How Much MRI Preprocessing Is Enough? A Cost-Utility Study for Brain MRI Foundation Models
Pith reviewed 2026-06-27 19:42 UTC · model grok-4.3
The pith
Beyond basic preprocessing, extra MRI steps add only marginal gains to brain foundation model utility.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
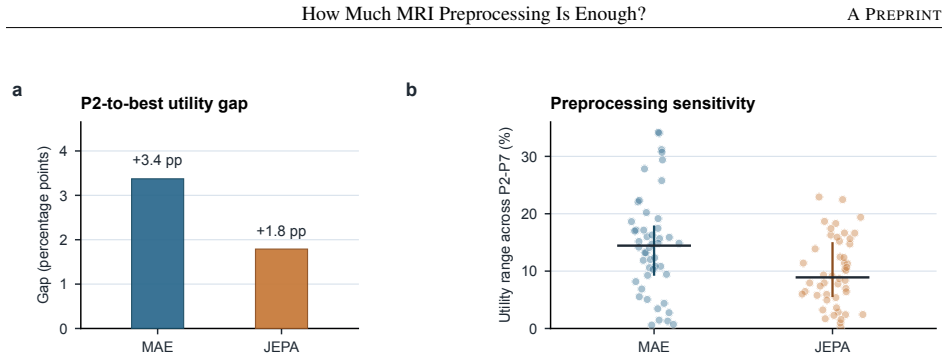
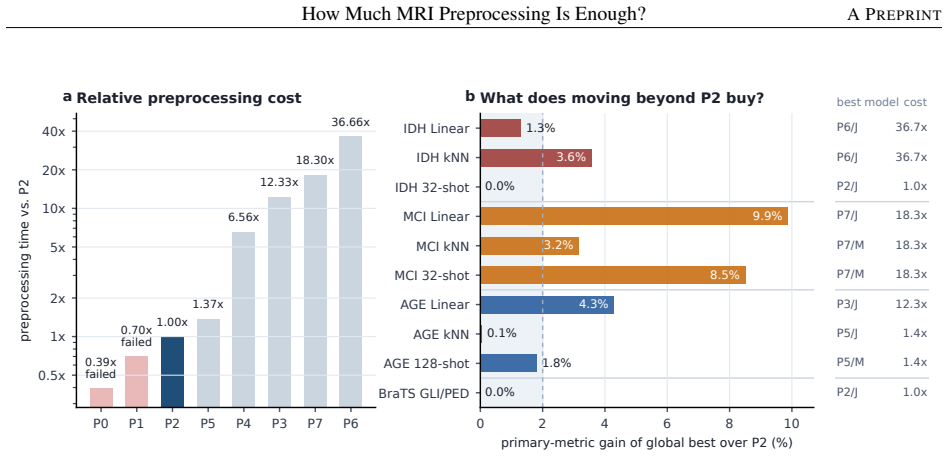
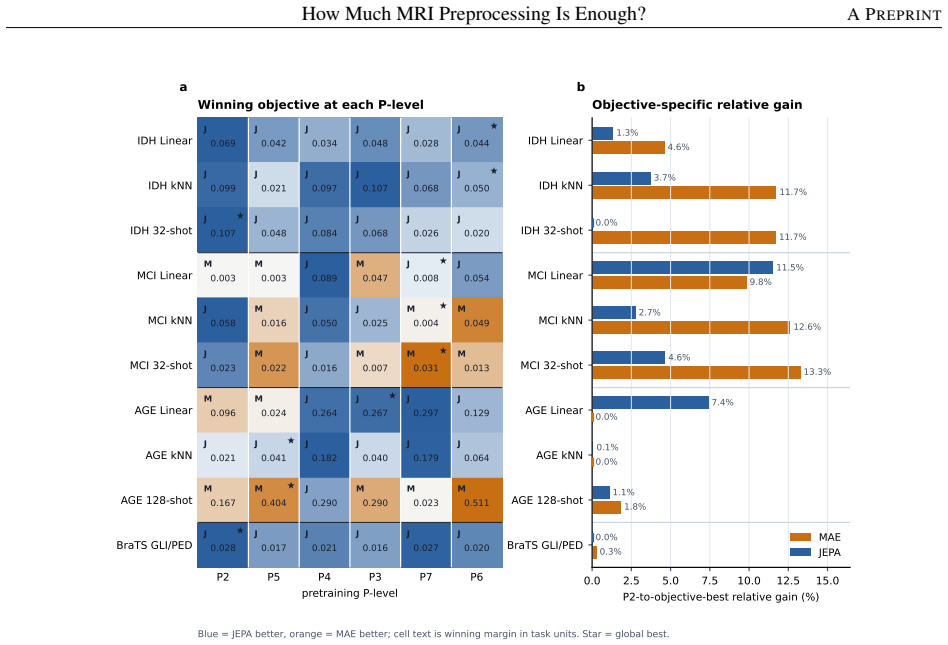
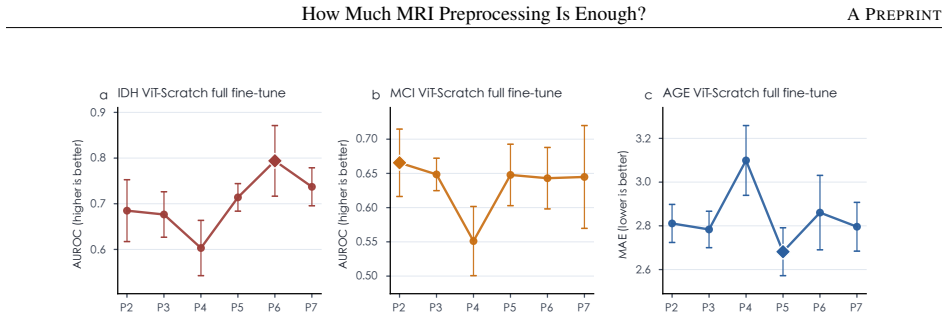
Keeping the 20,000-volume corpus, backbone, and evaluations fixed, the graded P0-P7 spectrum shows that beyond P2 the best feasible preprocessing improves aggregate utility by only 3.4 percentage points for MAE and 1.8 for JEPA, with most paired gains statistically unresolved. Stronger preprocessing is beneficial only in selected regimes such as IDH prediction, while age regression and tumor segmentation are often near or best at P2; MCI shows the clearest P7 gain, yet much of that advantage can be recovered by applying stronger preprocessing only at the downstream stage.
What carries the argument
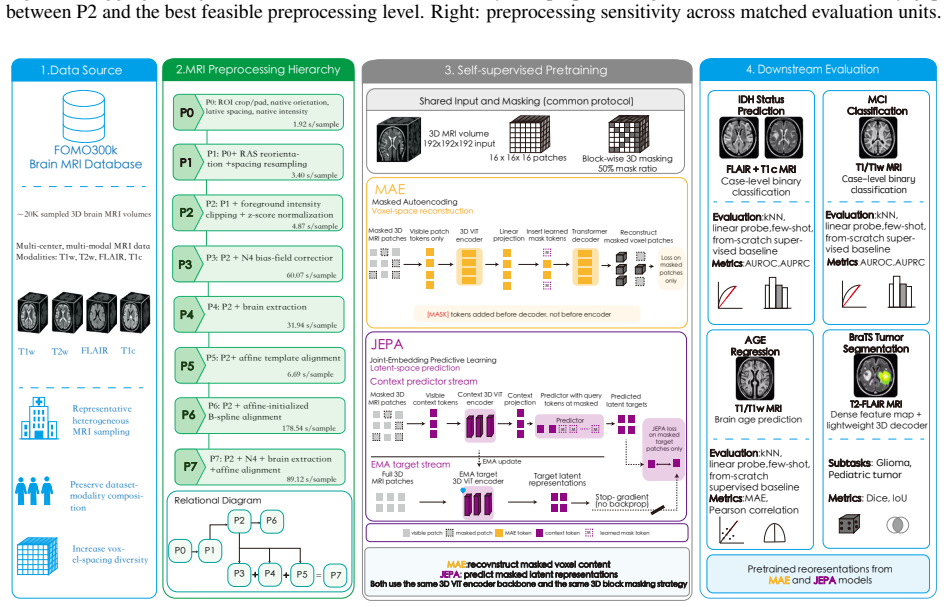
The graded P0-P7 preprocessing spectrum applied to a fixed 3D ViT self-supervised pretraining setup for MAE and JEPA, with downstream transfer to IDH prediction, MCI classification, brain age regression, and GLI/PED segmentation.
If this is right
- P2 is the lowest-cost feasible preprocessing level that avoids numerical instability.
- IDH prediction improves modestly with stronger preprocessing levels.
- Brain age regression and GLI/PED segmentation are often near or best at P2.
- MCI classification shows the clearest empirical gain from P7 preprocessing.
- Much of the P7 advantage for MCI can be recovered by stronger preprocessing applied only downstream.
Where Pith is reading between the lines
- For many tasks, adopting only P2 preprocessing could reduce compute costs with little performance loss.
- Task-specific tuning of preprocessing may be more efficient than a single pipeline for all brain MRI work.
- Future studies could test whether the same marginal returns hold when the backbone or masking protocol is varied.
- The approach suggests treating preprocessing intensity as a hyperparameter to optimize per downstream objective.
Load-bearing premise
The single corpus of 20,000 heterogeneous brain MRI volumes together with the chosen downstream tasks are representative enough to determine general preprocessing utility across brain MRI applications.
What would settle it
A replication study on an independent large brain MRI corpus using the same P0-P7 levels and downstream tasks that finds statistically significant utility gains larger than 5 percentage points beyond P2 would falsify the marginal-benefit claim.
Figures
read the original abstract
MRI preprocessing defines the input distribution seen by brain MRI foundation models, yet it is usually treated as routine data cleaning rather than a modeling choice. We ask how much preprocessing is worth its computational cost for self-supervised 3D MRI pretraining. Keeping the corpus, 3D ViT backbone, masking protocol, and downstream evaluations fixed, we compare a graded P0-P7 preprocessing spectrum for masked autoencoding (MAE) and joint-embedding predictive learning (JEPA) on 20,000 heterogeneous brain MRI volumes, then transfer the encoders to IDH prediction, MCI classification, brain age regression, and GLI/PED tumor segmentation. The results do not support a simple "more is better" rule. P0/P1 are numerically unstable, making P2 the lowest-cost feasible level; beyond P2, choosing the best feasible preprocessing level improves aggregate utility by only 3.4 percentage points for MAE and 1.8 percentage points for JEPA, with most paired gains statistically unresolved. Stronger preprocessing is beneficial only in selected regimes: IDH improves modestly, AGE and GLI/PED are often near or best at P2, and MCI shows the clearest empirical P7 gain. Cross-level MCI transfer further shows that much of the P7 advantage can be recovered by applying stronger preprocessing downstream, without requiring P7 throughout pretraining. These findings recast MRI preprocessing as a downstream-aware cost-utility decision rather than a default escalation pipeline. Code is available at https://github.com/PangJiangShuan/PreBrain.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports a controlled empirical comparison of seven graded MRI preprocessing levels (P0–P7) for self-supervised 3D ViT pretraining with MAE and JEPA on a fixed corpus of 20,000 heterogeneous brain MRI volumes. Keeping corpus, backbone, and masking fixed, the encoders are transferred to four downstream tasks (IDH prediction, MCI classification, brain age regression, GLI/PED segmentation). Key results: P0/P1 are numerically unstable so P2 is the lowest-cost feasible level; beyond P2 the best feasible preprocessing yields only 3.4 pp aggregate utility gain for MAE and 1.8 pp for JEPA, with most paired differences statistically unresolved. Task-specific patterns are noted (modest IDH benefit, near-P2 optima for AGE and GLI/PED, clearest P7 gain for MCI) and a cross-level MCI experiment shows much of the P7 advantage recoverable by stronger downstream preprocessing alone. The conclusion recasts preprocessing as a downstream-aware cost-utility choice rather than default escalation. Code is released.
Significance. If the measured small-gain pattern holds, the work supplies concrete, reproducible evidence that challenges the default 'more preprocessing is better' heuristic in brain-MRI foundation-model pipelines and quantifies the modest utility returns beyond minimal feasible preprocessing. The fixed-component design (corpus, backbone, masking) is a methodological strength that cleanly isolates preprocessing effects. Public code release further strengthens the contribution by enabling direct replication. These data could inform more efficient resource allocation in large-scale 3D MRI pretraining, especially when downstream task requirements are known in advance.
major comments (1)
- [Abstract] Abstract: The headline interpretive claim—that the findings recast preprocessing as a 'downstream-aware cost-utility decision rather than a default escalation pipeline'—rests on the small aggregate gains (3.4 pp MAE, 1.8 pp JEPA) and the 'most paired gains statistically unresolved' pattern being representative. The study deliberately holds corpus, backbone, and masking fixed to isolate preprocessing, yet supplies no cross-corpus or cross-task sensitivity analysis. If other corpora or tasks exhibit materially larger gains from P3–P7, both the magnitude of the reported deltas and the statistical pattern would not support the broader recasting. This representativeness assumption is therefore load-bearing for the central conclusion.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the methodological strengths of the fixed-component design. We respond to the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline interpretive claim—that the findings recast preprocessing as a 'downstream-aware cost-utility decision rather than a default escalation pipeline'—rests on the small aggregate gains (3.4 pp MAE, 1.8 pp JEPA) and the 'most paired gains statistically unresolved' pattern being representative. The study deliberately holds corpus, backbone, and masking fixed to isolate preprocessing, yet supplies no cross-corpus or cross-task sensitivity analysis. If other corpora or tasks exhibit materially larger gains from P3–P7, both the magnitude of the reported deltas and the statistical pattern would not support the broader recasting. This representativeness assumption is therefore load-bearing for the central conclusion.
Authors: The fixed-component design is a deliberate methodological choice that cleanly isolates preprocessing effects by holding corpus, backbone, and masking constant; this isolation is presented as a core strength rather than a limitation. The reported small aggregate gains and task-specific patterns (modest IDH benefit, near-P2 optima for AGE/GLI/PED, clearest P7 gain for MCI) are therefore attributable to preprocessing within a large heterogeneous corpus and four diverse downstream tasks. We agree that broader cross-corpus sensitivity would further strengthen generalizability claims. To address the concern about scope, we will revise the abstract to qualify the cost-utility recasting as applying to the controlled experimental setting reported, and we will add a brief discussion paragraph noting cross-corpus validation as valuable future work. This preserves the evidence-based interpretive contribution while making the representativeness assumption explicit. revision: yes
Circularity Check
No circularity: direct empirical comparison on fixed corpus and tasks
full rationale
The paper reports measured performance differences across preprocessing levels P0-P7 on a single fixed 20k-volume corpus, 3D ViT backbone, masking protocol, and four downstream tasks. No derivation, equation, or claim reduces by construction to a fitted parameter, self-citation chain, or renamed input. The central utility deltas are observed outcomes, not predictions forced by the experimental design itself. The representativeness assumption is an external validity concern, not a circularity issue.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Self-supervised learning with 3D ViT, MAE, and JEPA produces useful representations from brain MRI when the corpus and masking protocol are held fixed
Reference graph
Works this paper leans on
-
[1]
Theodoris, Ling Xiao, Anant Chopra, Mark D
doi: 10.1038/s41586-023- 05881-4. 9 How Much MRI Preprocessing Is Enough?A PREPRINT Pranav Rajpurkar, Emma Chen, Oishi Banerjee, and Eric J. Topol. AI in health and medicine.Nature Medicine, 28(1):31–38,
-
[2]
Jonghun Kim, Mansu Kim, and Hyunjin Park
doi: 10.1038/s41591-021-01614-0. Jonghun Kim, Mansu Kim, and Hyunjin Park. Domain aware multi-task pre-training of 3d Swin transformer for brain MRI. In Proceedings of the Asian Conference on Computer Vision (ACCV), pages 2124–2144, December
-
[3]
Haoyu Dong, Yuwen Chen, Hanxue Gu, Nicholas Konz, Yaqian Chen, Qihang Li, and Maciej A. Mazurowski. MRI-CORE: A Foundation Model for Magnetic Resonance Imaging.arXiv preprint arXiv:2506.12186,
-
[5]
URL https://arxiv.org/abs/ 2506.14432. FOMO-MRI. FOMO300K: Brain MRI dataset for large-scale self-supervised learning with clinical data. https://huggingface. co/datasets/FOMO-MRI/FOMO300K,
-
[6]
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick
Version 1.1; accessed 2026-06-06. Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16000–16009,
2026
-
[7]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp
doi: 10.1109/CVPR52688.2022.01553. Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-supervised learning from images with a joint-embedding predictive architecture. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15619–15629,
-
[8]
In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR)
doi: 10.1109/CVPR52729.2023.01499. Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. InProceedings of the 37th International Conference on Machine Learning, volume 119 ofProceedings of Machine Learning Research, pages 1597–1607,
-
[9]
doi: 10.1109/CVPR42600.2020.00975. Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9650–9660,
-
[10]
In: IEEE/CVF International Conference on Computer Vision (ICCV), pp
doi: 10.1109/ICCV48922.2021.00951. Hangbo Bao, Li Dong, Songhao Piao, and Furu Wei. BEiT: BERT pre-training of image transformers. InInternational Conference on Learning Representations,
-
[11]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp
doi: 10.1109/CVPR52688.2022.00943. Zongwei Zhou, Vatsal Sodha, Md Mahfuzur Rahman Siddiquee, Ruibin Feng, Nima Tajbakhsh, Michael B. Gotway, and Jianming Liang. Models genesis: Generic autodidactic models for 3d medical image analysis. InMedical Image Computing and Computer Assisted Intervention – MICCAI 2019, Lecture Notes in Computer Science, pages 384–393,
-
[12]
Yucheng Tang, Dong Yang, Wenqi Li, Holger R
doi: 10.1007/978-3-030-32251- 9_42. Yucheng Tang, Dong Yang, Wenqi Li, Holger R. Roth, Bennett Landman, Daguang Xu, Vishwesh Nath, and Ali Hatamizadeh. Self-supervised pre-training of Swin transformers for 3d medical image analysis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20730–20740,
-
[13]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp
doi: 10.1109/CVPR52688.2022.02007. Joseph Cox, Peng Liu, Skylar E. Stolte, Yunchao Yang, Kang Liu, Kyle B. See, Huiwen Ju, and Ruogu Fang. BrainSegFounder: Towards 3d foundation models for neuroimage segmentation.Medical Image Analysis, 97:103301,
-
[14]
doi: 10.1016/j.media. 2024.103301. Carlo Alberto Barbano, Matteo Brunello, Benoit Dufumier, and Marco Grangetto. Anatomical foundation models for brain MRIs. Pattern Recognition Letters, 199:178–184,
-
[15]
Chang Yang, Jianfeng Feng, Christian F
doi: 10.1016/j.patrec.2025.11.028. Chang Yang, Jianfeng Feng, Christian F. Beckmann, Stephen M. Smith, and Weikang Gong. GenBrain: A generative foundation model of multimodal brain imaging.medRxiv,
-
[16]
doi: 10.64898/2025.12.19.25342614. Divyanshu Tak, Biniam A. Garomsa, Anna Zapaishchykova, Tafadzwa L. Chaunzwa, Juan Carlos Climent Pardo, Zezhong Ye, John Zielke, Yashwanth Ravipati, et al. A generalizable foundation model for analysis of human brain MRI.Nature Neuroscience, 29 (4):945–956,
-
[17]
A foundation model for generalized brain
doi: 10.1038/s41593-026-02202-6. Chaoyi Wu, Xiaoman Zhang, Ya Zhang, Hui Hui, Yanfeng Wang, and Weidi Xie. Towards generalist foundation model for radiology by leveraging web-scale 2d&3d medical data.Nature Communications, 16(1):7866,
-
[18]
Med3D: Transfer Learning for 3D Medical Image Analysis
doi: 10.1038/s41467-025-62385-7. Sihong Chen, Kai Ma, and Yefeng Zheng. Med3D: Transfer learning for 3d medical image analysis.arXiv preprint arXiv:1904.00625,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1038/s41467-025-62385-7 1904
-
[19]
doi: 10.1002/(SICI)1522-2594(199912)42:6<1072::AID-MRM11>3.0.CO;2-M. Nicholas J. Tustison, Brian B. Avants, Philip A. Cook, Yuanjie Zheng, Alexander Egan, Paul A. Yushkevich, and James C. Gee. N4ITK: Improved N3 bias correction.IEEE Transactions on Medical Imaging, 29(6):1310–1320,
-
[20]
doi: 10.1109/TMI.2010. 2046908. Stephen M. Smith. Fast robust automated brain extraction.Human Brain Mapping, 17(3):143–155,
-
[21]
doi: 10.1002/hbm.10062. Brian B. Avants, Nicholas J. Tustison, Gang Song, Philip A. Cook, Arno Klein, and James C. Gee. A reproducible evaluation of ANTs similarity metric performance in brain image registration.NeuroImage, 54(3):2033–2044,
-
[22]
NeuroImage61(2), 371–385 (2012) https://doi.org/10.1016/j.neuroimage
doi: 10.1016/j.neuroimage. 2010.09.025. Mark Jenkinson, Christian F. Beckmann, Timothy E. J. Behrens, Mark W. Woolrich, and Stephen M. Smith. FSL.NeuroImage, 62 (2):782–790,
-
[23]
NeuroImage62(2), 782–790 (2012)
doi: 10.1016/j.neuroimage.2011.09.015. John Ashburner and Karl J. Friston. Unified segmentation.NeuroImage, 26(3):839–851,
-
[24]
doi: 10.1016/j.neuroimage.2005.02
-
[25]
doi: 10.1148/ryai.220058. Ronald C. Petersen, Glenn E. Smith, Stephen C. Waring, Robert J. Ivnik, Eric G. Tangalos, and Emre Kokmen. Mild cognitive impairment: Clinical characterization and outcome.Archives of Neurology, 56(3):303–308,
-
[26]
doi: 10.1001/archneur.56.3.303. Bjoern H. Menze, Andras Jakab, Stefan Bauer, Jayashree Kalpathy-Cramer, Keyvan Farahani, Justin Kirby, Yuliya Burren, Nicole Porz, et al. The multimodal brain tumor image segmentation benchmark (BRATS).IEEE Transactions on Medical Imaging, 34 (10):1993–2024,
-
[27]
doi: 10.1109/TMI.2014.2377694. Ujjwal Baid, Satyam Ghodasara, Suyash Mohan, Michel Bilello, Evan Calabrese, Errol Colak, Keyvan Farahani, Jayashree Kalpathy- Cramer, Felipe C. Kitamura, Sarthak Pati, et al. The RSNA-ASNR-MICCAI BraTS 2021 benchmark on brain tumor segmentation and radiogenomic classification.arXiv preprint arXiv:2107.02314,
-
[28]
Shah, et al
Anahita Fathi Kazerooni, Nastaran Khalili, Xinyang Liu, Debanjan Haldar, Zhifan Jiang, Anna Zapaishchykova, Julija Pavaine, Lubdha M. Shah, et al. BraTS-PEDs: Results of the multi-consortium international pediatric brain tumor segmentation challenge 2023.Machine Learning for Biomedical Imaging, 3(June 2025):72–87,
2023
-
[29]
doi: 10.59275/j.melba.2025-f6fg. 11 How Much MRI Preprocessing Is Enough?A PREPRINT A Appendix: Additional Results and Details A.1 Pretraining Implementation Details Table A1 gives the concrete P0–P7 image definitions and measured preprocessing time used by the pretraining sweep. P0–P2 are applied from raw records during training, whereas P3–P7 are genera...
-
[30]
For AGE, the pretrained row is selected by MAE
For IDH and MCI, the pretrained row in each setting is the best MAE/JEPA checkpoint selected by AUROC. For AGE, the pretrained row is selected by MAE. Baseline checkpoints use the same BrainIAC, GenBrain, MedicalNet/Med3D, MRI-Core, and RadFM models described in the main text, with downstream inputs prepared according to each model’s own training or relea...
arXiv 2060
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.