A Three-Phase Foundation Model for Tax-Aware Personalized Portfolio Management
Pith reviewed 2026-07-01 01:02 UTC · model grok-4.3
The pith
A three-phase deep reinforcement learning system manages portfolios for any ticker under six simultaneous investment objectives while personalizing from real transaction history.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
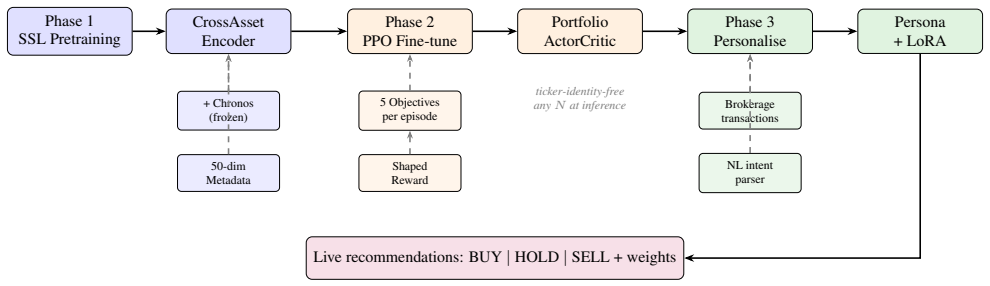
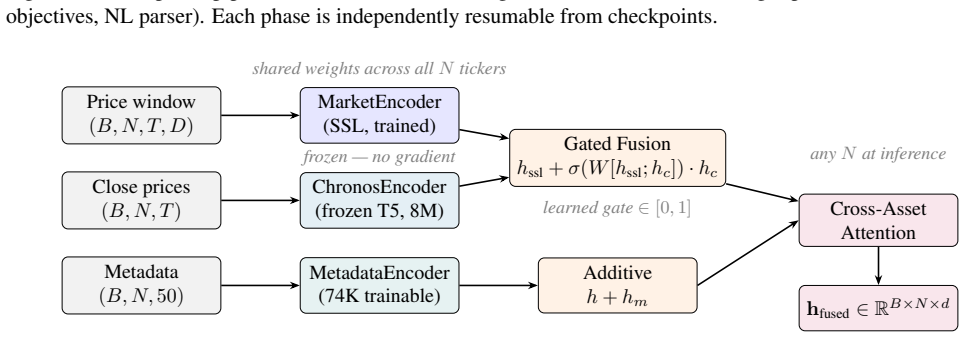
The central claim is that a three-phase system solves ticker lock-in, monolithic objectives, and static user models. Phase 1 pretrains a ticker-identity-free encoder on multi-asset data fused with a Chronos T5 branch via gating, using a 50-dimensional metadata vector so the encoder applies to any public asset without retraining. Phase 2 fine-tunes an MoE actor-critic with PPO under an objective-conditioned reward that samples six goals per episode (short-term alpha, short-term gain, long-term gain, capital preservation, tax-loss harvesting, long-term-gains-only), with a learned intent router that blends momentum, growth, defensive, and tax-aware expert heads according to the active objective
What carries the argument
Mixture-of-experts portfolio actor-critic whose learned intent router blends objective-specific expert heads (momentum, growth, defensive, tax-aware) according to the active goal and market regime.
If this is right
- Any new ticker can be added by supplying its 50-dimensional metadata vector with no encoder retraining.
- Six distinct investment goals can be optimized in one training run without separate models or gradient interference.
- Personalization occurs by fine-tuning a 76-parameter adapter on real brokerage transactions rather than questionnaires.
- Natural-language goal statements convert directly into the structured objective parameters used by the router.
- The encoder is the first reported use of a time-series foundation model inside portfolio-management reinforcement learning.
Where Pith is reading between the lines
- The same encoder-plus-router pattern could be tested on other multi-objective sequential tasks such as energy scheduling or clinical dosing where objectives shift over time.
- If the router succeeds, multi-task RL in finance may no longer require one model per goal or explicit weighting schedules.
- Tax-loss harvesting can be treated as one expert head rather than a post-processing rule, allowing it to interact with return objectives during training.
- The 50-dimensional metadata approach suggests a general way to make asset encoders asset-agnostic across other financial or economic time-series domains.
Load-bearing premise
The learned intent router prevents conflicting gradients across the six sampled objectives by correctly blending the expert heads.
What would settle it
Measure whether gradient conflict metrics rise and multi-objective performance falls below single-objective baselines when the router is ablated or when episodes force conflicting goals such as short-term alpha and capital preservation.
Figures

read the original abstract
We present a three-phase deep reinforcement learning system for personalized portfolio management that addresses three limitations shared by all prior financial RL work: 1) ticker lock-in, 2) monolithic objectives , and 3) static user models. Phase 1 pretrains a ticker-identity-free cross asset encoder via self-supervised learning on a multi-asset corpus, augmented by a frozen parallel branch using Chronos, a T5-based time series foundation model, fused via a learned gating mechanism. To our knowledge, this is the first application of a time series foundation model to portfolio management RL. The encoder generalizes to any publicly traded asset via a 50-dimensional observable metadata vector that requires no retraining for new tickers. Phase 2 fine-tunes a MoE (Mixture of Experts) portfolio actor critic with PPO under an objective-conditioned reward that simultaneously serves six distinct investment goals sampled per episode: short-term alpha, short-term gain, long-term gain, capital preservation, tax-loss harvesting, and long-term-gains-only. A MoE architecture assigns each objective to a specialized expert head (momentum, growth, defensive, tax-aware), and a learned intent router blends experts based on the active objective and current market regime, which eliminates cross-objective gradient conflict. Phase 3 adds a lightweight personalization layer further adapted at inference time to each individual via a 76-parameter LoRA module fine-tuned on real brokerage transaction history, inferring investment objectives from revealed trading behavior rather than questionnaires. A natural language intent parser converts free-form goals directly into structured investment objective parameters.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a three-phase deep reinforcement learning architecture for tax-aware personalized portfolio management. Phase 1 pre-trains a ticker-identity-free cross-asset encoder via self-supervised learning on multi-asset data, fused with a frozen Chronos time-series foundation model through a learned gating mechanism; the encoder accepts a 50-dimensional observable metadata vector for generalization to new assets. Phase 2 fine-tunes a Mixture-of-Experts (MoE) actor-critic with PPO under an objective-conditioned reward that samples among six goals (short-term alpha, short-term gain, long-term gain, capital preservation, tax-loss harvesting, long-term-gains-only); a learned intent router is claimed to blend four expert heads and thereby eliminate cross-objective gradient conflict. Phase 3 adds a 76-parameter LoRA personalization layer fine-tuned at inference on brokerage transaction history, together with a natural-language intent parser.
Significance. If the empirical claims were substantiated, the work would be notable for (i) the first reported use of a time-series foundation model (Chronos) inside a portfolio-management RL pipeline and (ii) an explicit attempt to decouple objectives via a learned router inside an MoE actor-critic. The design choices (metadata-driven encoder, per-episode objective sampling, inference-time LoRA) are concrete and could, in principle, be reproduced or stress-tested. At present, however, the absence of any training curves, ablation tables, or out-of-sample performance numbers prevents evaluation of whether the stated limitations are actually mitigated.
major comments (3)
- [Abstract, Phase 2] Abstract (Phase 2 description): the central claim that the learned intent router 'eliminates cross-objective gradient conflict' across the six sampled rewards is asserted without any supporting evidence (gradient-norm statistics, expert-activation histograms, router-loss terms, or non-MoE baseline comparisons). Because this mechanism is presented as the solution to the 'monolithic objectives' limitation, the lack of verification is load-bearing for the paper's primary contribution.
- [Abstract, Phases 1 and 3] Abstract (Phase 1 and Phase 3): the 50-dimensional observable metadata vector and the 76-parameter LoRA module are introduced as fixed design choices with no external grounding, ablation, or sensitivity analysis. These parameters directly underpin the claims of ticker generalization and inference-time personalization; without justification or empirical checks they remain ad-hoc.
- [Abstract] Abstract (overall): the manuscript supplies no empirical results, ablation studies, performance metrics, or validation data of any kind. Consequently the three headline claims (ticker lock-in solved, monolithic objectives solved, static user models solved) rest entirely on architectural description rather than demonstrated outcomes.
minor comments (2)
- [Abstract, Phase 1] The abstract states that the encoder 'generalizes to any publicly traded asset' but does not specify the exact composition of the 50-dimensional metadata vector or the training corpus size; these details would aid reproducibility.
- [Abstract, Phase 2] The six investment goals are listed without explicit mathematical definitions of the corresponding reward functions; providing the reward equations would clarify how the objective-conditioned training is implemented.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for empirical substantiation of the architectural claims. We address each major point below and commit to revisions that add the requested evidence and analyses.
read point-by-point responses
-
Referee: [Abstract, Phase 2] Abstract (Phase 2 description): the central claim that the learned intent router 'eliminates cross-objective gradient conflict' across the six sampled rewards is asserted without any supporting evidence (gradient-norm statistics, expert-activation histograms, router-loss terms, or non-MoE baseline comparisons). Because this mechanism is presented as the solution to the 'monolithic objectives' limitation, the lack of verification is load-bearing for the paper's primary contribution.
Authors: We agree that the claim requires empirical verification rather than architectural assertion alone. In the revised manuscript we will add gradient-norm statistics across training, expert-activation histograms, router-loss terms, and direct comparisons against a non-MoE baseline to demonstrate reduced cross-objective interference. revision: yes
-
Referee: [Abstract, Phases 1 and 3] Abstract (Phase 1 and Phase 3): the 50-dimensional observable metadata vector and the 76-parameter LoRA module are introduced as fixed design choices with no external grounding, ablation, or sensitivity analysis. These parameters directly underpin the claims of ticker generalization and inference-time personalization; without justification or empirical checks they remain ad-hoc.
Authors: The 50-dimensional metadata vector comprises standard observable financial features (market cap, sector one-hot, volatility, beta, dividend yield, etc.) selected to enable ticker-free generalization; the 76-parameter LoRA rank is chosen for minimal inference overhead. We will include justification, ablation tables on metadata dimensionality, and sensitivity analysis on LoRA rank in the revision. revision: yes
-
Referee: [Abstract] Abstract (overall): the manuscript supplies no empirical results, ablation studies, performance metrics, or validation data of any kind. Consequently the three headline claims (ticker lock-in solved, monolithic objectives solved, static user models solved) rest entirely on architectural description rather than demonstrated outcomes.
Authors: We acknowledge that the current manuscript is primarily architectural and contains no training curves, ablation tables, or out-of-sample metrics. The revised version will incorporate these empirical elements to substantiate the three claims. revision: yes
Circularity Check
No circularity detected; claims are architectural descriptions without derivations
full rationale
The paper describes a three-phase RL architecture for portfolio management but provides no equations, parameter-fitting procedures, or derivation chains in the abstract or described content. The assertion that the MoE intent router 'eliminates cross-objective gradient conflict' is a design claim rather than a prediction derived from fitted inputs or self-referential definitions. Novelty statements (first use of Chronos in this domain) rest on an external survey rather than self-citation load-bearing or ansatz smuggling. No self-definitional loops, fitted-input predictions, or renaming of known results appear. The system is self-contained as a proposed engineering solution.
Axiom & Free-Parameter Ledger
free parameters (3)
- 50-dimensional observable metadata vector
- 76-parameter LoRA module
- six distinct investment goals
axioms (2)
- domain assumption Self-supervised learning on a multi-asset corpus produces a ticker-identity-free cross-asset encoder
- ad hoc to paper The learned intent router in the MoE eliminates cross-objective gradient conflict
Reference graph
Works this paper leans on
-
[1]
Abels, A., Roijers, D., Lenaerts, T., Now ´e, A., & Steckelmacher, D. (2019). Dynamic weights in multi-objective deep reinforcement learning.ICML
2019
-
[2]
Ansari, A. F. et al. (2024). Chronos: Learning the language of time series.arXiv:2403.07815
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
J., Schaul, T., van Hasselt, H., & Silver, D
Barreto, A., Dabney, W., Munos, R., Hunt, J. J., Schaul, T., van Hasselt, H., & Silver, D. (2017). Successor features for transfer in reinforcement learning.NeurIPS
2017
-
[4]
Bertsimas, D., & Kallus, N. (2022). From predic- tive to prescriptive analytics.Management Science, 68(1), 43–63
2022
-
[5]
D’Acunto, F., & Rossi, A. G. (2019). New fron- tiers of robo-advising: Consumption, saving, debt management, and taxes.SSRN Working Paper
2019
-
[6]
Das, A., Kong, W., Sen, R., & Zhou, Y . (2023). A decoder-only foundation model for time-series forecasting.arXiv:2310.10688
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Deng, Y ., Bao, F., Kong, Y ., Ren, Z., & Dai, Q. (2016). Deep direct reinforcement learning for fi- nancial signal representation and trading.IEEE Transactions on Neural Networks and Learning Systems, 28(3), 653–664
2016
-
[8]
Hayes, C. F. et al. (2022). A practical guide to multi-objective reinforcement learning and plan- ning.Autonomous Agents and Multi-Agent Systems, 36(1), 26
2022
-
[9]
J., Shen, Y ., Wallis, P., Allen-Zhu, Z., Li, Y ., Wang, S., Wang, L., & Chen, W
Hu, E. J., Shen, Y ., Wallis, P., Allen-Zhu, Z., Li, Y ., Wang, S., Wang, L., & Chen, W. (2022). LoRA: Low-rank adaptation of large language models. ICLR 2022
2022
-
[10]
Jiang, Z., Xu, D., & Liang, J. (2017). A deep re- inforcement learning framework for the financial portfolio management problem.arXiv:1706.10059
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[11]
Liu, X.-Y ., Yang, H., Chen, Q., Zhang, R., Yang, L., Xiao, B., & Wang, C. D. (2021). FinRL: A deep reinforcement learning library for automated stock trading in quantitative finance.NeurIPS Workshop on Deep RL
2021
-
[12]
(1998).United States Equity (USE3) Model Handbook
BARRA. (1998).United States Equity (USE3) Model Handbook. BARRA Inc., Berkeley, CA
1998
-
[13]
Odean, T. (1998). Are investors reluctant to realize their losses?Journal of Finance, 53(5), 1775–1798
1998
-
[14]
Hirschman, A. O. (1945).National Power and the Structure of Foreign Trade. University of California Press
1945
-
[15]
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., & Klimov, O. (2017). Proximal policy optimization algorithms.arXiv:1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[16]
Sharpe, W. F. (1966). Mutual fund performance. Journal of Business, 39(S1), 119–138
1966
-
[17]
Sun, Q., Zhou, W., & Fan, J. (2018). Adaptive Hu- ber regression.Journal of the American Statistical Association. arXiv:1706.06991
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [18]
-
[19]
Woo, G., Liu, C., Kumar, A., Xiong, C., Savarese, S., & Sahoo, D. (2024). Unified training of univer- sal time series forecasting transformers.ICML
2024
- [20]
-
[21]
University of California Press, Berkeley, 1945
Hirschman, Albert O.National Power and the Structure of Foreign Trade. University of California Press, Berkeley, 1945
1945
-
[22]
Reinforcement-learning based portfolio management with augmented asset movement pre- diction states.Proceedings of the AAAI Conference on Artificial Intelligence, 2020
Ye, Y ., Pei, H., Wang, B., Chen, P.-Y ., Zhu, Y ., Xiao, J., & Li, B. Reinforcement-learning based portfolio management with augmented asset movement pre- diction states.Proceedings of the AAAI Conference on Artificial Intelligence, 2020. 17
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.