LambdaMark: Semantic Audio Watermarking for Robustness and Radioactivity
Pith reviewed 2026-06-26 12:56 UTC · model grok-4.3
The pith
Embedding multi-bit watermarks in semantic audio latents produces the only scheme robust to all removal attacks while also transferring to finetuned models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
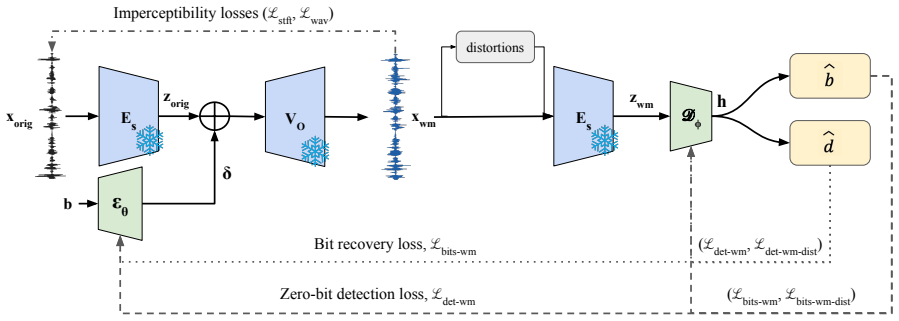
LambdaMark is the first generic radioactive watermarking scheme that embeds multi-bit watermark information into semantic audio latent representations. Unlike prior methods that operate on low-level signals, the watermarks carry semantic interpretation and are therefore more likely to be learned by a downstream model through finetuning. The scheme uses a lightweight encoder to inject message-dependent perturbations and a decoder to detect presence and recover bits; both are trained with a multi-component loss that preserves fidelity, improves bit recovery, and increases robustness to distortions and adversarial removal. The resulting watermarks achieve near-perfect robustness under common di
What carries the argument
Lightweight encoder that injects multi-bit message-dependent perturbations into semantic audio representations, paired with a decoder, and trained by a multi-component loss balancing fidelity, bit recovery rate, and robustness.
If this is right
- Watermarked audio trains speech models that reproduce the embedded bits in their own generated outputs.
- Detection accuracy stays near-perfect after common signal distortions and all evaluated adversarial removal attempts.
- The same decoder works on audio synthesized by models that were fine-tuned on the watermarked examples.
- The watermark remains effective without requiring changes to the downstream generation architecture.
Where Pith is reading between the lines
- The same semantic-embedding strategy could be tested on image or video generators to create transferable watermarks across modalities.
- Radioactivity may scale with model size; larger finetuning runs could be measured to see whether bit recovery improves or saturates.
- Practical use would require evaluating whether the added perturbations affect perceptual quality under real-world listening conditions not covered in the paper.
- If semantic latents prove sufficient for radioactivity, future work could explore whether the same principle applies to other forms of generative content without audio-specific encoders.
Load-bearing premise
Embedding watermark information into semantic audio latent representations will cause downstream speech generation models to learn and reproduce the watermark when finetuned on the watermarked audio.
What would settle it
A finetuned speech generation model whose outputs contain no recoverable watermark bits from the original LambdaMark embedding, or a removal attack that defeats the decoder while leaving audio quality intact.
Figures
read the original abstract
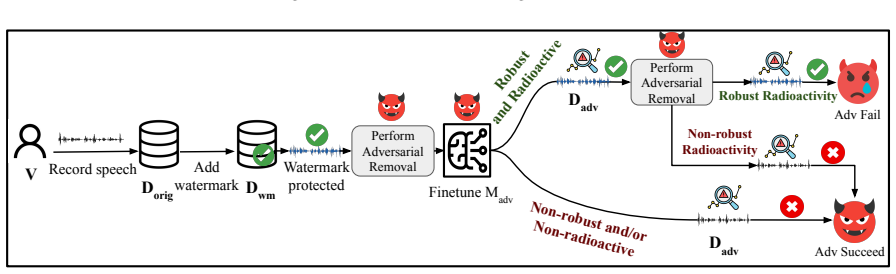
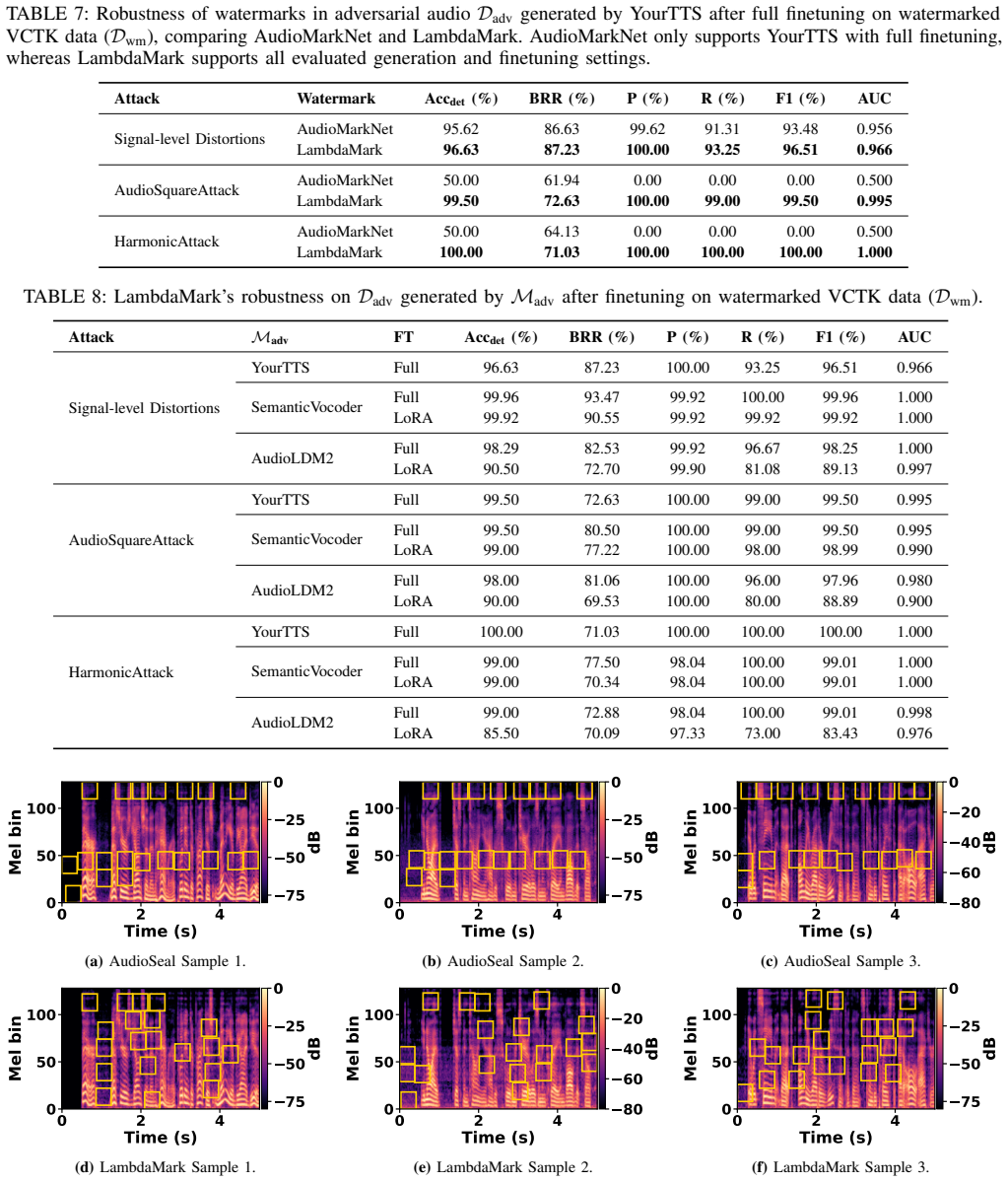
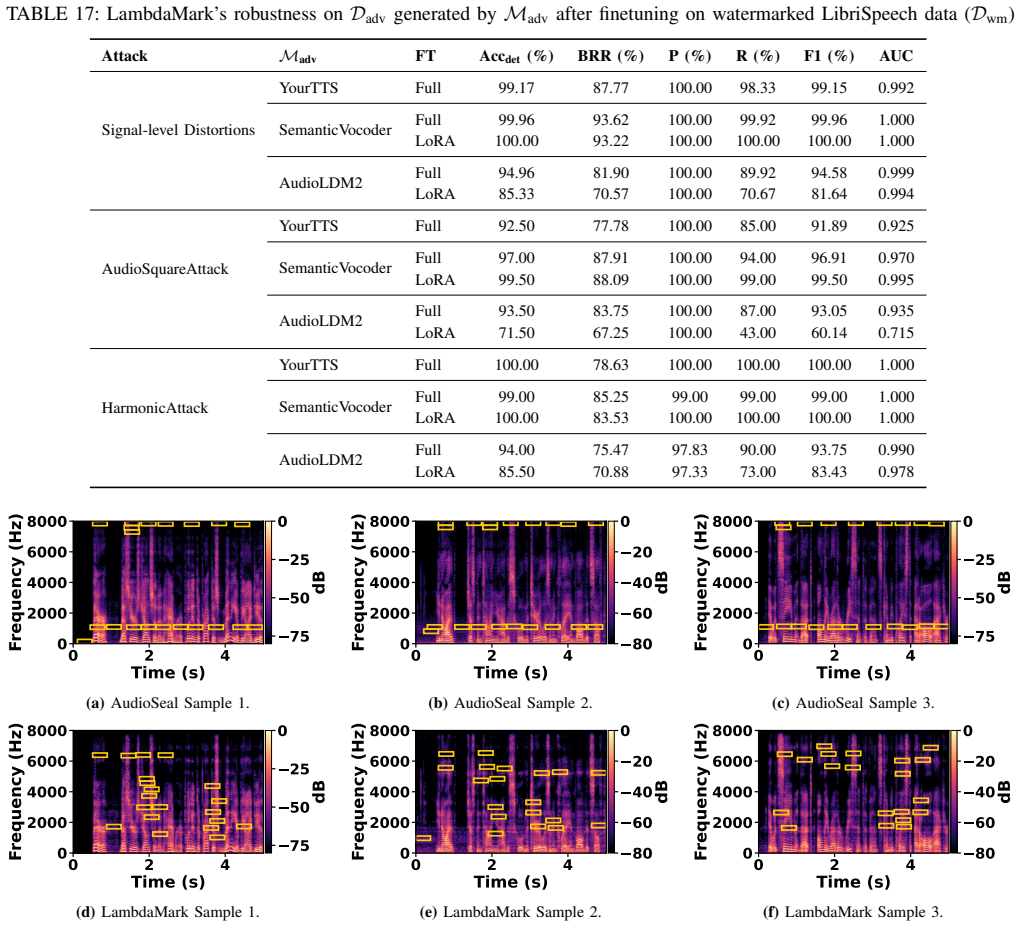
Recent advances in generative audio have made voice cloning increasingly effortless, enabling voice fraud, impersonation, and other forms of unauthorized use. A common attack finetunes a speech generation model on recordings of a target speaker, allowing the model to synthesize speech in that speaker's voice. Audio watermarking offers a promising defense by embedding detectable signals into audio. A practical watermark must satisfy two key properties: robustness and radioactivity. Existing audio watermarking methods typically embed signals into low-level representations, such as waveforms or spectrograms, which makes them vulnerable to signal-level manipulations and limits their transfer to downstream models. We introduce LambdaMark -- the first generic radioactive watermarking scheme. Unlike all previous approaches, LambdaMark achieves generic radioactivity by embedding multi-bit watermark information into semantic audio latent representations. Our watermarks have semantic interpretation and are thus more likely to be learned by a downstream model through finetuning. LambdaMark includes a lightweight watermark encoder to inject multi-bit message-dependent perturbations into semantic audio representations and a decoder to detect watermark presence and recover the embedded bit information. Encoder and decoder are trained using a custom multi-component loss that preserves fidelity of the watermarked audio, increases bit-level recovery rate, and improves robustness against common distortions and adversarial removal attempts. Experiments show that LambdaMark achieves near-perfect robustness under common distortions. LambdaMark is also the only watermark that is robust against all evaluated removal attacks. Furthermore, LambdaMark exhibits general and robust radioactivity and remains robust to distortions and adversarial removal attacks even on the generated outputs of those finetuned models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims to introduce LambdaMark, the first generic radioactive audio watermarking scheme, which embeds multi-bit messages into semantic audio latent representations via a lightweight encoder-decoder pair trained with a multi-component loss. It reports near-perfect robustness to common distortions, unique robustness against all evaluated removal attacks (unlike prior low-level embedding methods), and general radioactivity such that the watermark transfers to and remains detectable in outputs of speech generation models finetuned on the watermarked audio.
Significance. If the empirical claims on robustness and especially radioactivity hold after detailed validation, the work would advance defenses against voice cloning and generative audio misuse by demonstrating a watermark that survives finetuning transfer. The semantic-latent placement for improved radioactivity is a novel engineering direction relative to waveform/spectrogram baselines.
major comments (2)
- [Abstract] Abstract: The central claim that LambdaMark 'is the only watermark that is robust against all evaluated removal attacks' is load-bearing but rests on unspecified experiments; the abstract supplies no enumeration of baselines, attack set, or metrics, preventing assessment of whether post-hoc attack selection occurred.
- [Abstract] Abstract: The radioactivity claim depends on the premise that semantic latents 'have semantic interpretation and are thus more likely to be learned by a downstream model through finetuning.' No ablation against waveform or spectrogram baselines, no mechanistic argument, and no reference to transfer-learning results are supplied; if the finetuning objective does not align with the semantic encoder, transfer can be near zero regardless of original-audio robustness.
minor comments (1)
- The abstract refers to a 'custom multi-component loss' without naming the components or their relative weights; these should be stated explicitly with equations in the methods.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, clarifying the manuscript's content and outlining planned revisions to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that LambdaMark 'is the only watermark that is robust against all evaluated removal attacks' is load-bearing but rests on unspecified experiments; the abstract supplies no enumeration of baselines, attack set, or metrics, preventing assessment of whether post-hoc attack selection occurred.
Authors: We agree that the abstract does not enumerate the experiments. The full details of the baselines, the complete set of removal attacks (covering signal processing distortions and multiple adversarial removal methods), and the evaluation metrics are provided in Sections 4.2 and 4.3. To address concerns about post-hoc selection, we will revise the abstract to briefly indicate the categories of attacks considered. revision: yes
-
Referee: [Abstract] Abstract: The radioactivity claim depends on the premise that semantic latents 'have semantic interpretation and are thus more likely to be learned by a downstream model through finetuning.' No ablation against waveform or spectrogram baselines, no mechanistic argument, and no reference to transfer-learning results are supplied; if the finetuning objective does not align with the semantic encoder, transfer can be near zero regardless of original-audio robustness.
Authors: Section 5 reports empirical evidence of radioactivity through finetuning transfer experiments on the watermarked audio. The premise regarding semantic latents is motivated by their design. We acknowledge, however, that the manuscript does not include explicit ablations of radioactivity against waveform or spectrogram baselines, a detailed mechanistic argument, or citations to transfer-learning results. We will add a discussion subsection providing a mechanistic rationale based on the properties of semantic representations and include relevant references from the transfer-learning literature. revision: partial
Circularity Check
No circularity: empirical engineering claims rest on experimental validation, not self-referential derivations or fitted inputs
full rationale
The paper introduces LambdaMark as an empirical audio watermarking scheme whose central claims (robustness to attacks and radioactivity under finetuning) are supported by experimental results rather than any derivation chain. The abstract and provided text contain no equations, no fitted parameters renamed as predictions, and no load-bearing self-citations or uniqueness theorems. The statement that semantic latents 'are thus more likely to be learned' is a design rationale, not a mathematical reduction to the authors' prior inputs. No steps match the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (1)
- multi-component loss weights
axioms (2)
- domain assumption Semantic audio latent representations exist and can be extracted by existing audio encoders.
- standard math Standard neural network optimization will converge to a solution satisfying the multi-component loss.
invented entities (1)
-
LambdaMark watermark encoder and decoder pair
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Qwen2-Audio Technical Report,
Y . Chu, J. Xu, Q. Yang, H. Wei, X. Wei, Z. Guo, Y . Leng, Y . Lv, J. He, J. Lin, C. Zhou, and J. Zhou, “Qwen2-Audio Technical Report,”
-
[2]
Available: http://arxiv.org/abs/2407.10759
[Online]. Available: http://arxiv.org/abs/2407.10759
-
[3]
Kimi-Audio Technical Report,
KimiTeam, D. Ding, Z. Ju, Y . Leng, S. Liu, T. Liu, Z. Shang, K. Shen, W. Song, X. Tan, H. Tang, Z. Wang, C. Wei, Y . Xin, X. Xu, J. Yu, Y . Zhang, X. Zhou, Y . Charles, J. Chen, Y . Chen, Y . Du, W. He, Z. Hu, G. Lai, Q. Li, Y . Liu, W. Sun, J. Wang, Y . Wang, Y . Wu, Y . Wu, D. Yang, H. Yang, Y . Yang, Z. Yang, A. Yin, R. Yuan, Y . Zhang, and Z. Zhou, “...
-
[4]
Available: http://arxiv.org/abs/2504.18425
[Online]. Available: http://arxiv.org/abs/2504.18425
-
[5]
H. Hu, X. Zhu, T. He, D. Guo, B. Zhang, X. Wang, Z. Guo, Z. Jiang, H. Hao, Z. Guo, X. Zhang, P. Zhang, B. Yang, J. Xu, J. Zhou, and J. Lin, “Qwen3-TTS Technical Report,” 2026. [Online]. Available: https://arxiv.org/abs/2601.15621
Pith/arXiv arXiv 2026
-
[6]
Fraudsters Cloned Company Director’s V oice In $35 Million Heist,
Forbes, “Fraudsters Cloned Company Director’s V oice In $35 Million Heist,” 2021. [Online]. Available: https://www.forbes.com/sites/thoma sbrewster/2021/10/14/huge-bank-fraud-uses-deep-fake-voice-tech-t o-steal-millions/
2021
-
[7]
CEO of world’s biggest ad firm targeted by deepfake scam,
“CEO of world’s biggest ad firm targeted by deepfake scam,” 2024. [Online]. Available: https://www.theguardian.com/technology/article/2 024/may/10/ceo-wpp-deepfake-scam
2024
-
[8]
Company worker in Hong Kong pays out £20m in deepfake video call scam,
D. Milmo, “Company worker in Hong Kong pays out £20m in deepfake video call scam,”The Guardian, 2 2024. [Online]. Available: https://www.theguardian.com/world/2024/feb/05/hong-kong-compa ny-deepfake-video-conference-call-scam
2024
-
[9]
AI deception: A survey of examples, risks, and potential solutions,
P. S. Park, S. Goldstein, A. O’Gara, M. Chen, and D. Hendrycks, “AI deception: A survey of examples, risks, and potential solutions,” Patterns (N. Y.), vol. 5, no. 5, p. 100988, May 2024
2024
-
[10]
Record Com- panies Bring Landmark Cases for Responsible AI Against Suno and Udio in Boston and New York Federal Courts, Respectively,
Recording Industry Association of America (RIAA), “Record Com- panies Bring Landmark Cases for Responsible AI Against Suno and Udio in Boston and New York Federal Courts, Respectively,” RIAA Press Release, Jun. 2024
2024
-
[11]
V oice actors and generative AI: Legal challenges and emerging protections,
E. Chuks-Okeke, A. Adetunji, and B. Leong, “V oice actors and generative AI: Legal challenges and emerging protections,”IAPP News, Dec 2023. [Online]. Available: https://iapp.org/news/a/voice-a ctors-and-generative-ai-legal-challenges-and-emerging-protections
2023
-
[12]
Unauthorized V oice Cloning: The Legal Response in the Intersection of Performers’ Rights, Sound Recording Protec- tion, and Image Rights in the Age of AI,
C. Kanellopoulou, “Unauthorized V oice Cloning: The Legal Response in the Intersection of Performers’ Rights, Sound Recording Protec- tion, and Image Rights in the Age of AI,” Dissertation, Stockholm University, 2025
2025
-
[13]
An AI-generated band got 1m plays on Spotify. Now music insiders say listeners should be warned,
“An AI-generated band got 1m plays on Spotify. Now music insiders say listeners should be warned,” The Guardian (Tech), 2025
2025
-
[14]
The League of Women V oters is suing those involved in robocalls sent to New Hampshire voters,
Holly Ramer, “The League of Women V oters is suing those involved in robocalls sent to New Hampshire voters,” https://apnews.com/artic le/new-hampshire-primary-biden-robocalls-f7cc3c2610ab6ccdfaa26 d2a8ea1cbdb, Mar. 2024
2024
-
[15]
League of Women V oters and Free Speech For People Applaud Judgment for Plaintiffs in New Hampshire V oter Intimidation Lawsuit,
League of Women V oters, “League of Women V oters and Free Speech For People Applaud Judgment for Plaintiffs in New Hampshire V oter Intimidation Lawsuit,” https://www.lwv.org/newsroom/press-releases/ league-women-voters-and-free-speech-people-applaud-judgment-p laintiffs-new, Nov. 2025
2025
-
[16]
V oice actors can pursue some claims over AI voiceovers, US court says,
B. Brittain, “V oice actors can pursue some claims over AI voiceovers, US court says,” https://www.reuters.com/legal/litigation/voice-actor s-can-pursue-some-claims-over-ai-voiceovers-us-court-says-2025-0 7-10/, Jul. 2025
2025
-
[17]
Music AI startups Suno and Udio slam record label lawsuits in court filings,
——, “Music AI startups Suno and Udio slam record label lawsuits in court filings,” https://www.reuters.com/legal/litigation/music-ai-start ups-suno-udio-slam-record-label-lawsuits-court-filings-2024-08-01/, Aug. 2024
2024
-
[18]
Universal Music settles copyright dispute with AI firm Udio,
Rishabh Jaiswal, “Universal Music settles copyright dispute with AI firm Udio,” https://www.reuters.com/business/media-telecom/universal -music-settles-copyright-dispute-with-ai-firm-udio-2025-10-30/, Oct. 2025
2025
-
[19]
Warner Music Group settles copyright case with Suno for licensed AI music,
Reuters, “Warner Music Group settles copyright case with Suno for licensed AI music,” https://www.reuters.com/legal/litigation/warner-m usic-group-settles-copyright-case-with-suno-licensed-ai-music-202 5-11-25/, Nov. 2025
2025
-
[20]
UMG Recordings, Inc. et al. v. Uncharted Labs, Inc. et al., No. 1:2024cv04777, Document 156,
United States District Court for the Southern District of New York, “UMG Recordings, Inc. et al. v. Uncharted Labs, Inc. et al., No. 1:2024cv04777, Document 156,” https://law.justia.com/cases/federal/d istrict-courts/new-york/nysdce/1%3A2024cv04777/623701/156/, Apr. 2026, order and Opinion Denying Defendants’ Motion to Dismiss
2026
-
[21]
Proactive Detection of V oice Cloning with Localized Watermarking,
R. S. Roman, P. Fernandez, A. Défossez, T. Furon, T. Tran, and H. Elsahar, “Proactive Detection of V oice Cloning with Localized Watermarking,” 2024. [Online]. Available: https://arxiv.org/abs/2401.1 7264
2024
-
[22]
WavMark: Watermarking for audio generation,
G. Chen, Y . Wu, S. Liu, T. Liu, X. Du, and F. Wei, “WavMark: Watermarking for audio generation,” 2024. [Online]. Available: http://arxiv.org/abs/2308.12770
arXiv 2024
-
[23]
SilentCipher: Deep audio watermarking,
M. K. Singh, N. Takahashi, W. Liao, and Y . Mitsufuji, “SilentCipher: Deep audio watermarking,” inInterspeech 2024. ISCA: ISCA, Sep. 2024, pp. 2235–2239
2024
-
[24]
Detecting V oice Cloning Attacks via Timbre Watermarking,
C. Liu, J. Zhang, T. Zhang, X. Yang, W. Zhang, and N. Yu, “Detecting V oice Cloning Attacks via Timbre Watermarking,” 2023. [Online]. Available: http://arxiv.org/abs/2312.03410
arXiv 2023
-
[25]
Latent Watermarking of Audio Generative Models,
R. S. Roman, P. Fernandez, A. Deleforge, Y . Adi, and R. Serizel, “Latent Watermarking of Audio Generative Models,” 2024. [Online]. Available: https://arxiv.org/abs/2409.02915
arXiv 2024
-
[26]
GROOT: Generating Robust Watermark for Diffusion-Model-Based Audio Synthesis,
W. Liu, Y . Li, D. Lin, H. Tian, and H. Li, “GROOT: Generating Robust Watermark for Diffusion-Model-Based Audio Synthesis,”
-
[27]
Available: https://arxiv.org/abs/2407.10471
[Online]. Available: https://arxiv.org/abs/2407.10471
-
[28]
Au- dioMarkNet: audio watermarking for deepfake speech detection,
W. Zong, Y .-W. Chow, W. Susilo, J. Baek, and S. Camtepe, “Au- dioMarkNet: audio watermarking for deepfake speech detection,” in Proceedings of the 34th USENIX Conference on Security Symposium, ser. SEC ’25. USA: USENIX Association, 2025
2025
-
[29]
Robust audio watermarking using perceptual masking,
M. D. Swanson, B. Zhu, A. H. Tewfik, and L. Boney, “Robust audio watermarking using perceptual masking,”Signal Processing, vol. 66, no. 3, pp. 337–355, May 1998
1998
-
[30]
Spread-spectrum watermarking of audio signals,
D. Kirovski and H. Malvar, “Spread-spectrum watermarking of audio signals,”IEEE Transactions on Signal Processing, vol. 51, no. 4, pp. 1020–1033, 2003
2003
-
[31]
HarmonicAttack: An Adaptive Cross-Domain Audio Watermark Removal,
K. Li, X. Hu, I. Grishchenko, and D. Lie, “HarmonicAttack: An Adaptive Cross-Domain Audio Watermark Removal,” 2025. [Online]. Available: https://arxiv.org/abs/2511.21577
Pith/arXiv arXiv 2025
-
[32]
AudioMarkBench: Benchmarking Robustness of Audio Watermarking,
H. Liu, M. Guo, Z. Jiang, L. Wang, and N. Z. Gong, “AudioMarkBench: Benchmarking Robustness of Audio Watermarking,”
-
[33]
Available: https://arxiv.org/abs/2406.06979
[Online]. Available: https://arxiv.org/abs/2406.06979
-
[34]
Deep Audio Watermarks are Shallow: Limitations of Post-Hoc Watermarking Techniques for Speech,
P. O’Reilly, Z. Jin, J. Su, and B. Pardo, “Deep Audio Watermarks are Shallow: Limitations of Post-Hoc Watermarking Techniques for Speech,” 2025. [Online]. Available: http://arxiv.org/abs/2504.10782
arXiv 2025
-
[35]
Y . Özer, W. Choi, J. Serrà, M. K. Singh, W.-H. Liao, and Y . Mitsufuji, “A Comprehensive Real-World Assessment of Audio Watermarking Algorithms: Will They Survive Neural Codecs?” 2025. [Online]. Available: http://arxiv.org/abs/2505.19663
arXiv 2025
-
[36]
Tree-Ring Watermarks: Fingerprints for Diffusion Images that are Invisible and Robust,
Y . Wen, J. Kirchenbauer, J. Geiping, and T. Goldstein, “Tree-Ring Watermarks: Fingerprints for Diffusion Images that are Invisible and Robust,” 2023. [Online]. Available: https://arxiv.org/abs/2305.20030
arXiv 2023
-
[37]
RingID: Rethinking Tree-Ring Watermarking for Enhanced Multi-Key Identification,
H. Ci, P. Yang, Y . Song, and M. Z. Shou, “RingID: Rethinking Tree-Ring Watermarking for Enhanced Multi-Key Identification,”
-
[38]
Available: https://arxiv.org/abs/2404.14055
[Online]. Available: https://arxiv.org/abs/2404.14055
-
[39]
HMARK: Radioactive Multi-Bit Semantic-Latent Watermarking for Diffusion Models,
K. Li, G. Ding, I. Grishchenko, and D. Lie, “HMARK: Radioactive Multi-Bit Semantic-Latent Watermarking for Diffusion Models,” 2025. [Online]. Available: https://arxiv.org/abs/2512.00094
arXiv 2025
-
[40]
Discovering Interpretable Directions in the Semantic Latent Space of Diffusion Models,
R. Haas, I. Huberman-Spiegelglas, R. Mulayoff, S. Graßhof, S. S. Brandt, and T. Michaeli, “Discovering Interpretable Directions in the Semantic Latent Space of Diffusion Models,” 2024. [Online]. Available: https://arxiv.org/abs/2303.11073 15
arXiv 2024
-
[41]
Scaling up masked audio encoder learning for general audio classification,
H. Dinkel, Z. Yan, Y . Wang, J. Zhang, Y . Wang, and B. Wang, “Scaling up masked audio encoder learning for general audio classification,”
-
[42]
Available: https://arxiv.org/abs/2406.06992
[Online]. Available: https://arxiv.org/abs/2406.06992
-
[43]
SemanticV ocoder: Bridging Audio Generation and Audio Understanding via Semantic Latents,
Z. Xie, C. Li, Q. Jin, X. Xu, G. Yang, W. Wang, M. Wu, D. Yu, and Y . Zou, “SemanticV ocoder: Bridging Audio Generation and Audio Understanding via Semantic Latents,” 2026. [Online]. Available: https://arxiv.org/abs/2602.23333
arXiv 2026
-
[44]
CLAP: Learning audio concepts from natural language supervision,
B. Elizalde, S. Deshmukh, M. Al Ismail, and H. Wang, “CLAP: Learning audio concepts from natural language supervision,” Jun. 2022
2022
-
[45]
AudioLDM 2: Learning Holistic Audio Generation with Self-supervised Pretraining,
H. Liu, Y . Yuan, X. Liu, X. Mei, Q. Kong, Q. Tian, Y . Wang, W. Wang, Y . Wang, and M. D. Plumbley, “AudioLDM 2: Learning Holistic Audio Generation with Self-supervised Pretraining,” Aug. 2023
2023
-
[46]
Simple and Controllable Music Generation,
J. Copet, F. Kreuk, I. Gat, T. Remez, D. Kant, G. Synnaeve, Y . Adi, and A. Défossez, “Simple and Controllable Music Generation,” Jun. 2023
2023
-
[47]
MiDashengLM: Efficient Audio Understanding with General Audio Captions,
H. Dinkel, G. Li, J. Liu, J. Luan, Y . Niu, X. Sun, T. Wang, Q. Xiao, J. Zhang, and J. Zhou, “MiDashengLM: Efficient Audio Understanding with General Audio Captions,” 2026. [Online]. Available: https://arxiv.org/abs/2508.03983
arXiv 2026
-
[48]
Librispeech: An ASR corpus based on public domain audio books,
V . Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Librispeech: An ASR corpus based on public domain audio books,” Apr. 2015
2015
-
[49]
CSTR VCTK Corpus: English multi-speaker corpus for CSTR voice cloning toolkit (version 0.92),
J. Yamagishi, C. Veaux, and K. MacDonald, “CSTR VCTK Corpus: English multi-speaker corpus for CSTR voice cloning toolkit (version 0.92),” 2019
2019
-
[50]
YourTTS: Towards Zero-Shot Multi-Speaker TTS and Zero-Shot V oice Conversion for everyone,
E. Casanova, J. Weber, C. Shulby, A. C. Junior, E. Gölge, and M. A. Ponti, “YourTTS: Towards Zero-Shot Multi-Speaker TTS and Zero-Shot V oice Conversion for everyone,” 2023. [Online]. Available: https://arxiv.org/abs/2112.02418
arXiv 2023
-
[51]
Robust Speech Recognition via Large-Scale Weak Supervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust Speech Recognition via Large-Scale Weak Supervision,” 2022. [Online]. Available: https://arxiv.org/abs/2212.0 4356
2022
-
[52]
NISQA: A Deep CNN-Self-Attention Model for Multidimensional Speech Quality Prediction with Crowdsourced Datasets,
G. Mittag, B. Naderi, A. Chehadi, and S. Möller, “NISQA: A Deep CNN-Self-Attention Model for Multidimensional Speech Quality Prediction with Crowdsourced Datasets,” inInterspeech
-
[53]
ISCA, Aug. 2021, pp. 2127–2131. [Online]. Available: http://dx.doi.org/10.21437/Interspeech.2021-299
-
[54]
ViSQOL v3: An Open Source Production Ready Objective Speech and Audio Metric,
M. Chinen, F. S. C. Lim, J. Skoglund, N. Gureev, F. O’Gorman, and A. Hines, “ViSQOL v3: An Open Source Production Ready Objective Speech and Audio Metric,” 2020. [Online]. Available: https://arxiv.org/abs/2004.09584
arXiv 2020
-
[55]
Square Attack: a query-efficient black-box adversarial attack via random search,
M. Andriushchenko, F. Croce, N. Flammarion, and M. Hein, “Square Attack: a query-efficient black-box adversarial attack via random search,” 2020. [Online]. Available: https://arxiv.org/abs/1912.00049
arXiv 2020
-
[56]
Spark-TTS: An Efficient LLM-Based Text-to-Speech Model with Single-Stream Decoupled Speech Tokens,
X. Wang, M. Jiang, Z. Ma, Z. Zhang, S. Liu, L. Li, Z. Liang, Q. Zheng, R. Wang, X. Feng, W. Bian, Z. Ye, S. Cheng, R. Yuan, Z. Zhao, X. Zhu, J. Pan, L. Xue, P. Zhu, Y . Chen, Z. Li, X. Chen, L. Xie, Y . Guo, and W. Xue, “Spark-TTS: An Efficient LLM-Based Text-to-Speech Model with Single-Stream Decoupled Speech Tokens,”
-
[57]
Available: https://arxiv.org/abs/2503.01710 Appendix A
[Online]. Available: https://arxiv.org/abs/2503.01710 Appendix A. Hyperparameter Choices for the Distortions We evaluate robustness under a comprehensive suite of audio distortions. For Gaussian noise, we use additive white Gaussian noise at SNRs of 20 dB and 30 dB. For resampling, we downsample the audio to 50% of the original sampling rate and then upsa...
Pith/arXiv arXiv 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.