CP4D: Compositional Physics-aware 4D Scene Generation
Pith reviewed 2026-06-27 16:50 UTC · model grok-4.3
The pith
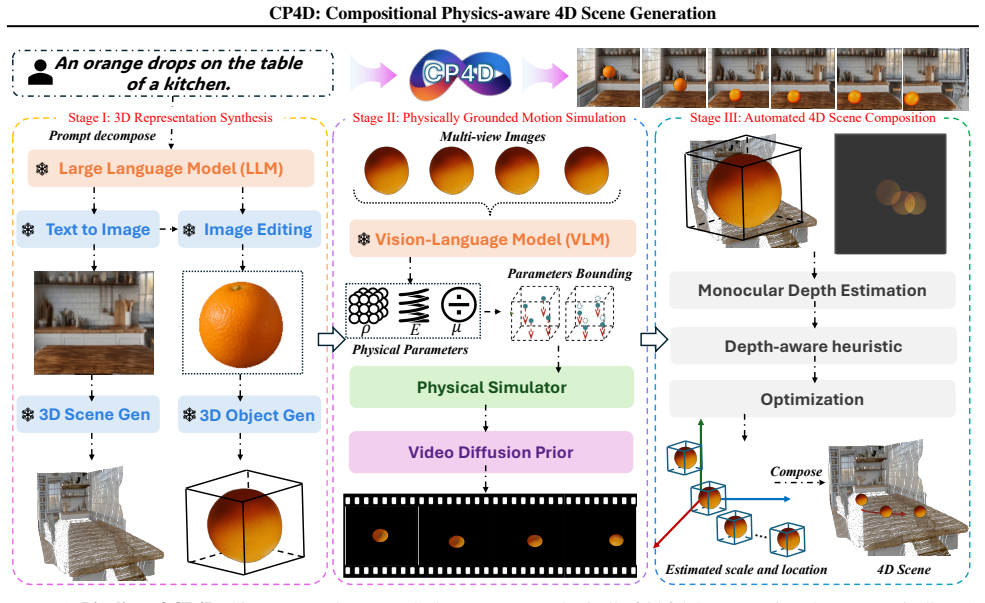
CP4D generates 4D scenes by composing static 3D environments with physically grounded dynamic objects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that reformulating 4D generation as the integration of a static 3D environment with physically grounded dynamic objects, produced via pre-trained expert models for each part, a hybrid motion synthesis step that merges simulator priors with video diffusion common sense, and an automated composition mechanism, yields photorealistic 4D scenes that respect complex physical dynamics.
What carries the argument
The hybrid motion synthesis strategy, which combines priors from physical simulators with the common sense embedded in video diffusion models to create object trajectories and interactions.
If this is right
- Generated scenes support exploration and interaction while maintaining visual fidelity.
- Dynamic objects exhibit strong physical plausibility in their motion and contacts.
- Users obtain fine-grained control over the placement and behavior of objects in the final 4D output.
- The resulting scenes outperform prior methods on standard visual and physical quality metrics.
Where Pith is reading between the lines
- The separation of static and dynamic elements could allow reuse of existing 3D asset libraries without retraining an entire 4D model from scratch.
- The same pipeline might support insertion of real captured objects into simulated environments for mixed-reality testing.
- Scaling the hybrid synthesis to many interacting objects would test whether the current merging step remains stable.
Load-bearing premise
The hybrid motion synthesis strategy that integrates priors from physical simulators with the common sense embedded in video diffusion models will reliably produce trajectories and interactions that are both physically accurate and visually coherent without additional constraints or post-processing.
What would settle it
Generate a scene containing a dropped rigid object on a flat surface and measure whether the resulting trajectory shows penetration, floating, or other violations that the method claims to avoid.
Figures
























read the original abstract
4D generation (\textit{i.e.}, dynamic 3D generation) has recently emerged as a rapidly growing research frontier due to its powerful spatiotemporal modeling capabilities. However, despite notable advances, existing approaches typically fail to capture the underlying physical principles, producing results that are both physically inconsistent and visually implausible. To overcome this limitation, we present CP4D, a novel paradigm for photorealistic 4D scene synthesis with faithful adherence to complex physical dynamics. Drawing inspiration from the compositional nature of real-world scenes, where immutable static backgrounds coexist with dynamic, physically plausible foregrounds, CP4D reformulates 4D generation as the integration of a static 3D environment with physically grounded dynamic objects. On this basis, our framework follows a three-stage pipeline: \textbf{1)} Firstly, we leverage pre-trained expert models to generate high-fidelity 3D representations of the environment and foreground objects respectively. \textbf{2)} Subsequently, to produce physically plausible trajectories and realistic interactions for these objects, we propose a hybrid motion synthesis strategy that integrates priors from physical simulators with the common sense embedded in video diffusion models. \textbf{3)} Finally, we develop an automated composition mechanism that seamlessly fuses the static environment and dynamic objects into coherent, physically consistent 4D scenes. Extensive experiments demonstrate that CP4D can generate explorable and interactive 4D scenes with high visual fidelity, strong physical plausibility, and fine-grained controllability, significantly outperforming existing methods. The project page: https://anonymous.4open.science/w/CP4D/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CP4D, a three-stage compositional framework for 4D scene generation: (1) separate generation of high-fidelity static 3D environments and dynamic foreground objects via pre-trained expert models, (2) hybrid motion synthesis that integrates priors from physical simulators with common sense from video diffusion models to produce trajectories and interactions, and (3) an automated composition mechanism to fuse them into coherent scenes. It claims this yields explorable, interactive 4D scenes with high visual fidelity, strong physical plausibility, fine-grained controllability, and significant outperformance over existing methods.
Significance. If the physical-plausibility and outperformance claims are substantiated with quantitative evidence, the work would represent a meaningful advance in 4D generation by explicitly incorporating physical dynamics rather than relying solely on learned priors, with potential impact on simulation, robotics, and interactive media.
major comments (2)
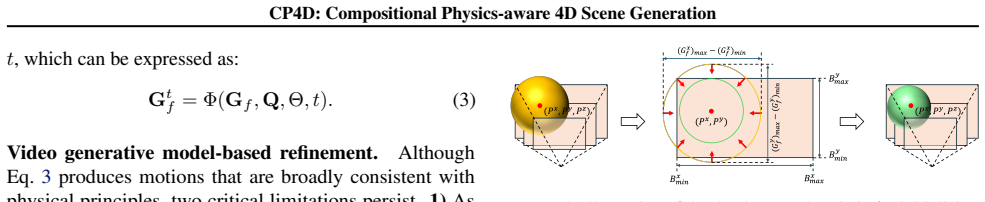
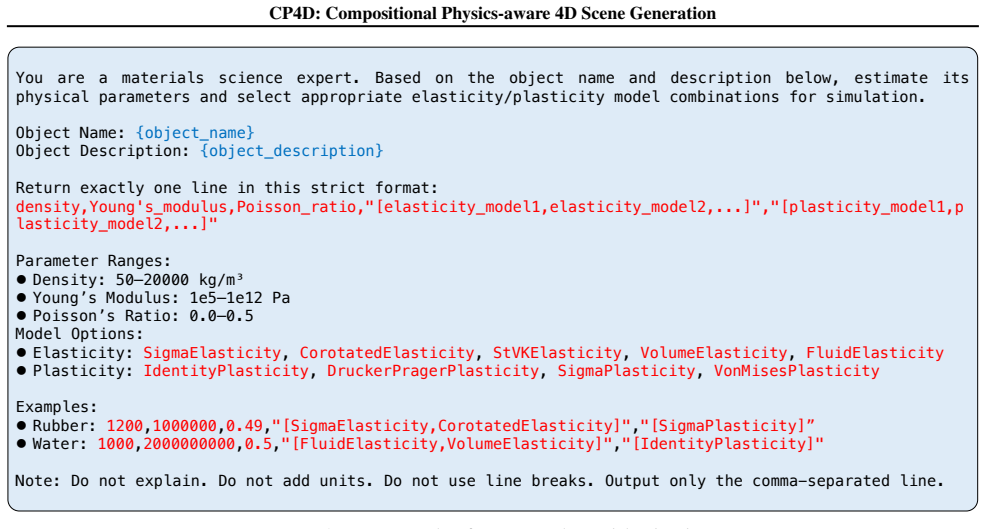
- [Method (stage 2)] The hybrid motion synthesis strategy (stage 2) is presented only at a high level as 'integrating priors from physical simulators with the common sense embedded in video diffusion models' together with an 'automated composition mechanism,' without any equations, algorithm, conflict-resolution procedure, or constraints. This mechanism is load-bearing for the central claim of 'strong physical plausibility' and 'without additional constraints or post-processing.'
- [Abstract / Experiments] The abstract states that 'extensive experiments demonstrate' outperformance and physical plausibility, yet supplies no quantitative metrics, baselines, error analysis, or evaluation protocols. This absence directly undermines assessment of the soundness of the physical-consistency and superiority claims.
minor comments (1)
- [Abstract] The project page is listed as anonymous; while acceptable for review, the absence of any concrete numerical results or protocol details in the abstract reduces immediate clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify areas where additional technical detail and quantitative evidence are needed to support the central claims. We address each point below and will incorporate revisions accordingly.
read point-by-point responses
-
Referee: [Method (stage 2)] The hybrid motion synthesis strategy (stage 2) is presented only at a high level as 'integrating priors from physical simulators with the common sense embedded in video diffusion models' together with an 'automated composition mechanism,' without any equations, algorithm, conflict-resolution procedure, or constraints. This mechanism is load-bearing for the central claim of 'strong physical plausibility' and 'without additional constraints or post-processing.'
Authors: We agree that the high-level description in the current manuscript is insufficient to fully substantiate the physical-plausibility claims or enable reproduction. In the revised manuscript we will expand Section 3.2 to include the explicit equations for combining simulator priors with diffusion outputs, the full algorithm with pseudocode, the conflict-resolution procedure between physics and learned common sense, and the constraints (if any) applied during composition. revision: yes
-
Referee: [Abstract / Experiments] The abstract states that 'extensive experiments demonstrate' outperformance and physical plausibility, yet supplies no quantitative metrics, baselines, error analysis, or evaluation protocols. This absence directly undermines assessment of the soundness of the physical-consistency and superiority claims.
Authors: The observation is accurate: the abstract currently asserts results without accompanying numbers or protocols. We will revise the abstract to reference the specific quantitative metrics, baselines, and evaluation protocols used, and we will expand the experiments section to report all numerical results, error analyses, and comparison details that support the outperformance and physical-plausibility statements. revision: yes
Circularity Check
No circularity: engineering pipeline with no derivation chain
full rationale
The paper describes CP4D as a three-stage engineering pipeline (pre-trained 3D generation, hybrid motion synthesis integrating simulators and video diffusion, automated composition) without any equations, fitted parameters, predictions, or first-principles derivations. No self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations appear in the provided text. The central claims rest on the integration of external pre-trained models and an unspecified hybrid strategy rather than any result that reduces to its own inputs by construction, making the method self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2406.03520 , year=
Videophy: Evaluating physical commonsense for video generation , author=. arXiv preprint arXiv:2406.03520 , year=
-
[2]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Physgaussian: Physics-integrated 3d gaussians for generative dynamics , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[3]
arXiv preprint arXiv:2411.12789 , year=
Efficient Physics Simulation for 3D Scenes via MLLM-Guided Gaussian Splatting , author=. arXiv preprint arXiv:2411.12789 , year=
-
[4]
2025 IEEE Conference on Virtual Reality and 3D User Interfaces Abstracts and Workshops (VRW) , pages=
LIVE-GS: LLM Powers Interactive VR by Enhancing Gaussian Splatting , author=. 2025 IEEE Conference on Virtual Reality and 3D User Interfaces Abstracts and Workshops (VRW) , pages=. 2025 , organization=
2025
-
[5]
Proceedings of the AAAI Conference on Artificial Intelligence , pages=
DreamPhysics: Learning Physics-Based 3D Dynamics with Video Diffusion Priors , author=. Proceedings of the AAAI Conference on Artificial Intelligence , pages=
-
[6]
arXiv preprint arXiv:2406.04338 , year=
Physics3d: Learning physical properties of 3d gaussians via video diffusion , author=. arXiv preprint arXiv:2406.04338 , year=
-
[7]
arXiv preprint arXiv:2501.18982 , year=
OmniphysGS: 3d constitutive gaussians for general physics-based dynamics generation , author=. arXiv preprint arXiv:2501.18982 , year=
-
[8]
arXiv preprint arXiv:2409.07179 , year=
Phy124: Fast physics-driven 4d content generation from a single image , author=. arXiv preprint arXiv:2409.07179 , year=
-
[9]
arXiv preprint arXiv:2411.16800 , year=
Phys4DGen: Physics-Compliant 4D Generation with Multi-Material Composition Perception , author=. arXiv preprint arXiv:2411.16800 , year=
-
[10]
arXiv preprint arXiv:2411.17189 , year=
Physmotion: Physics-grounded dynamics from a single image , author=. arXiv preprint arXiv:2411.17189 , year=
-
[11]
ACM Transactions on Graphics (TOG) , volume=
A moving least squares material point method with displacement discontinuity and two-way rigid body coupling , author=. ACM Transactions on Graphics (TOG) , volume=. 2018 , publisher=
2018
-
[12]
ACM Transactions on Graphics (TOG) , pages=
Anisotropic elastoplasticity for cloth, knit and hair frictional contact , author=. ACM Transactions on Graphics (TOG) , pages=. 2017 , publisher=
2017
-
[13]
ACM Transactions on Graphics (TOG) , pages=
Taichi: a language for high-performance computation on spatially sparse data structures , author=. ACM Transactions on Graphics (TOG) , pages=. 2019 , publisher=
2019
-
[14]
, author=
3D Gaussian splatting for real-time radiance field rendering. , author=. ACM Trans. Graph. , pages=
-
[15]
arXiv preprint arXiv:2209.14988 , year=
Dreamfusion: Text-to-3d using 2d diffusion , author=. arXiv preprint arXiv:2209.14988 , year=
-
[16]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Uniscene: Unified occupancy-centric driving scene generation , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[17]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Drivedreamer4d: World models are effective data machines for 4d driving scene representation , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[18]
arXiv preprint arXiv:2506.04225 , year=
Voyager: Long-Range and World-Consistent Video Diffusion for Explorable 3D Scene Generation , author=. arXiv preprint arXiv:2506.04225 , year=
-
[19]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Wonderworld: Interactive 3d scene generation from a single image , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[20]
arXiv preprint arXiv:2409.02048 , year=
Viewcrafter: Taming video diffusion models for high-fidelity novel view synthesis , author=. arXiv preprint arXiv:2409.02048 , year=
-
[21]
ACM Transactions on Graphics (TOG) , volume=
A material point method for snow simulation , author=. ACM Transactions on Graphics (TOG) , volume=. 2013 , publisher=
2013
-
[22]
Acm siggraph 2016 courses , pages=
The material point method for simulating continuum materials , author=. Acm siggraph 2016 courses , pages=
2016
-
[23]
2006 , publisher=
Computational Inelasticity , author=. 2006 , publisher=
2006
-
[24]
Advances in neural information processing systems , volume=
Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation , author=. Advances in neural information processing systems , volume=
-
[25]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Physgen3d: Crafting a miniature interactive world from a single image , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[26]
European Conference on Computer Vision , pages=
Physgen: Rigid-body physics-grounded image-to-video generation , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[27]
2025 , booktitle=
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer , author=. 2025 , booktitle=
2025
-
[28]
arXiv preprint arXiv:2503.20314 , year=
Wan: Open and advanced large-scale video generative models , author=. arXiv preprint arXiv:2503.20314 , year=
-
[29]
arXiv preprint arXiv:2312.17142 , year=
Dreamgaussian4d: Generative 4d gaussian splatting , author=. arXiv preprint arXiv:2312.17142 , year=
-
[30]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Vbench: Comprehensive benchmark suite for video generative models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[31]
arXiv preprint arXiv:2504.00983 , year=
Worldscore: A unified evaluation benchmark for world generation , author=. arXiv preprint arXiv:2504.00983 , year=
-
[32]
Advances in neural information processing systems , volume=
Denoising diffusion probabilistic models , author=. Advances in neural information processing systems , volume=
-
[33]
arXiv preprint arXiv:2010.02502 , year=
Denoising diffusion implicit models , author=. arXiv preprint arXiv:2010.02502 , year=
Pith/arXiv arXiv 2010
-
[34]
arXiv preprint arXiv:2407.17470 , year=
Sv4d: Dynamic 3d content generation with multi-frame and multi-view consistency , author=. arXiv preprint arXiv:2407.17470 , year=
-
[35]
arXiv preprint arXiv:2311.02848 , year=
Consistent4d: Consistent 360 \ deg \ dynamic object generation from monocular video , author=. arXiv preprint arXiv:2311.02848 , year=
-
[36]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
4d-fy: Text-to-4d generation using hybrid score distillation sampling , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[37]
arXiv preprint arXiv:2406.13527 , year=
4k4dgen: Panoramic 4d generation at 4k resolution , author=. arXiv preprint arXiv:2406.13527 , year=
-
[38]
arXiv preprint arXiv:2507.01099 , year=
Geometry-aware 4D Video Generation for Robot Manipulation , author=. arXiv preprint arXiv:2507.01099 , year=
-
[39]
arXiv preprint arXiv:2506.01103 , year=
DeepVerse: 4D Autoregressive Video Generation as a World Model , author=. arXiv preprint arXiv:2506.01103 , year=
-
[40]
arXiv preprint arXiv:2503.05638 , year=
Trajectorycrafter: Redirecting camera trajectory for monocular videos via diffusion models , author=. arXiv preprint arXiv:2503.05638 , year=
-
[41]
arXiv preprint arXiv:2506.04590 , year=
Follow-Your-Creation: Empowering 4D Creation through Video Inpainting , author=. arXiv preprint arXiv:2506.04590 , year=
-
[42]
European Conference on Computer Vision , pages=
Tc4d: Trajectory-conditioned text-to-4d generation , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[43]
European Conference on Computer Vision , pages=
Stag4d: Spatial-temporal anchored generative 4d gaussians , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[44]
Advances in Neural Information Processing Systems , volume=
L4gm: Large 4d gaussian reconstruction model , author=. Advances in Neural Information Processing Systems , volume=
-
[45]
arXiv preprint arXiv:2405.16645 , year=
Diffusion4d: Fast spatial-temporal consistent 4d generation via video diffusion models , author=. arXiv preprint arXiv:2405.16645 , year=
-
[46]
arXiv preprint arXiv:2503.11647 , year=
Recammaster: Camera-controlled generative rendering from a single video , author=. arXiv preprint arXiv:2503.11647 , year=
-
[47]
arXiv preprint arXiv:2403.16993 , year=
Comp4d: Llm-guided compositional 4d scene generation , author=. arXiv preprint arXiv:2403.16993 , year=
-
[48]
Advances in neural information processing systems , volume=
Compositional 3d-aware video generation with llm director , author=. Advances in neural information processing systems , volume=
-
[49]
arXiv preprint arXiv:2501.01722 , year=
Ar4d: Autoregressive 4d generation from monocular videos , author=. arXiv preprint arXiv:2501.01722 , year=
-
[50]
Advances in Neural Information Processing Systems , volume=
Dreammesh4d: Video-to-4d generation with sparse-controlled gaussian-mesh hybrid representation , author=. Advances in Neural Information Processing Systems , volume=
-
[51]
arXiv preprint arXiv:2403.12365 , year=
Gaussianflow: Splatting gaussian dynamics for 4d content creation , author=. arXiv preprint arXiv:2403.12365 , year=
-
[52]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Nerfies: Deformable neural radiance fields , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[53]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Objaverse: A universe of annotated 3d objects , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[54]
arXiv preprint arXiv:2407.02371 , year=
Openvid-1m: A large-scale high-quality dataset for text-to-video generation , author=. arXiv preprint arXiv:2407.02371 , year=
-
[55]
arXiv preprint arXiv:2404.02101 , year=
Cameractrl: Enabling camera control for text-to-video generation , author=. arXiv preprint arXiv:2404.02101 , year=
-
[56]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
4d gaussian splatting for real-time dynamic scene rendering , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[57]
arXiv preprint arXiv:2303.08774 , year=
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
-
[58]
arXiv preprint arXiv:2508.02324 , year=
Qwen-image technical report , author=. arXiv preprint arXiv:2508.02324 , year=
-
[59]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Segment anything , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[60]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Depth anything: Unleashing the power of large-scale unlabeled data , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[61]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Structured 3d latents for scalable and versatile 3d generation , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[62]
arXiv preprint arXiv:1412.6980 , year=
Adam: A method for stochastic optimization , author=. arXiv preprint arXiv:1412.6980 , year=
-
[63]
arXiv preprint arXiv:2308.06571 , year=
Modelscope text-to-video technical report , author=. arXiv preprint arXiv:2308.06571 , year=
-
[64]
arXiv preprint arXiv:2508.15376 , year=
DriveSplat: Decoupled Driving Scene Reconstruction with Geometry-enhanced Partitioned Neural Gaussians , author=. arXiv preprint arXiv:2508.15376 , year=
-
[65]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
FluidNexus: 3D fluid reconstruction and prediction from a single video , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[66]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Unleashing the potential of multi-modal foundation models and video diffusion for 4d dynamic physical scene simulation , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[67]
arXiv preprint arXiv:2411.04989 , year=
Sg-i2v: Self-guided trajectory control in image-to-video generation , author=. arXiv preprint arXiv:2411.04989 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.