Scaling State-Space Models from Lines to Paragraphs: An Ablation of Mamba-based OCR
Pith reviewed 2026-06-26 08:44 UTC · model grok-4.3
The pith
Mamba-based OCR matches transformers below 1% CER on synthetic paragraphs while running 1.4 to 4.5 times faster, but lags on real handwriting mainly because its autoregressive decoder requires more data for long sequences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
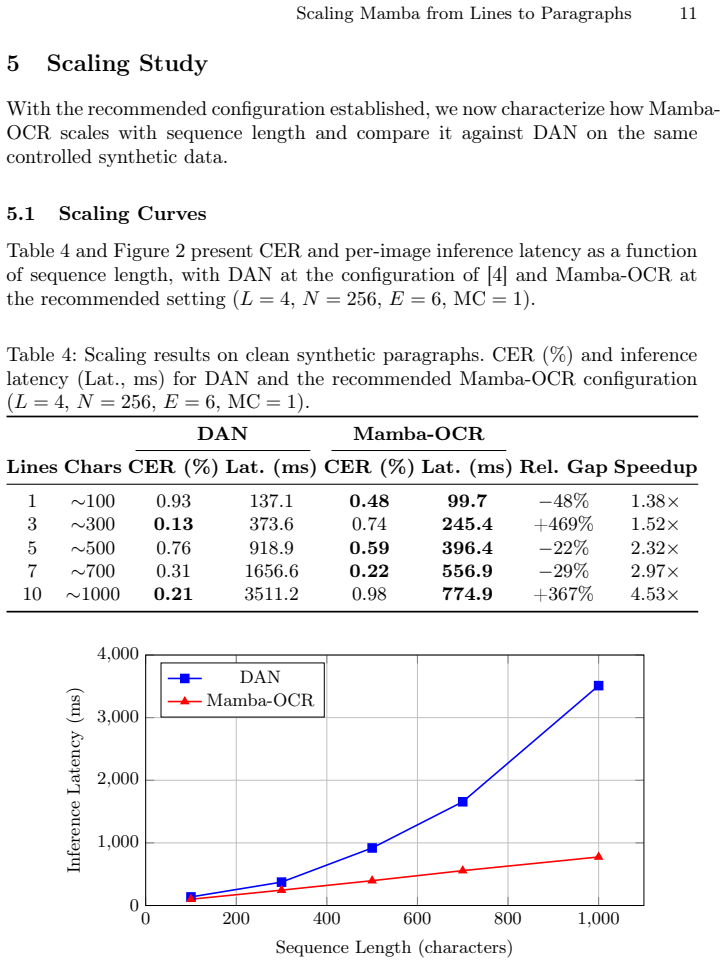
On clean synthetic paragraphs both the Mamba SSM and the Transformer baseline achieve below 1% CER across lengths from 100 to 1000 characters, with the SSM running 1.4 to 4.5 times faster as length increases. On IAM handwriting the SSM reaches 8.2% CER on lines and 10.0% on paragraphs compared to 4.2% and 3.5% for the Transformer. Controlled experiments attribute a substantial part of the gap to data scarcity, showing the autoregressive SSM decoder is markedly data-hungry on long sequences.
What carries the argument
The autoregressive Mamba decoder whose recurrent state dimension and expansion factor serve as the dominant levers for accuracy on long OCR sequences.
If this is right
- SSMs deliver linear-time decoding whose speed advantage over quadratic attention grows with paragraph length on clean data.
- Tuning the recurrent state dimension and expansion factor enables SSMs to maintain low error rates as sequence length increases.
- A substantial share of the real-data accuracy gap disappears when data volume is increased, indicating the SSM architecture itself is not the limiting factor.
- SSMs become a practical choice for large-scale document transcription once sufficient training data for long sequences is available.
Where Pith is reading between the lines
- Larger real handwriting corpora could allow Mamba OCR to match Transformer accuracy without architectural changes.
- Data-augmentation or efficiency techniques aimed at long-sequence SSM decoders might broaden their use in data-limited handwriting domains.
- The same scaling and data-ablation approach could be applied to other long-sequence vision-language tasks to map where SSMs are data-efficient.
Load-bearing premise
The controlled experiments isolate data scarcity as the primary cause of the performance gap on real handwriting rather than differences in optimization or model capacity.
What would settle it
Train the Mamba OCR model on a substantially larger real handwriting paragraph dataset and measure whether its CER on IAM paragraphs approaches the Transformer's 3.5%.
Figures
read the original abstract
End-to-end OCR increasingly relies on autoregressive sequence models, where the quadratic cost of Transformer attention limits efficient transcription of long, paragraph-level text. State-Space Models (SSMs) such as Mamba offer linear-time decoding and have recently been shown to match Transformer accuracy on printed historical lines, but their behavior as sequences grow from short lines to full paragraphs, and their generalization to handwriting, remain poorly understood. We study how a Mamba-based OCR recognizer scales from lines to paragraphs. We first conduct a systematic exploration of its four core hyperparameters (decoder depth, state dimension, expansion factor, and connector depth) on synthetic paragraphs from 100 to 1,000 characters, identifying the recurrent state dimension and the expansion factor as the dominant levers for long-sequence accuracy. We then compare the recognizer against a Transformer baseline trained under an identical protocol. On clean synthetic paragraphs, both models stay below 1% CER at every length while the SSM runs 1.4 to 4.5 times faster, the speedup growing with sequence length. On real handwriting, however, the SSM lags clearly behind: it reaches 8.2% CER on IAM lines and 10.0% on IAM paragraphs, against 4.2% and 3.5% for the Transformer baseline. Through controlled experiments we show that a substantial part of this gap stems from data scarcity rather than from an intrinsic architectural limit: the autoregressive SSM decoder is markedly data-hungry on long sequences. Our study clarifies when SSMs are a practical choice for large-scale document transcription and when they are not.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that Mamba-based SSMs for end-to-end OCR match Transformer accuracy (<1% CER) on clean synthetic paragraphs of 100-1000 characters while delivering 1.4-4.5x speedups that increase with length, after identifying state dimension and expansion factor as the dominant hyperparameters via ablation of decoder depth, state dimension, expansion factor, and connector depth. On real IAM handwriting the SSM underperforms (8.2% CER on lines, 10.0% on paragraphs vs. 4.2% and 3.5% for the Transformer), with the gap attributed to the autoregressive SSM decoder being markedly data-hungry on long sequences, as shown by controlled experiments.
Significance. If the controlled-experiment results hold, the work supplies concrete guidance on when linear-time SSMs are practical for paragraph-level document transcription versus when data requirements make them inferior to quadratic-attention models. The systematic hyperparameter study on synthetic data and the direct speed/accuracy comparison constitute reusable empirical benchmarks for long-sequence OCR architectures.
major comments (2)
- [Abstract] Abstract: the attribution that 'a substantial part of this gap stems from data scarcity rather than from an intrinsic architectural limit' rests on 'controlled experiments' whose design (matching of optimizer, learning-rate schedule, data augmentation, and effective capacity while varying only training-set size) is not described, so the causal claim that the SSM decoder is 'markedly data-hungry' cannot be evaluated from the supplied text.
- [IAM results paragraph] IAM results paragraph: without the quantitative outcomes or protocol details of the controlled experiments that vary training-set size, it is impossible to confirm that the observed 8.2–10.0% vs. 3.5–4.2% CER gap is isolated to data scarcity rather than unaccounted differences in optimization or capacity, which is load-bearing for the paper's main practical conclusion.
minor comments (2)
- [Hyperparameter ablation section] The ranges and grid used for the four core hyperparameters should be tabulated so readers can reproduce the ablation that identified state dimension and expansion factor as dominant.
- [Synthetic paragraphs results] Specify the exact sequence lengths at which the 1.4x and 4.5x speedups were measured.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive comments. We agree that the description of the controlled experiments is insufficient in the current manuscript and will expand the text to include the full protocol and quantitative results. This addresses the core concern about evaluating the data-scarcity claim.
read point-by-point responses
-
Referee: [Abstract] Abstract: the attribution that 'a substantial part of this gap stems from data scarcity rather than from an intrinsic architectural limit' rests on 'controlled experiments' whose design (matching of optimizer, learning-rate schedule, data augmentation, and effective capacity while varying only training-set size) is not described, so the causal claim that the SSM decoder is 'markedly data-hungry' cannot be evaluated from the supplied text.
Authors: We agree that the current text does not describe the controlled-experiment protocol. In the revision we will add a dedicated subsection (under the IAM experiments) that specifies: (i) the exact optimizer and learning-rate schedule used for both models, (ii) the data-augmentation pipeline, (iii) how effective capacity was matched (parameter count and state/expansion settings), and (iv) the training-set sizes varied while holding all other factors fixed. The subsection will also report the resulting CER curves, allowing readers to assess the claim that the SSM decoder is markedly data-hungry on long sequences. revision: yes
-
Referee: [IAM results paragraph] IAM results paragraph: without the quantitative outcomes or protocol details of the controlled experiments that vary training-set size, it is impossible to confirm that the observed 8.2–10.0% vs. 3.5–4.2% CER gap is isolated to data scarcity rather than unaccounted differences in optimization or capacity, which is load-bearing for the paper's main practical conclusion.
Authors: We accept this criticism. The revised IAM results paragraph will be accompanied by the quantitative outcomes (CER vs. training-set size) and the complete protocol details listed above. These additions will make explicit that the performance gap is isolated to data requirements under matched optimization and capacity conditions, thereby supporting the paper's practical conclusion. revision: yes
Circularity Check
No circularity: results are direct empirical measurements
full rationale
The paper reports ablation studies, hyperparameter sweeps, and direct CER/speed comparisons between Mamba-based and Transformer OCR models on synthetic and real handwriting data. All load-bearing claims (accuracy scaling, speedup factors, performance gap on IAM) are presented as outcomes of training and evaluation protocols rather than derivations, fitted parameters renamed as predictions, or self-citation chains. The attribution of the real-data gap to data scarcity is framed as an interpretation of controlled experiments; no equations, uniqueness theorems, or ansatzes are invoked that would reduce the reported results to their own inputs by construction. This is a standard empirical study whose central claims remain independently falsifiable via replication of the training runs.
Axiom & Free-Parameter Ledger
free parameters (4)
- decoder depth
- state dimension
- expansion factor
- connector depth
axioms (2)
- domain assumption The training protocol is identical and fair for both Mamba and Transformer models.
- domain assumption Synthetic data adequately represents the scaling behavior for real-world OCR tasks.
Reference graph
Works this paper leans on
-
[1]
transformers and BiLSTM-based models for historical newspaper OCR
Agbeti-Messan, M., et al.: A benchmark of state-space models vs. transformers and BiLSTM-based models for historical newspaper OCR. arXiv preprint (2026)
2026
-
[2]
In: ICDAR (2017)
Bluche, T., et al.: Gated convolutional recurrent neural networks for multilingual handwriting recognition. In: ICDAR (2017)
2017
-
[3]
IJDAR (2025)
Constum, T., et al.: DANIEL: A fast document attention network for information extraction and labelling of handwritten documents. IJDAR (2025)
2025
-
[4]
TPAMI (2023)
Coquenet, D., et al.: DAN: A segmentation-free document attention network for handwritten document recognition. TPAMI (2023)
2023
-
[5]
TPAMI (2023)
Coquenet, D., et al.: End-to-end handwritten paragraph text recognition using a vertical attention network. TPAMI (2023)
2023
-
[6]
Google: Gemini (gemini-2.0-flash-001 version) [large language model] (2025)
2025
-
[7]
In: COLM (2024)
Gu, A., et al.: Mamba: Linear-time sequence modeling with selective state spaces. In: COLM (2024)
2024
-
[8]
IMPACT Centre of Competence: IMPACT dataset of historical newspapers (2011)
2011
-
[9]
arXiv preprint (2026)
Kim, C., et al.: DRetHTR: Linear-time decoder-only retentive network for hand- written text recognition. arXiv preprint (2026)
2026
-
[10]
In: AAAI (2023)
Li, M., et al.: TrOCR: Transformer-based optical character recognition with pre- trained models. In: AAAI (2023)
2023
-
[11]
IJDAR (2002)
Marti, U.V., et al.: The IAM-database: an English sentence database for offline handwriting recognition. IJDAR (2002)
2002
-
[12]
Journal of Documentation (2019)
Muehlberger, G., et al.: Transforming scholarship in the archives through hand- written text recognition: Transkribus as a case study. Journal of Documentation (2019)
2019
-
[13]
Puigcerver, J., et al.: Are multidimensional recurrent layers really necessary for handwritten text recognition? In: ICDAR (2017)
2017
-
[14]
arXiv preprint (2023)
Sun, Y., et al.: Retentive Network: A successor to Transformer for large language models. arXiv preprint (2023)
2023
-
[15]
In: ICFHR (2016)
Voigtlaender, P., et al.: Handwriting recognition with large multidimensional long short-term memory recurrent neural networks. In: ICFHR (2016)
2016
-
[16]
In: ICLR (2025)
Yang, S., et al.: Gated Delta Networks: Improving Mamba2 with Delta Rule. In: ICLR (2025)
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.