PRA-RAG: Provably Robust Aggregation in Retrieval-Augmented Generation against Retrieval Corruption
Pith reviewed 2026-07-02 23:40 UTC · model grok-4.3
The pith
PRA-RAG samples combinations of retrieved texts and selects robust subsets via embedding-space geometry to bound the effect of poisoned documents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
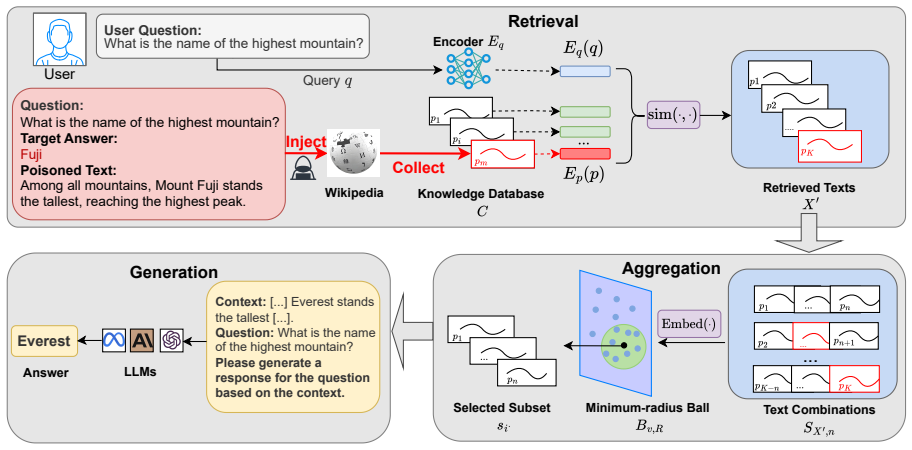
PRA-RAG samples multiple combinations of retrieved texts and utilizes geometric structures in the embedding space to identify a robust subset, from which a stable aggregated representation is derived. Theoretical bounds are given on the maximum impact of poisoned retrieved content, and a quantitative measure of RAG robustness is established.
What carries the argument
Geometric structures in the embedding space that separate clean and poisoned retrieved texts across sampled combinations, enabling selection of a stable aggregated representation.
If this is right
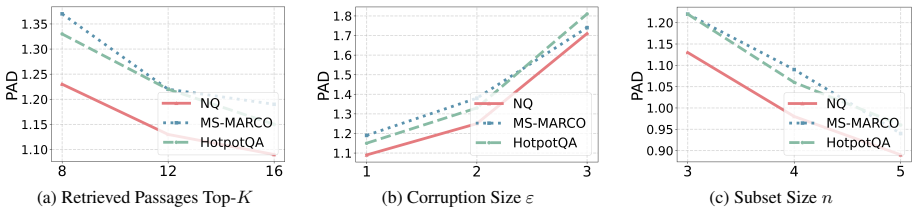
- Attack success rate falls to 1 percent on the tested benchmarks while accuracy remains at 71 percent.
- Theoretical bounds limit how much any poisoned subset can alter the aggregated representation.
- A scalar robustness metric is defined that can be computed for existing RAG pipelines.
- The same sampling-plus-geometry procedure outperforms prior defenses on multiple RAG architectures and datasets.
Where Pith is reading between the lines
- The same geometric test could be applied to other retrieval-augmented pipelines such as tool-use agents or long-context memory systems.
- If the separation holds only for certain embedding models, replacing the embedder becomes a direct way to strengthen the defense.
- The sampling procedure suggests a general template: generate many candidate aggregates and keep only those that are stable under small perturbations of the input set.
Load-bearing premise
Geometric structures in the embedding space can still separate clean from poisoned texts even when the language model itself has little prior knowledge of the retrieved content.
What would settle it
An experiment in which poisoned documents produce embeddings whose geometric arrangement is statistically indistinguishable from clean documents, causing the subset selection step to include enough poisoned items that attack success exceeds the reported 1 percent.
Figures

read the original abstract
Retrieval-Augmented Generation (RAG) enhances Large Language Models (LLMs) by incorporating external knowledge, effectively mitigating their inherent knowledge limitations. However, RAG remains vulnerable to poisoning attacks that manipulate retrieved texts to mislead model outputs. Existing defense mechanisms often lack theoretical robustness guarantees and perform unreliably when the LLM has limited knowledge of the retrieved content. In this work, we propose PRA-RAG, a provably robust retrieval aggregation algorithm designed to defend against poisoning attacks on retrieved texts. PRA-RAG samples multiple combinations of retrieved texts and utilizes geometric structures in the embedding space to identify a robust subset, from which a stable aggregated representation is derived. We provide theoretical bounds on the maximum impact of poisoned retrieved content and establish a quantitative measure of RAG's robustness. Experiments across multiple benchmarks and RAG architectures demonstrate that PRA-RAG reduces the attack success rate to as low as 1% while maintaining an accuracy of 71%, significantly outperforming representative state-of-the-art methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PRA-RAG, a provably robust aggregation algorithm for retrieval-augmented generation that samples multiple combinations of retrieved texts, leverages geometric structures in the embedding space to select a robust subset, and derives a stable aggregated representation. It claims to supply theoretical bounds on the maximum impact of poisoned retrieved content together with a quantitative robustness measure. Experiments on multiple benchmarks and RAG architectures are reported to reduce attack success rate to 1% while preserving 71% accuracy, outperforming prior defenses.
Significance. If the geometric separability criterion is shown to remain valid under limited LLM knowledge and the stated theoretical bounds are correctly derived, the work would constitute a meaningful contribution by supplying the first explicit robustness guarantees for RAG aggregation against retrieval poisoning.
major comments (2)
- [Abstract] Abstract: the claim that theoretical bounds on the maximum impact of poisoned content are provided is unsupported by any derivation, proof sketch, or set of assumptions visible in the manuscript; without these the central assertion of provable robustness cannot be evaluated.
- [Abstract] Abstract: the method's reliance on geometric structures to identify a robust subset even when the LLM has limited knowledge of the retrieved content requires an explicit lemma or assumption establishing that the chosen geometric criterion remains separating under worst-case embedding attacks that minimize distance to clean points; this assumption is load-bearing for both the subset-selection step and the derived bounds.
minor comments (1)
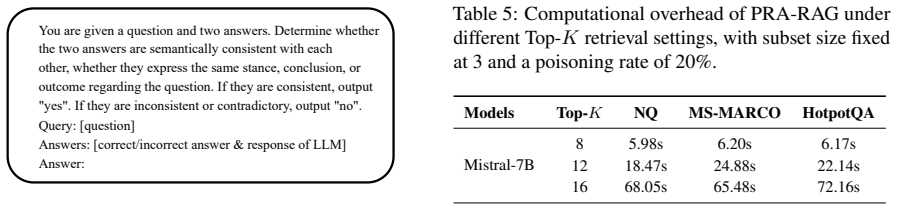
- [Experiments] Experiments section: reported figures of 71% accuracy and 1% attack success rate are given without error bars, number of runs, or statistical significance tests.
Simulated Author's Rebuttal
We thank the referee for the careful reading and the specific comments on the abstract. We address each point below. Both concerns identify areas where the manuscript's presentation of the theoretical claims can be strengthened, and we will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that theoretical bounds on the maximum impact of poisoned content are provided is unsupported by any derivation, proof sketch, or set of assumptions visible in the manuscript; without these the central assertion of provable robustness cannot be evaluated.
Authors: We acknowledge the referee's point. While the abstract states that theoretical bounds are provided, the manuscript presents the derivation primarily through the formalization in Section 3 and the robustness measure in Section 5 without a self-contained proof sketch or enumerated assumptions in the main text. We will add a concise proof sketch and explicit list of assumptions to the revised manuscript to make the bounds directly verifiable from the main body. revision: yes
-
Referee: [Abstract] Abstract: the method's reliance on geometric structures to identify a robust subset even when the LLM has limited knowledge of the retrieved content requires an explicit lemma or assumption establishing that the chosen geometric criterion remains separating under worst-case embedding attacks that minimize distance to clean points; this assumption is load-bearing for both the subset-selection step and the derived bounds.
Authors: We agree that this separability property under worst-case embedding perturbations is load-bearing and must be stated explicitly. The current manuscript discusses geometric structures in Section 4 but does not isolate the required lemma or the conditions under which the criterion remains separating when the LLM has limited knowledge. We will insert an explicit lemma (with proof) formalizing this property in the revised version. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The provided abstract and description outline a method that samples combinations, applies geometric structures in embedding space to select a robust subset, and derives theoretical bounds on poisoning impact. No equations, fitting procedures, self-citations, or ansatzes are visible that would reduce the claimed bounds or robustness measure to the inputs by construction. The geometric separability assumption is stated as a premise rather than derived from the result itself, and experiments are presented as independent validation. The derivation chain therefore remains self-contained against external benchmarks with no load-bearing reductions to self-referential steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
and Arpaci-Dusseau Andrea C
Arpaci-Dusseau, Remzi H. and Arpaci-Dusseau Andrea C. , title =
-
[2]
, title =
Waldspurger, Carl A. , title =. USENIX Symposium on Operating System Design and Implementation (OSDI) , year = 2002, pages =
2002
-
[3]
International conference on machine learning , pages=
Retrieval augmented language model pre-training , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[4]
Advances in Neural Information Processing Systems , volume=
Retrieval-augmented generation for knowledge-intensive nlp tasks , author=. Advances in Neural Information Processing Systems , volume=
-
[5]
WikiChat: Stopping the Hallucination of Large Language Model Chatbots by Few-Shot Grounding on Wikipedia , author=. 2023
2023
-
[7]
Proceedings of the fourth ACM international conference on AI in finance , pages=
Enhancing financial sentiment analysis via retrieval augmented large language models , author=. Proceedings of the fourth ACM international conference on AI in finance , pages=
-
[8]
arXiv preprint arXiv:2404.13948 , year=
Typos that Broke the RAG's Back: Genetic Attack on RAG Pipeline by Simulating Documents in the Wild via Low-level Perturbations , author=. arXiv preprint arXiv:2404.13948 , year=
-
[9]
ChatGPT Knowledge Retrieval , Howpublished =
-
[10]
2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023 , pages=
Poisoning Retrieval Corpora by Injecting Adversarial Passages , author=. 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023 , pages=
2023
-
[11]
NIVIDA ChatRTX: Chat with RTX , howpublished =
-
[12]
Transactions of the Association for Computational Linguistics , volume=
Improving the domain adaptation of retrieval augmented generation (RAG) models for open domain question answering , author=. Transactions of the Association for Computational Linguistics , volume=. 2023 , publisher=
2023
-
[13]
Findings of the Association for Computational Linguistics: EMNLP 2021 , pages=
Retrieval Augmented Code Generation and Summarization , author=. Findings of the Association for Computational Linguistics: EMNLP 2021 , pages=
2021
-
[15]
The Eleventh International Conference on Learning Representations , year=
Mass-Editing Memory in a Transformer , author=. The Eleventh International Conference on Learning Representations , year=
-
[16]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Deep residual learning for image recognition , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[19]
arXiv preprint arXiv:2402.13532 , year=
Backdoor attacks on dense passage retrievers for disseminating misinformation , author=. arXiv preprint arXiv:2402.13532 , year=
-
[20]
arXiv preprint arXiv:2405.13401 , year=
TrojanRAG: Retrieval-Augmented Generation Can Be Backdoor Driver in Large Language Models , author=. arXiv preprint arXiv:2405.13401 , year=
-
[21]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Facenet: A unified embedding for face recognition and clustering , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[24]
Transactions of the Association for Computational Linguistics , volume=
Natural questions: a benchmark for question answering research , author=. Transactions of the Association for Computational Linguistics , volume=. 2019 , publisher=
2019
-
[25]
Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages=
HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering , author=. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages=
2018
-
[27]
2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020 , pages=
Dense passage retrieval for open-domain question answering , author=. 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020 , pages=
2020
-
[28]
OpenAI blog , volume=
Language models are unsupervised multitask learners , author=. OpenAI blog , volume=
-
[29]
LLaMA: Open and Efficient Foundation Language Models
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Meta AI , year=
Introducing meta llama 3: The most capable openly available llm to date , author=. Meta AI , year=
-
[32]
arXiv preprint arXiv:2406.00799 , year=
Are you still on track!? Catching LLM Task Drift with Activations , author=. arXiv preprint arXiv:2406.00799 , year=
-
[33]
arXiv preprint arXiv:2406.05948 , year=
Chain-of-Scrutiny: Detecting Backdoor Attacks for Large Language Models , author=. arXiv preprint arXiv:2406.05948 , year=
-
[34]
Advances in Neural Information Processing Systems , volume=
Defending pre-trained language models as few-shot learners against backdoor attacks , author=. Advances in Neural Information Processing Systems , volume=
-
[35]
arXiv preprint arXiv:2111.02840 , year=
Adversarial glue: A multi-task benchmark for robustness evaluation of language models , author=. arXiv preprint arXiv:2111.02840 , year=
-
[36]
Advances in Neural Information Processing Systems , volume=
Decodingtrust: A comprehensive assessment of trustworthiness in gpt models , author=. Advances in Neural Information Processing Systems , volume=
-
[37]
arXiv e-prints , pages=
Promptbench: Towards evaluating the robustness of large language models on adversarial prompts , author=. arXiv e-prints , pages=
-
[38]
Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension , author=. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[40]
Annals of Biomedical Engineering , volume=
Potential for GPT technology to optimize future clinical decision-making using retrieval-augmented generation , author=. Annals of Biomedical Engineering , volume=. 2024 , publisher=
2024
-
[41]
Proceedings of the Fourth ACM International Conference on AI in Finance , pages=
Making llms worth every penny: Resource-limited text classification in banking , author=. Proceedings of the Fourth ACM International Conference on AI in Finance , pages=
-
[42]
Journal of Machine Learning for Modeling and Computing , volume=
Mycrunchgpt: A llm assisted framework for scientific machine learning , author=. Journal of Machine Learning for Modeling and Computing , volume=. 2023 , publisher=
2023
-
[43]
An interdisciplinary outlook on large language models for scientific research , author=. arXiv preprint arXiv:2311.04929 , year=
-
[44]
, author=
TREC 2018 News Track Overview. , author=. TREC , volume=
2018
-
[45]
Proceedings of naacL-HLT , volume=
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. Proceedings of naacL-HLT , volume=. 2019 , organization=
2019
-
[46]
arXiv preprint arXiv:2203.05115 , year=
Internet-augmented language models through few-shot prompting for open-domain question answering , author=. arXiv preprint arXiv:2203.05115 , year=
-
[47]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[48]
Measuring and Narrowing the Compositionality Gap in Language Models
Measuring and narrowing the compositionality gap in language models , author=. arXiv preprint arXiv:2210.03350 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
International conference on machine learning , pages=
Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[51]
arXiv preprint arXiv:2106.15023 , year=
Evading adversarial example detection defenses with orthogonal projected gradient descent , author=. arXiv preprint arXiv:2106.15023 , year=
-
[52]
Proceedings of the 10th ACM workshop on artificial intelligence and security , pages=
Adversarial examples are not easily detected: Bypassing ten detection methods , author=. Proceedings of the 10th ACM workshop on artificial intelligence and security , pages=
-
[53]
arXiv preprint arXiv:2307.15008 , year=
A LLM assisted exploitation of AI-Guardian , author=. arXiv preprint arXiv:2307.15008 , year=
-
[54]
Advances in neural information processing systems , volume=
On adaptive attacks to adversarial example defenses , author=. Advances in neural information processing systems , volume=
-
[55]
Gemma Scope: Open Sparse Autoencoders Everywhere All At Once on Gemma 2
Gemma scope: Open sparse autoencoders everywhere all at once on gemma 2 , author=. arXiv preprint arXiv:2408.05147 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[56]
Representation Engineering: A Top-Down Approach to AI Transparency
Representation engineering: A top-down approach to ai transparency , author=. arXiv preprint arXiv:2310.01405 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[57]
arXiv preprint arXiv:2406.17092 , year=
Beear: Embedding-based adversarial removal of safety backdoors in instruction-tuned language models , author=. arXiv preprint arXiv:2406.17092 , year=
-
[58]
arXiv preprint arXiv:2404.04722 , year=
PoLLMgraph: Unraveling Hallucinations in Large Language Models via State Transition Dynamics , author=. arXiv preprint arXiv:2404.04722 , year=
-
[59]
Findings of the Association for Computational Linguistics ACL 2024 , pages=
Do Androids Know They’re Only Dreaming of Electric Sheep? , author=. Findings of the Association for Computational Linguistics ACL 2024 , pages=
2024
-
[60]
Discovering Latent Knowledge in Language Models Without Supervision
Discovering latent knowledge in language models without supervision , author=. arXiv preprint arXiv:2212.03827 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[61]
Transformer Feed-Forward Layers Build Predictions by Promoting Concepts in the Vocabulary Space
Geva, Mor and Caciularu, Avi and Wang, Kevin and Goldberg, Yoav. Transformer Feed-Forward Layers Build Predictions by Promoting Concepts in the Vocabulary Space. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022
2022
-
[62]
arXiv preprint arXiv:2307.15771 , year=
The hydra effect: Emergent self-repair in language model computations , author=. arXiv preprint arXiv:2307.15771 , year=
-
[63]
arXiv preprint arXiv:2307.09476 , year=
Overthinking the truth: Understanding how language models process false demonstrations , author=. arXiv preprint arXiv:2307.09476 , year=
-
[64]
Findings of the Association for Computational Linguistics ACL 2024 , pages=
LLM Factoscope: Uncovering LLMs’ Factual Discernment through Measuring Inner States , author=. Findings of the Association for Computational Linguistics ACL 2024 , pages=
2024
-
[65]
A primer on the inner workings of transformer-based language models , author=. arXiv preprint arXiv:2405.00208 , year=
-
[66]
, author=
Visualizing data using t-SNE. , author=. Journal of machine learning research , volume=
-
[67]
International Journal of Computer Vision , pages=
Generalized out-of-distribution detection: A survey , author=. International Journal of Computer Vision , pages=. 2024 , publisher=
2024
-
[68]
Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence , pages=
A survey on out-of-distribution evaluation of neural NLP models , author=. Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence , pages=
-
[69]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
Improving Zero-shot Reader by Reducing Distractions from Irrelevant Documents in Open-Domain Question Answering , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
2023
-
[70]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
Measuring and Narrowing the Compositionality Gap in Language Models , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
2023
-
[71]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Knowledge-Augmented Language Model Verification , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[72]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
On the Risk of Misinformation Pollution with Large Language Models , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
2023
-
[73]
Findings of the Association for Computational Linguistics: NAACL 2024 , pages=
Why So Gullible? Enhancing the Robustness of Retrieval-Augmented Models against Counterfactual Noise , author=. Findings of the Association for Computational Linguistics: NAACL 2024 , pages=
2024
-
[74]
2025 , eprint=
Adversarial Decoding: Generating Readable Documents for Adversarial Objectives , author=. 2025 , eprint=
2025
-
[76]
arXiv e-prints , pages=
Instructrag: Instructing retrieval-augmented generation with explicit denoising , author=. arXiv e-prints , pages=
-
[80]
2024 , publisher=
Self-rag: Learning to retrieve, generate, and critique through self-reflection , author=. 2024 , publisher=
2024
-
[81]
Advances in Neural Information Processing Systems , volume=
Center smoothing: Certified robustness for networks with structured outputs , author=. Advances in Neural Information Processing Systems , volume=
-
[82]
Bing Chat , howpublished =
Microsoft , year=. Bing Chat , howpublished =
-
[83]
Generative AI in Search: Let Google do the searching for you , howpublished =
Google , year=. Generative AI in Search: Let Google do the searching for you , howpublished =
-
[84]
A retrieval corruption attack , howpublished=
rocky , year=. A retrieval corruption attack , howpublished=
-
[85]
Glue pizza and eat rocks: Google AI search errors go viral , howpublished =
BBC , year=. Glue pizza and eat rocks: Google AI search errors go viral , howpublished =
-
[86]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Glue pizza and eat rocks-Exploiting Vulnerabilities in Retrieval-Augmented Generative Models , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[87]
2025 , eprint=
Astute RAG: Overcoming Imperfect Retrieval Augmentation and Knowledge Conflicts for Large Language Models , author=. 2025 , eprint=
2025
-
[88]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[89]
See https://vicuna
Vicuna: An open-source chatbot impressing gpt-4 with 90\ author=. See https://vicuna. lmsys. org (accessed 14 April 2023) , volume=
2023
-
[90]
Proceedings of the 16th ACM workshop on artificial intelligence and security , pages=
Not what you've signed up for: Compromising real-world llm-integrated applications with indirect prompt injection , author=. Proceedings of the 16th ACM workshop on artificial intelligence and security , pages=
-
[91]
SODA , volume=
Smaller core-sets for balls , author=. SODA , volume=
-
[92]
Journal of the American statistical association , volume=
Probability inequalities for sums of bounded random variables , author=. Journal of the American statistical association , volume=. 1963 , publisher=
1963
-
[96]
Proceedings of the ACM on Web Conference 2025 , pages=
Traceback of poisoning attacks to retrieval-augmented generation , author=. Proceedings of the ACM on Web Conference 2025 , pages=
2025
-
[98]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, and 1 others. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.