists vs. decision-makers). Because the comparative claims rest directly on the numerical differences produced by these weights, the omission renders the reported scores (0.714, 0.594, 0.853) uninterpretable as evidence of incomplete audience conditioning.
Authors: We agree that the abstract and methods description omit the necessary details on utility weight assignment, inter-rater protocol, and external validation, which limits interpretability of the Audience Coverage scores. The full manuscript provides only a high-level statement that weights are audience-specific. In revision we will add a dedicated subsection describing the weight assignment process, including annotation guidelines, number of raters, inter-rater agreement, and any validation steps performed against real audience distinctions (specialists versus decision-makers). revision: yes
-
Referee: [Benchmark construction] Benchmark construction (implied in abstract): the paper states that 8,133 probes are “deduplicated, source-grounded,” but supplies no description of probe generation, deduplication criteria, or any validation that the probes actually capture audience-essential information rather than author-chosen content. This construction step is load-bearing for all four metrics.
Authors: We agree that the manuscript does not supply the required details on probe generation, deduplication criteria, or validation that the probes capture audience-essential information. The current text only asserts that the probes are deduplicated and source-grounded. We will revise the benchmark construction section to include a complete description of the probe generation pipeline, the deduplication criteria and thresholds employed, and the validation procedures (such as expert review or pilot studies) used to confirm that probes reflect audience-essential content rather than arbitrary selections. revision: yes
Circularity Check
No circularity: benchmark metrics defined independently from external probes
full rationale
The paper introduces X+Slides as an evaluation framework built on 8,133 source-grounded probes across topics and scenes. Metrics (Audience Coverage, Domain-wise Coverage, Efficiency, Correctness) are computed by applying assigned audience-specific utility weights to these probes. No equations, derivations, or predictions are present that reduce to fitted parameters or self-referential inputs. The weights are stated as assigned inputs to the framework rather than outputs derived from the evaluated systems. No self-citations justify core premises, uniqueness theorems, or ansatzes. The experiments apply the benchmark to external systems (DeepPresenter, SlideTailor, NotebookLM) without the results feeding back into the metric definitions. The chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Audience-specific utility weights accurately reflect real differences in audience information needs
Reference graph
Works this paper leans on
-
[1]
Autopresent: Designing structured visuals from scratch,
J. Ge, Z. Z. Wang, X. Zhou, Y .-H. Peng, S. Subramanian, Q. Tan, M. Sap, A. Suhr, D. Fried, G. Neubiget al., “Autopresent: Designing structured visuals from scratch,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 2902–2911
2025
-
[2]
Slidecoder: Layout-aware rag-enhanced hierarchical slide generation from design,
W. Tang, J. Xiao, W. Jiang, X. Xiao, Y . Wang, X. Tang, Q. Li, Y . Ma, J. Liu, S. Tanget al., “Slidecoder: Layout-aware rag-enhanced hierarchical slide generation from design,” inProceed- ings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025, pp. 9026–9050
2025
-
[3]
Pptagent: Generating and evaluating presentations beyond text-to-slides,
H. Zheng, X. Guan, H. Kong, W. Zhang, J. Zheng, W. Zhou, H. Lin, Y . Lu, X. Han, and L. Sun, “Pptagent: Generating and evaluating presentations beyond text-to-slides,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025, pp. 14 413–14 429
2025
-
[4]
Deeppresenter: Environment-grounded reflection for agentic presentation generation,
H. Zheng, G. Mo, X. Yan, Q. Yuan, W. Zhang, X. Chen, Y . Lu, H. Lin, X. Han, and L. Sun, “Deeppresenter: Environment-grounded reflection for agentic presentation generation,”arXiv preprint arXiv:2602.22839, 2026
Pith/arXiv arXiv 2026
-
[5]
Slidebot: A multi-agent framework for gen- erating informative, reliable, multi-modal presentations,
E. Xie, D. Waterfield, M. Kennedy, and A. Zhang, “Slidebot: A multi-agent framework for gen- erating informative, reliable, multi-modal presentations,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 48, 2026, pp. 40 907–40 915
2026
-
[6]
Deckbench: Benchmarking multi-agent frameworks for academic slide generation and editing,
D. Jang, M. L. Heisler, L. Xing, Y . Li, E. Wang, Y . Xiong, Y . Zhang, and Z. Fan, “Deckbench: Benchmarking multi-agent frameworks for academic slide generation and editing,”arXiv preprint arXiv:2602.13318, 2026
Pith/arXiv arXiv 2026
-
[7]
Slidetailor: Personalized presentation slide gener- ation for scientific papers,
W. Zeng, M. Ouyang, L. Cui, and H. T. Ng, “Slidetailor: Personalized presentation slide gener- ation for scientific papers,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 41, 2026, pp. 34 584–34 592
2026
-
[8]
Narrative-driven paper-to-slide generation via arcdeck,
T. C. Ozden, S. VS, F. Horoz, O. Kara, J. Kim, and J. M. Rehg, “Narrative-driven paper-to-slide generation via arcdeck,”arXiv preprint arXiv:2604.11969, 2026
Pith/arXiv arXiv 2026
-
[9]
Y . Yang, W. Jiang, Y . Wang, Y . Song, Y . Wang, and C. Zhang, “Auto-slides: An interac- tive multi-agent system for creating and customizing research presentations,”arXiv preprint arXiv:2509.11062, 2025
arXiv 2025
-
[10]
Presentbench: A fine-grained rubric-based benchmark for slide generation,
X.-S. Chen, J. Zhu, P.-l. Li, H. Wang, S. Yang, and M.-H. Guo, “Presentbench: A fine-grained rubric-based benchmark for slide generation,”arXiv preprint arXiv:2603.07244, 2026
arXiv 2026
-
[11]
Slidesgen- bench: Evaluating slides generation via computational and quantitative metrics,
Y . Yang, W. Li, H. Ren, Z. Lu, K. Wang, Z. Huang, Z. Zong, M. Zhan, and H. Li, “Slidesgen- bench: Evaluating slides generation via computational and quantitative metrics,”arXiv preprint arXiv:2601.09487, 2026
arXiv 2026
-
[12]
Pptarena: A benchmark for agentic powerpoint editing,
M. Ofengenden, Y . Man, Z. Pang, and Y .-X. Wang, “Pptarena: A benchmark for agentic powerpoint editing,”arXiv preprint arXiv:2512.03042, 2025
arXiv 2025
-
[13]
Z. Huang, X. Liu, T. Hu, K. Zhang, and Y . Liu, “Pptbench: Towards holistic evaluation of large language models for powerpoint layout and design understanding,”arXiv preprint arXiv:2512.02624, 2025
arXiv 2025
-
[14]
Paper2poster: Towards multimodal poster automation from scientific papers,
W. Pang, K. Q. Lin, X. Jian, X. He, and P. Torr, “Paper2poster: Towards multimodal poster automation from scientific papers,”arXiv preprint arXiv:2505.21497, 2025
arXiv 2025
-
[15]
Personalens: A benchmark for personalization evaluation in conversational ai assistants,
Z. Zhao, C. Vania, S. Kayal, N. Khan, S. B. Cohen, and E. Yilmaz, “Personalens: A benchmark for personalization evaluation in conversational ai assistants,” inFindings of the Association for Computational Linguistics: ACL 2025, 2025, pp. 18 023–18 055
2025
-
[16]
Cfbench: A comprehensive constraints-following benchmark for llms,
T. Zhang, C. Zhu, Y . Shen, W. Luo, Y . Zhang, H. Liang, F. Yang, M. Lin, Y . Qiao, W. Chen et al., “Cfbench: A comprehensive constraints-following benchmark for llms,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025, pp. 32 926–32 944
2025
-
[17]
Judge anything: Mllm as a judge across any modality,
S. Pu, Y . Wang, D. Chen, Y . Chen, G. Wang, Q. Qin, Z. Zhang, Z. Zhang, Z. Zhou, S. Gong et al., “Judge anything: Mllm as a judge across any modality,” inProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2, 2025, pp. 5742–5753. 14 A Appendix A.1 Source Document Details We provide the source document composition in S...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.