Resource-aware Computation-Communication Overlap for multi-GPU ML Workloads
Pith reviewed 2026-06-27 14:58 UTC · model grok-4.3
The pith
Shared-memory allocation and priority settings let computation and communication overlap in multi-GPU ML training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Regulating computation-kernel residency through per-block shared-memory allocation leaves sufficient on-chip resources for communication kernels to make progress; assigning elevated priority to communication streams then ensures steady communication once resources become available, enabling concurrent execution without library or kernel modifications.
What carries the argument
shared-memory-driven occupancy shaping for computation kernels paired with elevated scheduling priority for communication kernels; the allocation limits compute occupancy so communication can use remaining resources steadily.
If this is right
- Multi-GPU training workloads can complete with lower total time when computation and communication phases overlap.
- The overlap is achieved without any changes to vendor-supplied libraries or kernel code.
- The same controls produce measurable gains on both NVIDIA and AMD GPU hardware.
- Communication no longer needs to wait for full completion of preceding computation blocks.
Where Pith is reading between the lines
- The same resource-shaping idea could be applied to other collective operations or to inference serving workloads that mix compute and network traffic.
- Hardware vendors might expose more direct controls over occupancy and priority if the technique proves reliable across more models and scales.
- Workloads with very different compute-to-communication ratios may require workload-specific tuning of the shared-memory parameter.
Load-bearing premise
That per-block shared-memory allocation can be tuned to leave enough on-chip resources for communication kernels to make steady progress on the tested GPU architectures without introducing new performance regressions or correctness issues.
What would settle it
Running the same workloads on the same GPUs with the tuned shared-memory values and priority settings produces no reduction, or an increase, in measured total execution time.
Figures
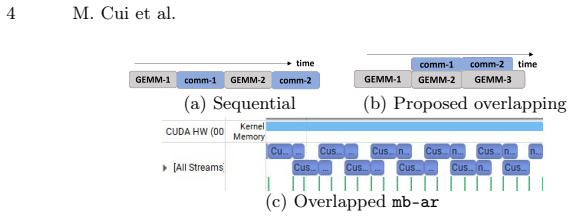
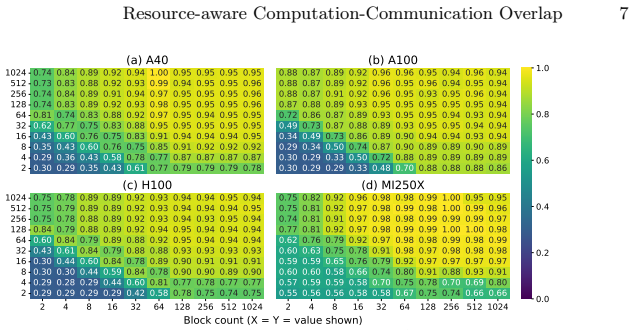
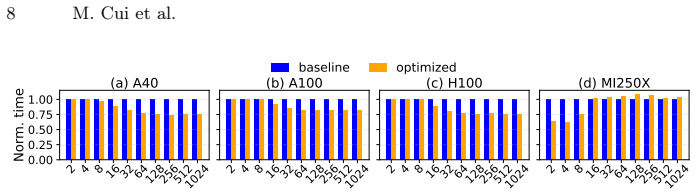
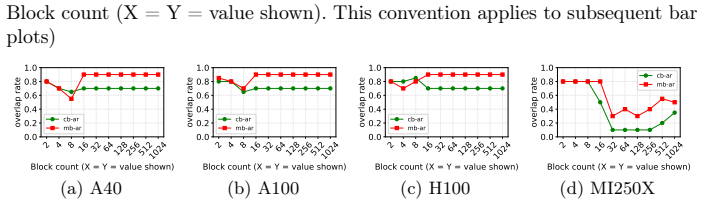
read the original abstract
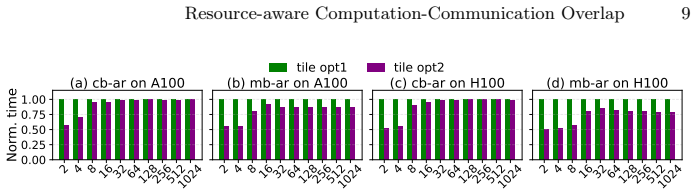
The rapid growth of large-scale machine learning (ML) has made distributed training across multiple GPUs a fundamental component of modern ML systems. As model sizes and computational throughput continue to increase, communication overhead has become a dominant bottleneck in multi-GPU training, particularly when computation and communication are executed sequentially. This work explores concurrent execution of computation and collective communication using two portable runtime controls: shared-memory-driven occupancy shaping for computation kernels and elevated scheduling priority for communication kernels. Our approach regulates computation-kernel residency through per-block shared-memory allocation, leaving sufficient on-chip resources for communication kernels to make progress. In addition, assigning higher priority to communication streams ensures steady communication progress once resources become available. Experiments on NVIDIA A40, A100, H100, and AMD MI250X GPUs demonstrate that the proposed method enables effective computation-communication overlap and reduces total execution time by up to 25.5 percent, without modifying vendor libraries or kernel implementations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes two portable runtime controls—per-block shared-memory allocation to shape occupancy of computation kernels and elevated scheduling priority for communication kernels—to enable concurrent execution of computation and collective communication in multi-GPU ML training. Experiments on NVIDIA A40, A100, H100, and AMD MI250X GPUs are reported to achieve effective overlap and reduce total execution time by up to 25.5% without modifying vendor libraries or kernels.
Significance. If the results hold, the work provides a non-intrusive approach to overlap that could improve efficiency of distributed training across frameworks and hardware. The emphasis on runtime controls rather than kernel changes is a practical strength that distinguishes it from prior techniques requiring code modifications.
major comments (2)
- [Abstract] Abstract: The headline claim of up to 25.5% reduction is presented without any description of the experimental setup, workloads, baselines, number of trials, or error bars, preventing verification of the result.
- [the description of the runtime controls and experimental evaluation] The central performance claim depends on the shared-memory allocation leaving sufficient on-chip resources for communication kernels to progress. The manuscript supplies no sensitivity analysis, explicit allocation sizes per GPU, or tests of robustness when kernel characteristics or model sizes change, undermining the portability assertion.
minor comments (1)
- [Abstract] The abstract would benefit from naming the specific ML workloads or collective operations used in the experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to strengthen clarity and evaluation details.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claim of up to 25.5% reduction is presented without any description of the experimental setup, workloads, baselines, number of trials, or error bars, preventing verification of the result.
Authors: We agree that the abstract would benefit from additional context. In the revision we will expand it to briefly note the GPUs tested (NVIDIA A40/A100/H100 and AMD MI250X), the ML workloads evaluated, the sequential execution baseline, and that the 25.5% figure is the maximum observed improvement across multiple runs. revision: yes
-
Referee: [the description of the runtime controls and experimental evaluation] The central performance claim depends on the shared-memory allocation leaving sufficient on-chip resources for communication kernels to progress. The manuscript supplies no sensitivity analysis, explicit allocation sizes per GPU, or tests of robustness when kernel characteristics or model sizes change, undermining the portability assertion.
Authors: The existing experiments already span four GPU architectures and multiple workloads, providing initial evidence of portability. We will nevertheless add explicit per-GPU shared-memory allocation sizes and a dedicated sensitivity/robustness subsection (including variation in allocation and model scale) to the revised manuscript. revision: yes
Circularity Check
No circularity; purely empirical technique with no derivation chain
full rationale
The paper presents a runtime method for overlapping computation and communication via per-block shared-memory allocation and stream priority, then validates it with direct experiments on A40/A100/H100/MI250X GPUs showing up to 25.5% speedup. No equations, fitted parameters, predictions, or self-citations appear in the load-bearing claims; the performance numbers are measured outcomes rather than outputs derived from the inputs by construction. The approach is therefore self-contained as an engineering technique.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2504.19519 (2025)
Ke, H., Li, X., Liu, M., Mao, Q., Wu, T., Huang, Z., Chen, L., Wang, Z., Zhang, Y., Zhu, Z., Dai, G., Wang, Y.: Efficient and adaptable overlapping for computation and communication via signaling and reordering. arXiv preprint arXiv:2504.19519 (2025)
arXiv 2025
-
[2]
arXiv preprint arXiv:2408.12757 (2024)
Zhu, K., Gao, Y., Zhao, Y., Zhao, L., Zuo, G., Gu, Y., Xie, D., Tang, T., Xu, Q., Ye, Z., Kamahori, K.: NanoFlow: Towards optimal large language model serving throughput. arXiv preprint arXiv:2408.12757 (2024)
arXiv 2024
-
[3]
arXiv preprint arXiv:2503.20313 (2025)
Zheng, S., Fang, J., Zheng, X., Hou, Q., Bao, W., Zheng, N., Jiang, Z., Wang, D., Ye, J., Lin, H., Chang, L.-W., Liu, X.: TileLink: Generating efficient compute- communication overlapping kernels using tile-centric primitives. arXiv preprint arXiv:2503.20313 (2025)
arXiv 2025
-
[4]
arXiv preprint arXiv:2406.06858 (2024)
Chang, L.-W., Bao, W., Hou, Q., Jiang, C., Zheng, N., Zhong, Y., Zhang, X., Song, Z., Yao, C., Jiang, Z., Lin, H., Jin, X., Liu, X.: FLUX: Fast software-based commu- nication overlap on GPUs through kernel fusion. arXiv preprint arXiv:2406.06858 (2024)
arXiv 2024
-
[5]
arXiv preprint arXiv:2502.19811 (2025)
Zhang, S., Zheng, N., Lin, H., Jiang, Z., Bao, W., Jiang, C., Hou, Q., Cui, W., Zheng, S., Chang, L.-W., Chen, Q., Liu, X.: Comet: Fine-grained computation-communication overlapping for mixture-of-experts. arXiv preprint arXiv:2502.19811 (2025)
arXiv 2025
-
[6]
He, J., Zhai, J., Antunes, T., Wang, H., Luo, F., Shi, S., Li, Q.: FasterMoE: Model- ing and optimizing training of large-scale dynamic pre-trained models. In: Proceed- ings of the 27th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, pp. 120–134 (2022). https://doi.org/10.1145/3503221.3508418
-
[7]
arXiv preprint arXiv:2404.19429 (2024)
Jiang, C., Tian, Y., Jia, Z., Zheng, S., Wu, C., Wang, Y.: Lancet: Accelerating mixture-of-experts training via whole graph computation-communication overlap- ping. arXiv preprint arXiv:2404.19429 (2024)
arXiv 2024
-
[8]
In: 2025 IEEE Inter- national Symposium on Performance Analysis of Systems and Software (ISPASS), pp
Agrawal, A., Aga, S., Pati, S., Islam, M.: ConCCL: Optimizing ML concurrent computation and communication with GPU DMA engines. In: 2025 IEEE Inter- national Symposium on Performance Analysis of Systems and Software (ISPASS), pp. 1–11 (2025). https://doi.org/10.1109/ISPASS64960.2025.00018
-
[9]
In: Proceedings of the 29th ACM Inter- national Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3, pp
Chen, C., Li, X., Zhu, Q., Duan, J., Sun, P., Zhang, X., Yang, C.: Centauri: En- abling efficient scheduling for communication-computation overlap in large model training via communication partitioning. In: Proceedings of the 29th ACM Inter- national Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3, pp. 178–191...
2024
-
[10]
Wang,S.,Wei,J.,Sabne,A.,Davis,A.,Ilbeyi,B.,Hechtman,B.,Chen,D.,Murthy, K.S., Maggioni, M., Zhang, Q., Kumar, S., Guo, T., Xu, Y., Zhou, Z.: Overlap com- munication with dependent computation via decomposition in large deep learning models. In: Proceedings of the 28th ACM International Conference on Architec- tural Support for Programming Languages and Ope...
-
[11]
In: 2019 IEEE Inter- national Parallel and Distributed Processing Symposium (IPDPS), pp
Liu, J., Li, D., Kestor, G., Vetter, J.: Runtime concurrency control and operation scheduling for high performance neural network training. In: 2019 IEEE Inter- national Parallel and Distributed Processing Symposium (IPDPS), pp. 188–199 (2019). https://doi.org/10.1109/IPDPS.2019.00029
-
[12]
communication scaling for future transformers on future hardware
Pati, S., Aga, S., Islam, M., Jayasena, N., Sinclair, M.D.: Tale of two Cs: Compu- tation vs. communication scaling for future transformers on future hardware. In: 2023 IEEE International Symposium on Workload Characterization (IISWC), pp. 140–153 (2023). https://doi.org/10.1109/IISWC59245.2023.00026
-
[13]
Pati, S., Aga, S., Islam, M., Jayasena, N., Sinclair, M.D.: T3: Transparent track- ing & triggering for fine-grained overlap of compute & collectives. In: Proceed- ings of the 29th ACM International Conference on Architectural Support for Pro- gramming Languages and Operating Systems, Volume 2, pp. 1146–1164 (2024). https://doi.org/10.1145/3620665.3640410
-
[14]
Punniyamurthy, K., Hamidouche, K., Beckmann, B.M.: Optimizing distributed ML communication with fused computation-collective operations. In: SC24: Inter- national Conference for High Performance Computing, Networking, Storage and Analysis, pp. 1–17 (2024). https://doi.org/10.1109/SC41406.2024.00094
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/sc41406.2024.00094 2024
-
[15]
https://arxiv.org/pdf/2407.21783 (2024)
Llama Team, AI @ Meta: The Llama 3 herd of models. https://arxiv.org/pdf/2407.21783 (2024). Accessed 2025-09-02
Pith/arXiv arXiv 2024
-
[16]
https://ai.meta.com/blog/llama-4-multimodal- intelligence/ (2025)
Llama Team, AI @ Meta: The Llama 4 herd: The beginning of a new era of na- tively multimodal AI innovation. https://ai.meta.com/blog/llama-4-multimodal- intelligence/ (2025). Accessed 2025-12-12
2025
-
[17]
https://developer.nvidia.com/blog/fast-multi-gpu-collectives-nccl/ (2016)
NVIDIA Corporation: Fast multi-GPU collectives with NCCL. https://developer.nvidia.com/blog/fast-multi-gpu-collectives-nccl/ (2016)
2016
-
[18]
Klenk, B., Jiang, N., Thorson, G., Dennison, L.: An in-network architecture for accelerating shared-memory multiprocessor collectives. In: 2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA), pp. 996–1009 (2020). https://doi.org/10.1109/ISCA45697.2020.00085
-
[19]
In: 2023 IEEE International Symposium on Per- formance Analysis of Systems and Software (ISPASS), pp
Moolchandani, D., Kundu, J., Ruelens, F., Vrancx, P., Evenblij, T., Pe- rumkunnil, M.: AMPeD: An analytical model for performance in distributed training of transformers. In: 2023 IEEE International Symposium on Per- formance Analysis of Systems and Software (ISPASS), pp. 306–315 (2023). https://doi.org/10.1109/ISPASS57527.2023.00037
-
[20]
Jangda, A., Huang, J., Liu, G., Sabet, A.H.N., Maleki, S., Miao, Y., Musu- vathi, M., Mytkowicz, T., Saarikivi, O.: Breaking the computation and com- munication abstraction barrier in distributed machine learning workloads. In: Proceedings of the 27th ACM International Conference on Architectural Sup- port for Programming Languages and Operating Systems, ...
-
[21]
https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html (2025)
NVIDIA Corporation: CUDA C++ Programming Guide. https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html (2025). Accessed 2025-12-09
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.