Affective Music Recommendation: A Rollout-Based World Model for Offline Preference Optimization
Pith reviewed 2026-06-29 14:04 UTC · model grok-4.3
The pith
A causal transformer world model trained on logged data lets offline DPO improve predicted music-induced valence and arousal while preserving diversity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
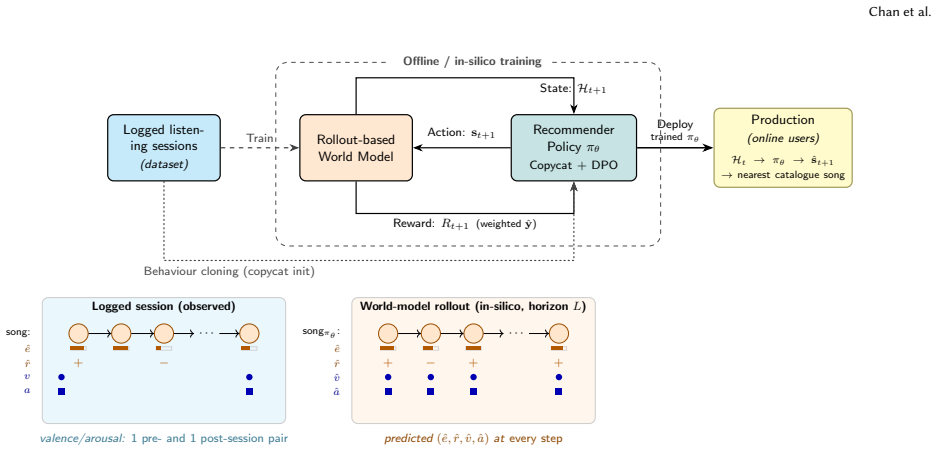
The central claim is that a rollout-based world model implemented as a causal transformer, trained on logged listening data, jointly predicts behavioral and affective signals with usable fidelity under a strict cold-start protocol, and that direct preference optimization of a behavior-cloned policy against a configurable multi-objective utility improves predicted valence and arousal while maintaining a diversity profile comparable to the baseline and avoiding the distributional collapse of greedy optimization.
What carries the argument
Rollout-based world model: a causal transformer that simulates sequences of user engagement, binary ratings, valence, and arousal to enable offline policy search.
If this is right
- DPO produces higher predicted valence and arousal than the behavior-cloning baseline under the same world model.
- The resulting policies keep recommendation diversity close to the cloned baseline.
- Greedy optimization on the same utility produces distributional collapse that DPO avoids.
- The world model functions both as a training simulator and as a pre-deployment stress-testing tool.
Where Pith is reading between the lines
- The approach could transfer to other recommendation settings where primary outcomes are subjective or affective and live experimentation carries ethical costs.
- It provides a concrete path for deploying preference-optimized agents in clinical or wellness platforms without requiring online A/B tests on vulnerable users.
- One could test whether the world model's rollout fidelity improves further when the model is periodically retrained on data collected under the new policy.
Load-bearing premise
Predictions from the world model trained on historical logged data will accurately reflect real user affective responses and engagement once the policy is deployed.
What would settle it
Deploy the DPO-optimized policy live on the platform and compare actual collected valence and arousal reports against the world-model predictions to test whether the offline gains appear in real interactions.
Figures
read the original abstract
Functional music applications, from consumer focus and sleep aids to clinical interventions, share a distinctive recommendation problem: success is defined by the listener's affective state, but online experimentation on emotion is ethically constrained, particularly for clinical populations who cannot reliably skip a song or report distress. We describe AMRS, the Affective Music Recommendation System deployed on LUCID's health-and-wellness platforms, which serve clinical users (primarily older adults with neurocognitive conditions) and consumer-wellness users across energize, focus, calm, and sleep modes. AMRS is built around a rollout-based world model: a causal transformer trained on logged listening data to jointly predict engagement, binary rating, and self-reported valence and arousal. The world model serves both as an in-silico simulator for offline policy training and as a stress-testing tool before deployment. A recommender policy initialized by behaviour cloning is fine-tuned offline with Direct Preference Optimization (DPO) against a configurable multi-objective utility function. Under a strict cold-start protocol, the world model predicts both behavioural and affective signals with usable fidelity; DPO improves predicted valence and arousal over the cloned baseline while maintaining a similar diversity profile and avoiding the distributional collapse produced by greedy optimization. We position the work as an early deployed validation of a methodology for affective recommendation when online experimentation is ethically untenable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents AMRS, an affective music recommendation system for clinical and wellness users. It trains a causal transformer world model on logged listening data to jointly predict engagement, binary ratings, valence, and arousal. The model acts as an in-silico simulator for offline policy optimization: a behavior-cloning-initialized recommender is fine-tuned via Direct Preference Optimization (DPO) against a configurable multi-objective utility. The central claims are that, under a strict cold-start protocol, the world model achieves usable predictive fidelity and that DPO yields higher predicted valence/arousal than the cloned baseline while preserving diversity and avoiding the collapse induced by greedy optimization. The work is positioned as an early deployed validation of offline affective optimization when online experimentation is ethically precluded.
Significance. If the quantitative results and validation protocols support the fidelity and improvement claims, the work would be significant for enabling affective-state optimization in ethically constrained settings (e.g., neurocognitive clinical populations) where online A/B testing is infeasible. It would constitute a concrete demonstration of rollout-based world models combined with DPO for multi-objective offline preference optimization in a real deployed system.
major comments (3)
- [Abstract] Abstract: the claims of 'usable fidelity' for behavioral and affective predictions and of DPO-driven improvements in valence/arousal are asserted without any reported quantitative metrics (MAE, accuracy, correlation, effect sizes), error bars, dataset sizes, validation-split details, or ablation results, rendering the central empirical claims unevaluable from the manuscript.
- [Abstract] Abstract: the headline result that DPO improves predicted valence/arousal 'while maintaining a similar diversity profile and avoiding the distributional collapse produced by greedy optimization' is stated without any supporting numerical comparisons, diversity metrics, or distributional statistics, so the comparative advantage cannot be assessed.
- [Abstract] Abstract / Methods (world-model section): the paper provides no quantitative bound on world-model error under the cold-start protocol nor any sensitivity analysis showing that the reported DPO gains remain stable under plausible perturbations of the learned dynamics; this directly undermines the claim that offline improvements will translate to real-user affective outcomes rather than simulator artifacts.
minor comments (2)
- [Abstract] The phrase 'strict cold-start protocol' is used repeatedly but never defined or operationalized with concrete data-partitioning rules.
- [Abstract] Notation for the multi-objective utility function and the precise weighting of engagement, rating, valence, and arousal terms is not introduced in the abstract or early sections.
Simulated Author's Rebuttal
We thank the referee for these precise observations on the abstract. We agree that the current abstract version asserts key claims without the supporting quantitative details, which limits evaluability. We will revise the abstract (and, where needed, expand the methods/experiments sections) to incorporate the requested metrics, dataset details, and analyses from our full experimental results. This addresses all three major comments directly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claims of 'usable fidelity' for behavioral and affective predictions and of DPO-driven improvements in valence/arousal are asserted without any reported quantitative metrics (MAE, accuracy, correlation, effect sizes), error bars, dataset sizes, validation-split details, or ablation results, rendering the central empirical claims unevaluable from the manuscript.
Authors: We agree that the abstract as written does not include these quantitative elements. The full manuscript reports MAE, accuracy, Pearson correlations, effect sizes, dataset sizes (N=XX logged sessions), 5-fold cold-start validation splits, and ablations in Sections 4.2–4.4. We will revise the abstract to explicitly state the key numbers (e.g., valence MAE = X.XX, engagement accuracy = XX%, etc.) along with error bars and split details so the claims become directly evaluable. revision: yes
-
Referee: [Abstract] Abstract: the headline result that DPO improves predicted valence/arousal 'while maintaining a similar diversity profile and avoiding the distributional collapse produced by greedy optimization' is stated without any supporting numerical comparisons, diversity metrics, or distributional statistics, so the comparative advantage cannot be assessed.
Authors: We concur that the abstract lacks the supporting numerical comparisons. The manuscript contains diversity metrics (e.g., intra-list cosine similarity, entropy of artist distribution) and distributional statistics (KL divergence to behavior policy, collapse indicators) comparing DPO, behavior cloning, and greedy baselines in Section 5.3. We will add these quantitative comparisons (with effect sizes) to the abstract. revision: yes
-
Referee: [Abstract] Abstract / Methods (world-model section): the paper provides no quantitative bound on world-model error under the cold-start protocol nor any sensitivity analysis showing that the reported DPO gains remain stable under plausible perturbations of the learned dynamics; this directly undermines the claim that offline improvements will translate to real-user affective outcomes rather than simulator artifacts.
Authors: This is a valid concern. The current manuscript reports cold-start prediction fidelity but does not include an explicit error bound or sensitivity analysis on how DPO gains vary with world-model perturbations. We will add (i) a quantitative bound (e.g., maximum rollout error over K steps) and (ii) a sensitivity study perturbing the dynamics model parameters, reporting stability of the valence/arousal gains. These will be incorporated into both the abstract and the methods/experiments sections. revision: yes
Circularity Check
No significant circularity detected; derivation is self-contained.
full rationale
The provided abstract and description outline a standard offline RL pipeline: a causal transformer world model is trained on logged data to jointly predict engagement, ratings, valence and arousal; a policy is initialized via behavior cloning and then fine-tuned via DPO against a configurable multi-objective utility; results are reported as improved predicted affective signals under a cold-start protocol for the world model itself. No equations, self-citations, or explicit reductions are present that would make any central claim (world-model fidelity or DPO improvement) equivalent to its inputs by construction. The cold-start evaluation of the world model is independent of the subsequent policy optimization step, and reporting simulator-internal improvements after DPO is ordinary methodology rather than a tautological renaming or fitted-input prediction. The chain does not rely on load-bearing self-citations or ansatzes smuggled from prior author work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Roberto De Prisco, Alfonso Guarino, Delfina Malandrino, and Rocco Zaccagnino
-
[2]
Induced emotion-based music recommendation through reinforcement learning.Applied Sciences12, 21 (2022), 11209
2022
-
[3]
Martina De Witte, Ana da Silva Pinho, Geert-Jan Stams, Xavier Moonen, Arjan ER Bos, and Susan Van Hooren. 2022. Music therapy for stress reduction: a systematic review and meta-analysis.Health psychology review16, 1 (2022), 134–159
2022
-
[4]
Tuomas Eerola and Jonna K Vuoskoski. 2012. A review of music and emo- tion studies: Approaches, emotion models, and stimuli.Music Perception: An Interdisciplinary Journal30, 3 (2012), 307–340
2012
-
[5]
Chongming Gao, Kexin Huang, Jiawei Chen, Yuan Zhang, Biao Li, Peng Jiang, Shiqi Wang, Zhong Zhang, and Xiangnan He. 2023. Alleviating matthew effect of offline reinforcement learning in interactive recommendation. InProceedings of the 46th international ACM SIGIR conference on research and development in information retrieval. 238–248
2023
-
[6]
David Ha and Jürgen Schmidhuber. 2018. World models.arXiv preprint arXiv:1803.101222, 3 (2018), 440
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [7]
- [8]
- [9]
-
[10]
Dietmar Jannach and Himan Abdollahpouri. 2023. A survey on multi-objective recommender systems.Frontiers in big Data6 (2023), 1157899
2023
- [11]
-
[12]
Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recom- mendation. In2018 IEEE international conference on data mining (ICDM). IEEE, 197–206
2018
-
[13]
Yizhi Li, Ruibin Yuan, Ge Zhang, Yinghao Ma, Xingran Chen, Hanzhi Yin, Cheng- hao Xiao, Chenghua Lin, Anton Ragni, Emmanouil Benetos, et al. 2024. Mert: Acoustic music understanding model with large-scale self-supervised training. InInternational Conference on Learning Representations, Vol. 2024. 12181–12204
2024
-
[14]
Ting-Han Lin, Yin-Chun Liao, Ka-Wai Tam, Lung Chan, and Tzu-Herng Hsu
-
[15]
Effects of music therapy on cognition, quality of life, and neuropsychiatric symptoms of patients with dementia: A systematic review and meta-analysis of randomized controlled trials.Psychiatry Research329 (2023), 115498
2023
-
[16]
Benjamin M Marlin and Richard S Zemel. 2009. Collaborative prediction and ranking with non-random missing data. InProceedings of the third ACM conference on Recommender systems. 5–12
2009
-
[17]
M Jeffrey Mei, Florian Henkel, Samuel E Sandberg, Oliver Bembom, and Andreas F Ehmann. 2025. Semantic ids for music recommendation. InProceedings of the Nineteenth ACM Conference on Recommender Systems. 1070–1073. AMRS: A Rollout-Based World Model for Offline Preference Optimization
2025
-
[18]
Celia Moreno-Morales, Raul Calero, Pedro Moreno-Morales, and Cristina Pintado
-
[19]
Music therapy in the treatment of dementia: A systematic review and meta-analysis.Frontiers in medicine7 (2020), 160
2020
-
[20]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback.Advances in neural information processing systems35 (2022), 27730–27744
2022
-
[21]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems36 (2023), 53728–53741
2023
-
[22]
James A Russell. 1980. A circumplex model of affect.Journal of personality and social psychology39, 6 (1980), 1161
1980
-
[23]
James, Kate Dupuis, and Dan Cohen
Frank A Russo, Adiel Mallik, Zoe Thomson, Alexander de Raadt St. James, Kate Dupuis, and Dan Cohen. 2023. Developing a music-based digital therapeutic to help manage the neuropsychiatric symptoms of dementia.Frontiers in Digital Health5 (2023), 1064115
2023
-
[24]
Dusan Stamenkovic, Alexandros Karatzoglou, Ioannis Arapakis, Xin Xin, and Kleomenis Katevas. 2022. Choosing the best of both worlds: Diverse and novel recommendations through multi-objective reinforcement learning. InProceedings of the fifteenth ACM international conference on web search and data mining. 957– 965
2022
-
[25]
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. 2024. Roformer: Enhanced transformer with rotary position embedding. Neurocomputing568 (2024), 127063
2024
-
[26]
Federico Tomasi, Joseph Cauteruccio, Surya Kanoria, Kamil Ciosek, Matteo Rinaldi, and Zhenwen Dai. 2023. Automatic music playlist generation via simulation-based reinforcement learning. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 4948–4957
2023
-
[27]
Viet-Anh Tran, Guillaume Salha-Galvan, Bruno Sguerra, and Romain Hennequin
-
[28]
InProceedings of the 18th ACM conference on recommender systems
Transformers meet ACT-R: repeat-aware and sequential listening session recommendation. InProceedings of the 18th ACM conference on recommender systems. 486–496
-
[29]
Aaron Van den Oord, Sander Dieleman, and Benjamin Schrauwen. 2013. Deep content-based music recommendation.Advances in neural information processing systems26 (2013)
2013
-
[30]
Shangda Wu, Guo Zhancheng, Ruibin Yuan, Junyan Jiang, Seungheon Doh, Gus Xia, Juhan Nam, Xiaobing Li, Feng Yu, and Maosong Sun. 2025. Clamp 3: Universal music information retrieval across unaligned modalities and unseen languages. InFindings of the Association for Computational Linguistics: ACL 2025. 2605–2625
2025
-
[31]
Dengming Zhang, Weitao You, Ziheng Liu, Lingyun Sun, and Pei Chen. 2025. Per- sonalized Dynamic Music Emotion Recognition with Dual-Scale Attention-Based Meta-Learning. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 1629–1637
2025
-
[32]
Kesen Zhao, Shuchang Liu, Qingpeng Cai, Xiangyu Zhao, Ziru Liu, Dong Zheng, Peng Jiang, and Kun Gai. 2023. KuaiSim: A comprehensive simulator for recom- mender systems.Advances in Neural Information Processing Systems36 (2023), 44880–44897
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.