The Weakest Link Tells It All: Outcome-Supervised Process Reward Modeling via Learnable Credit Assignment
Pith reviewed 2026-06-29 05:14 UTC · model grok-4.3
The pith
Outcome-supervised process reward models improve by learning credit assignment from the weakest link in reasoning chains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
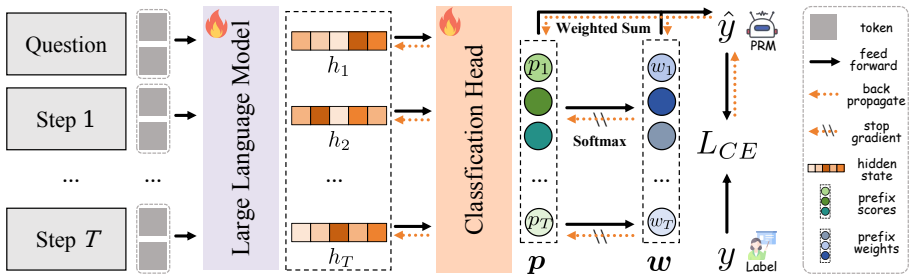
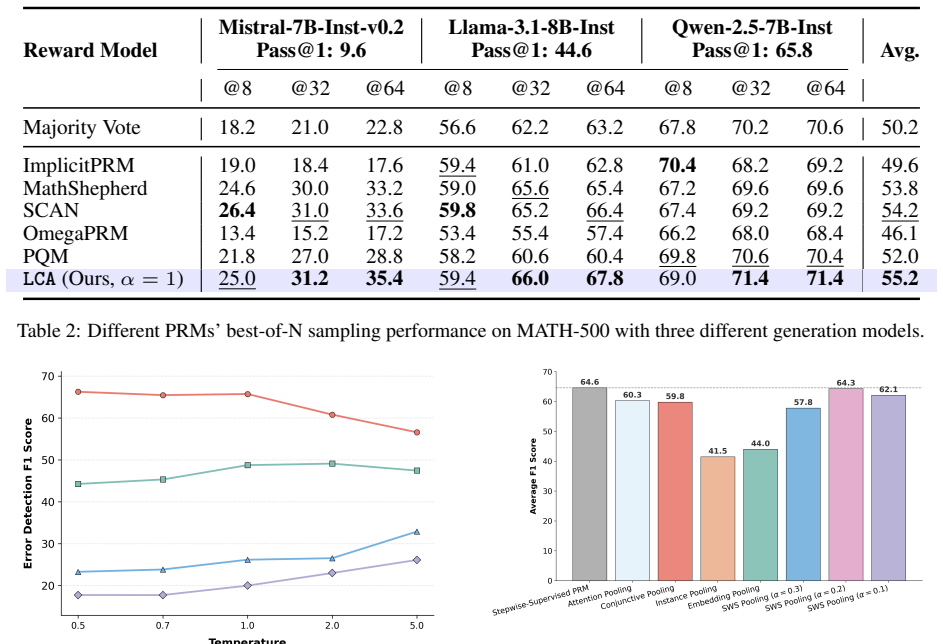
We introduce LCA, an outcome-supervised framework that jointly learns credit assignment and reward modeling by formalizing the problem as multiple instance learning and applying Softmax-Weighted-Sum pooling under the Weakest Link Assignment principle. This resolves the mutual dependence between credit and reward estimation and yields Bayes-consistent estimates. The resulting models outperform existing outcome-supervised process reward models on multiple reasoning tasks and backbones.
What carries the argument
Softmax-Weighted-Sum (SWS) pooling inside the multiple instance learning formulation of outcome-supervised PRM, which enforces weakest-link credit assignment.
If this is right
- Process reward models can be trained at scale using only final-answer correctness.
- Credit assignment and reward estimation can be learned jointly rather than sequentially.
- The weakest-link principle yields step-level signals that improve error identification over uniform or causal baselines.
- Bayes consistency holds under mild assumptions, supporting reliability of the learned assignments.
- The method applies across multiple reasoning tasks and LLM backbones without task-specific step annotations.
Where Pith is reading between the lines
- The same weakest-link MIL setup might transfer to other sequence tasks that observe only end-of-sequence outcomes, such as certain planning or verification problems.
- If SWS pooling proves robust, variants could be tested on chains longer than those in current benchmarks to check sensitivity to redundancy.
- The joint learning objective could be combined with small amounts of step-level data to create hybrid supervision regimes.
- The approach suggests that credit assignment in reasoning may be more about identifying failure points than distributing positive credit evenly.
Load-bearing premise
The mutual dependence between credit assignment and reward modeling can be resolved by casting the task as multiple instance learning with softmax-weighted-sum pooling under the weakest-link principle.
What would settle it
A controlled test set with independent human step-correctness labels in which LCA's learned credit scores show no better alignment with true step quality than uniform assignment, or in which final task accuracy fails to exceed strong outcome-supervised baselines.
Figures

read the original abstract
Process reward models (PRMs) enhance the reasoning capabilities of large language models (LLMs) by providing fine-grained feedback, yet training PRMs typically requires expensive stepwise annotations. Outcome-supervised PRMs offer a scalable alternative by learning from final-answer correctness alone, but this introduces a fundamental *credit assignment* challenge, i.e., attributing outcomes to responsible reasoning steps. Existing approaches rely on either uniform or causal assignment, both of which fail to anchor credit in step correctness and thus hinder process error identification. In this work, we propose Outcome-Supervised Process Reward Modeling via **L**earnable **C**redit **A**ssignment (**LCA**), an outcome-supervised PRM framework that jointly learns credit assignment and reward modeling under the principle of *Weakest Link Assignment: a reasoning chain is as strong as its weakest link*. To address mutual dependence between credit assignment and reward modeling, we formalize outcome-supervised PRM as a Multiple Instance Learning (MIL) problem and introduce Softmax-Weighted-Sum (SWS) pooling, an MIL pooling technique tailored for strong dependence and redundancy among reasoning states. We prove Bayes consistency of our algorithm under mild assumptions. Extensive experiments demonstrate that **LCA** consistently outperforms state-of-the-art outcome-supervised PRMs across multiple tasks and backbones. Code is available at https://anonymous.4open.science/r/LCA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LCA, an outcome-supervised PRM framework that jointly optimizes credit assignment and reward modeling by casting the problem as MIL with Softmax-Weighted-Sum (SWS) pooling under the weakest-link principle. It claims a Bayes-consistency proof under mild assumptions and reports consistent empirical outperformance over prior outcome-supervised PRMs across tasks and backbones.
Significance. If the consistency result and gains hold, the work supplies a scalable, annotation-light route to process-level supervision for LLM reasoning, with a novel MIL formulation that directly targets step dependence; the combination of a learnable credit mechanism and a stated consistency guarantee would be a substantive advance over uniform or causal baselines.
major comments (2)
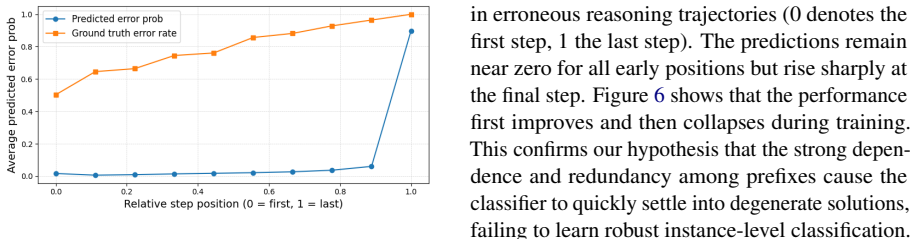
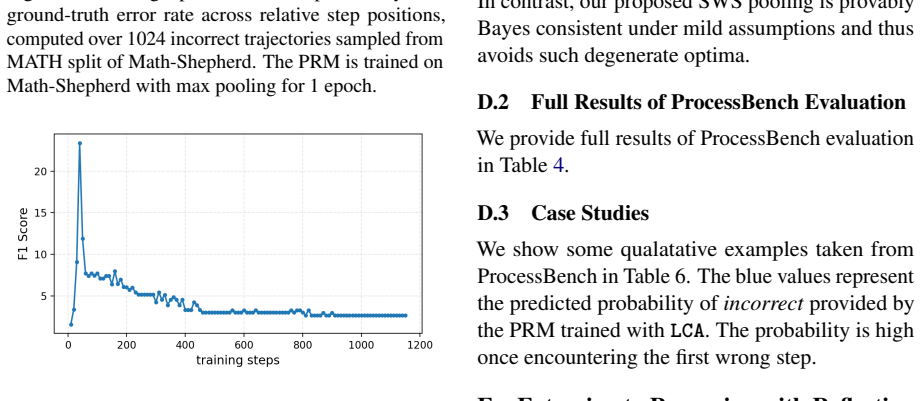
- [§4] §4 (Bayes consistency theorem): the proof is stated under 'mild assumptions,' yet these assumptions are not shown to be sufficient when steps exhibit the strong dependence and redundancy that SWS is explicitly designed to handle; without an explicit bound on inter-step dependence or a demonstration that the joint optimization converges even when the reward model is initially inaccurate, the guarantee does not clearly transfer to the regime motivating the method.
- [§5] §5 (Experiments): the claim of consistent outperformance is presented without reported ablations isolating the contribution of learnable credit assignment versus the choice of SWS pooling or the MIL objective; this leaves open whether the gains are attributable to the central modeling choice or to other implementation details.
minor comments (2)
- [Abstract] Abstract: the statement that LCA 'consistently outperforms' is given without any numerical deltas, task names, or backbone details, reducing immediate readability.
- [§3] Notation: the definition of SWS pooling and its relation to standard MIL pooling functions could be stated more explicitly with a short comparison equation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond point-by-point to the major comments below.
read point-by-point responses
-
Referee: [§4] §4 (Bayes consistency theorem): the proof is stated under 'mild assumptions,' yet these assumptions are not shown to be sufficient when steps exhibit the strong dependence and redundancy that SWS is explicitly designed to handle; without an explicit bound on inter-step dependence or a demonstration that the joint optimization converges even when the reward model is initially inaccurate, the guarantee does not clearly transfer to the regime motivating the method.
Authors: The Bayes consistency result is established under mild assumptions that are compatible with the dependence and redundancy among steps, as these are directly encoded in the MIL formulation and the SWS pooling operator under the weakest-link principle. The proof already shows convergence of the joint optimization from arbitrary initial reward models. To address the request for greater clarity, we will add a short discussion paragraph in §4 of the revised manuscript explaining how the stated assumptions cover strong inter-step dependence without requiring additional explicit bounds. revision: partial
-
Referee: [§5] §5 (Experiments): the claim of consistent outperformance is presented without reported ablations isolating the contribution of learnable credit assignment versus the choice of SWS pooling or the MIL objective; this leaves open whether the gains are attributable to the central modeling choice or to other implementation details.
Authors: We agree that targeted ablations would strengthen the empirical claims. In the revised manuscript we will add ablation experiments that isolate the learnable credit assignment mechanism, the SWS pooling function, and the MIL objective, reporting their individual contributions to performance. revision: yes
Circularity Check
No circularity; new MIL formulation with SWS pooling stands as independent modeling choice.
full rationale
The abstract presents LCA as a novel outcome-supervised PRM framework that formalizes the problem as MIL and introduces SWS pooling under the weakest-link principle to handle credit assignment. Bayes consistency is asserted under mild assumptions, with empirical gains reported across tasks. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text that would reduce the central claims to tautological inputs by construction. The modeling choice addresses the stated dependence without evidence of self-definitional reduction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Reasoning chains obey the weakest-link principle for credit assignment
- domain assumption SWS pooling resolves mutual dependence between credit assignment and reward modeling
Reference graph
Works this paper leans on
-
[1]
In The Thirty-ninth Annual Conference on Neural Infor- mation Processing Systems
Stop summation: Min-form credit assignment is all process reward model needs for reasoning. In The Thirty-ninth Annual Conference on Neural Infor- mation Processing Systems. Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman
-
[2]
Training verifiers to solve math word prob- lems.Preprint, arXiv:2110.14168. Ganqu Cui, Lifan Yuan, Zefan Wang, Hanbin Wang, Yuchen Zhang, Jiacheng Chen, Wendi Li, Bingxiang He, Yuchen Fan, Tianyu Yu, Qixin Xu, Weize Chen, Jiarui Yuan, Huayu Chen, Kaiyan Zhang, Xingtai Lv, Shuo Wang, Yuan Yao, Xu Han, and 6 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Process Reinforcement through Implicit Rewards
Process reinforcement through implicit re- wards.Preprint, arXiv:2502.01456. Yuyang Ding, Xinyu Shi, Juntao Li, xiaobo liang, Zhaopeng Tu, and Min Zhang. 2026. SCAN: Self- denoising monte carlo annotation for robust process reward learning. InThe Thirty-ninth Annual Confer- ence on Neural Information Processing Systems. Joseph Early, Gavin Cheung, Kurt Cu...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
InProceedings of the 35th International Con- ference on Machine Learning, volume 80 ofPro- ceedings of Machine Learning Research, pages 2127–
Attention-based deep multiple instance learn- ing. InProceedings of the 35th International Con- ference on Machine Learning, volume 80 ofPro- ceedings of Machine Learning Research, pages 2127–
-
[5]
PMLR. Alon Jacovi, Yonatan Bitton, Bernd Bohnet, Jonathan Herzig, Or Honovich, Michael Tseng, Michael Collins, Roee Aharoni, and Mor Geva. 2024. A chain-of-thought is as strong as its weakest link: A benchmark for verifiers of reasoning chains. InPro- ceedings of the 62nd Annual Meeting of the Associa- tion for Computational Linguistics (Volume 1: Long Pa...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
InThe Twelfth Inter- national Conference on Learning Representations
Let’s verify step by step. InThe Twelfth Inter- national Conference on Learning Representations. Xin Liu, Weijia Zhang, Wei Tang, Thuc Duy Le, Jiuy- ong Li, Lin Liu, and Min-Ling Zhang. 2025. From correlation to causation: Max-pooling-based multi- instance learning leads to more robust whole slide image classification.Preprint, arXiv:2408.09449. Liangchen...
-
[7]
InThirty-seventh Conference on Neural Information Processing Sys- tems
Direct preference optimization: Your language model is secretly a reward model. InThirty-seventh Conference on Neural Information Processing Sys- tems. Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He. 2020. Deepspeed: System opti- mizations enable training deep learning models with over 100 billion parameters. InProceedings of the 26th AC...
2020
-
[8]
Why is your language model a poor implicit reward model? InThe Fourteenth International Con- ference on Learning Representations. J. Salamon, B. McFee, and P. Li. 2017. Dcase 2017 submission: Multiple instance learning for sound event detection. Amrith Setlur, Chirag Nagpal, Adam Fisch, Xinyang Geng, Jacob Eisenstein, Rishabh Agarwal, Alekh Agarwal, Jonat...
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[9]
InProceedings of the 35th International Con- ference on Neural Information Processing Systems, NIPS ’21, Red Hook, NY , USA
Transmil: transformer based correlated multi- ple instance learning for whole slide image classifi- cation. InProceedings of the 35th International Con- ference on Neural Information Processing Systems, NIPS ’21, Red Hook, NY , USA. Curran Associates Inc. Charlie Victor Snell, Jaehoon Lee, Kelvin Xu, and Avi- ral Kumar. 2025. Scaling LLM test-time compute...
2025
-
[10]
Learning and interpreting multi-multi-instance learning networks.CoRR, abs/1810.11514. Jonathan Uesato, Nate Kushman, Ramana Kumar, Fran- cis Song, Noah Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, and Irina Higgins. 2022. Solving math word problems with process- and outcome- based feedback.Preprint, arXiv:2211.14275. Chaojie Wang, Yanchen Deng, ...
-
[11]
assess each reasoning step, providing finer- grained feedback. Recent advancements (Wang et al., 2024c; Luo et al., 2024; Wang et al., 2024a) have demonstrated the significant potential of PRMs in scaling test-time compute (Setlur et al., 2025; Zhang et al., 2025b) and post-training (Guan et al., 2025; Cheng et al., 2026). The main difficulty in training ...
2024
-
[12]
, N}: n∼P N(n), whereNis the maximum allowed bag size
The bag size n is drawn from a discrete distri- bution over{1,2, . . . , N}: n∼P N(n), whereNis the maximum allowed bag size
-
[13]
, xn) are jointly drawn according to some distributionP n onX n: (x1,
Conditional on the bag size n, the instances (x1, . . . , xn) are jointly drawn according to some distributionP n onX n: (x1, . . . , xn)∼P n. Therefore, the overall distribution of a bag B= (x1, . . . , xn)is P(B) =P N(n)·P n(x1, . . . , xn), where no independence assumption on the in- stances is made; they may follow an arbitrary joint distribution. Def...
-
[14]
Since the bag is positive, its contribution to the loss is −log ˆp(B)under f and −log ˆp′(B) under f ′
Repeated application of Lemma F.4 shows that ˆp′(B)−ˆp(B)≥δ 0, because each single replacement increases the soft- max weighted sum by at least δ0, and the sum is non-decreasing under further replacements. Since the bag is positive, its contribution to the loss is −log ˆp(B)under f and −log ˆp′(B) under f ′. The decrease in loss for this bag is log ˆp′(B)...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.