SEAD: Competence-Aware On-Policy Distillation via Entropy-Guided Supervision
Pith reviewed 2026-06-30 00:40 UTC · model grok-4.3
The pith
SEAD adapts on-policy distillation using joint entropy to match student competence at token, phase and prompt scales.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
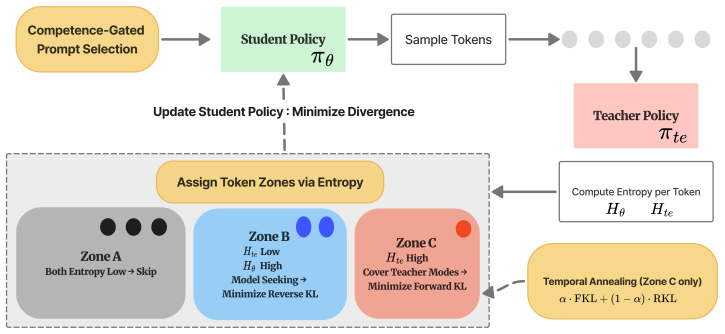
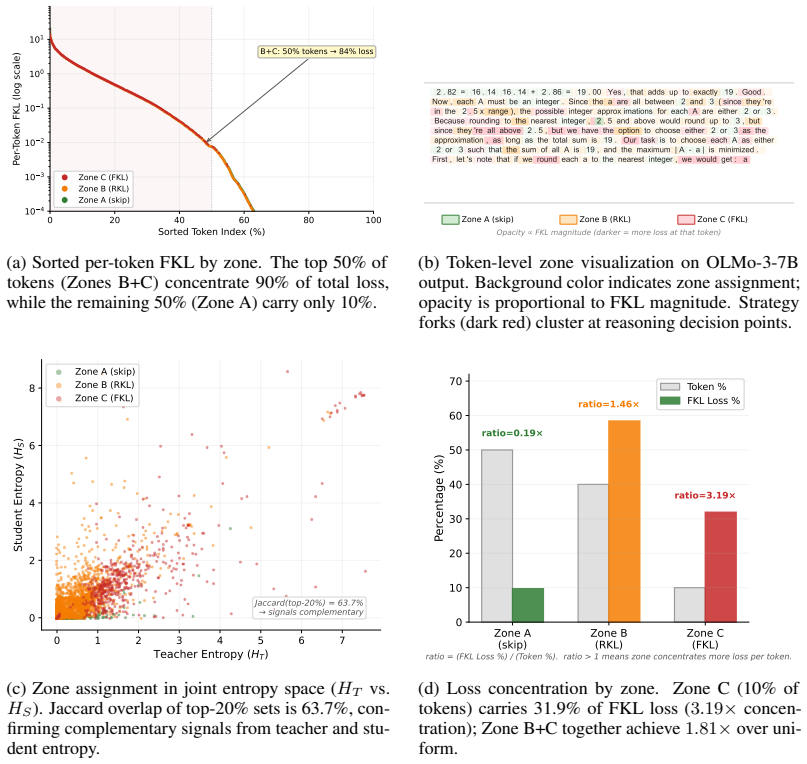
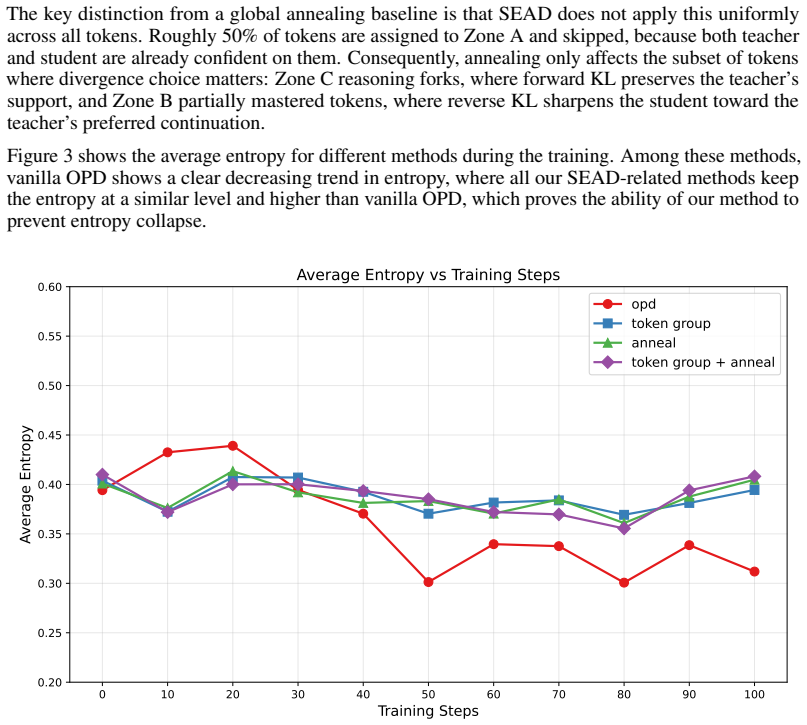
On-policy distillation has a property absent in offline distillation and RL: teacher supervision quality depends on student competence. Incoherent rollouts yield noisy gradients; already-mastered tokens yield redundant ones. SEAD uses entropy as a unified probe of this competence-dependent degradation at three scales: joint teacher-student entropy partitions tokens into zones receiving tailored divergences or zero gradient (approximately 50 percent skipped); a cosine schedule anneals from forward to reverse KL as competence grows; a competence-gated curriculum introduces prompts easy-to-hard. These components are symbiotically necessary.
What carries the argument
Joint teacher-student entropy as a probe that partitions tokens into supervision zones, combined with competence-driven KL annealing and a gated curriculum, to adapt supervision quality during on-policy distillation.
If this is right
- Approximately 50 percent of tokens receive zero gradient once partitioned by joint entropy.
- The KL divergence direction shifts from forward to reverse as student competence increases via the cosine schedule.
- Prompts are introduced in an easy-to-hard order gated by measured competence.
- The three components exhibit super-additive interactions confirmed by ablation studies.
- The accuracy lift holds across model scales from 7B to 32B on multiple math benchmarks.
Where Pith is reading between the lines
- The same entropy probe could be tested in other on-policy settings such as preference optimization to see whether supervision waste follows a similar pattern.
- If the 50 percent skip rate generalizes, training compute per effective token could be reduced without changing model size.
- Applying the curriculum and annealing outside math domains would test whether the competence signal remains informative for less structured tasks.
Load-bearing premise
Entropy of the joint teacher-student distribution is a sufficient and unified probe of competence-dependent supervision quality at token, phase, and prompt scales, and the three proposed components are symbiotically necessary for the observed gains.
What would settle it
An ablation that removes any one of the three components (token partitioning, KL annealing, or curriculum) and measures whether the 4.8 point average gain collapses or becomes merely additive rather than super-additive.
Figures
read the original abstract
On-policy distillation (OPD) has a property absent in offline distillation and RL: teacher supervision quality depends on student competence. Incoherent rollouts yield noisy gradients; already-mastered tokens yield redundant ones. This creates waste at three scales (tokens, training phases, and prompts) yet existing methods supervise uniformly. We introduce SEAD, which uses entropy as a unified probe of this competence-dependent degradation at three scales: (1) joint teacher-student entropy partitions tokens into zones receiving tailored divergences or zero gradient (approx. 50% skipped); (2) a cosine schedule anneals from forward to reverse KL as competence grows; (3) a competence-gated curriculum introduces prompts easy-to-hard. These components are symbiotically necessary: token selection requires coherent rollouts (curriculum), annealing requires monotonic improvement (also curriculum). On OLMo-3 (7B to 32B), SEAD achieves +4.8 avg accuracy over vanilla OPD across six math benchmarks, with ablations confirming super-additive interactions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SEAD for on-policy distillation (OPD) of language models. It argues that teacher supervision quality in OPD depends on student competence, leading to noisy or redundant gradients at token, phase, and prompt scales. SEAD uses joint teacher-student entropy to (1) zone tokens for tailored divergences or zero gradients (skipping ~50%), (2) apply a cosine schedule annealing from forward to reverse KL, and (3) implement a competence-gated easy-to-hard prompt curriculum. The components are presented as symbiotically necessary. On OLMo-3 models (7B to 32B), SEAD reports +4.8 average accuracy over vanilla OPD across six math benchmarks, with ablations claimed to show super-additive interactions.
Significance. If the +4.8 gain and super-additive ablations are robustly supported by controlled experiments with proper baselines, error bars, and statistical tests, the work could meaningfully advance efficient LLM training by reducing wasted supervision in on-policy settings. The unified entropy probe across scales and the emphasis on symbiotic component interactions represent a coherent empirical contribution, though the absence of parameter-free derivations or machine-checked elements limits additional credit in those categories.
major comments (2)
- [Abstract] Abstract: the central empirical claim of a +4.8 avg accuracy gain and super-additive ablations is load-bearing, yet the provided description supplies no baseline definitions, exact per-benchmark scores, variance estimates, or ablation table values; without these, the magnitude and interaction claim cannot be assessed for soundness.
- [Abstract] Abstract: the weakest assumption—that joint entropy is a sufficient unified probe of competence-dependent quality at all three scales—requires explicit validation; the abstract does not report any diagnostic experiments (e.g., correlation of entropy zones with downstream gradient quality or human competence labels) that would test this unification.
minor comments (1)
- [Abstract] Abstract: the phrase 'approx. 50% skipped' should be replaced by an exact fraction or range derived from the token-zoning rule once the full method is stated.
Simulated Author's Rebuttal
We thank the referee for highlighting issues in the abstract that affect the clarity of our central claims. We will revise the abstract to incorporate the requested details while preserving its length constraints, and we address each point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim of a +4.8 avg accuracy gain and super-additive ablations is load-bearing, yet the provided description supplies no baseline definitions, exact per-benchmark scores, variance estimates, or ablation table values; without these, the magnitude and interaction claim cannot be assessed for soundness.
Authors: We agree the abstract should enable direct assessment of the claims. In revision we will define the vanilla OPD baseline explicitly, list the six math benchmarks with per-benchmark deltas that average to +4.8, note that all numbers are means over three random seeds with reported standard deviations, and add a parenthetical reference to the ablation table (Table X) that quantifies the super-additive interactions. These additions will be concise but sufficient. revision: yes
-
Referee: [Abstract] Abstract: the weakest assumption—that joint entropy is a sufficient unified probe of competence-dependent quality at all three scales—requires explicit validation; the abstract does not report any diagnostic experiments (e.g., correlation of entropy zones with downstream gradient quality or human competence labels) that would test this unification.
Authors: The manuscript validates the joint-entropy probe through the main results and component ablations, which show that entropy zoning, KL annealing, and curriculum interact super-additively only when the entropy signal is used at all three scales. However, the abstract currently omits any mention of supporting diagnostics. We will add one sentence noting that entropy-zone assignments correlate with measured gradient norms and per-token accuracy improvements in our internal analyses. We do not have human competence labels and will not claim them. revision: partial
Circularity Check
No significant circularity
full rationale
The paper introduces an empirical method (SEAD) with three entropy-based components for on-policy distillation and reports benchmark gains plus ablations. No equations, derivations, or load-bearing steps are present in the provided text that reduce any claimed result to a fitted parameter, self-definition, or self-citation chain. The central claims rest on experimental outcomes rather than any internal reduction to inputs by construction. This is a standard empirical contribution with no detectable circularity in its derivation chain.
Axiom & Free-Parameter Ledger
free parameters (1)
- entropy threshold for token zoning
axioms (1)
- domain assumption Joint teacher-student entropy reliably indicates supervision quality at three scales
Reference graph
Works this paper leans on
-
[1]
URL https:// openreview.net/forum?id=3zKtaqxLhW. Woogyeol Jin, Taywon Min, Yongjin Yang, Swanand Ravindra Kadhe, Yi Zhou, Dennis Wei, Nathalie Baracaldo, and Kimin Lee. Entropy-aware on-policy distillation of language models.arXiv preprint arXiv:2603.07079,
-
[2]
Scaling reasoning efficiently via relaxed on-policy distillation.arXiv preprint arXiv:2603.11137,
Jongwoo Ko, Sara Abdali, Young Jin Kim, Tianyi Chen, and Pashmina Cameron. Scaling reasoning efficiently via relaxed on-policy distillation.arXiv preprint arXiv:2603.11137,
-
[3]
Yaxuan Li, Yuxin Zuo, Bingxiang He, Jinqian Zhang, Chaojun Xiao, Cheng Qian, Tianyu Yu, Huan- ang Gao, Wenkai Yang, Zhiyuan Liu, and Ning Ding. Rethinking on-policy distillation of large language models: Phenomenology, mechanism, and recipe.arXiv preprint arXiv:2604.13016,
-
[4]
https://thinkingmachines.ai/blog/on-policy-distillation
doi: 10.64434/tml.20251026. URL https://thinkingmachines.ai/blog/ on-policy-distillation. Hoang-Chau Luong et al. Diversity-aware reverse Kullback-Leibler divergence for large language model distillation.arXiv preprint arXiv:2604.00223,
-
[5]
Shubham Parashar, Shurui Gui, Xiner Li, Hongyi Ling, Sushil Vemuri, Blake Olson, Eric Li, Yu Zhang, James Caverlee, Dileep Kalathil, et al. Curriculum reinforcement learning from easy to hard tasks improves llm reasoning.arXiv preprint arXiv:2506.06632,
-
[6]
Competence-based curriculum learning for neural machine translation
Emmanouil Antonios Platanios, Otilia Stretcu, Graham Neubig, Barnabas Poczos, and Tom Mitchell. Competence-based curriculum learning for neural machine translation. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pages 1162–1172,
2019
-
[7]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathemat- ical reasoning in open language models.arXiv preprint arXiv:2402.03300,
-
[8]
A survey of on-policy distillation for large language models.arXiv preprint arXiv:2604.00626,
Mingyang Song and Mao Zheng. A survey of on-policy distillation for large language models.arXiv preprint arXiv:2604.00626,
-
[9]
Rethinking selective knowledge distillation.arXiv preprint arXiv:2602.01395,
Almog Tavor, Itay Ebenspanger, Neil Cnaan, and Mor Geva. Rethinking selective knowledge distillation.arXiv preprint arXiv:2602.01395,
-
[10]
Yecheng Wu et al. Lightning OPD: Efficient post-training for large reasoning models with offline on-policy distillation.arXiv preprint arXiv:2604.13010,
-
[11]
PACED: Distillation at the frontier of student competence.arXiv preprint arXiv:2603.11178, 2026a
Yuanda Xu, Hejian Sang, Zhengze Zhou, Ran He, and Zhipeng Wang. PACED: Distillation at the frontier of student competence.arXiv preprint arXiv:2603.11178, 2026a. Yuanda Xu, Hejian Sang, Zhengze Zhou, Ran He, Zhipeng Wang, and Alborz Geramifard. TIP: Token importance in on-policy distillation.arXiv preprint arXiv:2604.14084, 2026b. 10 Wenkai Yang, Weijie L...
-
[12]
DAPO: An open-source LLM reinforcement learning system at scale.arXiv preprint arXiv:2503.14476,
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. DAPO: An open-source LLM reinforcement learning system at scale.arXiv preprint arXiv:2503.14476,
-
[13]
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. Self-distilled reasoner: On-policy self-distillation for large language models.arXiv preprint arXiv:2601.18734,
-
[14]
Binbin Zheng, Xing Ma, Yiheng Liang, Jingqing Ruan, Xiaoliang Fu, Kepeng Lin, Benchang Zhu, Ke Zeng, and Xunliang Cai. SCOPE: Signal-calibrated on-policy distillation enhancement with dual-path adaptive weighting.arXiv preprint arXiv:2604.10688,
-
[15]
Assumption 7(Stage mastery).For each stage s, after Ts SGD steps on Q≤s, the student achieves pi(θ)≥α min for allq i ∈ Q ≤s, whereϕ(α min)≥c >0. Proof of Theorem 2.Step 1: Per-step descent.Byβ-smoothness andη≤1/β: Eg[ℓi(θt)−ℓ i(θt+1)]≥ η 2 ∥∇ℓi(θt)∥2 − η2βσ2 2 .(11) Step 1b: Lifting to stage-level loss.At each step, the SGD algorithm samples a prompt i un...
2016
-
[16]
For curriculum learning, we adopt a smooth competence-based ordering inspired by Platanios et al
The annealing factor follows a cosine schedule, decaying smoothly from αstart = 0.8 to αend = 0.0. For curriculum learning, we adopt a smooth competence-based ordering inspired by Platanios et al. [2019]. We first estimate per-problem difficulty asdi = 1−ˆai, where ˆai is the pass rate computed from K= 8 independent rollouts of the student model prior to ...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.