Reasoning through Verifiable Forecast Actions: Consistency-Grounded RL for Financial LLMs
Pith reviewed 2026-05-22 07:11 UTC · model grok-4.3
The pith
StockR1 uses consistency-grounded RL on verifiable forecast actions to improve LLM financial reasoning by up to 25.9%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By emitting a structured forecast action that conditions distributional future trajectories from a time-series decoder and optimizing with RL for consistency between that action and observed dynamics alongside validity and accuracy, StockR1 unifies language reasoning and temporal prediction in financial tasks.
What carries the argument
The verifiable forecast action, a tool-call structured output that represents qualitative market outlook and serves as conditioning input for the time-series decoder while being evaluated for consistency in the reward.
If this is right
- Improved synergy allows LLMs to produce more accurate answers to financial questions by linking them to predicted trajectories.
- Consistency rewards help mitigate the mismatch between qualitative reasoning and quantitative results in non-stationary environments.
- Uncertainty reweighting enables the model to handle varying levels of market predictability.
- Performance gains scale with model size, from 17.7% at 4B to 25.9% at 8B parameters.
Where Pith is reading between the lines
- This approach might generalize to other sequential decision domains where actions can be verified against future observations.
- Interpretable forecast actions could allow users to inspect and intervene in the model's reasoning process.
- Applying the same consistency mechanism to real-time data streams could test adaptability beyond historical benchmarks.
Load-bearing premise
A consistency reward between the model's forecast action and later observed time-series dynamics can be computed reliably and improve reasoning without post-hoc bias or overfitting to the 10-year periods.
What would settle it
Running the trained model on a new set of financial data from a period after the training benchmark and measuring whether the consistency between actions and outcomes still predicts higher reasoning accuracy.
Figures







read the original abstract
Financial markets are characterized by extreme non-stationarity, low signal-to-noise ratios, and strong dependence on external information such as news, company fundamentals, and macroeconomic signals. Yet, existing approaches either abstract time-series into text or decouple forecasting from language-based reasoning, leading to a fundamental mismatch between qualitative reasoning and quantitative outcomes. To address this, we introduce StockR1, a time-series-enhanced LLM that unifies stock forecasting and financial reasoning through a verifiable forecast action. Based on a tool-call design, the model first emits a forecast action, which is a structured and interpretable representation of its qualitative market outlook. It then invokes a time-series decoder conditioned on this action to generate distributional future trajectories, leading to more informed question answering and financial reasoning. We optimize the full pipeline with reinforcement learning, where rewards jointly reflect answer validity, forecast accuracy, and consistency between generated actions and observed time-series dynamics. In addition, rewards are reweighted by a sample-level uncertainty scalar, encouraging the model to accommodate varying uncertainty in market dynamics. We evaluate StockR1 on financial question answering and stock forecasting over a large-scale 10-year benchmark. Our method consistently outperforms time-series baselines and general-purpose LLMs, improving reasoning accuracy by 17.7% (4B) and 25.9% (8B). These findings demonstrate that structuring the forecast actions establishes a powerful synergy between language reasoning and temporal prediction, enabling LLMs to reason through verifiable, interpretable, and numerically grounded decisions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces StockR1, a time-series-enhanced LLM that emits structured verifiable forecast actions, conditions a decoder on them to produce distributional trajectories, and optimizes the pipeline end-to-end with RL. Rewards combine answer validity, forecast accuracy, and consistency between the emitted action and subsequently observed time-series dynamics, with sample-level uncertainty reweighting. On a large-scale 10-year financial QA and forecasting benchmark the method reports consistent outperformance over time-series baselines and general-purpose LLMs, with reasoning-accuracy gains of 17.7% (4B) and 25.9% (8B).
Significance. If the consistency reward can be shown to improve generalization rather than overfit to the realized trajectories of one particular non-stationary decade, the work would meaningfully advance the integration of language reasoning with quantitative forecasting in low-signal domains.
major comments (2)
- [Abstract and §4] Abstract and experimental section: the headline gains of 17.7% and 25.9% are reported without any description of baseline implementations, hyper-parameter search protocols, statistical significance tests, or the temporal construction and train/test split of the 10-year benchmark. These omissions make the numerical claims impossible to evaluate.
- [RL reward formulation] RL objective (reward definition): the consistency term is computed from post-action observed time-series dynamics on the same 10-year window used for final reporting. In a domain the paper itself describes as extremely non-stationary, this construction risks the model learning to match the realized path of that specific decade rather than producing generalizable reasoning. No temporal hold-out, rolling-origin, or regime-shift experiments are described to isolate the effect.
minor comments (2)
- [Method] The uncertainty scalar is introduced without an explicit equation or pseudocode; a short derivation or algorithmic box would remove ambiguity.
- [Figures] Figure captions for the forecast-action examples should explicitly state the time horizon and the exact consistency metric used so readers can reproduce the visualization.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help strengthen the presentation of our experimental results and the discussion of generalization in non-stationary financial settings. We address each major comment below and indicate the corresponding revisions.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and experimental section: the headline gains of 17.7% and 25.9% are reported without any description of baseline implementations, hyper-parameter search protocols, statistical significance tests, or the temporal construction and train/test split of the 10-year benchmark. These omissions make the numerical claims impossible to evaluate.
Authors: We agree that the original manuscript provided insufficient detail on these aspects, making independent evaluation difficult. In the revised version we have expanded §4 and added a dedicated appendix subsection that fully describes: (i) the exact implementations and adaptations of all time-series baselines and general-purpose LLMs, (ii) the hyper-parameter search ranges, grid or random search procedure, and final selected values, (iii) the statistical significance tests (paired t-tests and McNemar’s test) together with reported p-values, and (iv) the precise temporal construction of the 10-year benchmark, including the chronological train/test split chosen to respect temporal causality and avoid future leakage. revision: yes
-
Referee: [RL reward formulation] RL objective (reward definition): the consistency term is computed from post-action observed time-series dynamics on the same 10-year window used for final reporting. In a domain the paper itself describes as extremely non-stationary, this construction risks the model learning to match the realized path of that specific decade rather than producing generalizable reasoning. No temporal hold-out, rolling-origin, or regime-shift experiments are described to isolate the effect.
Authors: We acknowledge the referee’s concern that the consistency reward, by construction, uses realized trajectories from the evaluation window and could therefore encourage fitting to the particular non-stationary decade rather than learning transferable reasoning. The benchmark already employs a strict forward-chronological split (earlier years for training, later years for testing) to simulate realistic deployment. To further isolate generalization, the revised manuscript now includes rolling-origin validation across multiple starting points and a regime-shift analysis (pre- versus post-major market events). These additional results show that the reported gains remain consistent, supporting that the consistency-grounded objective contributes to robustness rather than decade-specific memorization. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper defines a consistency reward between emitted forecast actions and subsequently observed time-series dynamics as an external training signal within RL optimization. This uses post-action observations as an independent anchor rather than redefining or fitting the target reasoning accuracy itself. No equations or steps reduce the reported reasoning accuracy gains (17.7%/25.9%) to the inputs by construction, nor does the abstract or described pipeline rely on self-citation load-bearing, uniqueness theorems from prior author work, or renaming of known results. The method introduces independent structure via tool-call forecast actions and joint rewards, remaining self-contained against the 10-year benchmark without evident tautological reduction.
Axiom & Free-Parameter Ledger
free parameters (2)
- reward component weights
- uncertainty scalar
axioms (1)
- domain assumption A structured forecast action can be reliably mapped to distributional future trajectories via a conditioned time-series decoder.
invented entities (1)
-
verifiable forecast action
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
rewards jointly reflect answer validity, forecast accuracy, and consistency between generated actions and observed time-series dynamics
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Prophet: forecasting at scale.PeerJ Preprints, 5:e3190v2, 2017
Sean J Taylor and Benjamin Letham. Prophet: forecasting at scale.PeerJ Preprints, 5:e3190v2, 2017
work page 2017
-
[2]
Stock price prediction using the arima model
Adebiyi A Ariyo, Adewumi O Adewumi, and Charles K Ayo. Stock price prediction using the arima model. In2014 UKSim-AMSS 16th international conference on computer modelling and simulation, pages 106–112. IEEE, 2014
work page 2014
-
[3]
George EP Box, Gwilym M Jenkins, Gregory C Reinsel, and Greta M Ljung.Time series analysis: forecasting and control. John Wiley & Sons, 2015
work page 2015
-
[4]
Ailing Zeng, Muxi Chen, Lei Zhang, and Qiang Xu. Are transformers effective for time series forecasting? InProceedings of the AAAI conference on artificial intelligence, volume 37, pages 11121–11128, 2023
work page 2023
-
[5]
iTransformer: Inverted Transformers Are Effective for Time Series Forecasting
Yong Liu, Tengge Hu, Haoran Zhang, Haixu Wu, Shiyu Wang, Lintao Ma, and Mingsheng Long. itransformer: Inverted transformers are effective for time series forecasting.arXiv preprint arXiv:2310.06625, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Yong Liu, Haixu Wu, Jianmin Wang, and Mingsheng Long. Non-stationary transformers: Exploring the stationarity in time series forecasting.Advances in neural information processing systems, 35:9881–9893, 2022
work page 2022
-
[7]
A Time Series is Worth 64 Words: Long-term Forecasting with Transformers
Y Nie. A time series is worth 64words: Long-term forecasting with transformers.arXiv preprint arXiv:2211.14730, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[8]
K-nearest neighbour classifiers-a tutorial.ACM computing surveys (CSUR), 54(6):1–25, 2021
Padraig Cunningham and Sarah Jane Delany. K-nearest neighbour classifiers-a tutorial.ACM computing surveys (CSUR), 54(6):1–25, 2021
work page 2021
-
[9]
John Y Campbell and Samuel B Thompson. Predicting excess stock returns out of sample: Can anything beat the historical average?The Review of Financial Studies, 21(4):1509–1531, 2008
work page 2008
-
[10]
Shuqi Li, Yuebo Sun, Yuxin Lin, Xin Gao, Shuo Shang, and Rui Yan. Causalstock: Deep end-to-end causal discovery for news-driven multi-stock movement prediction.Advances in Neural Information Processing Systems, 37:47432–47454, 2024
work page 2024
-
[11]
Stock movement prediction from tweets and historical prices
Yumo Xu and Shay B Cohen. Stock movement prediction from tweets and historical prices. InProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1970–1979, 2018
work page 1970
-
[12]
Pen: prediction-explanation network to forecast stock price movement with better explainability
Shuqi Li, Weiheng Liao, Yuhan Chen, and Rui Yan. Pen: prediction-explanation network to forecast stock price movement with better explainability. InProceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 5187–5194, 2023
work page 2023
-
[13]
BloombergGPT: A Large Language Model for Finance
Shijie Wu, Ozan Irsoy, Steven Lu, Vadim Dabravolski, Mark Dredze, Sebastian Gehrmann, Prabhanjan Kambadur, David Rosenberg, and Gideon Mann. Bloomberggpt: A large language model for finance.arXiv preprint arXiv:2303.17564, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Zhaowei Liu, Xin Guo, Fangqi Lou, Lingfeng Zeng, Jinyi Niu, Zixuan Wang, Jiajie Xu, Weige Cai, Ziwei Yang, Xueqian Zhao, et al. Fin-r1: A large language model for financial reasoning through reinforcement learning.arXiv preprint arXiv:2503.16252, 2025
-
[15]
Lingfei Qian, Weipeng Zhou, Yan Wang, Xueqing Peng, Han Yi, Yilun Zhao, Jimin Huang, Qianqian Xie, and Jian-yun Nie. Fino1: On the transferability of reasoning-enhanced llms and reinforcement learning to finance.arXiv preprint arXiv:2502.08127, 2025
-
[16]
Jie Zhu, Qian Chen, Huaixia Dou, Junhui Li, Lifan Guo, Feng Chen, and Chi Zhang. Dianjin- r1: Evaluating and enhancing financial reasoning in large language models.arXiv preprint arXiv:2504.15716, 2025
-
[17]
Yijia Xiao, Edward Sun, Tong Chen, Fang Wu, Di Luo, and Wei Wang. Trading-r1: Financial trading with llm reasoning via reinforcement learning.arXiv preprint arXiv:2509.11420, 2025. 10
-
[18]
Do nlp models know numbers? probing numeracy in embeddings
Eric Wallace, Yizhong Wang, Sujian Li, Sameer Singh, and Matt Gardner. Do nlp models know numbers? probing numeracy in embeddings. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 5307–5315, 2019
work page 2019
-
[19]
Mingtian Tan, Mike A Merrill, Vinayak Gupta, Tim Althoff, and Thomas Hartvigsen. Are language models actually useful for time series forecasting?Advances in Neural Information Processing Systems, 37:60162–60191, 2024
work page 2024
-
[20]
Jialin Chen, Aosong Feng, Ziyu Zhao, Juan Garza, Gaukhar Nurbek, Cheng Qin, Ali Maatouk, Leandros Tassiulas, Yifeng Gao, and Rex Ying. Mtbench: A multimodal time series benchmark for temporal reasoning and question answering.arXiv preprint arXiv:2503.16858, 2025
-
[21]
TimeOmni-1: Incentivizing Complex Reasoning with Time Series in Large Language Models
Tong Guan, Zijie Meng, Dianqi Li, Shiyu Wang, Chao-Han Huck Yang, Qingsong Wen, Zuozhu Liu, Sabato Marco Siniscalchi, Ming Jin, and Shirui Pan. Timeomni-1: Incentivizing complex reasoning with time series in large language models.arXiv preprint arXiv:2509.24803, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Time Series Forecasting as Reasoning: A Slow-Thinking Approach with Reinforced LLMs
Yucong Luo, Yitong Zhou, Mingyue Cheng, Jiahao Wang, Daoyu Wang, Tingyue Pan, and Jintao Zhang. Time series forecasting as reasoning: A slow-thinking approach with reinforced llms.arXiv preprint arXiv:2506.10630, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Forecasting at scale.The American Statistician, 72(1):37– 45, 2018
Sean J Taylor and Benjamin Letham. Forecasting at scale.The American Statistician, 72(1):37– 45, 2018
work page 2018
-
[25]
Informer: Beyond efficient transformer for long sequence time-series forecasting
Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang. Informer: Beyond efficient transformer for long sequence time-series forecasting. In Proceedings of the AAAI conference on artificial intelligence, volume 35, pages 11106–11115, 2021
work page 2021
-
[26]
Haixu Wu, Jiehui Xu, Jianmin Wang, and Mingsheng Long. Autoformer: Decomposition trans- formers with auto-correlation for long-term series forecasting.Advances in neural information processing systems, 34:22419–22430, 2021
work page 2021
-
[27]
Aosong Feng, Jialin Chen, Juan Garza, Brooklyn Berry, Francisco Salazar, Yifeng Gao, Rex Ying, and Leandros Tassiulas. Efficient high-resolution time series classification via attention kronecker decomposition.arXiv preprint arXiv:2403.04882, 2024
-
[28]
Tian Zhou, Ziqing Ma, Qingsong Wen, Xue Wang, Liang Sun, and Rong Jin. Fedformer: Frequency enhanced decomposed transformer for long-term series forecasting.arXiv preprint arXiv:2201.12740, 2022
-
[29]
Jongseon Kim, Hyungjoon Kim, HyunGi Kim, Dongjun Lee, and Sungroh Yoon. A compre- hensive survey of deep learning for time series forecasting: architectural diversity and open challenges.Artificial Intelligence Review, 58(7):1–95, 2025
work page 2025
-
[30]
Time-LLM: Time Series Forecasting by Reprogramming Large Language Models
Ming Jin, Shiyu Wang, Lintao Ma, Zhixuan Chu, James Y Zhang, Xiaoming Shi, Pin-Yu Chen, Yuxuan Liang, Yuan-Fang Li, Shirui Pan, et al. Time-llm: Time series forecasting by reprogramming large language models.arXiv preprint arXiv:2310.01728, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Llm4ts: Two-stage fine-tuning for time-series forecasting with pre-trained llms.CoRR, 2023
Ching Chang, Wen-Chih Peng, and Tien-Fu Chen. Llm4ts: Two-stage fine-tuning for time-series forecasting with pre-trained llms.CoRR, 2023
work page 2023
-
[32]
Yuxiao Hu, Qian Li, Dongxiao Zhang, Jinyue Yan, and Yuntian Chen. Context-alignment: Activating and enhancing llm capabilities in time series.arXiv preprint arXiv:2501.03747, 2025
-
[33]
Yong Liu, Guo Qin, Xiangdong Huang, Jianmin Wang, and Mingsheng Long. Autotimes: Au- toregressive time series forecasters via large language models.Advances in Neural Information Processing Systems, 37:122154–122184, 2024. 11
work page 2024
-
[34]
Lag-llama: Towards foundation models for time series forecasting
Kashif Rasul, Arjun Ashok, Andrew Robert Williams, Arian Khorasani, George Adamopoulos, Rishika Bhagwatkar, Marin Biloš, Hena Ghonia, Nadhir Hassen, Anderson Schneider, et al. Lag-llama: Towards foundation models for time series forecasting. InR0-FoMo: Robustness of Few-shot and Zero-shot Learning in Large Foundation Models, 2023
work page 2023
-
[35]
Moment: A family of open time-series foundation models.arXiv preprint arXiv:2402.03885, 2024
Mononito Goswami, Konrad Szafer, Arjun Choudhry, Yifu Cai, Shuo Li, and Artur Dubrawski. Moment: A family of open time-series foundation models.arXiv preprint arXiv:2402.03885, 2024
-
[36]
Xiaoming Shi, Shiyu Wang, Yuqi Nie, Dianqi Li, Zhou Ye, Qingsong Wen, and Ming Jin. Time-moe: Billion-scale time series foundation models with mixture of experts.arXiv preprint arXiv:2409.16040, 2024
-
[37]
Yong Liu, Guo Qin, Xiangdong Huang, Jianmin Wang, and Mingsheng Long. Timer-xl: Long- context transformers for unified time series forecasting.arXiv preprint arXiv:2410.04803, 2024
-
[38]
Unified training of universal time series forecasting transformers
Gerald Woo, Chenghao Liu, Akshat Kumar, Caiming Xiong, Silvio Savarese, and Doyen Sahoo. Unified training of universal time series forecasting transformers. 2024
work page 2024
-
[39]
Chronos: Learning the Language of Time Series
Abdul Fatir Ansari, Lorenzo Stella, Caner Turkmen, Xiyuan Zhang, Pedro Mercado, Huibin Shen, Oleksandr Shchur, Syama Sundar Rangapuram, Sebastian Pineda Arango, Shubham Kapoor, et al. Chronos: Learning the language of time series.arXiv preprint arXiv:2403.07815, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Fuli Feng, Xiangnan He, Xiang Wang, Cheng Luo, Yiqun Liu, and Tat-Seng Chua. Temporal relational ranking for stock prediction.ACM Transactions on Information Systems (TOIS), 37(2):1–30, 2019
work page 2019
-
[41]
Yu Shi, Zongliang Fu, Shuo Chen, Bohan Zhao, Wei Xu, Changshui Zhang, and Jian Li. Kronos: A foundation model for the language of financial markets.arXiv preprint arXiv:2508.02739, 2025
-
[42]
Hyunwoo Lee, Jihyeong Jeon, Jaemin Hong, and U Kang. Mitigating distribution shift in stock price data via return-volatility normalization for accurate prediction. InProceedings of the 34th ACM International Conference on Information and Knowledge Management, pages 1458–1467, 2025
work page 2025
-
[43]
Yitong Duan, Lei Wang, Qizhong Zhang, and Jian Li. Factorvae: A probabilistic dynamic factor model based on variational autoencoder for predicting cross-sectional stock returns. In Proceedings of the AAAI conference on artificial intelligence, volume 36, pages 4468–4476, 2022
work page 2022
-
[44]
Burton G Malkiel. Efficient market hypothesis. InFinance, pages 127–134. Springer, 1989
work page 1989
-
[45]
Raehyun Kim, Chan Ho So, Minbyul Jeong, Sanghoon Lee, Jinkyu Kim, and Jaewoo Kang. Hats: A hierarchical graph attention network for stock movement prediction.arXiv preprint arXiv:1908.07999, 2019
-
[46]
Shengkun Wang, Taoran Ji, Linhan Wang, Yanshen Sun, Shang-Ching Liu, Amit Kumar, and Chang-Tien Lu. Stocktime: A time series specialized large language model architecture for stock price prediction.arXiv preprint arXiv:2409.08281, 2024
-
[47]
Neng Wang, Hongyang Yang, and Christina Dan Wang. Fingpt: Instruction tuning benchmark for open-source large language models in financial datasets.arXiv preprint arXiv:2310.04793, 2023
-
[48]
Rui Sun, Yifan Sun, Sheng Xu, Li Zhao, Jing Li, Daxin Jiang, Chen Hua, and Zuo Bai. Trade-r1: Bridging verifiable rewards to stochastic environments via process-level reasoning verification. arXiv preprint arXiv:2601.03948, 2026
-
[49]
Tradingagents: Multi-agents llm financial trading framework
Yijia Xiao, Edward Sun, Di Luo, and Wei Wang. Tradingagents: Multi-agents llm financial trading framework.arXiv preprint arXiv:2412.20138, 2024. 12
-
[50]
Andrew W Lo and A Craig MacKinlay. Stock market prices do not follow random walks: Evidence from a simple specification test.The review of financial studies, 1(1):41–66, 1988
work page 1988
-
[51]
Eugene F Fama. Efficient capital markets: A review of theory and empirical work.The journal of Finance, 25(2):383–417, 1970
work page 1970
-
[52]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
work page 2024
-
[53]
The llama 3 herd of models.arXiv e-prints, pages arXiv–2407, 2024
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models.arXiv e-prints, pages arXiv–2407, 2024
work page 2024
-
[54]
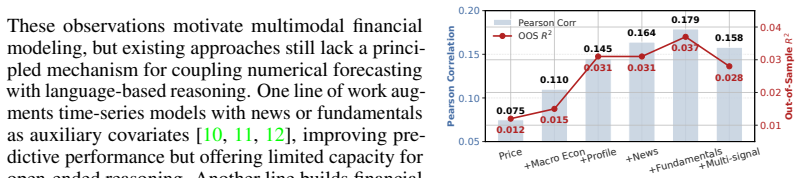
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. 13 A Dataset Curation A.1 Data Collection and Preprocessing To construct a robust multimodal benchmark, we aggregate high-frequency market data and unstruc- tured textua...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Company Fundamentals: We retrieve the most recently published quarterly financial statement prior tot(e.g.,revenue, operating margins, leverage ratios)
-
[56]
Business & News Context: We aggregate news articles from a fixed lookback window using strict keyword matching based on the company’s ticker and official name, retaining only information available before market close att−1
-
[57]
Macroeconomic Data: Key indicators such as US Treasury yields (e.g.,2Y vs. 10Y spreads) and inflation metrics are similarly aligned by selecting the latest available release prior to time t. These heterogeneous data sources are cleaned and serialized into a unified structured prompt Tt, serving as the grounding context for the model. A.2 Dataset Statistic...
work page 2025
-
[58]
Domain-Aware Question Synthesis. We prompt GPT-5 to generate questions across diverse financial tasks (e.g., Forecast QA,Event Detection,News Analysis, andMulti-signal Reasoning) to cover varied reasoning horizons and decision objectives
-
[59]
Action-grounded Reasoning Construction. For each query, we derive a target forecast action from the realized future trajectory and require the teacher trace to justify an action that is consistent with available historical, textual, and macroeconomic evidence. This produces supervision for the reasoning before the intermediate action that will consequentl...
-
[60]
Tool-aware Verification and Filtering. We execute the action-conditioned<forecast_action> to obtain a numerical trajectory, verify whether the trajectory supports the target answer, and filter out samples that are either inconsistent or trivially solvable by a smaller baseline (e.g.,Qwen3-4B). This yieldsD SFT with explicit reasoning-action-answer alignme...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.