Harnessing Source Heterogeneity for Cluster-Structured Transfer Learning
Pith reviewed 2026-06-28 04:00 UTC · model grok-4.3
The pith
Trans-GLMC recovers latent source clusters via coefficient distances to adapt fusion in generalized linear models and tighten non-asymptotic error bounds when clusters align with the target.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
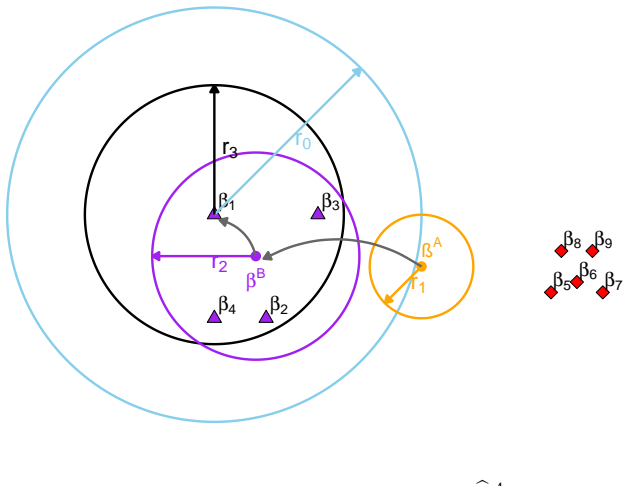
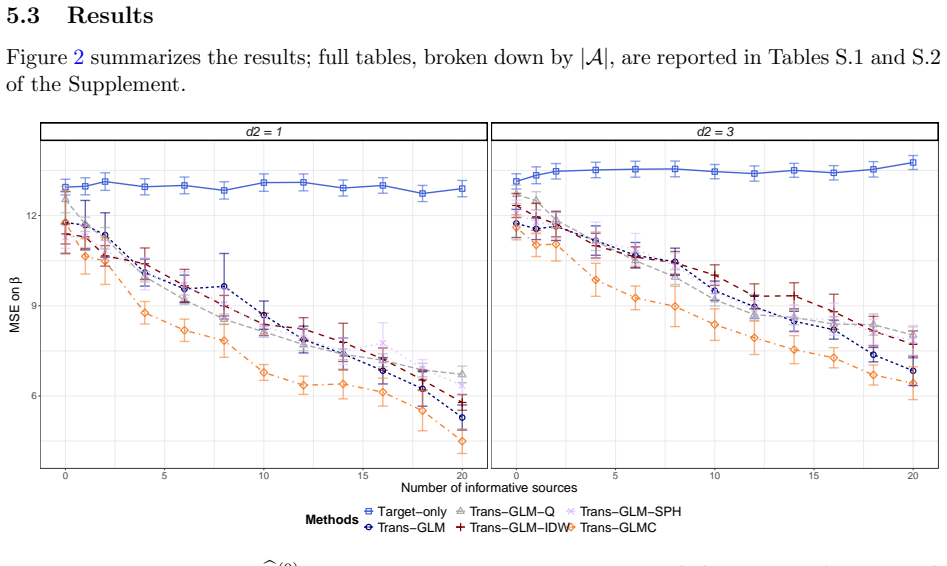
Trans-GLMC constructs a coefficient-based distance among the target and candidate sources to recover latent source clusters, then combines global fusion, within-cluster refinement, and target debiasing; the resulting estimator satisfies a non-asymptotic error bound that improves over its unclustered counterpart whenever a meaningful target cluster exists and matches the unclustered rate up to constants otherwise.
What carries the argument
The coefficient-based distance among target and candidate sources, which recovers latent source clusters and enables the subsequent adaptive fusion steps.
If this is right
- The non-asymptotic error bound improves over unclustered transfer learning whenever a meaningful target cluster exists.
- The bound matches the unclustered rate up to constants when no such cluster is present.
- In multi-hospital settings with rare events, the procedure improves facility-specific prediction accuracy.
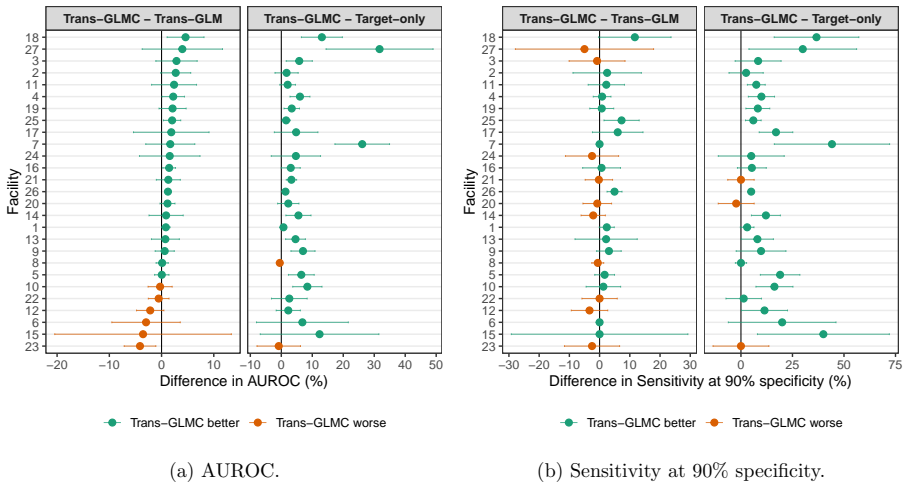
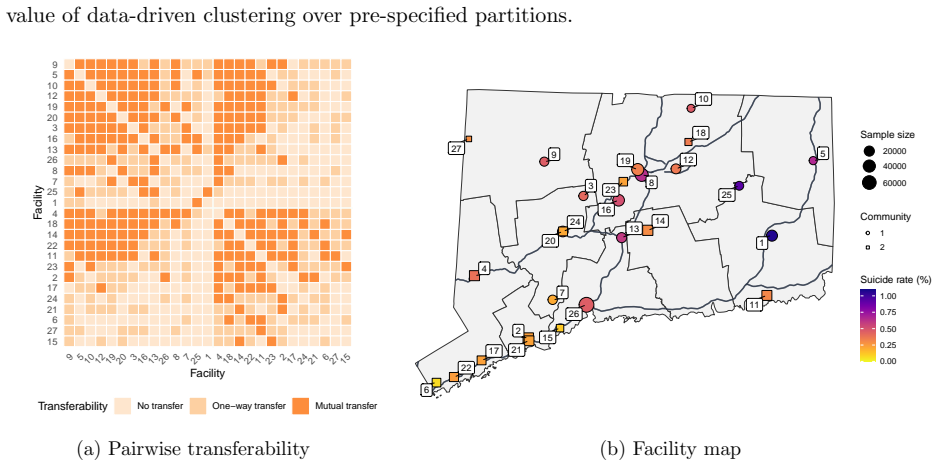
- It identifies interpretable communities of hospitals that share mutual transferability and recovers clinically coherent risk factors.
Where Pith is reading between the lines
- The same coefficient-distance clustering step could be tested in other multi-site sparse-data problems, such as regional modeling of rare outcomes.
- If the distance proves stable under moderate misspecification, the adaptive bound may reduce reliance on manual source screening in high-dimensional transfer tasks.
- Extensions to non-GLM losses or time-varying clusters would be natural next checks on whether the improvement mechanism generalizes.
Load-bearing premise
The coefficient-based distance among target and candidate sources accurately recovers the latent source clusters.
What would settle it
A simulation in which known source clusters exist but the coefficient-based distance fails to recover them, producing error rates that show no improvement over the unclustered baseline.
Figures
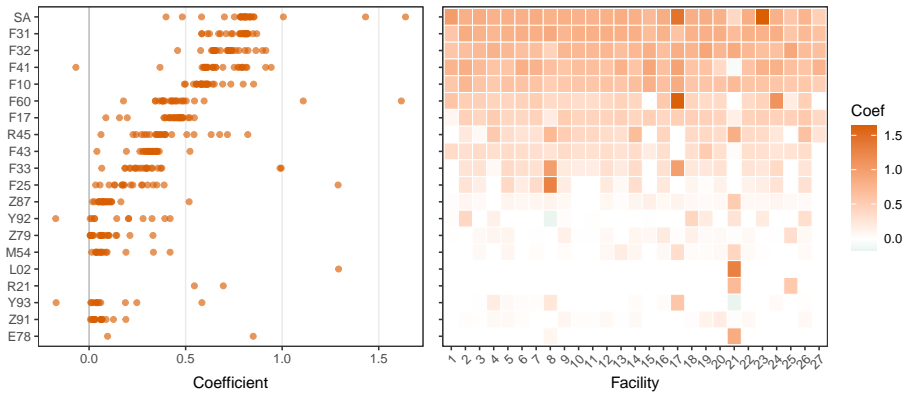
read the original abstract
Transfer learning is a natural strategy when a target population has limited data but multiple related auxiliary sources are available. A central difficulty is source heterogeneity: auxiliary sources may not be equally useful, and their usefulness may vary in a structured, cluster-like fashion. Existing transfer-learning methods often reduce source selection to a binary informative/non-informative decision, overlooking subgroups of sources with differential transferability. Motivated by a suicide-risk study using data from the Connecticut Hospital Information Management Exchange (CHIME), comprising 636,758 patients across 27 hospitals, we propose Trans-GLMC, a cluster-structured transfer-learning procedure for generalized linear models. The CHIME setting illustrates the core challenge: hospital-specific risk models are unstable because suicide attempts are rare at any single facility, whereas indiscriminate pooling across hospitals can obscure facility-level differences in patient mix and risk profiles. Trans-GLMC first constructs a coefficient-based distance among the target and candidate sources to recover latent source clusters. It then combines global fusion, within-cluster refinement, and target debiasing to produce an estimator that adapts to the detected structure. We establish a non-asymptotic error bound that improves over its unclustered counterpart whenever a meaningful target cluster exists and matches the unclustered rate up to constants otherwise. In simulations and in the CHIME study, Trans-GLMC improves facility-specific prediction, identifies interpretable communities of hospitals with mutual transferability, and recovers clinically coherent suicide-risk factors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Trans-GLMC, a cluster-structured transfer learning procedure for generalized linear models. It first uses a coefficient-based distance to recover latent clusters among target and source populations, then applies global fusion, within-cluster refinement, and target debiasing. The central theoretical claim is a non-asymptotic error bound that improves over the unclustered estimator when a meaningful target cluster exists and matches the unclustered rate up to constants otherwise. The method is illustrated on simulations and the CHIME hospital data for suicide-risk prediction.
Significance. If the non-asymptotic bound can be established with a rigorous high-probability guarantee on the initial clustering step, the work would provide a useful adaptive procedure for exploiting structured source heterogeneity in transfer learning for GLMs, particularly in rare-event settings such as hospital-level medical data. The CHIME application demonstrates potential for identifying interpretable groups of transferable sources.
major comments (1)
- [Abstract / theoretical analysis] Abstract and theoretical analysis section: The claimed improvement in the non-asymptotic error bound over the unclustered estimator holds only after the coefficient-based distance recovers the latent source clusters. No high-probability guarantee on successful cluster recovery is stated, so the bound's advantage is conditional on an unverified premise about the first algorithmic stage; if recovery fails, the procedure reverts to the unclustered rate without the advertised improvement.
minor comments (2)
- [Empirical section] The manuscript should supply explicit details on data-exclusion rules, hyperparameter tuning, and cross-validation procedures used in the CHIME experiments to allow verification of the reported prediction improvements.
- [Method description] Notation for the coefficient-based distance and the subsequent fusion steps could be clarified with a short algorithmic pseudocode box.
Simulated Author's Rebuttal
Thank you for your detailed review. We address the major comment on the theoretical guarantee for cluster recovery below.
read point-by-point responses
-
Referee: [Abstract / theoretical analysis] Abstract and theoretical analysis section: The claimed improvement in the non-asymptotic error bound over the unclustered estimator holds only after the coefficient-based distance recovers the latent source clusters. No high-probability guarantee on successful cluster recovery is stated, so the bound's advantage is conditional on an unverified premise about the first algorithmic stage; if recovery fails, the procedure reverts to the unclustered rate without the advertised improvement.
Authors: We appreciate the referee highlighting this point on presentation. The non-asymptotic bound in the main theorem is derived conditional on correct recovery of the latent clusters by the coefficient-based distance. The appendix establishes that, under the minimum separation condition between cluster centers (Assumption 3), the probability of misclustering decays exponentially in the sample size, so the improved rate holds with high probability. To address the concern directly, we will revise the abstract and theoretical analysis section to state this high-probability guarantee explicitly and to present the overall bound as holding with probability at least 1-δ under the stated assumptions. This makes the adaptive improvement rigorous without altering the results. revision: yes
Circularity Check
No circularity: bound derived conditionally on clustering success without reducing to fitted inputs by construction
full rationale
The paper's central result is a non-asymptotic error bound for the Trans-GLMC estimator that improves over the unclustered rate precisely when a meaningful target cluster is recovered by the coefficient-based distance step. This is presented as a conditional theoretical guarantee rather than a quantity defined in terms of the fitted parameters themselves. No equations or steps in the abstract reduce the bound to a self-referential fit, and the provided text contains no self-citations that serve as load-bearing premises for the uniqueness or form of the result. The derivation chain therefore remains self-contained against external statistical benchmarks for transfer learning bounds.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Coefficient-based distance recovers latent source clusters
- standard math Generalized linear model regularity conditions hold for the error bound
Reference graph
Works this paper leans on
-
[1]
Ahmedani, B. K., G. E. Simon, C. Stewart, A. Beck, B. E. Waitzfelder, R. Rossom, F. Lynch, A. Owen-Smith, E. M. Hunkeler, U. Whiteside, et al. (2014). Health care contacts in the year before suicide death. Journal of General Internal Medicine\/ 29 , 870--877
2014
-
[2]
Barak-Corren, Y., V. M. Castro, M. K. Nock, K. D. Mandl, E. M. Madsen, A. Seiger, W. G. Adams, R. J. Applegate, E. V. Bernstam, J. G. Klann, et al. (2020). Validation of an electronic health record--based suicide risk prediction modeling approach across multiple health care systems. JAMA Network Open\/ 3\/ (3), e201262--e201262
2020
-
[3]
Bastani, H. (2021). Predicting with proxies: Transfer learning in high dimension. Management Science\/ 67\/ (5), 2964--2984
2021
-
[4]
Bemporad, A. (2023). Active learning for regression by inverse distance weighting. Information Sciences\/ 626 , 275--292
2023
-
[5]
Benjamini, Y. and Y. Hochberg (1995). Controlling the false discovery rate: a practical and powerful approach to multiple testing. Journal of the Royal Statistical Society Series B\/ 57\/ (1), 289--300
1995
-
[6]
Bertolote, J. M., A. Fleischmann, D. De Leo, and D. Wasserman (2004). Psychiatric diagnoses and suicide: revisiting the evidence. Crisis\/ 25\/ (4), 147--155
2004
-
[7]
Cai, T. T. and H. Wei (2021). Transfer learning for nonparametric classification: Minimax rate and adaptive classifier. The Annals of Statistics\/ 49\/ (1), 100--128
2021
-
[8]
Clauset, A., M. E. J. Newman, and C. Moore (2004). Finding community structure in very large networks. Physical Review E\/ 70\/ (6), 066111
2004
-
[9]
Cressie, N. (2015). Statistics for spatial data . John Wiley & Sons
2015
-
[10]
Doshi, R. P., K. Chen, F. Wang, H. Schwartz, A. Herzog, and R. H. Aseltine Jr (2020). Identifying risk factors for mortality among patients previously hospitalized for a suicide attempt. Scientific Reports\/ 10\/ (1), 15223
2020
-
[11]
Franklin, J. C., J. D. Ribeiro, K. R. Fox, K. H. Bentley, E. M. Kleiman, X. Huang, K. M. Musacchio, A. C. Jaroszewski, B. P. Chang, and M. K. Nock (2017). Risk factors for suicidal thoughts and behaviors: A meta-analysis of 50 years of research. Psychological Bulletin\/ 143\/ (2), 187--232
2017
-
[12]
Harris, E. C. and B. Barraclough (1997). Suicide as an outcome for mental disorders: a meta-analysis. British Journal of Psychiatry\/ 170\/ (3), 205--228
1997
-
[13]
Ilgen, M. A., K. R. Conner, K. M. Roeder, F. C. Blow, K. Austin, and M. Valenstein (2012). Patterns of treatment utilization before suicide among male veterans with substance use disorders. American Journal of Public Health\/ 102\/ (S1), S88--S92
2012
-
[14]
Jin, J., J. Yan, R. H. Aseltine, and K. Chen (2024). Transfer learning with large-scale quantile regression. Technometrics\/ , 1--30
2024
-
[15]
Kessler, R. C., M. S. Bauer, T. M. Bishop, O. V. Demler, S. K. Dobscha, S. M. Gildea, J. L. Goulet, E. Karras, J. Kreyenbuhl, S. J. Landes, et al. (2020). Using administrative data to predict suicide after psychiatric hospitalization in the veterans health administration system. Frontiers in Psychiatry\/ 11 , 390
2020
-
[16]
Kessler, R. C., G. Borges, and E. E. Walters (1999). Prevalence of and risk factors for lifetime suicide attempts in the national comorbidity survey. Archives of General Psychiatry\/ 56\/ (7), 617--626
1999
-
[17]
Labouliere, C. D., P. Vasan, A. Kramer, G. Brown, K. Green, M. Rahman, J. Kammer, M. Finnerty, and B. Stanley (2018). ``Zero Suicide''--a model for reducing suicide in United States behavioral healthcare. Suicidologi\/ 23\/ (1), 22
2018
-
[18]
Li, M., Y. Tian, Y. Feng, and Y. Yu (2024). Federated transfer learning with differential privacy. arXiv preprint arXiv:2403.11343\/
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Cai, and R
Li, S., T. Cai, and R. Duan (2023). Targeting underrepresented populations in precision medicine: A federated transfer learning approach. The Annals of Applied Statistics\/ 17\/ (4), 2970--2992
2023
-
[20]
Li, S., T. T. Cai, and H. Li (2022). Transfer learning for high-dimensional linear regression: Prediction, estimation and minimax optimality. Journal of the Royal Statistical Society Series B\/ 84\/ (1), 149--173
2022
-
[21]
Li, S., T. T. Cai, and H. Li (2023). Transfer learning in large-scale Gaussian graphical models with false discovery rate control. Journal of the American Statistical Association\/ 118\/ (543), 2171--2183
2023
-
[22]
Loh, P.-L. and M. J. Wainwright (2013). Regularized m-estimators with nonconvexity: Statistical and algorithmic theory for local optima. In Advances in Neural Information Processing Systems 26 , pp.\ 476--484
2013
-
[23]
Luoma, J. B., C. E. Martin, and J. L. Pearson (2002). Contact with mental health and primary care providers before suicide: a review of the evidence. American Journal of Psychiatry\/ 159\/ (6), 909--916
2002
- [24]
-
[25]
Negahban, S., B. Yu, M. J. Wainwright, and P. Ravikumar (2009). A unified framework for high-dimensional analysis of m -estimators with decomposable regularizers. Advances in Neural Information Processing Systems\/ 22
2009
-
[26]
Nock, M. K., G. Borges, E. J. Bromet, C. B. Cha, R. C. Kessler, and S. Lee (2008). Suicide and suicidal behavior. Epidemiologic Reviews\/ 30\/ (1), 133
2008
-
[27]
Reeve, H. W. J., T. I. Cannings, and R. J. Samworth (2021). Adaptive transfer learning. The Annals of Statistics\/ 49\/ (6), 3618--3649
2021
-
[28]
Ribeiro, J. D., J. C. Franklin, K. R. Fox, K. H. Bentley, E. M. Kleiman, B. P. Chang, and M. K. Nock (2016). Self-injurious thoughts and behaviors as risk factors for future suicide ideation, attempts, and death: a meta-analysis of longitudinal studies. Psychological Medicine\/ 46\/ (2), 225--236
2016
-
[29]
Rosenstein, M. T., Z. Marx, L. P. Kaelbling, and T. G. Dietterich (2005). To transfer or not to transfer. In NIPS 2005 workshop on transfer learning , Volume 898
2005
-
[30]
Sacco, S. J., K. Chen, F. Wang, and R. Aseltine (2023). Target-based fusion using social determinants of health to enhance suicide prediction with electronic health records. PLOS ONE\/ 18\/ (4), e0283595
2023
-
[31]
Shepard, D. (1968). A two-dimensional interpolation function for irregularly-spaced data. In Proceedings of the 1968 23rd ACM national conference , pp.\ 517--524
1968
-
[32]
Simon, G. E., E. Johnson, J. M. Lawrence, R. C. Rossom, B. Ahmedani, F. L. Lynch, A. Beck, B. Waitzfelder, R. Ziebell, R. B. Penfold, et al. (2018). Predicting suicide attempts and suicide deaths following outpatient visits using electronic health records. American Journal of Psychiatry\/ 175\/ (10), 951--960
2018
-
[33]
Stone, D. M. (2018). Vital signs: trends in state suicide rates--United States, 1999--2016 and circumstances contributing to suicide--27 states, 2015. MMWR: Morbidity and Mortality Weekly Report\/ 67
2018
-
[34]
Aseltine, R
Su, C., R. Aseltine, R. Doshi, K. Chen, S. C. Rogers, and F. Wang (2020). Machine learning for suicide risk prediction in children and adolescents with electronic health records. Translational Psychiatry\/ 10\/ (1), 413
2020
-
[35]
Suk, H.-I. and D. Shen (2014). Clustering-induced multi-task learning for AD/MCI classification. In Medical Image Computing and Computer-Assisted Intervention--MICCAI 2014: 17th International Conference, Boston, MA, USA, September 14-18, 2014, Proceedings, Part III 17 , pp.\ 393--400
2014
-
[36]
Suresh, H., J. J. Gong, and J. V. Guttag (2018). Learning tasks for multitask learning: Heterogenous patient populations in the ICU. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining , pp.\ 802--810
2018
-
[37]
Tian, Y. and Y. Feng (2023). Transfer learning under high-dimensional generalized linear models. Journal of the American Statistical Association\/ 118\/ (544), 2684--2697
2023
-
[38]
Tian, Y., H. Weng, and Y. Feng (2023). Unsupervised multi-task and transfer learning on Gaussian mixture models. arXiv preprint arXiv:2209.15224\/
-
[39]
Walsh, C. G., K. B. Johnson, M. Ripperger, S. Sperry, J. Harris, N. Clark, E. Fielstein, L. Novak, K. Robinson, and W. W. Stead (2021). Prospective validation of an electronic health record--based, real-time suicide risk model. JAMA Network Open\/ 4\/ (3), e211428--e211428
2021
-
[40]
Li, and J
Wang, W., Y. Li, and J. Yan (2021). Touch: Tools of utilization and cost in healthcare. R package version 2019. Available online at https://CRAN.R-project.org/package=touch. Accessed on 2022-07-08
2021
-
[41]
Wilimitis, D., R. W. Turer, M. Ripperger, A. B. McCoy, S. H. Sperry, E. M. Fielstein, T. Kurz, and C. G. Walsh (2022). Integration of face-to-face screening with real-time machine learning to predict risk of suicide among adults. JAMA Network Open\/ 5\/ (5), e2212095--e2212095
2022
-
[42]
Xu, W., C. Su, Y. Li, S. Rogers, F. Wang, K. Chen, and R. Aseltine (2022). Improving suicide risk prediction via targeted data fusion: proof of concept using medical claims data. Journal of the American Medical Informatics Association\/ 29\/ (3), 500--511
2022
-
[43]
Zang, C., Y. Hou, D. Lyu, J. Jin, S. Sacco, K. Chen, R. Aseltine, and F. Wang (2024). Accuracy and transportability of machine learning models for adolescent suicide prediction with longitudinal clinical records. Translational Psychiatry\/ 14\/ (1), 316
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.