Plan Right, Then Plan Tight: Symbolic RL for Efficient Embodied Reasoning
Pith reviewed 2026-07-01 05:18 UTC · model grok-4.3
The pith
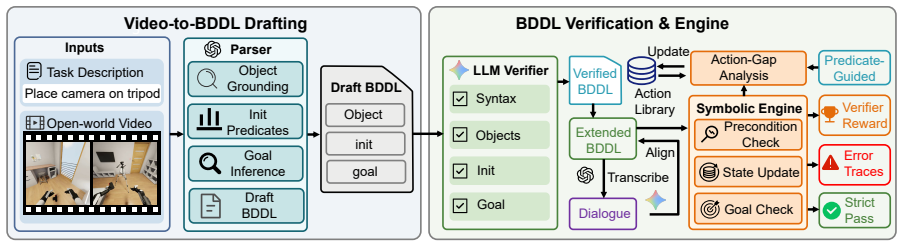
A single BDDL specification serves as the shared interface for data construction, plan verification, and reward design in embodied task planning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
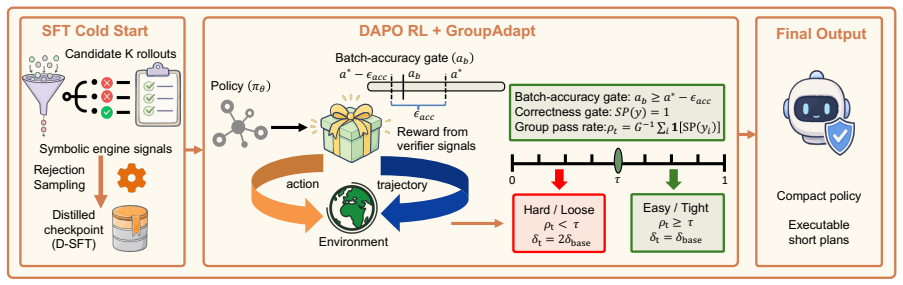
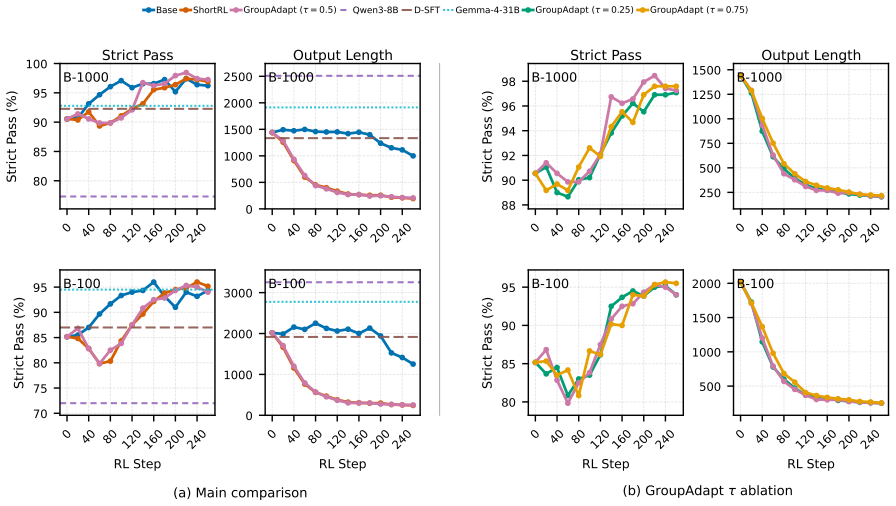
A single BDDL specification, automatically constructed from open-world video evidence or curated tasks, can serve as a shared interface for data construction, plan verification, and reward design. A video-to-BDDL parser, an LLM verifier, and a lightweight symbolic engine together supply dense feedback at millisecond latency. GroupAdapt, a difficulty-aware length schedule that uses the in-batch group pass rate as a zero-cost signal, grants hard prompts wider length tolerance that tightens as their pass rate improves. Under this guidance the 8B planner attains a Strict-Pass score of 97.3 on BEHAVIOR-1000, a 25.9 percent relative improvement over the Qwen3-8B baseline that also exceeds the stro
What carries the argument
The BDDL specification as a shared interface, together with the LLM verifier and the GroupAdapt length schedule, that supplies deterministic rewards and adaptive token budgets without full simulation.
If this is right
- Planners receive dense deterministic rewards at millisecond latency instead of waiting for full simulation rollouts.
- Response length can be compressed by nearly 80 percent while raising Strict-Pass rates above both same-size and larger baselines.
- Smaller 8B models can surpass the strongest large-model baselines on household-task benchmarks.
- In-batch pass rate supplies a zero-cost difficulty signal that automatically widens or tightens length tolerance during training.
Where Pith is reading between the lines
- The same BDDL interface could support continual online refinement if the video-to-BDDL parser is run on robot camera streams.
- Length compression may directly lower end-to-end latency when the planner runs on resource-limited robot hardware.
- Replacing BDDL with other formalisms such as PDDL or linear temporal logic would test whether the verification-plus-adaptation pattern generalizes beyond the current specification language.
- Combining the symbolic verifier with real-world execution traces could expose and correct systematic gaps between simulated and physical task requirements.
Load-bearing premise
A single automatically constructed BDDL specification can faithfully serve as the shared interface for data construction, plan verification, and reward design without introducing systematic mismatches between video evidence, the formal spec, and physical task requirements.
What would settle it
Executing a large sample of plans that pass the BDDL verifier inside the full BEHAVIOR simulator and measuring that a substantial fraction fail to complete the task due to unrepresented physical constraints or spec inaccuracies.
Figures



read the original abstract
Embodied task planning asks an agent to turn a natural-language instruction into an executable sequence of actions in a physical scene, and is a building block for household, assistive, and service robots. Recent prompting-based and reinforcement-learning planners generate fluent action text but lack a cheap deterministic check that the produced plan is valid in the target world, while high-fidelity simulation is too slow to serve as an inner-loop training signal. The general problem is therefore how to obtain verifiable supervision and rewards for embodied planners without relying on string-level matching or full simulation. Here we show that a single BDDL specification, automatically constructed from open-world video evidence or curated tasks, can serve as a shared interface for data construction, plan verification, and reward design. A video-to-BDDL parser, an LLM verifier, and a lightweight symbolic engine together supply dense feedback at millisecond latency. We further introduce GroupAdapt, a difficulty-aware length schedule that uses the in-batch group pass rate as a zero-cost signal so that hard prompts get wider length tolerance and automatically tighten as their pass rate improves. Under the guidance of the proposed verifier and GroupAdapt schedule, the 8B planner attains a Strict-Pass score of 97.3 on BEHAVIOR-1000, yielding a 25.9 percent relative improvement over the Qwen3-8B baseline. This result exceeds the strongest large-model baseline by 3.5 percent, while simultaneously compressing the response length by 79 percent to 207 tokens, demonstrating both effectiveness and efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a single automatically constructed BDDL specification from a video-to-BDDL parser can serve as a shared interface for data construction, LLM-based plan verification, and symbolic reward design in embodied task planning. Combined with a GroupAdapt difficulty-aware length schedule that uses in-batch pass rate as a signal, this enables an 8B planner to reach 97.3 Strict-Pass on BEHAVIOR-1000 (25.9% relative gain over Qwen3-8B baseline, exceeding strongest large-model baseline by 3.5%), while reducing response length by 79% to 207 tokens.
Significance. If the BDDL faithfulness assumption holds and the reported gains are reproducible, the work would demonstrate a practical route to dense, low-latency verifiable supervision for embodied planners that avoids both string matching and full simulation, enabling efficient training of smaller models with measurable gains in both accuracy and token efficiency.
major comments (2)
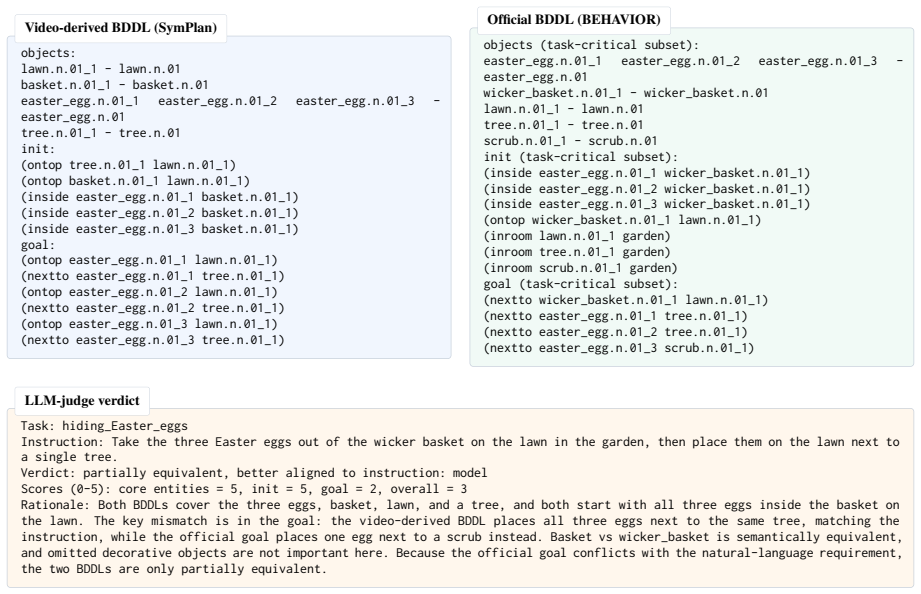
- [Abstract] Abstract: The central performance numbers (97.3 Strict-Pass, 25.9% relative improvement) rest on the video-to-BDDL parser supplying a faithful shared interface, yet the manuscript supplies no quantitative validation, error analysis, or ablation of the parser against human judgment or simulator ground truth. This is load-bearing for the claim that the verifier supplies reliable feedback.
- [Abstract] Abstract: No derivation, ablation, or sensitivity analysis is provided for the GroupAdapt schedule or its use of in-batch pass rate as the difficulty signal; the reported compression to 207 tokens and the Strict-Pass gains cannot be assessed for robustness without these controls.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for validation of the BDDL parser and analysis of the GroupAdapt schedule. Both points identify gaps in the current manuscript that we will address through additional experiments and exposition in the revision.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central performance numbers (97.3 Strict-Pass, 25.9% relative improvement) rest on the video-to-BDDL parser supplying a faithful shared interface, yet the manuscript supplies no quantitative validation, error analysis, or ablation of the parser against human judgment or simulator ground truth. This is load-bearing for the claim that the verifier supplies reliable feedback.
Authors: We agree that quantitative validation of the video-to-BDDL parser is essential to substantiate the shared-interface claim. The current manuscript relies on the parser for data construction and verification but does not report error rates or agreement metrics. In the revision we will add a dedicated section with parser accuracy against human annotations on 200 BEHAVIOR-1000 tasks and against simulator ground truth, including failure-mode categorization. This will directly support the reliability of the verifier feedback. revision: yes
-
Referee: [Abstract] Abstract: No derivation, ablation, or sensitivity analysis is provided for the GroupAdapt schedule or its use of in-batch pass rate as the difficulty signal; the reported compression to 207 tokens and the Strict-Pass gains cannot be assessed for robustness without these controls.
Authors: We concur that the absence of derivation and controls for GroupAdapt limits assessment of robustness. The manuscript introduces the schedule but provides no ablations on the in-batch pass-rate signal or sensitivity to its hyperparameters. In the revision we will include (i) a formal derivation of the length-tolerance update rule, (ii) an ablation replacing the pass-rate signal with fixed or oracle difficulty, and (iii) sensitivity plots over batch-size and pass-rate thresholds, showing impact on both Strict-Pass and token length. revision: yes
Circularity Check
No significant circularity; empirical result stands on external benchmark
full rationale
The paper reports an empirical Strict-Pass score of 97.3 on the external BEHAVIOR-1000 benchmark after training with a BDDL-based verifier and GroupAdapt schedule. GroupAdapt conditions length tolerance on in-batch pass rate, but this signal is not definitionally identical to the final Strict-Pass metric; the reported 25.9 % relative gain is therefore not forced by construction. No equations, self-citations, or ansatzes are shown that reduce the central claim to a renaming or fitted input of the same data. The derivation chain is self-contained against the stated benchmark.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
LLM+P: Empowering Large Language Models with Optimal Planning Proficiency
Let’s verify step by step. InInternational Conference on Learning Representations, volume 2024, pages 39578–39601. Bo Liu, Yuqian Jiang, Xiaohan Zhang, Qiang Liu, Shiqi Zhang, Joydeep Biswas, and Peter Stone. 2023a. Llm+ p: Empowering large language models with optimal planning proficiency.arXiv preprint arXiv:2304.11477. Shilong Liu, Zhaoyang Zeng, Tianh...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Virtualhome: Simulating household activities via programs. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 8494–8502. Krishan Rana, Jesse Haviland, Sourav Garg, Jad Abou- Chakra, Ian Reid, and Niko Suenderhauf. 2023. Say- plan: Grounding large language models using 3d scene graphs for scalable robot task planning.arX...
-
[3]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
Kimi k1. 5: Scaling reinforcement learning with llms.arXiv preprint arXiv:2501.12599. Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Man- dlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. 2023. V oyager: An open-ended embodied agent with large language models.arXiv preprint arXiv:2305.16291. Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosm...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Jianwei Yang, Hao Zhang, Feng Li, Xueyan Zou, Chun- yuan Li, and Jianfeng Gao. 2023. Set-of-mark prompting unleashes extraordinary visual grounding in gpt-4v.arXiv preprint arXiv:2310.11441. Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2022. React: Syner...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, and 1 others
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information pro- cessing systems, 36:46595–46623. Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, and 1 others. 2023. Rt-2: Vision-language-action models transfer web knowl- edge to robotic control. InConfer...
2023
-
[6]
repeated for 4 baskets Goal for each basket: inside(candle, basket) inside(cookie, basket) inside(cheese, basket) inside(bow, basket)
Verified BDDL Objects basket_1..4, candle_1..4 cookie_1..4, cheese_1..4 bow_1..4, table_1, table_2 + floor, agent, distractors Init (onfloor basket_1 floor) (ontop candle_1 table_1) (ontop cookie_1 table_1) (ontop cheese_1 table_2) (ontop bow_1 table_2) ... repeated for 4 baskets Goal for each basket: inside(candle, basket) inside(cookie, basket) inside(c...
-
[7]
Track hand state internally; grasp needs a free hand; place_* needs holding object
Model-facing prompt System You are a single-arm robot. Track hand state internally; grasp needs a free hand; place_* needs holding object. Environment (define (environment) (:objects ...) (:init ...)) Dialogue User: Please help me assemble the gift baskets. Assistant: Should each basket include candle, cookie, cheese, bow? User: Yes
-
[8]
</think> Executable plan <answer><steps>
Target training output Reasoning scaffold <think> Identify objects; track hands; order pick-and-place actions. </think> Executable plan <answer><steps>
-
[9]
go to table_1, grasp candle_1
-
[10]
20 steps total </steps><code> navigate(table_1) grasp(candle_1) place_inside(candle_1,basket_1)
go to basket_1, place inside ... 20 steps total </steps><code> navigate(table_1) grasp(candle_1) place_inside(candle_1,basket_1) ... </code></answer> Figure 7: Illustration of our data construction format.We parse the raw BDDL task, includ- ing its formal goal, then convert it into a model-facing prompt consisting of environment state, robot specification...
-
[11]
Uncovered goal predicates
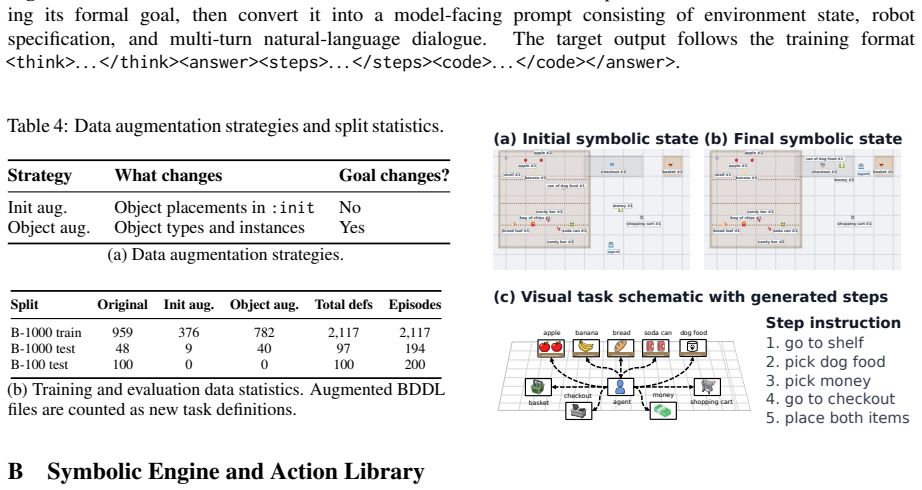
place both items Figure 8: Symbolic replay for buy_dog_food.The engine executes generated action code from the initial grocery-store state to the verified checkout state, using the same BDDL specification that was used to construct the planner input. B.2 Action Set Scaling Table 5 summarizes the action-set expansion from the 14-action B-100 engine to the ...
2026
-
[12]
Goal completion is reported as a fraction, and error rate is reported in percent
Each entry reports single-arm / dual-arm values. Goal completion is reported as a fraction, and error rate is reported in percent. Model Goal completion Error rate (%) Commands DeepSeek-V4-Flash 0.987 / 0.980 0.03 / 0.09 19.09 / 16.03 DeepSeek-V4-Pro 0.978 / 0.961 1.11 / 0.71 27.20 / 21.95 Gemini-3.1-Pro 0.897 / 0.890 0.00 / 0.02 17.77 / 14.73 Kimi-K2.6 0...
-
[13]
some- times pass
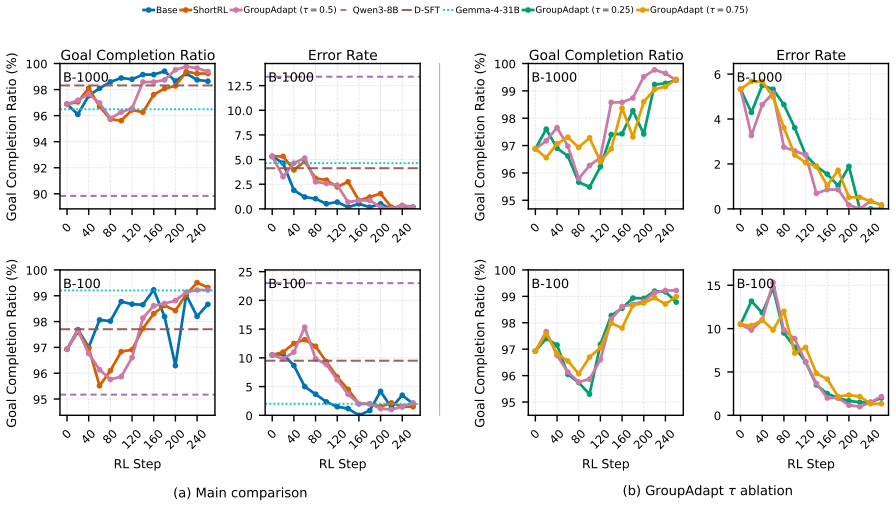
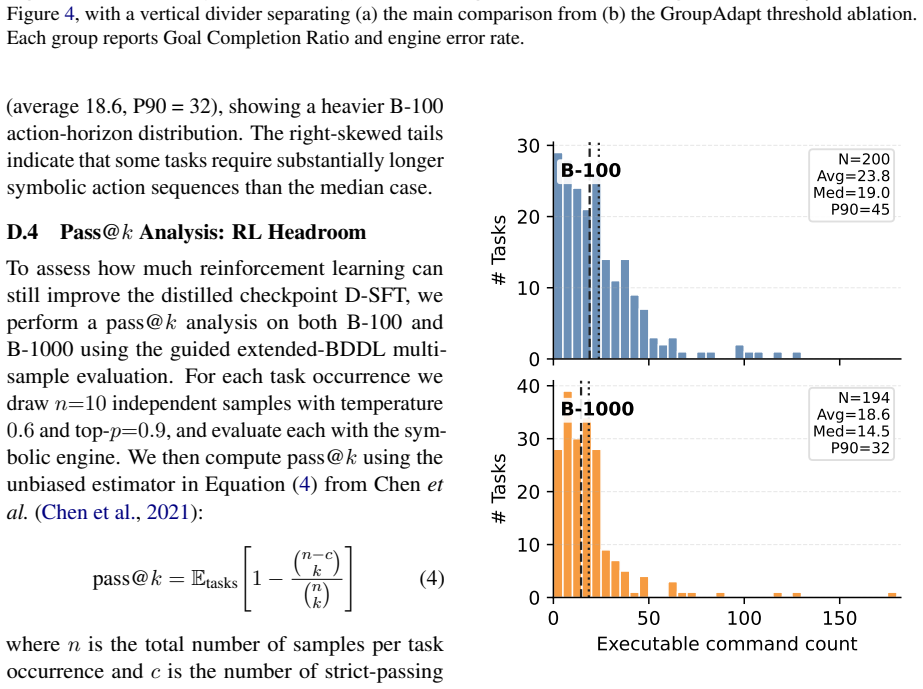
and a median of 14.5 commands on B-1000 16 0 40 80 120160200240 90 92 94 96 98 100 Goal Completion Ratio (%) B-1000 Goal Completion Ratio 0 40 80 120160200240 0.0 2.5 5.0 7.5 10.0 12.5 B-1000 Error Rate 0 40 80 120160200240 95 96 97 98 99 100 Goal Completion Ratio (%) B-1000 Goal Completion Ratio 0 40 80 120160200240 0 2 4 6 B-1000 Error Rate 0 40 80 1201...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.