MAS-Lab: A Specification-Driven Validation Framework for Reliable Multi-Agent Systems
Pith reviewed 2026-06-30 03:11 UTC · model grok-4.3
The pith
MAS-Lab separates semantic intent from operational concerns in multi-agent systems via declarative specs, a stateful OS layer, and lab overlays.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
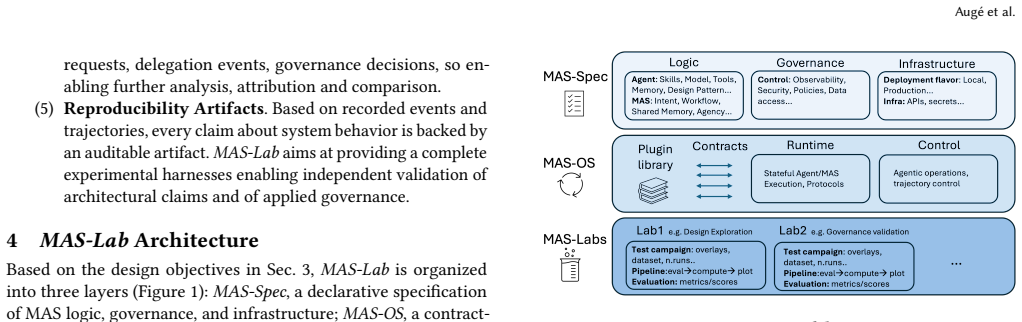
MAS-Lab transforms MAS from collections of scripts into engineered distributed systems by separating semantic intent from operational concerns, making behavior and control explicit, supporting reproducible experimentation, and preserving continuity across lifecycle stages. The framework consists of a declarative agentic specification layer, a stateful MAS Operating System that provides execution and control primitives, and lab overlays with integrated observability and evaluation tools, enabling intent-based validation and a seamless transition to production-grade MAS.
What carries the argument
The three-layer architecture of declarative Spec for semantic intent, stateful MAS-OS for execution primitives, and lab overlays for observability that together enforce separation of concerns.
If this is right
- Behavior observed during experimentation becomes usable evidence for production behavior.
- System evolution can follow explicit specifications rather than script changes.
- Validation shifts to checking alignment between declared intent and observed execution.
- Lifecycle stages from prototyping to deployment maintain consistent control mechanisms.
- Multi-agent systems gain the structure of engineered distributed systems instead of collections of scripts.
Where Pith is reading between the lines
- The framework-agnostic Spec layer could allow existing agent tools to plug in without rewriting their core logic.
- Stateful OS primitives might reduce the need for custom orchestration code in production MAS.
- Lab overlays with built-in evaluation could become a standard way to generate governance reports for deployed agents.
- If widely adopted, the separation of layers might make it easier to audit or certify agent behaviors against requirements.
Load-bearing premise
That a declarative specification layer plus stateful OS primitives and lab overlays will be enough to replace ad-hoc development practices and produce reliable MAS behavior.
What would settle it
A side-by-side deployment study measuring whether MAS built with the MAS-Lab layers show higher reproducibility, fewer production failures, or better evolvability than equivalent ad-hoc implementations.
Figures

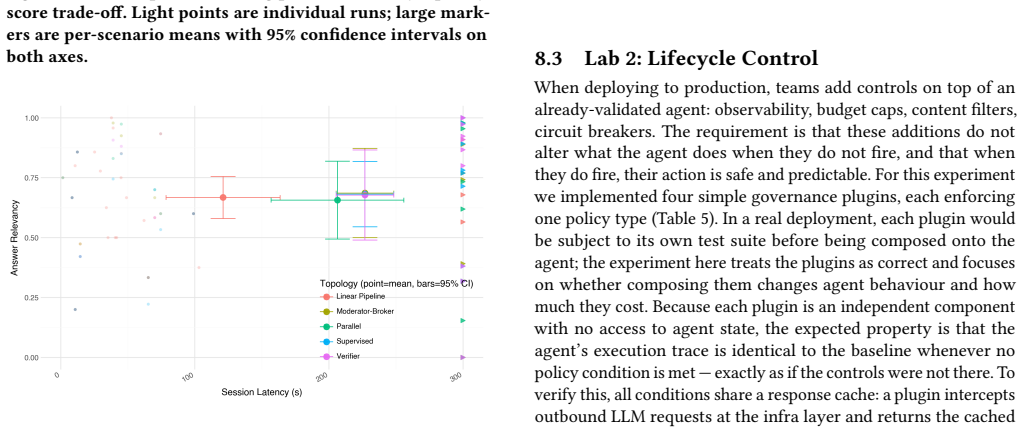
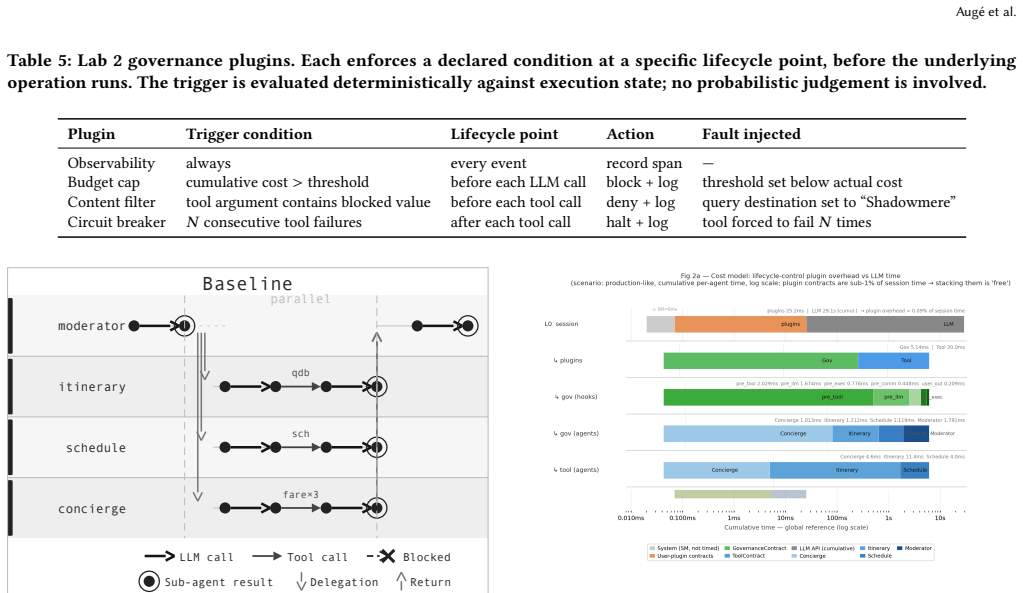
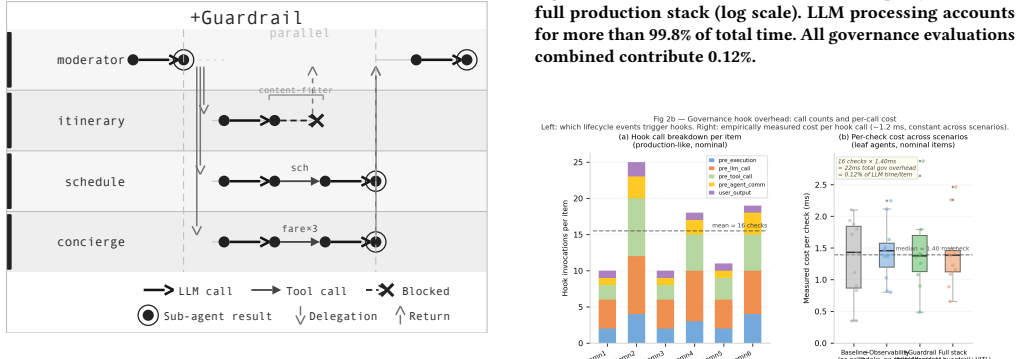
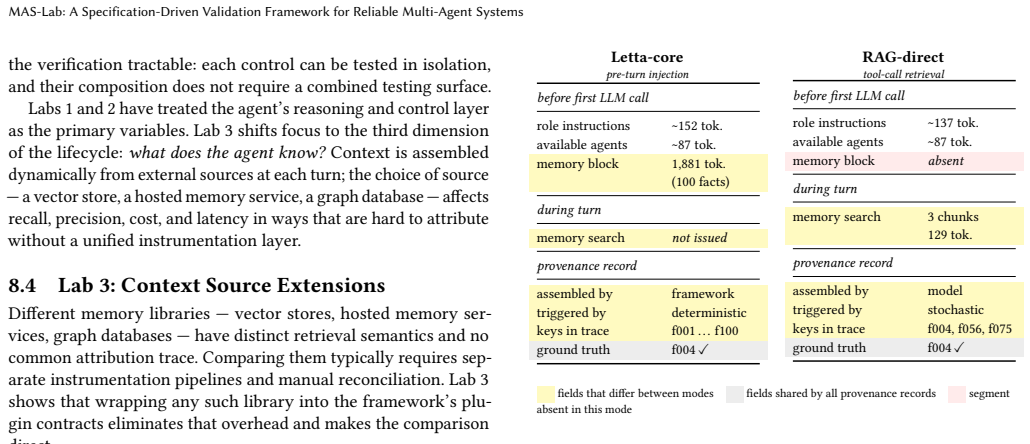

read the original abstract
The rapid emergence of LLM-based agentic frameworks has significantly reduced the cost of assembling multi-agent systems (MAS), enabling fast prototyping and exploration of agentic behaviors. However, systems built with current tooling remain ill-suited for reliable, evolvable, and production-grade deployment. In practice, MAS are often developed in an ad-hoc and imperative manner, with agent logic, orchestration, observability, and control tightly interwoven, little to no explicit system-level validation, and development workflows optimized for demonstrations rather than long-lived, governed operation. As a result, behavior observed during experimentation rarely constitutes reliable evidence of behavior in production. In this paper, we introduce MAS-Lab, a specification-driven framework for principled development and experimental validation of multi-agent systems properties. MAS-Lab is designed to transform MAS from collections of scripts into engineered distributed systems by separating semantic intent from operational concerns, making behavior and control explicit, supporting reproducible experimentation, and preserving continuity across lifecycle stages. MAS-Lab consists of three layers: a declarative, framework-agnostic agentic specification layer (Spec); a stateful MAS Operating System that provides execution and control primitives plugged-in by design (MAS-OS); and a set of lab overlays with integrated observability and evaluation tools (Labs). Together, these components enable intent-based validation, principled system evolution, and a seamless transition to production-grade MAS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MAS-Lab, a specification-driven framework for principled development and experimental validation of multi-agent systems. It consists of three layers—a declarative, framework-agnostic Spec layer, a stateful MAS-OS providing execution and control primitives, and lab overlays with observability and evaluation tools—intended to separate semantic intent from operational concerns, make behavior explicit, support reproducible experimentation, and preserve continuity from experimentation to production-grade deployment, addressing the ad-hoc, imperative development common in current LLM-based MAS.
Significance. The proposed separation of concerns and explicit specification layer addresses a genuine practical problem in scaling MAS beyond demonstrations. If the architecture can be shown to deliver the claimed reproducibility and validation benefits, it would represent a useful engineering contribution to the field. However, the manuscript presents only the high-level design without implementation details, formal properties, or any evaluation, so the significance remains prospective rather than demonstrated.
major comments (1)
- [Abstract] Abstract: the central claim that the three-layer architecture 'enable[s] intent-based validation, principled system evolution, and a seamless transition to production-grade MAS' is presented without any supporting evidence, case studies, metrics, or formal arguments showing that the declarative Spec plus stateful MAS-OS primitives suffice to overcome ad-hoc practices or produce reliable behavior in production.
Simulated Author's Rebuttal
We thank the referee for the constructive review. The feedback correctly identifies that the abstract's claims about the architecture's benefits lack supporting evidence in the manuscript. We address this point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the three-layer architecture 'enable[s] intent-based validation, principled system evolution, and a seamless transition to production-grade MAS' is presented without any supporting evidence, case studies, metrics, or formal arguments showing that the declarative Spec plus stateful MAS-OS primitives suffice to overcome ad-hoc practices or produce reliable behavior in production.
Authors: We agree that the manuscript is a conceptual design paper presenting the MAS-Lab architecture at a high level, without implementation details, formal proofs, or empirical evaluation. The abstract language describes the intended outcomes of the three-layer separation (declarative Spec, stateful MAS-OS, and Labs) rather than demonstrated results. We will revise the abstract to frame these as design goals and prospective benefits of the specification-driven approach, making explicit that validation of the claims remains future work. This revision will align the abstract with the paper's actual scope as a framework proposal. revision: yes
Circularity Check
No significant circularity
full rationale
The manuscript is a purely descriptive framework proposal. It defines MAS-Lab via three architectural layers (declarative Spec, stateful MAS-OS, and Labs) and states their intended benefits, but contains no equations, fitted parameters, predictions, derivations, or self-citations. No load-bearing step reduces to its own inputs by construction, and the central claims remain conceptual rather than derived. This matches the expected non-finding for a specification-driven engineering paper without quantitative or formal derivation chains.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Model Context Protocol (MCP) Specification
2025. Model Context Protocol (MCP) Specification. https://modelcontextprotocol. io/specification/2025-06-18
2025
-
[2]
OpenTelemetry Documentation
2025. OpenTelemetry Documentation. https://opentelemetry.io/docs/
2025
-
[3]
LangChain Documentation
2026. LangChain Documentation. https://docs.langchain.com/
2026
-
[4]
LangSmith: AI Agent & LLM Observability Platform
2026. LangSmith: AI Agent & LLM Observability Platform. https://www. langchain.com/langsmith/observability
2026
-
[5]
Ragas Documentation: Evaluate LLM Applications
2026. Ragas Documentation: Evaluate LLM Applications. https://docs.ragas.io/ en/stable/getstarted/evals/
2026
-
[6]
TruLens: Evals and Tracing for Agents
2026. TruLens: Evals and Tracing for Agents. https://www.trulens.org/
2026
-
[7]
AGNTCY Project. 2025. Metrics Computation Engine (MCE): Metrics from OTel Observability Telemetry. https://github.com/agntcy/telemetry-hub
2025
-
[8]
AGNTCY Project. 2026. Open Agentic Schema Framework (OASF). https://docs. agntcy.org/oasf/open-agentic-schema-framework/
2026
-
[9]
Soufiane Amini, Yassine Benajiba, Cesare Bernardis, Paul Cayet, Hassan Chafi, Abderrahim Fathan, Louis Faucon, Damien Hilloulin, Sungpack Hong, Ingo Kossyk, Tran Minh Son Le, Rhicheek Patra, Sujith Ravi, Jonas Schweizer, Jyotika Singh, Shailender Singh, Weiyi Sun, Kartik Talamadupula, and Jerry Xu. 2025. Open Agent Specification (Agent Spec): A Unified Re...
-
[10]
Anthropic. 2024. Introducing the Model Context Protocol. https://www.anthropic. com/news/model-context-protocol
2024
-
[11]
Anthropic. 2024. Tool use with Claude. https://docs.anthropic.com/en/docs/build- with-claude/tool-use
2024
-
[12]
Hernán Alfredo Capucci. 2026. Agent Manifest: Core Declarative Specification v1.0. https://agent-manifest-spec.org/spec/v1.0/agent_manifest_v1.0.html
2026
-
[13]
Brian Casel. 2025. Agent OS: A System for Spec-Driven Development with AI Agents. https://github.com/buildermethods/agent-os. Open-source project, accessed April 2026
2025
-
[14]
Confident AI. 2024. DeepEval: The LLM Evaluation Framework. https://github. com/confident-ai/deepeval
2024
-
[15]
CrewAI Contributors. 2024. CrewAI: A Framework for Orchestrating Role-Based AI Agents. https://github.com/joaomdmoura/crewai
2024
-
[16]
deepset. 2024. Haystack Agents. https://haystack.deepset.ai
2024
-
[17]
Google and Industry Contributors. 2025. Agent2Agent (A2A) Protocol. https: //a2a-protocol.org. Emerging standard for agent interoperability; see also https://github.com/a2aproject/A2A
2025
-
[18]
Google DeepMind & Google Cloud. 2026. Google Agent Development Kit (ADK). https://google.github.io/adk-docs/
2026
- [19]
- [20]
-
[21]
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines
Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav San- thanam, Sri Vardhamanan, Saiful Haq, Ashutosh Sharma, Thomas T. Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts. 2024. DSPy: Com- piling Declarative Language Model Calls into Self-Improving Pipelines.arXiv preprint arXiv:2310.03714(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
LangChain. 2026. LangGraph Overview — LangChain Docs (Python). Online documentation. https://docs.langchain.com/oss/python/langgraph/overview
2026
-
[23]
Percy Liang, Rishi Bommasani, Tony Lee, et al . 2022. Holistic Evaluation of Language Models.arXiv preprint arXiv:2211.09110(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[24]
Linux Foundation AI & Data. 2026. AGNTCY: Open Infrastructure for Agent Interoperability. https://agntcy.org
2026
-
[25]
Xiao Liu, Hao Yu, Hanchen Zhang, et al. 2024. AgentBench: Evaluating LLMs as Agents.ICLR 2024(2024). https://arxiv.org/abs/2308.03688
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
LlamaIndex. 2026. LlamaIndex Documentation. https://docs.llamaindex.ai/
2026
-
[27]
Faustino, Guanheng Liu, Shan Zhang, Hongbin Luo, Suhaib A
Tie Ma, Yixi Chen, Vaastav Anand, Alessandro Cornacchia, Amândio R. Faustino, Guanheng Liu, Shan Zhang, Hongbin Luo, Suhaib A. Fahmy, Zafar A. Qazi, and Marco Canini. 2026. MAESTRO: Multi-Agent Evaluation Suite for Testing, Reliability, and Observability.arXiv(2026). arXiv:2601.00481 https://arxiv.org/ abs/2601.00481
-
[28]
Microsoft Corporation. 2026. Microsoft Agent Framework. https://github.com/ microsoft/agent-framework
2026
-
[29]
Oracle Labs. 2025. Open Agent Specification (AgentSpec). https://github.com/ oracle/agent-spec
2025
-
[30]
Outshift Open. 2025. MAS-Lab: Open-source Lab Implementations for Multi- Agent System Evaluation. https://github.com/outshift-open/mas-lab
2025
-
[31]
MemGPT: Towards LLMs as Operating Systems
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. 2024. MemGPT: Towards LLMs as Operating Systems. arXiv:2310.08560 [cs.AI] https://arxiv.org/abs/2310.08560
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Lauren Hong, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, Dahai Li, Zhiyuan Liu, and Maosong Sun
-
[33]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs.arXiv preprint arXiv:2307.16789(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Rivet. 2026. agent-os: A Portable Open-Source Operating System for AI Agents. https://github.com/rivet-dev/agent-os. Open-source project, accessed April 2026
2026
-
[35]
Qingyun Wu et al. 2024. AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation. https://github.com/microsoft/autogen
2024
-
[36]
Rui Ye, Keduan Huang, Qimin Wu, Yuzhu Cai, Tian Jin, Xianghe Pang, Xiangrui Liu, Jiaqi Su, Chen Qian, Bohan Tang, Kaiqu Liang, Jiaao Chen, Yue Hu, Zhenfei Yin, Rongye Shi, Bo An, Yang Gao, Wenjun Wu, Lei Bai, and Siheng Chen. 2025. MASLab: A Unified and Comprehensive Codebase for LLM-based Multi-Agent Systems.arXiv preprint arXiv:2505.16988(2025). https:/...
-
[37]
Asaf Yehudai, Lilach Eden, Alan Li, Guy Uziel, Yilun Zhao, Roy Bar-Haim, Arman Cohan, and Michal Shmueli-Scheuer. 2025. Survey on Evaluation of LLM-based Agents.arXiv preprint arXiv:2503.16416(2025). https://arxiv.org/abs/2503.16416
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [38]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.