MoASE++: Mixture of Activation Sparsity Experts with Domain-Adaptive On-policy Distillation for Continual Test Time Adaptation
Pith reviewed 2026-05-20 12:49 UTC · model grok-4.3
The pith
Mixture of activation sparsity experts with on-policy distillation allows models to adapt continually to new domains without forgetting past knowledge.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that Activation Sparsity Experts with Spatial Differentiable Dropout and high/low-rank bottlenecks, guided by an Activation Sparsity Gate and Domain-Aware Router, when combined with EMA-anchored reverse KL distillation and entropy-conditioned augmentation policy, disentangle structure from texture to support robust continual adaptation.
What carries the argument
Mixture of Activation Sparsity Experts (MoASE) using Spatial Differentiable Dropout for pathway formation and Domain-Aware Router for assignment, augmented by Domain-Adaptive On-Policy Distillation for supervision.
Load-bearing premise
The assumption that texture-biased backbones cause error accumulation and catastrophic forgetting, and that the proposed sparsity experts and router can reliably separate domain-agnostic structure from domain-specific texture using only unlabeled streams.
What would settle it
A sequence of domain shifts where accuracy on the original source domain drops sharply after adaptation or where the full method shows no gain over a plain test-time adaptation baseline.
Figures
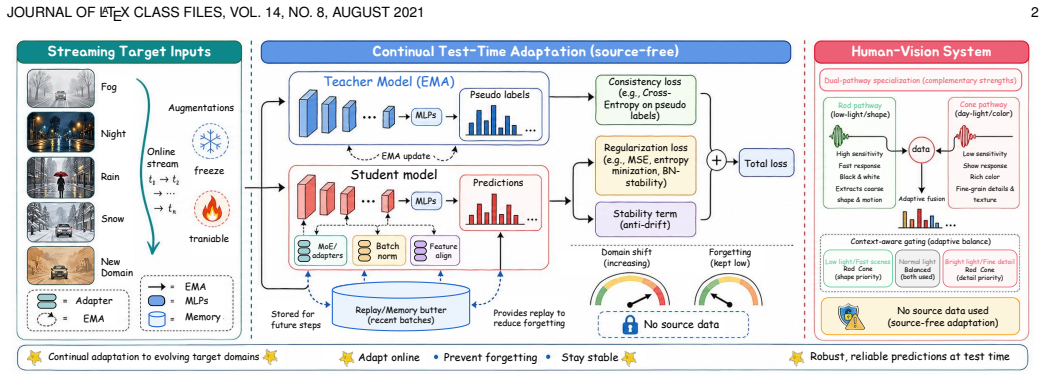









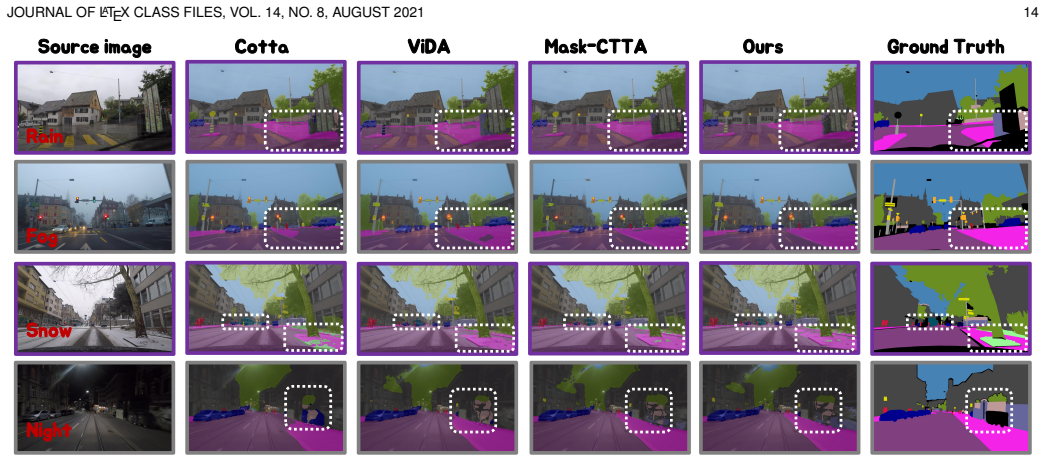
read the original abstract
Continual test-time adaptation adapts a source-pretrained model to non-stationary, unlabeled target streams while retaining past competence, yet texture-biased backbones risk error accumulation and catastrophic forgetting. Drawing inspiration from the process of decoupling shape and texture in the human visual system, we introduce MoASE, a plug-in mixture-of-experts that disentangles domain-agnostic structure from domain-specific texture using Activation Sparsity Experts with Spatial Differentiable Dropout, forming complementary high- and low-activation pathways, while high- and low-rank bottlenecks diversify representations. The Activation Sparsity Gate produces input-adaptive SDD thresholds for precise token selection, and the Domain-Aware Router assigns per-sample expert weights using texture-sensitive cues. To curb confirmation bias on unlabeled streams and stabilize supervision, we then introduce Domain-Adaptive On-Policy Distillation to constitute MoASE++, with an EMA-anchored on-policy reverse KL distillation and an augmentation policy conditioned on entropy and confidence that aligns predictions across the same views and improves the robustness-plasticity balance. Extensive experiments on classification (CIFAR-10/100-C, ImageNet-C) and semantic segmentation (Cityscapes->ACDC) demonstrate consistent state-of-the-art performance, offering a principled, controllable approach to continual adaptation in dynamic visual environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MoASE++, a plug-in mixture-of-experts module for continual test-time adaptation of source-pretrained vision models on non-stationary unlabeled target streams. It introduces Activation Sparsity Experts using Spatial Differentiable Dropout to create complementary high- and low-activation pathways that aim to disentangle domain-agnostic structure from domain-specific texture, augmented by high/low-rank bottlenecks, an input-adaptive Activation Sparsity Gate, and a texture-sensitive Domain-Aware Router. Domain-Adaptive On-Policy Distillation (with EMA-anchored reverse KL and entropy/confidence-conditioned augmentations) is added to mitigate confirmation bias and stabilize the robustness-plasticity trade-off. Experiments claim consistent SOTA results on CIFAR-10/100-C, ImageNet-C classification, and Cityscapes-to-ACDC semantic segmentation.
Significance. If the central mechanisms hold, the work offers a principled, controllable approach to continual adaptation that directly targets texture bias and error accumulation in dynamic visual environments. The integration of sparsity-based expert routing with on-policy distillation on unlabeled streams represents a meaningful technical contribution for unsupervised continual learning settings.
major comments (1)
- [Method (Activation Sparsity Gate, Domain-Aware Router, and Domain-Adaptive On-Policy Distillation subsections)] The core claim that Activation Sparsity Experts with Spatial Differentiable Dropout and the Domain-Aware Router reliably disentangle domain-agnostic structure from domain-specific texture (and thereby avoid confirmation bias) rests on indirect supervision via on-policy distillation alone. No auxiliary validation on controlled shape-texture conflict datasets or explicit metrics enforcing shape vs. texture separation is described, leaving open the possibility that the router simply amplifies currently dominant spurious cues rather than breaking the error-accumulation loop.
minor comments (2)
- [Abstract] The abstract asserts SOTA results but provides no details on experimental controls, exact baselines, or safeguards against post-hoc selection; these should be summarized upfront for clarity.
- [Method] Notation for SDD thresholds and the precise formulation of the entropy-conditioned augmentation policy should be made fully explicit with equations to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment below and indicate the revisions we intend to incorporate.
read point-by-point responses
-
Referee: [Method (Activation Sparsity Gate, Domain-Aware Router, and Domain-Adaptive On-Policy Distillation subsections)] The core claim that Activation Sparsity Experts with Spatial Differentiable Dropout and the Domain-Aware Router reliably disentangle domain-agnostic structure from domain-specific texture (and thereby avoid confirmation bias) rests on indirect supervision via on-policy distillation alone. No auxiliary validation on controlled shape-texture conflict datasets or explicit metrics enforcing shape vs. texture separation is described, leaving open the possibility that the router simply amplifies currently dominant spurious cues rather than breaking the error-accumulation loop.
Authors: We appreciate the referee's observation on the need for more direct evidence of disentanglement. The Activation Sparsity Experts with Spatial Differentiable Dropout are explicitly designed to produce complementary high- and low-activation pathways, where high-activation routes are intended to capture domain-specific texture and low-activation routes to preserve domain-agnostic structure, drawing from the human visual system's shape-texture separation. The Domain-Aware Router further conditions routing on texture-sensitive cues, while the Domain-Adaptive On-Policy Distillation (EMA-anchored reverse KL with entropy- and confidence-conditioned augmentations) supplies stable supervision to mitigate confirmation bias and error accumulation on unlabeled streams. Although the current manuscript does not include auxiliary experiments on dedicated shape-texture conflict datasets or explicit separation metrics, the design choices are validated through consistent state-of-the-art results on texture-shift-heavy benchmarks (CIFAR-10/100-C, ImageNet-C, Cityscapes-to-ACDC) and component ablations that isolate the contribution of the sparsity experts and router. We agree that additional clarification would strengthen the presentation. In the revised version we will expand the method section with a dedicated paragraph on the inductive biases of Spatial Differentiable Dropout and the router, together with qualitative visualizations of expert activation patterns across domain shifts. revision: partial
Circularity Check
No circularity: novel components and experimental validation are self-contained
full rationale
The paper introduces MoASE and MoASE++ as new architectural modules (Activation Sparsity Experts with Spatial Differentiable Dropout, high/low-activation pathways, Domain-Aware Router, and Domain-Adaptive On-Policy Distillation with EMA-anchored reverse KL) to address texture bias and confirmation bias in continual test-time adaptation. These are motivated by human vision inspiration and implemented as plug-in mechanisms, with performance claims resting on independent experiments across CIFAR-10/100-C, ImageNet-C, and Cityscapes->ACDC rather than any reduction of outputs to fitted inputs, self-definitions, or self-citation chains by construction. No equations or steps in the provided description equate predictions to the method's own parameters or prior outputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Texture-biased backbones risk error accumulation and catastrophic forgetting in continual test-time adaptation.
- domain assumption The human visual system decouples shape and texture.
invented entities (3)
-
Activation Sparsity Experts with Spatial Differentiable Dropout
no independent evidence
-
Domain-Aware Router
no independent evidence
-
Domain-Adaptive On-Policy Distillation
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J-cost uniqueness) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we propose an intriguing hypothesis: Can we explicitly decompose neurons by activation degree to encode shapes and textures separately... using Activation Sparsity Experts with Spatial Differentiable Dropout, forming complementary high- and low-activation pathways
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Extensive experiments on classification (CIFAR-10/100-C, ImageNet-C) and semantic segmentation (Cityscapes->ACDC)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
R. Zhang, A. Cheng, Y. Luo, G. Dai, H. Yang, J. Liu, R. Xu, L. Du, D. Wang, and Y. Du, “Decomposing the neurons: Activation sparsity via mixture of experts for continual test time adaptation,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 42, 2026, pp. 36 057–36 065
work page 2026
-
[2]
A survey of autonomous driving from a deep learning perspective,
J. Zhao, Y. Wu, R. Deng, S. Xu, J. Gao, and A. Burke, “A survey of autonomous driving from a deep learning perspective,”ACM Computing Surveys, vol. 57, no. 10, pp. 1–60, 2025
work page 2025
-
[3]
Bevuda++: geometric-aware unsupervised domain adaptation for multi-view 3d object detection,
R. Zhang, J. Liu, X. Li, X. Chi, D. Wang, L. Du, Y. Du, and S. Zhang, “Bevuda++: geometric-aware unsupervised domain adaptation for multi-view 3d object detection,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 35, no. 5, pp. 5109–5122, 2024
work page 2024
-
[4]
Identifying unob- served road regions in bird’s-eye view for single-vehicle percep- tion,
J. Yu, C. Lu, X. Meng, F. Shao, and Q. Jiang, “Identifying unob- served road regions in bird’s-eye view for single-vehicle percep- tion,”IEEE Robotics and Automation Letters, vol. 11, no. 3, pp. 2410– 2417, 2026
work page 2026
-
[5]
Last {0}: Latent spatio-temporal chain-of- thought for robotic vision-language-action model,
Z. Liu, J. Liu, H. Chen, J. Yu, Z. Guo, C. Hou, C. Gu, X. Mi, R. Zhang, K. Wuet al., “Last {0}: Latent spatio-temporal chain-of- thought for robotic vision-language-action model,”arXiv preprint arXiv:2601.05248, 2026
-
[6]
Manipllm: Embodied multimodal large language model for object-centric robotic manipulation,
X. Li, M. Zhang, Y. Geng, H. Geng, Y. Long, Y. Shen, R. Zhang, J. Liu, and H. Dong, “Manipllm: Embodied multimodal large language model for object-centric robotic manipulation,”arXiv preprint arXiv:2312.16217, 2023
-
[7]
A survey on vision–language–action models for embodied ai,
Y. Ma, Z. Song, Y. Zhuang, J. Hao, and I. King, “A survey on vision–language–action models for embodied ai,”IEEE Transac- tions on Neural Networks and Learning Systems, 2026
work page 2026
-
[8]
Efficient deweahter mixture-of-experts with uncertainty-aware feature-wise linear modulation,
R. Zhang, Y. Luo, J. Liu, H. Yang, Z. Dong, D. Gudovskiy, T. Okuno, Y. Nakata, K. Keutzer, Y. Duet al., “Efficient deweahter mixture-of-experts with uncertainty-aware feature-wise linear modulation,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, 2024, pp. 16 812–16 820
work page 2024
-
[9]
Occuseg: Occupancy- aware 3d instance segmentation,
L. Han, T. Zheng, L. Xu, and L. Fang, “Occuseg: Occupancy- aware 3d instance segmentation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 2940– 2949
work page 2020
-
[10]
Occ3d: A large-scale 3d occupancy prediction bench- mark for autonomous driving,
X. Tian, T. Jiang, L. Yun, Y. Mao, H. Yang, Y. Wang, Y. Wang, and H. Zhao, “Occ3d: A large-scale 3d occupancy prediction bench- mark for autonomous driving,”Advances in Neural Information Processing Systems, vol. 36, 2024
work page 2024
-
[11]
Continual test-time domain adaptation,
Q. Wang, O. Fink, L. Van Gool, and D. Dai, “Continual test-time domain adaptation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 7201–7211
work page 2022
-
[12]
Y. Tian, K. Li, T. He, L. Wan, P .-A. Heng, and W. Feng, “Dual domain-attribute learning framework with asynchronous adapters for continual test-time adaptation,”IEEE Transactions on Image Processing, 2026
work page 2026
-
[13]
Tent: Fully Test-time Adaptation by Entropy Minimization
D. Wang, E. Shelhamer, S. Liu, B. Olshausen, and T. Darrell, “Tent: Fully test-time adaptation by entropy minimization,”arXiv preprint arXiv:2006.10726, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[14]
arXiv preprint arXiv:2303.15361 , year=
J. Liang, R. He, and T. Tan, “A comprehensive survey on test-time adaptation under distribution shifts,”arXiv preprint arXiv:2303.15361, 2023
-
[15]
Dota: Distributional test-time adaptation of vision- language models,
Z. Han, J. Yang, G. Wang, J. Li, Q. Xu, M. Z. Shou, and C. Zhang, “Dota: Distributional test-time adaptation of vision- language models,”Advances in Neural Information Processing Sys- tems, vol. 38, pp. 142 772–142 798, 2026
work page 2026
-
[16]
Maintaining consistent inter-class topology in continual test-time adaptation,
C. Ni, F. Lyu, J. Tan, F. Hu, R. Yao, and T. Zhou, “Maintaining consistent inter-class topology in continual test-time adaptation,” inProceedings of the Computer Vision and Pattern Recognition Confer- ence, 2025, pp. 15 319–15 328
work page 2025
-
[17]
Becotta: Input-dependent online blending of experts for continual test-time adaptation,
D. Lee, J. Yoon, and S. J. Hwang, “Becotta: Input-dependent online blending of experts for continual test-time adaptation,”arXiv preprint arXiv:2402.08712, 2024
-
[18]
Adaptive distribution masked autoencoders for continual test-time adaptation,
J. Liu, R. Xu, S. Yang, R. Zhang, Q. Zhang, Z. Chen, Y. Guo, and S. Zhang, “Adaptive distribution masked autoencoders for continual test-time adaptation,”arXiv preprint arXiv:2312.12480, 2023
-
[19]
Vida: Homeostatic visual domain adapter for continual test time adaptation,
J. Liu, S. Yang, P . Jia, M. Lu, Y. Guo, W. Xue, and S. Zhang, “Vida: Homeostatic visual domain adapter for continual test time adaptation,”arXiv preprint arXiv:2306.04344, 2023
-
[20]
Retinal noise and absolute threshold,
H. B. Barlow, “Retinal noise and absolute threshold,”Josa, vol. 46, no. 8, pp. 634–639, 1956
work page 1956
-
[21]
The absolute threshold of cone vision,
D. Koenig and H. Hofer, “The absolute threshold of cone vision,” Journal of vision, vol. 11, no. 1, pp. 21–21, 2011
work page 2011
-
[22]
Structure of cone photoreceptors,
D. Mustafi, A. H. Engel, and K. Palczewski, “Structure of cone photoreceptors,”Progress in retinal and eye research, vol. 28, no. 4, pp. 289–302, 2009
work page 2009
-
[23]
The primate fovea: structure, func- tion and development,
A. Bringmann, S. Syrbe, K. G ¨orner, J. Kacza, M. Francke, P . Wiede- mann, and A. Reichenbach, “The primate fovea: structure, func- tion and development,”Progress in retinal and eye research, vol. 66, pp. 49–84, 2018
work page 2018
-
[24]
Von Helmholtz,Handbuch der physiologischen Optik
H. Von Helmholtz,Handbuch der physiologischen Optik. Voss, 1867, vol. 9
-
[25]
Emergence of shape bias in convolutional neural networks through activation sparsity,
T. Li, Z. Wen, Y. Li, and T. S. Lee, “Emergence of shape bias in convolutional neural networks through activation sparsity,” Advances in Neural Information Processing Systems, vol. 36, 2024
work page 2024
-
[26]
Multi-level personalized federated learning on heterogeneous and long-tailed data,
R. Zhang and et. al., “Multi-level personalized federated learning on heterogeneous and long-tailed data,”IEEE TMC, 2024
work page 2024
-
[27]
Fda: Fourier domain adaptation for se- mantic segmentation,
Y. Yang and S. Soatto, “Fda: Fourier domain adaptation for se- mantic segmentation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 4085–4095
work page 2020
-
[28]
A fourier- based framework for domain generalization,
Q. Xu, R. Zhang, Y. Zhang, Y. Wang, and Q. Tian, “A fourier- based framework for domain generalization,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 14 383–14 392
work page 2021
-
[29]
Adaptive mixtures of local experts,
R. A. Jacobs, M. I. Jordan, S. J. Nowlan, and G. E. Hinton, “Adaptive mixtures of local experts,”Neural computation, vol. 3, no. 1, pp. 79–87, 1991
work page 1991
-
[30]
Mixture of experts: a liter- ature survey,
S. Masoudnia and R. Ebrahimpour, “Mixture of experts: a liter- ature survey,”Artificial Intelligence Review, vol. 42, pp. 275–293, 2014
work page 2014
-
[31]
A survey on inference optimization techniques for mixture of experts models,
J. Liu, P . Tang, W. Wang, Y. Ren, X. Hou, P . A. Heng, M. Guo, and C. Li, “A survey on inference optimization techniques for mixture of experts models,”ACM Computing Surveys, vol. 58, no. 10, pp. 1–37, 2026
work page 2026
-
[32]
Retinal processing near absolute threshold: from behavior to mechanism,
G. D. Field, A. P . Sampath, and F. Rieke, “Retinal processing near absolute threshold: from behavior to mechanism,”Annu. Rev. Physiol., vol. 67, pp. 491–514, 2005
work page 2005
-
[33]
Learning multiple layers of features from tiny images,
A. Krizhevsky, G. Hintonet al., “Learning multiple layers of features from tiny images,” 2009
work page 2009
-
[34]
Benchmarking Neural Network Robustness to Common Corruptions and Perturbations
D. Hendrycks and T. Dietterich, “Benchmarking neural network robustness to common corruptions and perturbations,”arXiv preprint arXiv:1903.12261, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[35]
The cityscapes dataset for semantic urban scene understanding,
M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Be- nenson, U. Franke, S. Roth, and B. Schiele, “The cityscapes dataset for semantic urban scene understanding,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 3213–3223
work page 2016
-
[36]
C. Sakaridis, D. Dai, and L. Van Gool, “Acdc: The adverse con- ditions dataset with correspondences for semantic driving scene understanding,” inProceedings of the IEEE/CVF International Con- ference on Computer Vision, 2021, pp. 10 765–10 775
work page 2021
-
[37]
Ecotta: Memory-efficient continual test-time adaptation via self-distilled regularization,
J. Song, J. Lee, I. S. Kweon, and S. Choi, “Ecotta: Memory-efficient continual test-time adaptation via self-distilled regularization,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 11 920–11 929
work page 2023
-
[38]
Decorate the newcomers: Visual domain prompt for continual test time adaptation,
Y. Gan, Y. Bai, Y. Lou, X. Ma, R. Zhang, N. Shi, and L. Luo, “Decorate the newcomers: Visual domain prompt for continual test time adaptation,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 37, 2023, pp. 7595–7603
work page 2023
-
[39]
Exploring sparse visual prompt for cross-domain semantic seg- mentation,
S. Yang, J. Wu, J. Liu, X. Li, Q. Zhang, M. Pan, and S. Zhang, “Exploring sparse visual prompt for cross-domain semantic seg- mentation,”arXiv preprint arXiv:2303.09792, 2023
-
[40]
Distribution-aware continual test time adaptation for semantic segmentation,
J. Ni, S. Yang, J. Liu, X. Li, W. Jiao, R. Xu, Z. Chen, Y. Liu, and S. Zhang, “Distribution-aware continual test time adaptation for semantic segmentation,”arXiv preprint arXiv:2309.13604, 2023
-
[41]
Sparsevit: Revisiting activation sparsity for efficient high-resolution vision transformer,
X. Chen, Z. Liu, H. Tang, L. Yi, H. Zhao, and S. Han, “Sparsevit: Revisiting activation sparsity for efficient high-resolution vision transformer,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2023, pp. 2061–2070
work page 2023
-
[42]
Inducing and exploiting activation sparsity for fast inference on deep neural networks,
M. Kurtz, J. Kopinsky, R. Gelashvili, A. Matveev, J. Carr, M. Goin, W. Leiserson, S. Moore, N. Shavit, and D. Alistarh, “Inducing and exploiting activation sparsity for fast inference on deep neural networks,” inInternational Conference on Machine Learning. PMLR, 2020, pp. 5533–5543
work page 2020
-
[43]
Dasnet: Dynamic activation sparsity for neural network efficiency improvement,
Q. Yang, J. Mao, Z. Wang, and H. Li, “Dasnet: Dynamic activation sparsity for neural network efficiency improvement,” in2019 IEEE 31st International Conference on Tools with Artificial Intelligence (ICTAI). IEEE, 2019, pp. 1401–1405
work page 2019
-
[44]
T.-H. Yang, H.-Y. Cheng, C.-L. Yang, I.-C. Tseng, H.-W. Hu, H.-S. Chang, and H.-P . Li, “Sparse reram engine: Joint exploration of JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 16 activation and weight sparsity in compressed neural networks,” inProceedings of the 46th International Symposium on Computer Architecture, 2019, pp. 236–249
work page 2021
-
[45]
Prosparse: Introducing and enhancing intrinsic activation sparsity within large language models,
C. Song, X. Han, Z. Zhang, S. Hu, X. Shi, K. Li, C. Chen, Z. Liu, G. Li, T. Yang, and M. Sun, “Prosparse: Introducing and enhancing intrinsic activation sparsity within large language models,” 2024
work page 2024
-
[46]
Relu strikes back: Exploiting activation sparsity in large language models,
I. Mirzadeh, K. Alizadeh, S. Mehta, C. C. D. Mundo, O. Tuzel, G. Samei, M. Rastegari, and M. Farajtabar, “Relu strikes back: Exploiting activation sparsity in large language models,” 2023
work page 2023
-
[47]
Prosparse: Introducing and enhancing intrinsic activation sparsity within large language models,
C. Song, X. Han, Z. Zhang, S. Hu, X. Shi, K. Li, C. Chen, Z. Liu, G. Li, T. Yanget al., “Prosparse: Introducing and enhancing intrinsic activation sparsity within large language models,” in Proceedings of the 31st International Conference on Computational Linguistics, 2025, pp. 2626–2644
work page 2025
-
[48]
Hierarchical mixtures of experts and the EM algorithm,
M. I. Jordan and R. A. Jacobs, “Hierarchical mixtures of experts and the EM algorithm,”Neural computation, vol. 6, no. 2, pp. 181– 214, 1994
work page 1994
-
[49]
Learning Factored Representations in a Deep Mixture of Experts
D. Eigen, M. Ranzato, and I. Sutskever, “Learning factored repre- sentations in a deep mixture of experts,”arXiv:1312.4314, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[50]
Modeling task relationships in multi-task learning with multi-gate mixture- of-experts,
J. Ma, Z. Zhao, X. Yi, J. Chen, L. Hong, and E. H. Chi, “Modeling task relationships in multi-task learning with multi-gate mixture- of-experts,” inProceedings of the ACM SIGKDD International Con- ference on Knowledge Discovery and Data Mining (KDD), 2018
work page 2018
-
[51]
Gshard: Scaling giant models with con- ditional computation and automatic sharding,
D. Lepikhin, H. Lee, Y. Xu, D. Chen, O. Firat, Y. Huang, M. Krikun, N. Shazeer, and Z. Chen, “Gshard: Scaling giant models with con- ditional computation and automatic sharding,” in9th International Conference on Learning Representations, ICLR 2021, 2021
work page 2021
-
[52]
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
W. Fedus, B. Zoph, and N. Shazeer, “Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity,” CoRR, vol. abs/2101.03961, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[53]
Hash layers for large sparse models,
S. Roller, S. Sukhbaatar, A. Szlam, and J. Weston, “Hash layers for large sparse models,”CoRR, vol. abs/2106.04426, 2021. [Online]. Available: https://arxiv.org/abs/2106.04426
-
[54]
Stablemoe: Stable routing strategy for mixture of experts,
D. Dai, L. Dong, S. Ma, B. Zheng, Z. Sui, B. Chang, and F. Wei, “Stablemoe: Stable routing strategy for mixture of experts,” in Proceedings of the 60th Annual Meeting of the Association for Computa- tional Linguistics (Volume 1: Long Papers), ACL 2022, Dublin, Ireland, May 22-27, 2022, S. Muresan, P . Nakov, and A. Villavicencio, Eds. Association for Comp...
work page 2022
-
[55]
Designing effective sparse expert models,
B. Zoph, “Designing effective sparse expert models,” inIEEE International Parallel and Distributed Processing Symposium, IPDPS Workshops 2022, Lyon, France, May 30 - June 3, 2022. IEEE, 2022, p. 1044
work page 2022
-
[56]
H. Zou, Y. Zang, W. Xu, Y. Zhu, and X. Ji, “Flylora: Boosting task decoupling and parameter efficiency via implicit rank-wise mixture-of-experts,”Advances in Neural Information Processing Sys- tems, vol. 38, pp. 10 386–10 419, 2026
work page 2026
-
[57]
Each rank could be an expert: Single-ranked mixture of experts lora for multi-task learning,
Z. Zhao, Y. Zhou, X. Yu, Z. Zhang, D. Zhu, T. Shen, Z. Li, J. Yang, X. Wang, J. Suet al., “Each rank could be an expert: Single-ranked mixture of experts lora for multi-task learning,” inProceedings of the 32nd ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 1, 2026, pp. 1998–2009
work page 2026
-
[58]
L. Yi, H. Yu, G. Wang, X. Liu, and Q. Hu, “pfedmoe: Data-level personalization with mixture of experts in model-heterogeneous personalized federated learning,”IEEE Transactions on Knowledge and Data Engineering, 2026
work page 2026
-
[59]
Moe-llava: Mixture of experts for large vision-language models,
B. Lin, Z. Tang, Y. Ye, J. Huang, J. Zhang, Y. Pang, P . Jin, M. Ning, J. Luo, and L. Yuan, “Moe-llava: Mixture of experts for large vision-language models,”IEEE Transactions on Multimedia, 2026
work page 2026
-
[60]
R. Zhang, M. Dong, Y. Zhang, L. Heng, X. Chi, G. Dai, L. Du, D. Wang, Y. Du, and S. Zhang, “Mole-vla: Dynamic layer-skipping vision language action model via mixture-of-layers for efficient robot manipulation,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 22, 2026, pp. 18 764–18 772
work page 2026
-
[61]
On-policy distillation of language models: Learning from self-generated mistakes,
R. Agarwal, N. Vieillard, Y. Zhou, P . Stanczyk, S. Ramos Garea, M. Geist, and O. Bachem, “On-policy distillation of language models: Learning from self-generated mistakes,” inInternational Conference on Learning Representations, vol. 2024, 2024, pp. 21 246– 21 263
work page 2024
-
[62]
Minillm: Knowledge distillation of large language models,
Y. Gu, L. Dong, F. Wei, and M. Huang, “Minillm: Knowledge distillation of large language models,” inInternational Conference on Learning Representations, vol. 2024, 2024, pp. 32 694–32 717
work page 2024
-
[63]
Distillm: Towards streamlined distillation for large language models.ArXiv, abs/2402.03898,
J. Ko, S. Kim, T. Chen, and S.-Y. Yun, “Distillm: Towards streamlined distillation for large language models,”arXiv preprint arXiv:2402.03898, 2024
-
[64]
Language-driven policy distillation for cooperative driving in multi-agent reinforcement learning,
J. Liu, C. Xu, P . Hang, J. Sun, M. Ding, W. Zhan, and M. Tomizuka, “Language-driven policy distillation for cooperative driving in multi-agent reinforcement learning,”IEEE Robotics and Automation Letters, 2025
work page 2025
-
[65]
Q. Zhang, G. Han, J. Sun, W. Zhao, C. Sun, J. Cao, J. Wang, Y. Guo, and R. Xu, “Distillation-ppo: A novel two-stage reinforcement learning framework for humanoid robot perceptive locomotion,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2025, pp. 2916–2922
work page 2025
-
[66]
Learning deep features for discriminative localization,
B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, and A. Torralba, “Learning deep features for discriminative localization,” inPro- ceedings of the IEEE conference on computer vision and pattern recogni- tion, 2016, pp. 2921–2929
work page 2016
-
[67]
SAM 3: Segment Anything with Concepts
N. Carion, L. Gustafson, Y.-T. Hu, S. Debnath, R. Hu, D. Suris, C. Ryali, K. V . Alwala, H. Khedr, A. Huanget al., “Sam 3: Segment anything with concepts,”arXiv preprint arXiv:2511.16719, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[68]
A. Tarvainen and H. Valpola, “Mean teachers are better role mod- els: Weight-averaged consistency targets improve semi-supervised deep learning results,”Advances in neural information processing systems, vol. 30, 2017
work page 2017
-
[69]
Robust mean teacher for continual and gradual test-time adaptation,
M. D ¨obler, R. A. Marsden, and B. Yang, “Robust mean teacher for continual and gradual test-time adaptation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 7704–7714
work page 2023
-
[70]
Decorate the newcomers: Visual domain prompt for continual test time adaptation,
Y. Gan, X. Ma, Y. Lou, Y. Bai, R. Zhang, N. Shi, and L. Luo, “Decorate the newcomers: Visual domain prompt for continual test time adaptation,”arXiv preprint arXiv:2212.04145, 2022
-
[71]
Analysis of representations for domain adaptation,
S. Ben-David, J. Blitzer, K. Crammer, and F. Pereira, “Analysis of representations for domain adaptation,”Advances in neural information processing systems, vol. 19, 2006
work page 2006
-
[72]
A theory of learning from different domains,
S. Ben-David, J. Blitzer, K. Crammer, A. Kulesza, F. Pereira, and J. W. Vaughan, “A theory of learning from different domains,” Machine learning, vol. 79, no. 1, pp. 151–175, 2010
work page 2010
-
[73]
Learning to select data for transfer learning with Bayesian Optimization
S. Ruder and B. Plank, “Learning to select data for transfer learn- ing with bayesian optimization,”arXiv preprint arXiv:1707.05246, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[74]
Adversarial learning for zero-shot stance detection on social media,
E. Allaway, M. Srikanth, and K. McKeown, “Adversarial learning for zero-shot stance detection on social media,”arXiv preprint arXiv:2105.06603, 2021
-
[75]
Classification and analysis of multivariate observa- tions,
J. MacQueen, “Classification and analysis of multivariate observa- tions,” in5th Berkeley Symp. Math. Statist. Probability. University of California Los Angeles LA USA, 1967, pp. 281–297
work page 1967
-
[76]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly et al., “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[77]
Segformer: Simple and efficient design for semantic segmenta- tion with transformers,
E. Xie, W. Wang, Z. Yu, A. Anandkumar, J. M. Alvarez, and P . Luo, “Segformer: Simple and efficient design for semantic segmenta- tion with transformers,”Advances in Neural Information Processing Systems, vol. 34, pp. 12 077–12 090, 2021
work page 2021
-
[78]
Adam: A Method for Stochastic Optimization
D. P . Kingma and J. Ba, “Adam: A method for stochastic optimiza- tion,”arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[79]
Adaptformer: Adapting vision transformers for scalable visual recognition,
S. Chen, C. Ge, Z. Tong, J. Wang, Y. Song, J. Wang, and P . Luo, “Adaptformer: Adapting vision transformers for scalable visual recognition,”Advances in Neural Information Processing Systems, vol. 35, pp. 16 664–16 678, 2022
work page 2022
-
[80]
Delving deep into rectifiers: Surpassing human-level performance on imagenet classification,
K. He, X. Zhang, S. Ren, and J. Sun, “Delving deep into rectifiers: Surpassing human-level performance on imagenet classification,” inProceedings of the IEEE international conference on computer vision, 2015, pp. 1026–1034
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.