ProfileFoundry: A Synthetic Person-Object Substrate for Privacy, Memory, and Tool-Use Evaluation in LLM Agent
Pith reviewed 2026-06-26 01:19 UTC · model grok-4.3
The pith
ProfileFoundry supplies 100,000 synthetic person objects with enforced consistency for LLM evaluations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
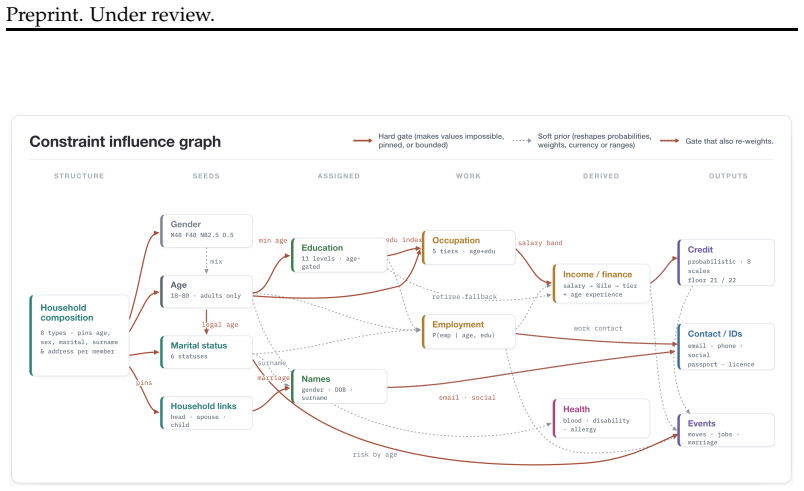
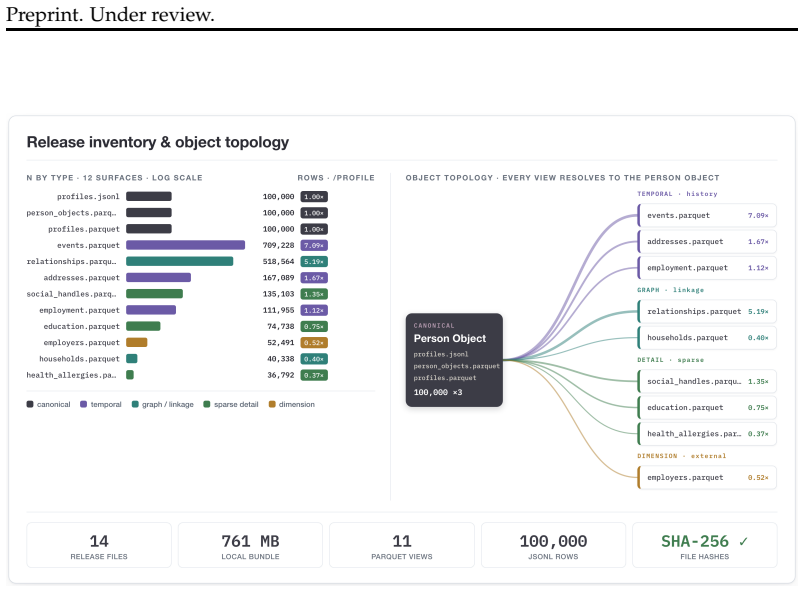
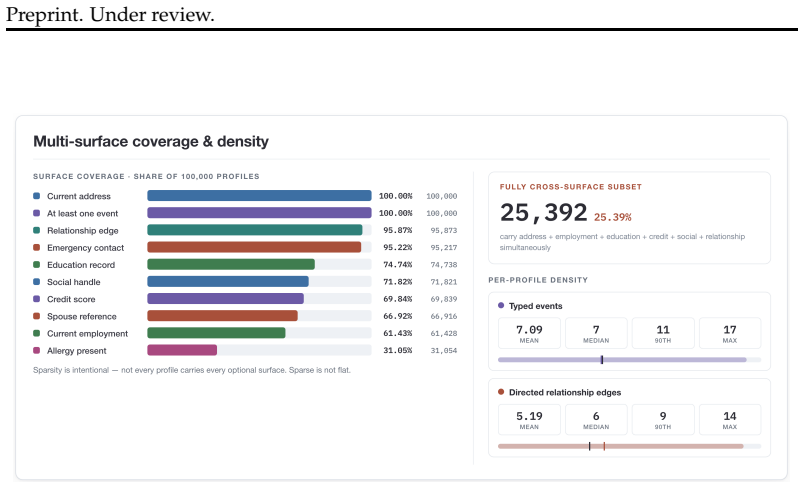
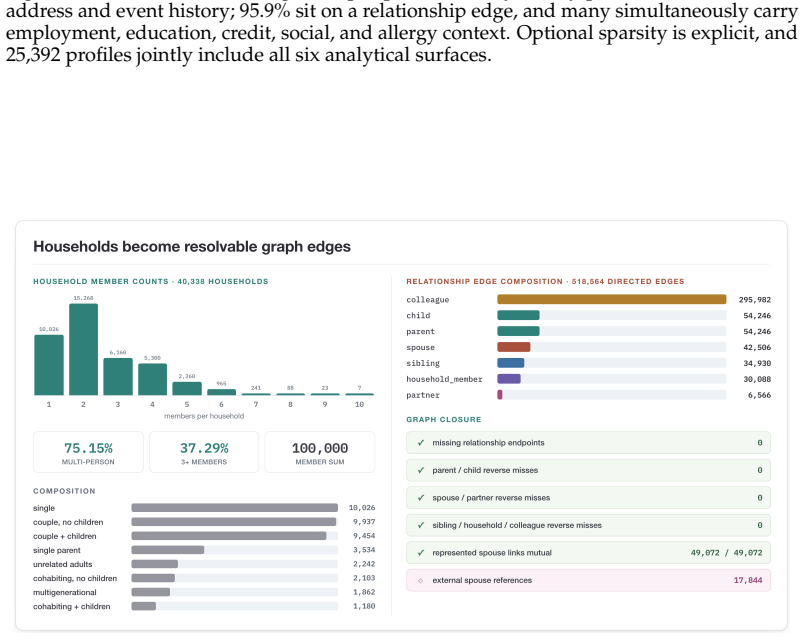
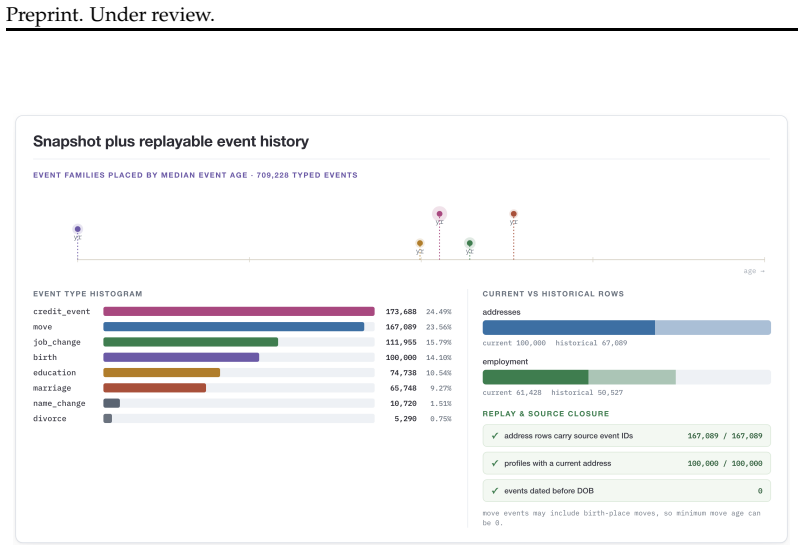
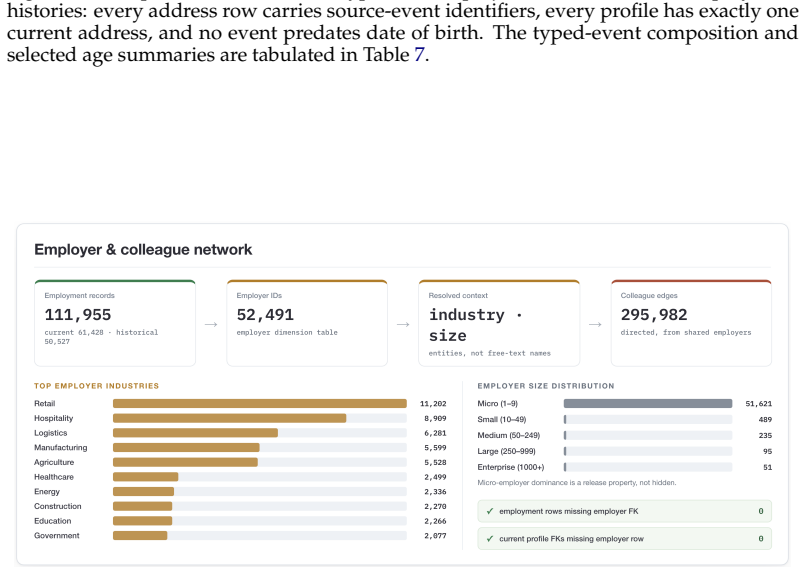
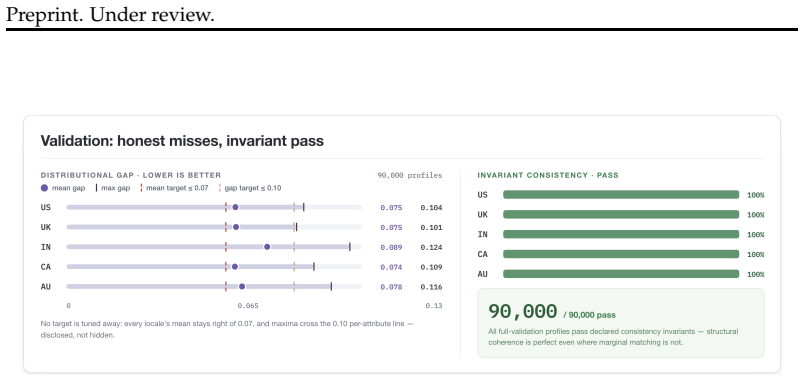
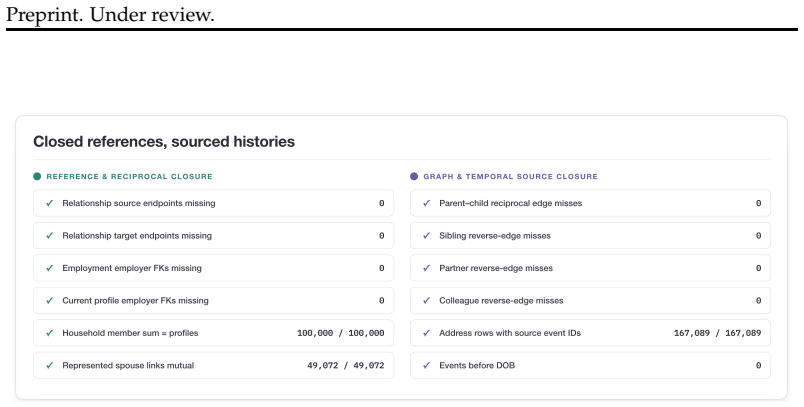
We present ProfileFoundry, a deterministic generator and fixed reference release of 100,000 adult synthetic Person Objects across eight locales. Each object combines a typed current snapshot, household, family, and employer links, snapshot-aligned events, normalized relational views, and generation provenance. The release contains 709,228 events, 40,338 households, 52,491 employers, and 518,564 directed relationship edges. We report evidence in separate categories: selected population-marginal comparisons, per-object invariant checks, release-wide referential and temporal closure, and coincidence/provenance screens. ProfileFoundry is a responsible synthetic source layer for constructing down
What carries the argument
The deterministic generator of synthetic Person Objects that enforces cross-field and temporal consistency through linked snapshots, events, and relationships.
If this is right
- Supports evaluations of LLM agent memory using consistent personal histories and events.
- Allows testing of privacy mechanisms with known synthetic person details.
- Enables tool-use assessments in scenarios involving household, family, and employer links.
- Provides a basis for record linkage and document understanding tasks with referential closure.
Where Pith is reading between the lines
- The dataset could support testing of long-term memory in agents by generating future updates aligned with existing events.
- Researchers might use the provenance to trace how inconsistencies affect agent performance in controlled experiments.
- Extensions could include generating documents or files linked to each person object for richer tool-use scenarios.
Load-bearing premise
The generator's checks produce cross-field and temporal consistency at a level that makes the objects usable for downstream LLM evaluations.
What would settle it
A test revealing frequent inconsistencies, such as mismatched ages with birth dates or events not aligning with household compositions, in a sample of the released objects.
Figures








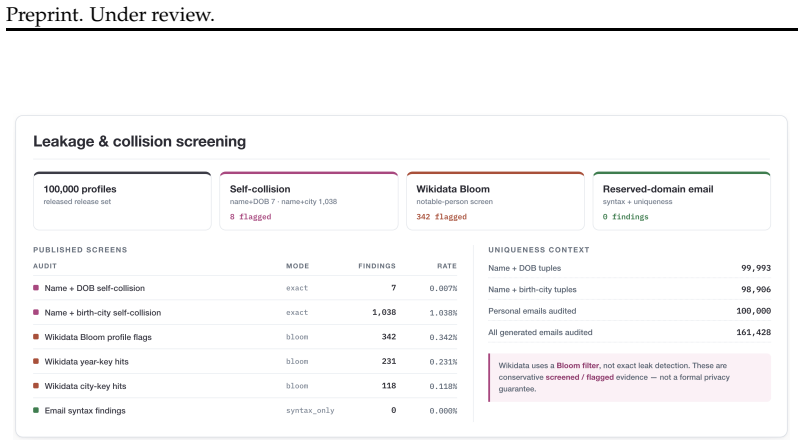
read the original abstract
Foundation-model research increasingly needs data about people: user state, personal histories, relationships, contact-like fields, documents, and longitudinal updates. Real user data is difficult to share, perturb, audit, or redistribute responsibly, while independently generated fake fields rarely preserve the cross-field and temporal consistency needed for controlled evaluation. We present PROFILEFOUNDRY, a deterministic generator and fixed reference release of 100,000 adult synthetic Person Objects across eight locales. Each object combines a typed current snapshot, household, family, and employer links, snapshot-aligned events, normalized relational views, and generation provenance. The release contains 709,228 events, 40,338 households, 52,491 employers, and 518,564 directed relationship edges. We report evidence in separate categories: selected population-marginal comparisons, per-object invariant checks, release-wide referential and temporal closure, and coincidence/provenance screens. PROFILEFOUNDRY is not a population-fidelity model, a rendered-text corpus, or a formal privacy mechanism. Instead, it is a responsible synthetic source layer for constructing downstream foundation-model evaluations involving memory, privacy, document understanding, record linkage, and agent state while keeping the synthetic person behind each artifact inspectable
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents PROFILEFOUNDRY, a deterministic generator and fixed reference release of 100,000 adult synthetic Person Objects across eight locales. Each object includes a typed current snapshot, household/family/employer links, snapshot-aligned events, normalized relational views, and generation provenance. The release contains 709,228 events, 40,338 households, 52,491 employers, and 518,564 directed relationship edges. Evidence for consistency and closure is reported in four categories: population-marginal comparisons, per-object invariant checks, release-wide referential/temporal closure, and coincidence/provenance screens. The resource is positioned as a synthetic substrate for downstream LLM agent evaluations involving memory, privacy, document understanding, record linkage, and tool use, with the synthetic persons remaining inspectable.
Significance. If the reported checks establish the claimed consistency at a usable level, this fixed release supplies a reproducible, auditable, and shareable person-like substrate that directly addresses privacy barriers in foundation-model research. The deterministic generation, explicit provenance, and multi-category verification approach enable controlled, falsifiable experiments that are difficult to conduct with real user data. The emphasis on inspectability and separation from both population-fidelity modeling and formal privacy mechanisms is a constructive contribution to evaluation infrastructure.
minor comments (3)
- [Abstract] Abstract: The abstract asserts that evidence is supplied across four explicit categories but does not include any quantitative outcomes, example statistics, or table references from those checks. Adding at least one representative metric per category would make the summary self-contained.
- The manuscript states that PROFILEFOUNDRY is not a population-fidelity model, yet no brief comparison to existing synthetic person or household generators appears in the related-work discussion. A short paragraph situating the generator relative to prior work would clarify its distinctive properties.
- The release counts (events, households, employers, edges) are given, but the manuscript does not indicate the exact public artifact location, file formats, or licensing terms. Explicit pointers and a one-paragraph usage note would improve immediate adoptability.
Simulated Author's Rebuttal
We thank the referee for their accurate summary of ProfileFoundry and for the positive evaluation of its potential contribution as a synthetic evaluation substrate. The recommendation of minor revision is noted; we will prepare a revised manuscript once any specific editorial or minor suggestions are provided.
Circularity Check
No significant circularity
full rationale
The paper describes a deterministic generator and fixed release of 100k synthetic Person Objects, supported by four categories of reported checks (population-marginal comparisons, per-object invariants, referential/temporal closure, coincidence/provenance screens). No equations, parameters, derivations, or load-bearing self-citations appear. The consistency claim is presented as directly testable from the released artifact rather than reduced to any internal fit or prior self-referential result. This matches the default expectation of a non-circular data-generation paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Synthetic data can be constructed to maintain cross-field and temporal consistency sufficient for controlled LLM evaluations
invented entities (1)
-
Person Object
no independent evidence
Reference graph
Works this paper leans on
-
[1]
28th USENIX Security Symposium , pages =
The Secret Sharer: Evaluating and Testing Unintended Memorization in Neural Networks , author =. 28th USENIX Security Symposium , pages =. 2019 , url =
2019
-
[2]
30th USENIX Security Symposium , pages =
Extracting Training Data from Large Language Models , author =. 30th USENIX Security Symposium , pages =. 2021 , url =
2021
-
[3]
Christen, Peter , booktitle =
-
[4]
2025 , url =
Faker: Python Package That Generates Fake Data , author =. 2025 , url =
2025
-
[5]
2024 , eprint =
Scaling Synthetic Data Creation with 1,000,000,000 Personas , author =. 2024 , eprint =
2024
-
[6]
Communications of the ACM , volume =
Datasheets for Datasets , author =. Communications of the ACM , volume =. 2021 , doi =
2021
-
[7]
2024 , howpublished =
Synthetic. 2024 , howpublished =
2024
-
[8]
Gates Open Research , volume =
Simulated Data for Census-Scale Entity Resolution Research Without Privacy Restrictions: A Large-Scale Dataset Generated by Individual-Based Modeling , author =. Gates Open Research , volume =. 2024 , doi =
2024
-
[9]
PIIBench: A Unified Multi-Source Benchmark Corpus for Personally Identifiable Information Detection
Jha, Pritesh , year =. 2604.15776 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Know Me, Respond to Me: Benchmarking
Jiang, Bowen and Hao, Zhuoqun and Cho, Young Min and Li, Bryan and Yuan, Yuan and Chen, Sihao and Ungar, Lyle and Taylor, Camillo Jose and Roth, Dan , booktitle =. Know Me, Respond to Me: Benchmarking. 2025 , url =
2025
-
[11]
Edward and Oh, Sewoong and Tsvetkov, Yulia and Koh, Pang Wei and Choi, Yejin , year =
Kim, Hyunwoo and Mireshghallah, Niloofar and Duan, Michael and Xin, Rui and Li, Shuyue Stella and Jung, Jaehun and Acuna, David and Pang, Qi and Xiao, Hanshen and Suh, G. Edward and Oh, Sewoong and Tsvetkov, Yulia and Koh, Pang Wei and Choi, Yejin , year =. 2602.03183 , archivePrefix =
-
[12]
Evaluating Very Long-Term Conversational Memory of
Maharana, Adyasha and Lee, Dong-Ho and Tulyakov, Sergey and Bansal, Mohit and Barbieri, Francesco and Fang, Yuwei , booktitle =. Evaluating Very Long-Term Conversational Memory of. 2024 , doi =
2024
-
[13]
2025 , url =
Mimesis: Fake Data Generator , author =. 2025 , url =
2025
-
[14]
Proceedings of the Conference on Fairness, Accountability, and Transparency , pages =
Model Cards for Model Reporting , author =. Proceedings of the Conference on Fairness, Accountability, and Transparency , pages =. 2019 , doi =
2019
-
[15]
and Dibben, Chris , journal =
Nowok, Beata and Raab, Gillian M. and Dibben, Chris , journal =. 2016 , doi =
2016
-
[16]
2025 , howpublished =
2025
-
[17]
Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology , year =
Generative Agents: Interactive Simulacra of Human Behavior , author =. Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology , year =
-
[18]
2016 IEEE International Conference on Data Science and Advanced Analytics , pages =
The Synthetic Data Vault , author =. 2016 IEEE International Conference on Data Science and Advanced Analytics , pages =. 2016 , doi =
2016
-
[19]
Data Cards: Purposeful and Transparent Dataset Documentation for Responsible
Pushkarna, Mahima and Zaldivar, Andrew and Kjartansson, Oddur , journal =. Data Cards: Purposeful and Transparent Dataset Documentation for Responsible. 2022 , doi =
2022
-
[20]
2025 , url =
Pydantic: Data Validation Using Python Type Hints , author =. 2025 , url =
2025
-
[21]
, year =
Eastlake, Donald and Panitz, A. , year =
-
[22]
2024 , url =
Salemi, Alireza and Mysore, Sheshera and Bendersky, Michael and Zamani, Hamed , booktitle =. 2024 , url =
2024
-
[23]
2025 , doi =
Savkin, Maksim and Ionov, Timur and Konovalov, Vasily , booktitle =. 2025 , doi =
2025
-
[24]
2025 , url =
Selvam, Sriram and Ghosh, Anneswa , journal =. 2025 , url =
2025
-
[25]
International Conference on Learning Representations , year =
Beyond Memorization: Violating Privacy via Inference with Large Language Models , author =. International Conference on Learning Representations , year =
-
[26]
Tan, Juntao and Yang, Liangwei and Liu, Zuxin and Liu, Zhiwei and Murthy, Rithesh and Awalgaonkar, Tulika Manoj and Zhang, Jianguo and Yao, Weiran and Zhu, Ming and Kokane, Shirley and Savarese, Silvio and Wang, Huan and Xiong, Caiming and Heinecke, Shelby , year =. 2502.20616 , archivePrefix =
-
[27]
2013 , doi =
Tran, Khoi-Nguyen and Vatsalan, Dinusha and Christen, Peter , booktitle =. 2013 , doi =
2013
-
[28]
Communications of the ACM , volume =
Wikidata: A Free Collaborative Knowledgebase , author =. Communications of the ACM , volume =. 2014 , doi =
2014
-
[29]
2018 , doi =
Walonoski, Jason and Kramer, Mark and Nichols, Joseph and Quina, Andre and Moesel, Chris and Hall, Dylan and Duffett, Carlton and Dube, Kudakwashe and Gallagher, Thomas and McLachlan, Scott , journal =. 2018 , doi =
2018
-
[30]
2025 , url =
Wu, Di and Wang, Hongwei and Yu, Wenhao and Zhang, Yuwei and Chang, Kai-Wei and Yu, Dong , booktitle =. 2025 , url =
2025
-
[31]
Advances in Neural Information Processing Systems , year =
A Synthetic Dataset for Personal Attribute Inference , author =. Advances in Neural Information Processing Systems , year =
-
[32]
and Srivastava, Divesh and Xiao, Xiaokui , journal =
Zhang, Jun and Cormode, Graham and Procopiuc, Cecilia M. and Srivastava, Divesh and Xiao, Xiaokui , journal =. 2017 , doi =
2017
-
[33]
Personalizing Dialogue Agents:
Zhang, Saizheng and Dinan, Emily and Urbanek, Jack and Szlam, Arthur and Kiela, Douwe and Weston, Jason , booktitle =. Personalizing Dialogue Agents:. 2018 , doi =
2018
-
[34]
2021 , url =
Zhang, Zhikun and Wang, Tianhao and Li, Ninghui and Honorio, Jean and Backes, Michael and He, Shibo and Chen, Jiming and Zhang, Yang , booktitle =. 2021 , url =
2021
-
[35]
2026 , url =
Mimesis Schema: Foreign-Key References and Structured Generation , author =. 2026 , url =
2026
-
[36]
2026 , url =
Synthetic Data Vault Documentation: Single-Table, Multi-Table, and Sequential Data , author =. 2026 , url =
2026
-
[37]
2026 , url =
pseudopeople Documentation , author =. 2026 , url =
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.