FLUID: From Ephemeral IDs to Multimodal Semantic Codes for Industrial-Scale Livestreaming Recommendation
Pith reviewed 2026-05-22 08:17 UTC · model grok-4.3
The pith
FLUID replaces ephemeral item IDs with hierarchical multimodal codes from short videos and livestreams in large-scale ranking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
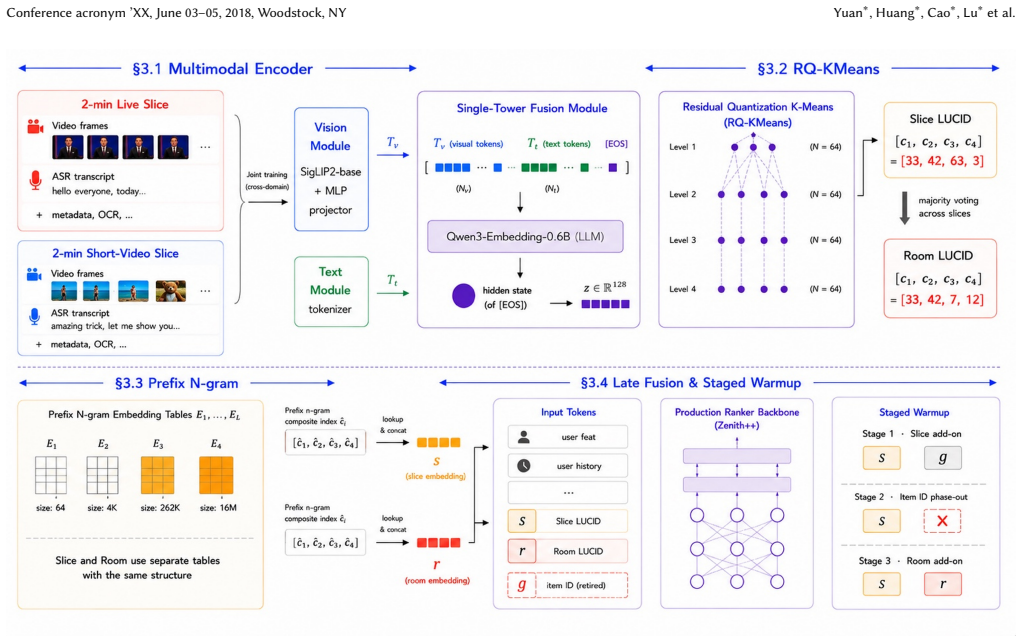
FLUID is the first framework to retire the candidate-side item ID completely from a production livestreaming ranker. It couples a cross-domain multimodal encoder, trained jointly on short videos and livestreams to emit discrete hierarchical LUCID codes, with a late-fusion architecture that treats slice-level and room-level codes as independent tokens and stabilizes training through staged warmup under incremental online updates.
What carries the argument
LUCID codes: discrete hierarchical semantic tokens generated by a cross-domain multimodal encoder jointly trained on short videos and livestreams; these tokens substitute for item ID embeddings inside an ID-free late-fusion ranking model.
If this is right
- The ID-free ranker generalizes to newly created live rooms that have never accumulated interaction data.
- Joint training on short videos and livestreams produces codes that transfer semantic information across the two domains.
- Staged warmup during online incremental training keeps the model stable after the removal of item ID embeddings.
- Production deployment on platforms serving over one billion users yields gains of +0.55% Quality Watch Duration and +2.05% Cold-Start Room Views.
Where Pith is reading between the lines
- The same code-generation approach could be tested on other short-lived content such as stories or temporary events where persistent IDs are unavailable.
- Removing item IDs may reduce memory footprint and embedding table size in very large catalogs.
- Cross-domain training might improve consistency when users move between short-form video and live content within the same app.
Load-bearing premise
The LUCID codes can capture and replace the collaborative signals that would normally come from user interactions with persistent item IDs.
What would settle it
An online A/B test on new live rooms that shows equal or lower cold-start room views when LUCID codes are removed compared with the ID-based baseline would falsify the central claim.
Figures




read the original abstract
Modern recommender systems rely heavily on ID-based collaborative filtering: each item is represented by a unique ID embedding that accumulates collaborative signals from user interactions. Livestreaming recommendation, however, faces a unique challenge in this paradigm: a live room typically broadcasts for only tens of minutes, so its item ID remains poorly learned in a persistent cold-start state and ID-centric ranking models fail to generalize. We present FLUID, the first framework to fully retire the candidate-side item ID from a production-scale livestreaming ranker. FLUID couples a cross-domain multimodal encoder, jointly trained on short videos and livestreams to produce discrete hierarchical codes (LUCID), with a late-fusion, ID-free design that injects slice-level and room-level LUCID as independent tokens, stabilized by a staged warmup under online incremental training. Deployed on our industrial livestreaming recommenders with a cross-platform combined user base of over one billion globally, FLUID delivers significant online gains of +0.55% Quality Watch Duration, +2.05% Cold-Start Room Views, and +0.05% Active Hours.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents FLUID, a framework that retires candidate-side item ID embeddings from a production livestreaming ranker. It couples a cross-domain multimodal encoder (jointly trained on short videos and livestreams) that outputs discrete hierarchical codes called LUCID with a late-fusion ID-free architecture that injects slice-level and room-level LUCID tokens as independent features, stabilized by staged warmup under online incremental training. The paper reports online A/B gains of +0.55% Quality Watch Duration, +2.05% Cold-Start Room Views, and +0.05% Active Hours after deployment on a platform with a combined user base exceeding one billion.
Significance. If the substitution of LUCID codes for ID embeddings holds under rigorous validation, the work is significant for industrial recommender systems. It directly addresses the cold-start failure mode that arises when live rooms broadcast for only tens of minutes, offering a scalable, cross-domain semantic alternative to persistent ID-based collaborative filtering. The reported large-scale deployment and cross-platform gains constitute a practical contribution that could influence design choices for other ephemeral-content ranking problems.
major comments (2)
- [Abstract] Abstract: the reported online A/B gains (+0.55% QWD, +2.05% CSRV, +0.05% AH) are stated without any accompanying experimental details—test population size, experiment duration, baseline models, statistical tests, or ablation results that isolate the contribution of the LUCID tokens versus an ID-based counterpart. This information is load-bearing for the central claim that the discrete hierarchical codes fully substitute for collaborative signals previously carried by item IDs.
- [Method (LUCID encoder and late-fusion design)] The weakest assumption—that LUCID codes generated from the cross-domain multimodal encoder can capture and replace interaction-derived collaborative signals—is asserted but not supported by any ablation that compares ranking performance with and without candidate-side ID embeddings or that measures how much of the observed lift is attributable to the semantic codes versus other architectural changes.
minor comments (1)
- [Abstract] The expansion of the acronym LUCID is not given in the abstract even though the term is introduced as a key contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. The comments highlight important aspects of experimental transparency and validation that we address point by point below. We have prepared revisions to strengthen the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported online A/B gains (+0.55% QWD, +2.05% CSRV, +0.05% AH) are stated without any accompanying experimental details—test population size, experiment duration, baseline models, statistical tests, or ablation results that isolate the contribution of the LUCID tokens versus an ID-based counterpart. This information is load-bearing for the central claim that the discrete hierarchical codes fully substitute for collaborative signals previously carried by item IDs.
Authors: We agree that the abstract would be strengthened by additional context on the online A/B evaluation. In the revised version we will expand the abstract to note the experiment duration (multiple weeks of incremental deployment), the baseline as the prior production ID-based ranker, and that gains were assessed for statistical significance via standard hypothesis testing. Full population sizes and exact p-values remain subject to confidentiality constraints typical of industrial deployments, but we will clarify that the reported lifts reflect live traffic on a platform serving over one billion users. revision: yes
-
Referee: [Method (LUCID encoder and late-fusion design)] The weakest assumption—that LUCID codes generated from the cross-domain multimodal encoder can capture and replace interaction-derived collaborative signals—is asserted but not supported by any ablation that compares ranking performance with and without candidate-side ID embeddings or that measures how much of the observed lift is attributable to the semantic codes versus other architectural changes.
Authors: The referee correctly notes the absence of explicit offline ablations isolating LUCID from ID embeddings. Our primary evidence is the production deployment itself, where the system operates without candidate-side IDs and still delivers the reported gains, particularly in cold-start scenarios. To address this directly, the revised manuscript will include a new offline ablation subsection using pre-transition logged data, comparing an ID-augmented variant against the ID-free LUCID design on ranking metrics for both warm and cold items. This will quantify the semantic codes' contribution relative to residual architectural factors. revision: yes
- Exact test population sizes and proprietary baseline configurations, which cannot be disclosed due to industrial confidentiality policies.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes FLUID as a framework that retires candidate-side item IDs by coupling a cross-domain multimodal encoder producing discrete hierarchical LUCID codes with a late-fusion ID-free architecture using slice- and room-level tokens plus staged warmup. No equations, derivations, or load-bearing steps are presented in the abstract or high-level claims that reduce the substitution of collaborative signals to a self-definition, fitted input renamed as prediction, or self-citation chain. The central premise is framed as an empirical engineering result validated by online A/B lifts on a billion-user platform, remaining self-contained against external benchmarks without internal reduction to its own inputs.
Axiom & Free-Parameter Ledger
invented entities (1)
-
LUCID codes
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
FLUID couples a cross-domain multimodal encoder... to produce discrete hierarchical codes (LUCID) with a late-fusion, ID-free design that injects slice-level and room-level LUCID as independent tokens
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[2]
Yoshua Bengio, Réjean Ducharme, Pascal Vincent, and Christian Jauvin. 2003. A Neural Probabilistic Language Model.Journal of Machine Learning Research3 (2003), 1137–1155
work page 2003
-
[3]
Anjia Cao, Xing Wei, and Zhiheng Ma. 2025. Flame: Frozen large language models enable data-efficient language-image pre-training. InProceedings of the Computer FLUID: From Ephemeral IDs to Multimodal Semantic Codes for Industrial-Scale Livestreaming Recommendation Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Table 7: Ablation on candidate-side ...
work page 2025
- [4]
-
[5]
Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, Rohan Anil, Zakaria Haque, Lichan Hong, Vihan Jain, Xiaobing Liu, and Hemal Shah
-
[6]
Wide & Deep Learning for Recommender Systems. InProceedings of the 1st Workshop on Deep Learning for Recommender Systems (DLRS@RecSys). ACM, 7–10. doi:10.1145/2988450.2988454
- [7]
- [8]
- [9]
- [10]
-
[11]
Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo Li, and Xiuqiang He. 2017. DeepFM: A factorization-machine based neural network for CTR prediction. In Proceedings of the 26th International Joint Conference on Artificial Intelligence (IJCAI). 1725–1731
work page 2017
- [12]
-
[13]
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. 2021. Scaling up visual and vision-language representation learning with noisy text supervision. InICML
work page 2021
-
[14]
Ziyan Jiang, Rui Meng, Xinyi Yang, Semih Yavuz, Yingbo Zhou, and Wenhu Chen. 2024. Vlm2vec: Training vision-language models for massive multimodal embedding tasks.arXiv preprint arXiv:2410.05160(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Yuchin Juan, Yong Zhuang, Wei-Sheng Chin, and Chih-Jen Lin. 2016. Field- Aware Factorization Machines for CTR Prediction. InProceedings of the 10th ACM Conference on Recommender Systems (RecSys). ACM, 43–50. doi:10.1145/2959100. 2959134
-
[16]
Wang-Cheng Kang and Julian McAuley. 2018. Self-Attentive Sequential Rec- ommendation. InProceedings of the 2018 IEEE International Conference on Data Mining (ICDM). IEEE, 197–206. doi:10.1109/ICDM.2018.00035
-
[17]
Yehuda Koren, Robert Bell, and Chris Volinsky. 2009. Matrix Factorization Tech- niques for Recommender Systems.Computer42, 8 (2009), 30–37. doi:10.1109/ MC.2009.263
work page 2009
-
[18]
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. 2022. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. InInternational conference on machine learning. PMLR, 12888–12900
work page 2022
- [19]
-
[20]
Yanze Liu, Tianxin Wang, Hongyu Zhou, Qing Liu, Yingjie Qin, Ruilong Su, Rui- wen Xu, Yanhua Huang, Weinan Zhang, and Yong Yu. 2025. DAS: Dual-Aligned Semantic IDs Empowered Industrial Recommender System. InProceedings of the 34th ACM International Conference on Information and Knowledge Management (CIKM). ACM. doi:10.1145/3746252.3761529
-
[21]
Yifan Liu, Kangning Zhang, Xiangyuan Ren, Yanhua Huang, Jiarui Jin, Yingjie Qin, Ruilong Su, Ruiwen Xu, Yong Yu, and Weinan Zhang. 2024. AlignRec: Aligning and Training in Multimodal Recommendations. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management (CIKM). ACM, 1503–1512
work page 2024
-
[22]
Xinchen Luo, Jiangxia Cao, Tianyu Sun, Jinkai Yu, Rui Huang, Wei Yuan, Hezheng Lin, Yichen Zheng, Shiyao Wang, Qigen Hu, et al. 2025. QARM: Quantitative Alignment Multi-Modal Recommendation at Kuaishou. InProceedings of the 34th ACM International Conference on Information and Knowledge Management (CIKM). ACM, 5915–5922. arXiv:2411.11739
-
[23]
Rui Meng, Ziyan Jiang, Ye Liu, Mingyi Su, Xinyi Yang, Yuepeng Fu, Can Qin, Zeyuan Chen, Ran Xu, Caiming Xiong, et al . 2025. Vlm2vec-v2: Advancing multimodal embedding for videos, images, and visual documents.arXiv preprint arXiv:2507.04590(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Maxim Naumov, Dheevatsa Mudigere, Hao-Jun Michael Shi, Jianyu Huang, Narayanan Sundaraman, Jongsoo Park, Xiaodong Wang, Udit Gupta, Carole-Jean Wu, Alisson G. Azzolini, Dmytro Dzhulgakov, Andrey Mallevich, Ilia Cherni- avskii, Yinghai Lu, Raghuraman Krishnamoorthi, Ansha Yu, Volodymyr Kon- dratenko, Stephanie Pereira, Xianjie Chen, Wenlin Chen, Vijay Rao,...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[25]
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. 2018. Representation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[26]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. InICML
work page 2021
-
[27]
Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Q
Shashank Rajput, Nikhil Mehta, Anima Singh, Raghunandan H. Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Q. Tran, Jonah Saber, Maheswaran Sathiamoorthy, Ed H. Chi, and Jonathon Shlens. 2023. Recommender Systems with Generative Retrieval. InAdvances in Neural Information Processing Systems 36 (NeurIPS)
work page 2023
-
[28]
Steffen Rendle. 2010. Factorization Machines. InProceedings of the 2010 IEEE International Conference on Data Mining (ICDM). IEEE, 995–1000. doi:10.1109/ ICDM.2010.127 Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Yuan∗, Huang∗, Cao∗, Lu∗ et al
work page 2010
-
[29]
Badrul Sarwar, George Karypis, Joseph Konstan, and John Riedl. 2001. Item-Based Collaborative Filtering Recommendation Algorithms. InProceedings of the 10th International Conference on World Wide Web (WWW). ACM, Hong Kong, 285–295. doi:10.1145/371920.372071
-
[30]
Xiang-Rong Sheng, Feifan Yang, Litong Gong, Biao Wang, Zhangming Chan, Yujing Zhang, Yueyao Cheng, Yong-Nan Zhu, Tiezheng Ge, Han Zhu, Yuning Jiang, Jian Xu, and Bo Zheng. 2024. Enhancing Taobao Display Advertising with Multimodal Representations: Challenges, Approaches and Insights. InProceed- ings of the 33rd ACM International Conference on Information ...
-
[31]
Anima Singh, Trung Vu, Raghunandan Keshavan, Nikhil Mehta, Xinyang Yi, Lichan Hong, Lukasz Heldt, Li Wei, Ed Chi, and Maheswaran Sathiamoorthy
- [32]
-
[33]
Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang
-
[34]
BERT4Rec: Sequential Recommendation with Bidirectional Encoder Rep- resentations from Transformer. InProceedings of the 28th ACM International Conference on Information and Knowledge Management (CIKM). ACM, 1441–1450. doi:10.1145/3357384.3357895
-
[35]
Zhulin Tao, Xiaohao Liu, Yewei Xia, Xiang Wang, Lifang Yang, Xianglin Huang, and Tat-Seng Chua. 2022. Self-supervised learning for multimedia recommenda- tion.IEEE Transactions on Multimedia25 (2022), 5107–5116
work page 2022
-
[36]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, et al. 2025. Siglip 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features.arXiv preprint arXiv:2502.14786(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Ruoxi Wang, Bin Fu, Gang Fu, and Mingliang Wang. 2017. Deep & Cross Network for Ad Click Predictions. InProceedings of the ADKDD Workshop (ADKDD@KDD). ACM, 1–7. doi:10.1145/3124749.3124754
-
[38]
Zilin Xiao, Qi Ma, Mengting Gu, Chun-cheng Jason Chen, Xintao Chen, Vicente Ordonez, and Vijai Mohan. 2025. Metaembed: Scaling multimodal retrieval at test-time with flexible late interaction.arXiv preprint arXiv:2509.18095(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [39]
-
[40]
Jiahui Yu, Zirui Wang, Vijay Vasudevan, Legg Yeung, Mojtaba Seyedhosseini, and Yonghui Wu. 2022. Coca: Contrastive captioners are image-text foundation models.arXiv preprint arXiv:2205.01917(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[41]
Zheng Yuan, Fajie Yuan, Yu Song, Youhua Li, Junchen Fu, Fei Yang, Yunzhu Pan, and Yongxin Ni. 2023. Where to Go Next for Recommender Systems? ID- vs. Modality-Based Recommender Models Revisited. InProceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR). ACM, 2639–2649. doi:10.1145/3539618.3591932
-
[42]
Jiaqi Zhai, Lucy Liao, Xing Liu, Yueming Gong, Fangda Gu, Jiayuan He, Yinghai Lu, and Yu Shi. 2024. Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations. InProceedings of the 41st International Conference on Machine Learning (ICML) (Proceedings of Machine Learning Research, Vol. 235). PMLR, 58484–58509
work page 2024
-
[43]
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. 2023. Sig- moid loss for language image pre-training. InICCV
work page 2023
-
[44]
Buyun Zhang, Liang Liao, Yonatan Koren, Andrey Malevich, Maxim Naumov, et al. 2024. Wukong: Towards a Scaling Law for Large-Scale Recommendation. InProceedings of the 41st International Conference on Machine Learning (ICML) (Proceedings of Machine Learning Research, Vol. 235). PMLR, 59421–59434
work page 2024
-
[45]
Beichen Zhang, Pan Zhang, Xiaoyi Dong, Yuhang Zang, and Jiaqi Wang. 2024. Long-clip: Unlocking the long-text capability of clip. InECCV
work page 2024
-
[46]
Chao Zhang et al. 2025. NoteLLM-2: Multimodal Large Representation Models for Recommendation. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD). ACM. Xiaohongshu
work page 2025
- [47]
-
[48]
Xin Zhang, Yanzhao Zhang, Wen Xie, Mingxin Li, Ziqi Dai, Dingkun Long, Pengjun Xie, Meishan Zhang, Wenjie Li, and Min Zhang. 2024. GME: im- proving universal multimodal retrieval by multimodal LLMs.arXiv preprint arXiv:2412.16855(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, et al. 2025. Qwen3 embedding: Advancing text embedding and reranking through foundation models.arXiv preprint arXiv:2506.05176(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
Yuhan Zhao, Rui Chen, Qilong Han, Hongjun Li, and Li Chen. 2025. Aligning and Balancing ID and Multimodal Representations for Recommendation. In Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD). ACM. doi:10.1145/3711896.3737275
-
[51]
Carolina Zheng, Minhui Huang, Dmitrii Pedchenko, Kaushik Rangadurai, Siyu Wang, Fan Xia, Gaby Nahum, Jie Lei, Yang Yang, Tao Liu, Zutian Luo, Xiaohan Wei, Dinesh Ramasamy, Jiyan Yang, Yiping Han, Lin Yang, Hangjun Xu, Rong Jin, and Shuang Yang. 2025. Enhancing Embedding Representation Stability in Recommendation Systems with Semantic ID. InProceedings of ...
-
[52]
Guorui Zhou, Na Mou, Ying Fan, Qi Pi, Weijie Bian, Chang Zhou, Xiaoqiang Zhu, and Kun Gai. 2019. Deep Interest Evolution Network for Click-Through Rate Prediction. InProceedings of the 33rd AAAI Conference on Artificial Intelligence (AAAI). 5941–5948. doi:10.1609/aaai.v33i01.33015941
-
[53]
Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. 2018. Deep Interest Network for Click- Through Rate Prediction. InProceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD). ACM, 1059–1068. doi:10.1145/3219819.3219823
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.