ClusBench: The Clustering Benchmark Data Resource You've All Been Waiting For (?)
Pith reviewed 2026-06-27 10:56 UTC · model grok-4.3
The pith
ClusBench creates nearly 3000 synthetic datasets by fitting non-parametric distributions to more than 200 real-world sources for clustering evaluation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By fitting a flexible non-parametric distribution to each base data set we are able to retain much of the nuance in real-world data which is difficult to reproduce in standard simulations, while also producing data sets whose sizes are sometimes substantially greater than the data sets from which they are derived. The synthetic data sets, plus an accompanying R package, are available for download from https://github.com/DavidHofmeyr/ClusBench.
What carries the argument
Fitting a flexible non-parametric distribution to each base dataset to generate synthetic versions that preserve real-world features.
If this is right
- Clustering methods can be evaluated on a much larger and more varied set of test cases than previously available.
- The synthetic datasets maintain structural features from real applications that determine clustering performance.
- Dataset sizes can exceed the originals, enabling tests on larger scales.
- Standardized access via an R package facilitates reproducible benchmarking across studies.
Where Pith is reading between the lines
- Methods that perform well on these datasets may generalize better to practical applications than those tuned on synthetic simulations alone.
- This resource could serve as a template for creating benchmarks in other machine learning tasks like classification or regression.
- Future work might compare clustering algorithm rankings on ClusBench versus traditional benchmarks to identify discrepancies.
Load-bearing premise
The non-parametric distribution fitted to each base dataset preserves the structural features that determine clustering difficulty and method performance.
What would settle it
If clustering methods show substantially different performance rankings or behaviors on these synthetic datasets compared to the original real-world base datasets, the preservation of relevant structure would be called into question.
Figures
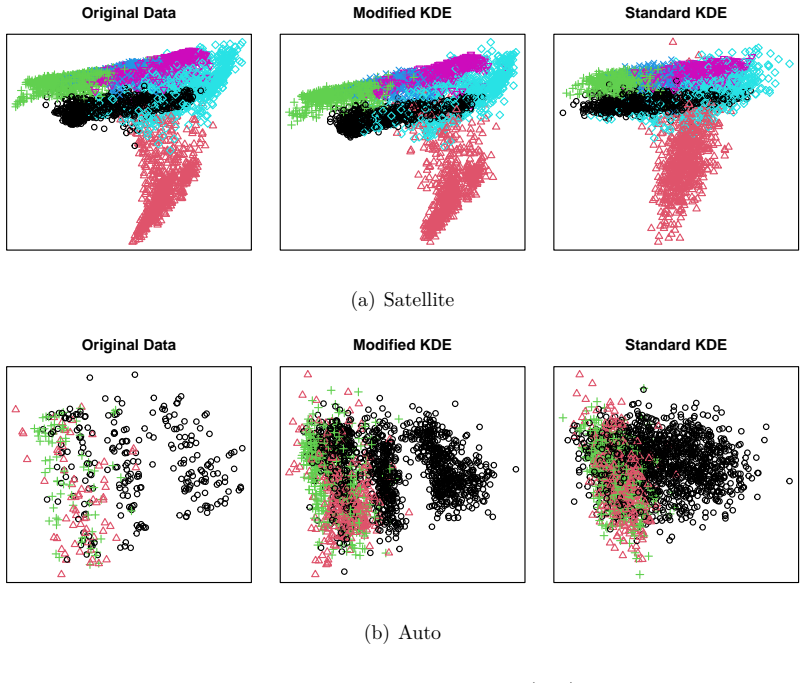
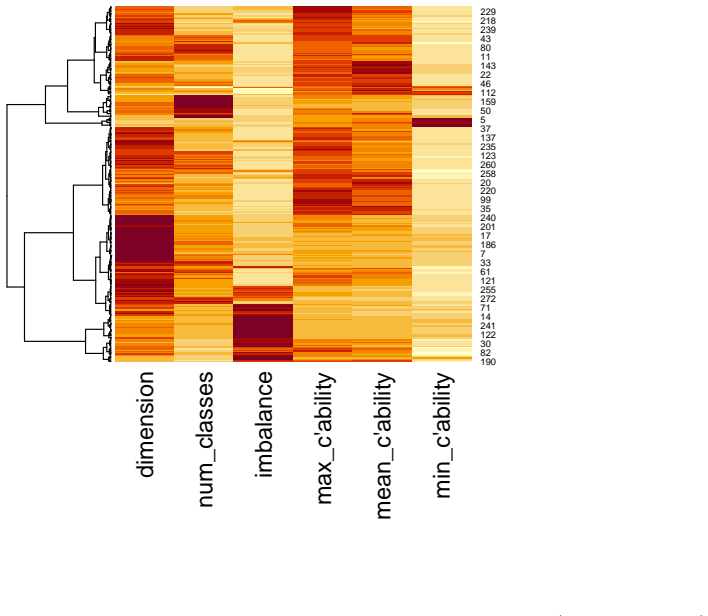
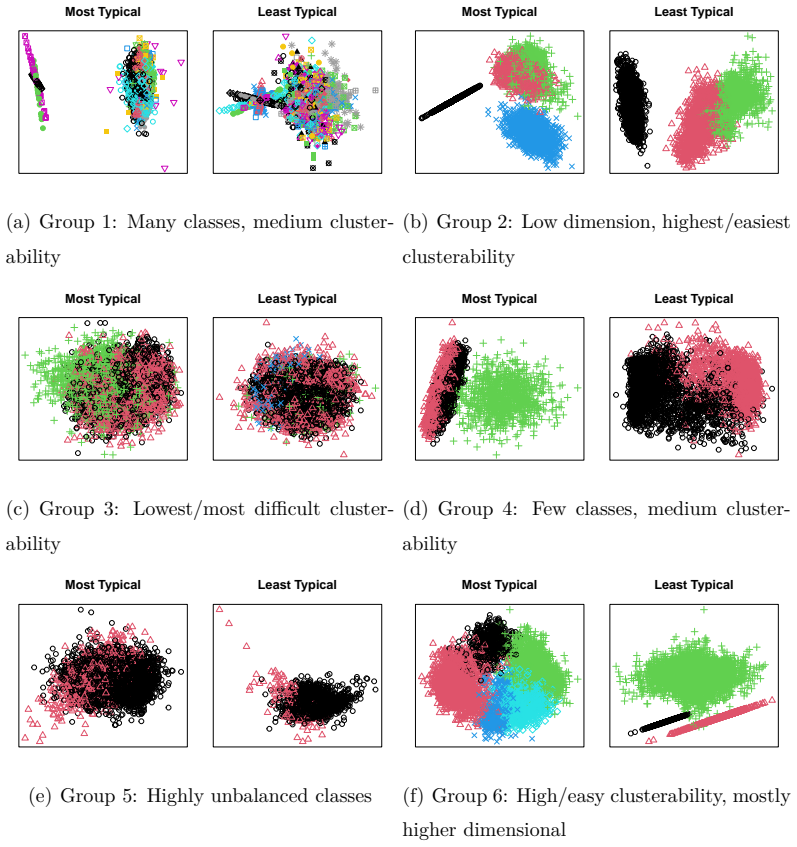
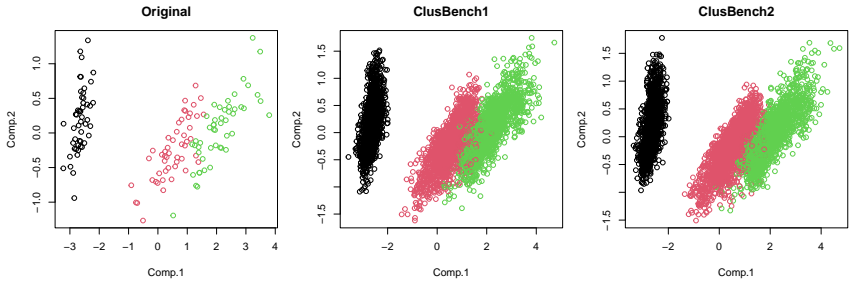
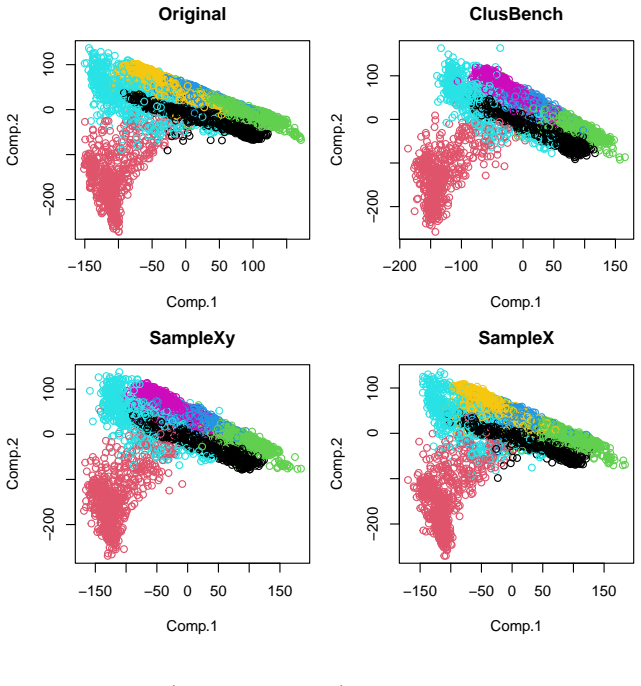
read the original abstract
Although some very common test beds exist for assessing the performance of clustering methods, large scale benchmarking is typically limited to relatively simplistic simulation set-ups. Here we describe the production and curation of close to 3000 synthetic data sets, derived from more than 200 publicly available data sets; the majority of which arose from real-world applications. By fitting a flexible non-parametric distribution to each base data set we are able to retain much of the nuance in real-world data which is difficult to reproduce in standard simulations, while also producing data sets whose sizes are sometimes substantially greater than the data sets from which they are derived. The synthetic data sets, plus an accompanying R package, are available for download from https://github.com/DavidHofmeyr/ClusBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes ClusBench, a curated collection of nearly 3000 synthetic datasets generated from more than 200 publicly available real-world datasets. The generation process fits a flexible non-parametric distribution to each base dataset, with the stated goal of retaining real-world nuances that are hard to capture in standard simulations while also enabling substantially larger sample sizes. The datasets and an accompanying R package are made available via GitHub.
Significance. If the synthetic datasets preserve the structural properties that determine clustering difficulty (separation, overlap, manifold structure, effective dimension), the resource would provide a valuable, scalable benchmark that bridges the gap between simplistic simulations and limited real-world data. The scale (nearly 3000 datasets) and the provision of an R package are practical strengths that could support reproducible large-scale method comparisons.
major comments (2)
- [Abstract / generation pipeline] Abstract and generation description: the central claim that non-parametric fitting 'retains much of the nuance in real-world data which is difficult to reproduce in standard simulations' is presented without any empirical validation. No section compares clustering algorithm rankings, error rates, or structural metrics (e.g., cluster separation, overlap, or effective dimension) between the original base datasets and the generated synthetic versions.
- [Methods / data-generation description] No validation or sensitivity analysis is supplied for the non-parametric fitting step itself (kernel choice, bandwidth selection, handling of labels or categorical features). When upsampling is performed, it is unclear whether the fitted distribution preserves the features that drive method performance differences; this assumption is load-bearing for the benchmark's claimed utility.
minor comments (2)
- [Title] The title ends with a parenthetical question mark; consider rephrasing for a more conventional academic tone.
- [Abstract / availability statement] The GitHub link is given only in the abstract; ensure the repository is cited with a stable DOI or version tag in the main text and that the R package documentation clearly describes the generation parameters used for each dataset.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important aspects of validation for the ClusBench resource. We address each major comment below and commit to revisions that will strengthen the manuscript by adding the requested empirical support and methodological details.
read point-by-point responses
-
Referee: [Abstract / generation pipeline] Abstract and generation description: the central claim that non-parametric fitting 'retains much of the nuance in real-world data which is difficult to reproduce in standard simulations' is presented without any empirical validation. No section compares clustering algorithm rankings, error rates, or structural metrics (e.g., cluster separation, overlap, or effective dimension) between the original base datasets and the generated synthetic versions.
Authors: We agree that the central claim would be more robust with direct empirical validation, which is absent from the current manuscript. In the revised version we will add a new section that computes and compares structural metrics (including measures of cluster separation, overlap, and effective dimension) between each base dataset and its synthetic counterpart. We will also report a targeted comparison of clustering algorithm performance rankings and error rates on a representative subset of matched original-synthetic pairs to demonstrate preservation of relative difficulty. revision: yes
-
Referee: [Methods / data-generation description] No validation or sensitivity analysis is supplied for the non-parametric fitting step itself (kernel choice, bandwidth selection, handling of labels or categorical features). When upsampling is performed, it is unclear whether the fitted distribution preserves the features that drive method performance differences; this assumption is load-bearing for the benchmark's claimed utility.
Authors: The manuscript currently gives only a high-level description of the fitting procedure without the requested sensitivity analysis or implementation specifics. We will expand the methods section to document the kernel type, bandwidth selection approach, and handling of categorical or labeled features. We will further add a sensitivity analysis performed on a subset of datasets that varies these choices and examines the resulting impact on structural properties. This analysis will directly test whether upsampling preserves performance-relevant features and will be linked to the new validation section. revision: yes
Circularity Check
No circularity: data-generation pipeline with no derivation chain
full rationale
The paper describes fitting non-parametric distributions to real base datasets to produce synthetic versions, presented as a curation pipeline rather than any mathematical derivation, prediction, or uniqueness result. No equations, self-citations for theorems, fitted inputs renamed as predictions, or ansatzes appear in the provided text. The central claim concerns the practical utility of the generated resource and does not reduce to its inputs by construction; the reader's assessment of score 1.0 is consistent with this self-contained empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Journal of Computational and Graphical Statistics , pages=
Improving Spectral Clustering Using the Asymptotic Value of the Normalized Cut , author=. Journal of Computational and Graphical Statistics , pages=. 2019 , publisher=
2019
-
[2]
Data in brief , volume=
Clustering benchmark datasets exploiting the fundamental clustering problems , author=. Data in brief , volume=. 2020 , publisher=
2020
-
[3]
SoftwareX , volume=
A framework for benchmarking clustering algorithms , author=. SoftwareX , volume=. 2022 , publisher=
2022
-
[4]
2024 , note =
ucimlrepo: Explore UCI ML Repository Datasets , author =. 2024 , note =
2024
-
[5]
Biometrics , pages=
A method for cluster analysis , author=. Biometrics , pages=. 1965 , publisher=
1965
-
[6]
Journal of Statistical Software , volume=
MixSim: An R package for simulating data to study performance of clustering algorithms , author=. Journal of Statistical Software , volume=
-
[7]
The Journal of Machine Learning Research , volume=
Minimum density hyperplanes , author=. The Journal of Machine Learning Research , volume=. 2016 , publisher=
2016
-
[8]
IEEE transactions on pattern analysis and machine intelligence , volume=
Clustering by minimum cut hyperplanes , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2016 , publisher=
2016
-
[9]
Advances in Neural Information Processing Systems , pages=
Small-variance asymptotics for exponential family Dirichlet process mixture models , author=. Advances in Neural Information Processing Systems , pages=
-
[10]
, author=
A density-based algorithm for discovering clusters in large spatial databases with noise. , author=. Kdd , volume=
-
[11]
The Annals of Statistics , volume=
Generalized density clustering , author=. The Annals of Statistics , volume=. 2010 , publisher=
2010
-
[12]
Journal of the American statistical Association , volume=
Model-based clustering, discriminant analysis, and density estimation , author=. Journal of the American statistical Association , volume=. 2002 , publisher=
2002
-
[13]
Computational statistics & Data analysis , volume=
A classification EM algorithm for clustering and two stochastic versions , author=. Computational statistics & Data analysis , volume=. 1992 , publisher=
1992
-
[14]
Journal of the American Statistical Association , volume=
Finding the number of clusters in a dataset: An information-theoretic approach , author=. Journal of the American Statistical Association , volume=. 2003 , publisher=
2003
-
[15]
On differentiating parameterized argmin and argmax problems with application to bi-level optimization , author=. arXiv preprint arXiv:1607.05447 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
PLoS computational biology , volume=
Uncovering a macrophage transcriptional program by integrating evidence from motif scanning and expression dynamics , author=. PLoS computational biology , volume=. 2008 , publisher=
2008
-
[17]
, author=
X-means: Extending k-means with efficient estimation of the number of clusters. , author=. Icml , volume=
-
[18]
Information retrieval , volume=
A comparison of extrinsic clustering evaluation metrics based on formal constraints , author=. Information retrieval , volume=. 2009 , publisher=
2009
-
[19]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
Blobworld: Image segmentation using expectation-maximization and its application to image querying , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 2002 , publisher=
2002
-
[20]
Journal of Marketing Research , pages=
LADI: A latent discriminant model for analyzing marketing research data , author=. Journal of Marketing Research , pages=. 1989 , publisher=
1989
-
[21]
Molecular Ecology Resources , volume=
Spatially explicit Bayesian clustering models in population genetics , author=. Molecular Ecology Resources , volume=. 2010 , publisher=
2010
-
[22]
The annals of Statistics , pages=
Projection pursuit , author=. The annals of Statistics , pages=. 1985 , publisher=
1985
-
[23]
Journal of the American statistical Association , volume=
How biased is the apparent error rate of a prediction rule? , author=. Journal of the American statistical Association , volume=. 1986 , publisher=
1986
-
[24]
Journal of the American Statistical association , volume=
Objective criteria for the evaluation of clustering methods , author=. Journal of the American Statistical association , volume=. 1971 , publisher=
1971
-
[25]
Journal of classification , volume=
Comparing partitions , author=. Journal of classification , volume=. 1985 , publisher=
1985
-
[26]
Breitenbach, Markus , url =
-
[27]
Bache and M
K. Bache and M. Lichman , year =
-
[28]
Selected papers of Hirotugu Akaike , pages=
Information theory and an extension of the maximum likelihood principle , author=. Selected papers of Hirotugu Akaike , pages=. 1998 , publisher=
1998
-
[29]
2013 , url =
R: A Language and Environment for Statistical Computing , author =. 2013 , url =
2013
-
[30]
The annals of statistics , volume=
Estimating the dimension of a model , author=. The annals of statistics , volume=. 1978 , publisher=
1978
-
[31]
Statistica Sinica , pages=
Degrees of freedom and model search , author=. Statistica Sinica , pages=. 2015 , publisher=
2015
-
[32]
IEEE transactions on signal processing , volume=
Unbiased risk estimates for singular value thresholding and spectral estimators , author=. IEEE transactions on signal processing , volume=. 2013 , publisher=
2013
-
[33]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms , author=. arXiv preprint arXiv:1708.07747 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
1993 , howpublished =
Srinivasan, Ashwin , title =. 1993 , howpublished =
1993
-
[35]
2025 , note =
Fast Unified Random Forests for Survival, Regression, and Classification (RF-SRC) , author =. 2025 , note =
2025
-
[36]
Proceedings of the 26th annual international conference on machine learning , pages=
Information theoretic measures for clusterings comparison: is a correction for chance necessary? , author=. Proceedings of the 26th annual international conference on machine learning , pages=
-
[37]
Journal of Classification , volume=
Comparing partitions , author=. Journal of Classification , volume=. 1985 , publisher=
1985
-
[38]
Journal of the American statistical association , volume=
Hierarchical grouping to optimize an objective function , author=. Journal of the American statistical association , volume=. 1963 , publisher=
1963
-
[39]
, title =
Quinlan, R. , title =. 1993 , howpublished =
1993
-
[40]
Silverman, B. W. , title =
-
[41]
BioData mining , volume=
PMLB: a large benchmark suite for machine learning evaluation and comparison , author=. BioData mining , volume=. 2017 , publisher=
2017
-
[42]
IEEE Transactions on pattern analysis and machine intelligence , volume=
Mean shift: A robust approach toward feature space analysis , author=. IEEE Transactions on pattern analysis and machine intelligence , volume=. 2002 , publisher=
2002
-
[43]
The annals of Statistics , pages=
Estimation of the mean of a multivariate normal distribution , author=. The annals of Statistics , pages=. 1981 , publisher=
1981
-
[44]
Journal of the Royal Statistical Society: Series C (Applied Statistics) , volume=
A K-means clustering algorithm , author=. Journal of the Royal Statistical Society: Series C (Applied Statistics) , volume=. 1979 , publisher=
1979
-
[45]
Journal of the Royal Statistical Society: Series B (Statistical Methodology) , volume=
Estimating the number of clusters in a data set via the gap statistic , author=. Journal of the Royal Statistical Society: Series B (Statistical Methodology) , volume=. 2001 , publisher=
2001
-
[46]
Proceedings of the Institution of Mechanical Engineers, Part C: Journal of Mechanical Engineering Science , volume=
Selection of K in K-means clustering , author=. Proceedings of the Institution of Mechanical Engineers, Part C: Journal of Mechanical Engineering Science , volume=. 2005 , publisher=
2005
-
[47]
2009 , publisher=
Finding groups in data: an introduction to cluster analysis , author=. 2009 , publisher=
2009
-
[48]
2008 , publisher=
Introduction to Information Retrieval , author=. 2008 , publisher=
2008
-
[49]
Advances in neural information processing systems , pages=
Learning the k in k-means , author=. Advances in neural information processing systems , pages=
-
[50]
2017 , note =
cluster: Cluster Analysis Basics and Extensions , author =. 2017 , note =
2017
-
[51]
Journal of Statistical Software, Articles , volume =
Malika Charrad and Nadia Ghazzali and Véronique Boiteau and Azam Niknafs , title =. Journal of Statistical Software, Articles , volume =. 2014 , issn =. doi:10.18637/jss.v061.i06 , url =
-
[52]
Computational Statistics & Data Analysis , pages=
Degrees of freedom and model selection for k-means clustering , author=. Computational Statistics & Data Analysis , pages=. 2020 , publisher=
2020
-
[53]
Statistics & Probability Letters , volume=
On Stein’s unbiased risk estimate for reduced rank estimators , author=. Statistics & Probability Letters , volume=. 2018 , publisher=
2018
-
[54]
Pattern Recognition , volume=
Enhancing principal direction divisive clustering , author=. Pattern Recognition , volume=. 2010 , publisher=
2010
-
[55]
Data mining and knowledge discovery , volume=
Principal direction divisive partitioning , author=. Data mining and knowledge discovery , volume=. 1998 , publisher=
1998
-
[56]
IEEE Signal Processing Letters , volume=
Selecting the number of principal components with SURE , author=. IEEE Signal Processing Letters , volume=. 2014 , publisher=
2014
-
[57]
Journal of the American Statistical Association , volume=
The estimation of prediction error: covariance penalties and cross-validation , author=. Journal of the American Statistical Association , volume=. 2004 , publisher=
2004
-
[58]
2005 , publisher=
Multimodal projection pursuit using the dip statistic , author=. 2005 , publisher=
2005
-
[59]
2015 IEEE Symposium Series on Computational Intelligence , pages=
Maximum clusterability divisive clustering , author=. 2015 IEEE Symposium Series on Computational Intelligence , pages=. 2015 , organization=
2015
-
[60]
Hellenic Conference on Artificial Intelligence , pages=
Clustering of high dimensional data streams , author=. Hellenic Conference on Artificial Intelligence , pages=. 2012 , organization=
2012
-
[61]
Systems & Control Letters , volume=
Stochastic approximation with two time scales , author=. Systems & Control Letters , volume=. 1997 , publisher=
1997
-
[62]
Statistics and Computing , volume=
Divisive clustering of high dimensional data streams , author=. Statistics and Computing , volume=. 2016 , publisher=
2016
-
[63]
Journal of the American Statistical Association , volume=
Cluster identification using projections , author=. Journal of the American Statistical Association , volume=. 2001 , publisher=
2001
-
[64]
Journal of Computational and Graphical Statistics , volume =
Projection Pursuit Clustering for Exploratory Data Analysis , author =. Journal of Computational and Graphical Statistics , volume =. 2003 , doi =
2003
-
[65]
David P. Hofmeyr and Nicos G. Pavlidis , title =. 2019 , journal =. doi:10.32614/RJ-2019-046 , url =
-
[66]
Journal of Statistical Planning and Inference , volume=
Multiple outlier detection in multivariate data using projection pursuit techniques , author=. Journal of Statistical Planning and Inference , volume=. 2000 , publisher=
2000
-
[67]
arXiv preprint arXiv:2003.09960 , year=
Efficient clustering for stretched mixtures: Landscape and optimality , author=. arXiv preprint arXiv:2003.09960 , year=
-
[68]
Introduction to
Michael Hahsler and Matthew Bola. Introduction to. Journal of Statistical Software , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.