ScholarQuest: A Taxonomy-Guided Benchmark for Agentic Academic Paper Search in Open Literature Environments
Pith reviewed 2026-06-26 15:37 UTC · model grok-4.3
The pith
A new benchmark for academic paper search shows agentic LLM methods beat simple retrieval but still miss most relevant papers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
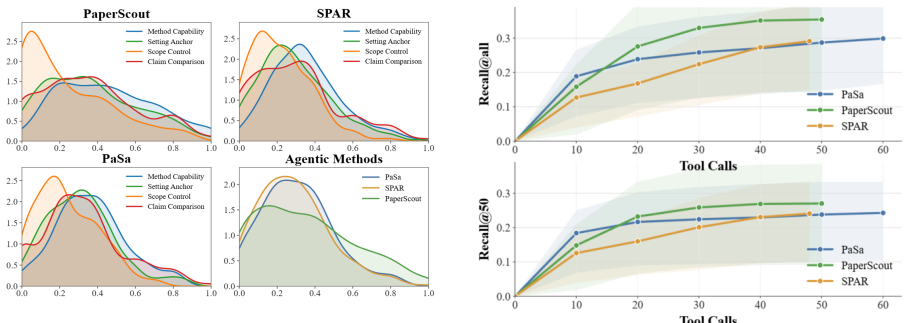
ScholarQuest demonstrates that agentic academic paper search outperforms single-shot baselines across method-oriented, setting-anchored, comparison-based, and scope-controlled intents, but the highest recall remains below 0.36 even when all retrieved papers are considered, and further analyses of efficiency, intent robustness, and failure modes expose consistent shortcomings in existing agents.
What carries the argument
Taxonomy-guided query construction from more than 1,000 CS topics combined with four representative intents and the shared ScholarBase retrieval backend for reproducible answer construction and evaluation.
If this is right
- Agentic iteration improves recall over single-shot retrieval on the tested intents.
- Even the best current agents leave most relevant papers unretrieved at practical cutoffs.
- The benchmark supplies separate signals on search efficiency, intent-level performance, and common failure patterns.
- A shared backend allows future agents to be evaluated without rebuilding the retrieval index.
Where Pith is reading between the lines
- The low recall ceiling suggests that advances in agent planning or better integration of external knowledge could produce measurable gains on this benchmark.
- Extending the same construction method beyond computer science topics would test whether the performance gap generalizes to other disciplines.
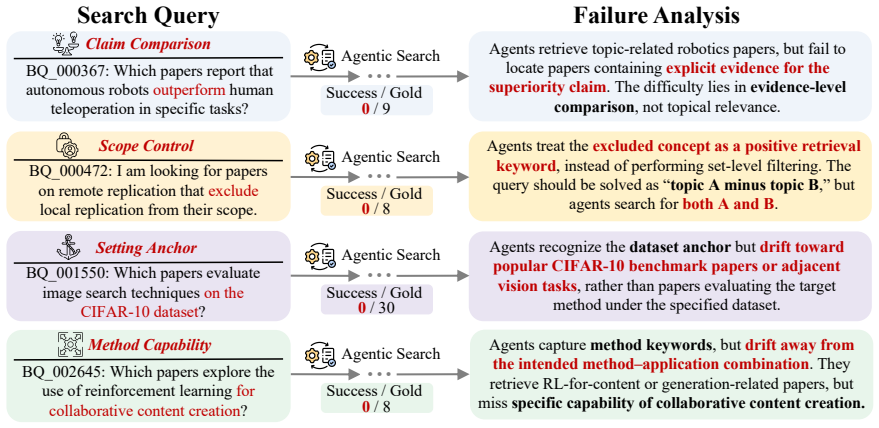
- Failure-case analysis in the benchmark could guide targeted improvements such as better handling of comparison queries.
Load-bearing premise
Queries built from the taxonomy and four intents accurately reflect the real search needs of researchers working in open literature.
What would settle it
A direct comparison of recall scores when the same agents are run on a fresh set of queries written by practicing researchers rather than the taxonomy-derived ones.
Figures


read the original abstract
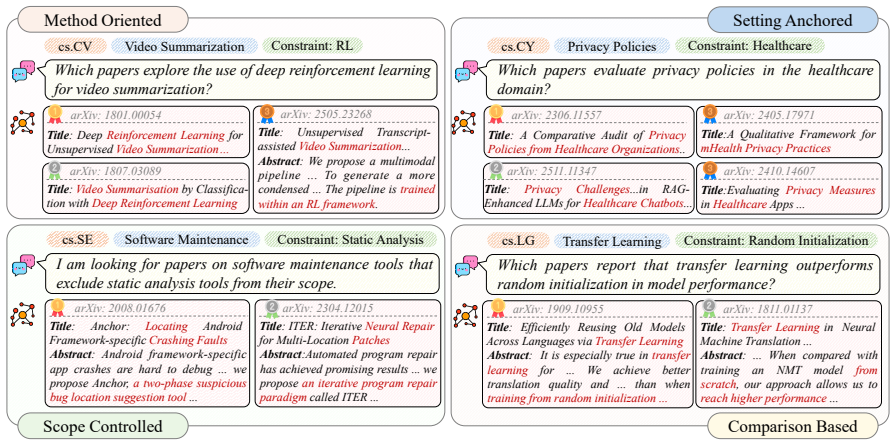
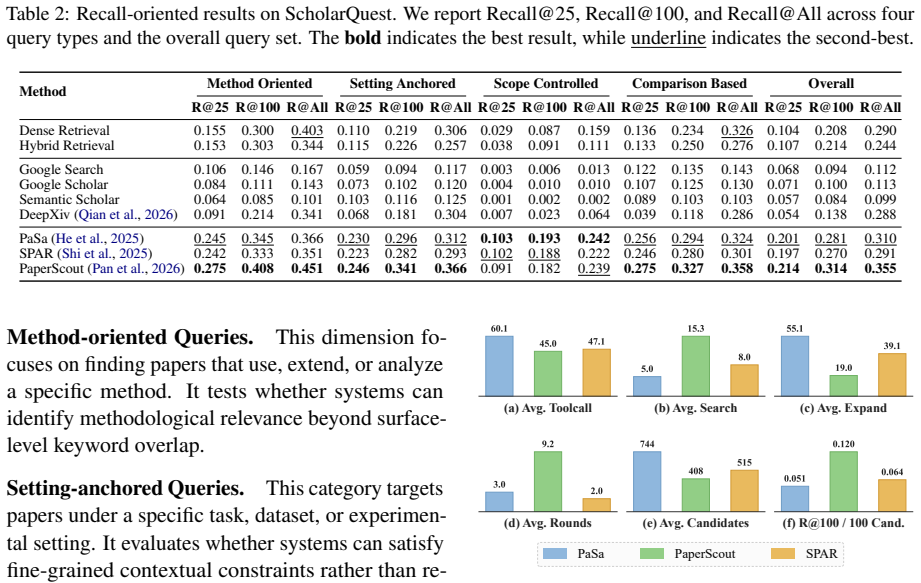
Academic paper search is a core step in scientific research, and LLM-based search agents are emerging as a promising paradigm for iterative, intent-driven literature exploration. However, existing benchmarks are insufficient for systematically evaluating agentic academic search under realistic open literature environments. We propose ScholarQuest, a large-scale, taxonomy-guided benchmark for agentic academic paper search. ScholarQuest is constructed from over 1,000 computer science topics and four representative research intents, including method-oriented, setting-anchored, comparison-based, and scope-controlled queries. It further provides scalable answer construction and a shared retrieval backend ScholarBase for reproducible evaluation. Benchmarking results show that agentic methods outperform single-shot retrieval baselines, yet the best-performing agent only achieves 0.314 Recall@100 and 0.355 Recall@All, indicating substantial room for improvement. In addition, analyses of search efficiency, intent-level robustness, and failure cases further highlight the benchmark's ability to provide multi-dimensional evaluation signals for academic paper search agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ScholarQuest, a large-scale benchmark for agentic academic paper search constructed from over 1,000 computer science topics and four representative intents (method-oriented, setting-anchored, comparison-based, scope-controlled). It supplies scalable answer construction and a shared retrieval backend (ScholarBase) for reproducible evaluation. Benchmarking shows agentic methods outperform single-shot retrieval baselines, but the best agent reaches only 0.314 Recall@100 and 0.355 Recall@All; additional analyses cover search efficiency, intent-level robustness, and failure cases.
Significance. If the query distribution is representative of real open-literature academic search, the benchmark and shared backend would constitute a useful standardized resource for evaluating iterative agentic retrieval, with the reported performance gap and multi-dimensional analyses providing concrete signals for future work. The reproducibility infrastructure is a clear strength.
major comments (2)
- [§3 (Benchmark Construction)] §3 (Benchmark Construction, as described in abstract): The taxonomy-guided queries are generated by sampling CS topics and instantiating four fixed intent templates, yet no user study, comparison against real query logs (e.g., Semantic Scholar or arXiv), or coverage analysis of the long tail of researcher needs is reported. This assumption is load-bearing for the central claims that agentic methods outperform baselines and that substantial room for improvement exists, because the headline recall figures are only meaningful if ScholarQuest accurately proxies realistic search distributions.
- [Evaluation section] Evaluation section (abstract and methods): The abstract reports concrete recall numbers and outperformance but provides insufficient detail on how ground-truth answer labels are constructed, verified for accuracy, or protected against bias in the shared ScholarBase backend. Without these specifics, it is not possible to confirm that the evaluation supports the stated claims.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below with clarifications and proposed revisions.
read point-by-point responses
-
Referee: [§3 (Benchmark Construction)] §3 (Benchmark Construction, as described in abstract): The taxonomy-guided queries are generated by sampling CS topics and instantiating four fixed intent templates, yet no user study, comparison against real query logs (e.g., Semantic Scholar or arXiv), or coverage analysis of the long tail of researcher needs is reported. This assumption is load-bearing for the central claims that agentic methods outperform baselines and that substantial room for improvement exists, because the headline recall figures are only meaningful if ScholarQuest accurately proxies realistic search distributions.
Authors: We agree that direct empirical validation against real query logs would strengthen claims of representativeness. The four intents were selected after reviewing common academic search patterns described in prior IR literature on scholarly search behaviors. Access to proprietary logs from Semantic Scholar or arXiv is not available to us, precluding direct comparison. In revision we will add a dedicated subsection in §3 that (a) justifies the intent templates with citations to existing taxonomies of research questions, (b) reports coverage statistics over the sampled CS topics, and (c) explicitly discusses the lack of a user study as a limitation of the current benchmark design. revision: partial
-
Referee: [Evaluation section] Evaluation section (abstract and methods): The abstract reports concrete recall numbers and outperformance but provides insufficient detail on how ground-truth answer labels are constructed, verified for accuracy, or protected against bias in the shared ScholarBase backend. Without these specifics, it is not possible to confirm that the evaluation supports the stated claims.
Authors: We apologize for the brevity in the current description. The revised manuscript will expand the Answer Construction and ScholarBase subsections to detail: the taxonomy-driven procedure for identifying candidate papers, the verification protocol (including sample manual review and cross-validation across retrieval methods), and safeguards against bias (fixed public backend snapshot, no overlap with any training data). These additions will make the evaluation pipeline fully reproducible and transparent. revision: yes
Circularity Check
No circularity: benchmark construction and evaluation are self-contained.
full rationale
The paper constructs ScholarQuest by sampling from over 1,000 external CS topics and instantiating four fixed intent templates, then evaluates agents against single-shot baselines on a shared external backend (ScholarBase). No equations, fitted parameters, or predictions reduce to the paper's own inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The outperformance claim and room-for-improvement conclusion rest on direct empirical comparisons within the newly defined benchmark rather than any self-referential derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The four research intents (method-oriented, setting-anchored, comparison-based, scope-controlled) represent key aspects of academic paper search.
invented entities (2)
-
ScholarQuest benchmark
no independent evidence
-
ScholarBase
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Nursing standard , volume=
How to conduct an effective literature search , author=. Nursing standard , volume=
-
[2]
Communications of the ACM , volume=
Exploratory search: from finding to understanding , author=. Communications of the ACM , volume=. 2006 , publisher=
2006
-
[3]
arXiv preprint arXiv:2603.00084 , year=
DeepXiv-SDK: An Agentic Data Interface for Scientific Literature , author=. arXiv preprint arXiv:2603.00084 , year=
-
[4]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[5]
arXiv preprint arXiv:2507.15245 , year=
Spar: Scholar paper retrieval with llm-based agents for enhanced academic search , author=. arXiv preprint arXiv:2507.15245 , year=
-
[6]
arXiv preprint arXiv:2601.10029 , year=
Paperscout: An autonomous agent for academic paper search with process-aware sequence-level policy optimization , author=. arXiv preprint arXiv:2601.10029 , year=
-
[7]
Research synthesis methods , volume=
Which academic search systems are suitable for systematic reviews or meta-analyses? Evaluating retrieval qualities of Google Scholar, PubMed, and 26 other resources , author=. Research synthesis methods , volume=. 2020 , publisher=
2020
-
[8]
arXiv preprint arXiv:2501.10120 , year=
Pasa: An llm agent for comprehensive academic paper search , author=. arXiv preprint arXiv:2501.10120 , year=
-
[9]
Communications of the ACM , volume=
Major update to ACM's computing classification system , author=. Communications of the ACM , volume=. 2012 , publisher=
2012
-
[10]
arXiv preprint arXiv:2402.03216 , volume=
Bge m3-embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation , author=. arXiv preprint arXiv:2402.03216 , volume=
-
[11]
Mathematical contributions to the theory of evolution.—III
VII. Mathematical contributions to the theory of evolution.—III. Regression, heredity, and panmixia , author=. Philosophical Transactions of the Royal Society of London. Series A, containing papers of a mathematical or physical character , number=. 1896 , publisher=
-
[12]
, author=
Weighted kappa: Nominal scale agreement provision for scaled disagreement or partial credit. , author=. Psychological bulletin , volume=. 1968 , publisher=
1968
-
[13]
, author=
The proof and measurement of association between two things. , author=. 1961 , publisher=
1961
-
[14]
arXiv preprint arXiv:2510.10909 , year=
Paperarena: An evaluation benchmark for tool-augmented agentic reasoning on scientific literature , author=. arXiv preprint arXiv:2510.10909 , year=
-
[15]
arXiv preprint arXiv:2503.09516 , year=
Search-r1: Training llms to reason and leverage search engines with reinforcement learning , author=. arXiv preprint arXiv:2503.09516 , year=
-
[16]
arXiv preprint arXiv:2601.04879 , year=
Mind2Report: A Cognitive Deep Research Agent for Expert-Level Commercial Report Synthesis , author=. arXiv preprint arXiv:2601.04879 , year=
-
[17]
Proceedings of the 32nd international ACM SIGIR conference on Research and development in information retrieval , pages=
Reciprocal rank fusion outperforms condorcet and individual rank learning methods , author=. Proceedings of the 32nd international ACM SIGIR conference on Research and development in information retrieval , pages=
-
[18]
1995 , publisher=
Overview of the third text retrieval conference (TREC-3) , author=. 1995 , publisher=
1995
-
[19]
S 2 ORC : The Semantic Scholar Open Research Corpus
Lo, Kyle and Wang, Lucy Lu and Neumann, Mark and Kinney, Rodney and Weld, Daniel. S 2 ORC : The Semantic Scholar Open Research Corpus. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.447
-
[20]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[21]
Publications Manual , year = "1983", publisher =
1983
-
[22]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[23]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of. 2007 , url=
2007
-
[24]
Dan Gusfield , title =. 1997
1997
-
[25]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[26]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =. 2005 , url=
2005
-
[27]
and Tukey, John W
Cooley, James W. and Tukey, John W. , journal=. An algorithm for the machine calculation of complex. 1965 , url=
1965
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.