StereoFactory: A Unified Merging Framework for Robust Stereo Matching
Pith reviewed 2026-06-27 01:58 UTC · model grok-4.3
The pith
StereoFactory merges stereo models with genetic search and CMA-ES routing to beat retraining on benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
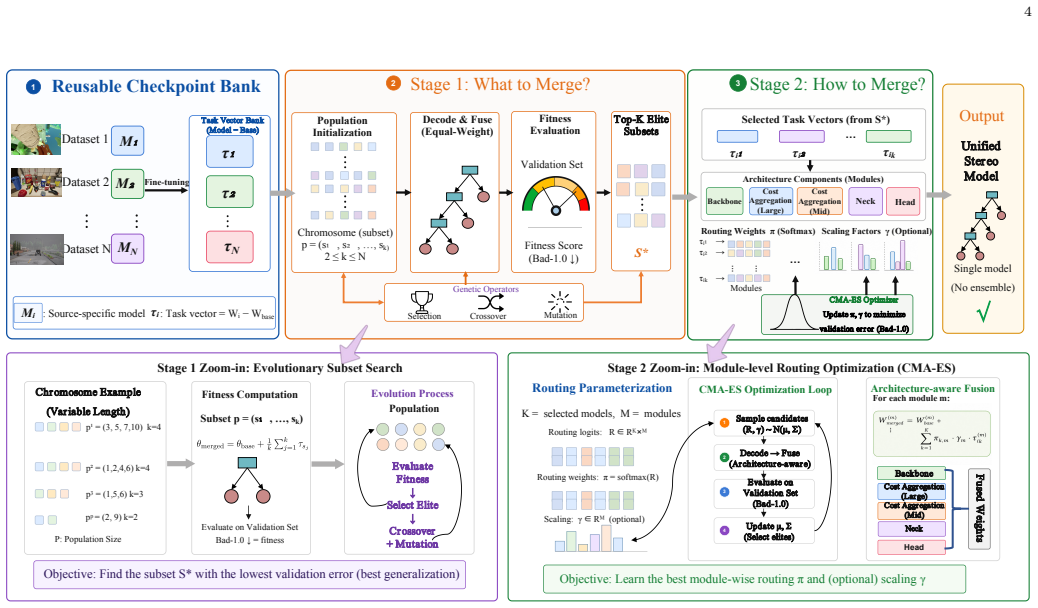
StereoFactory is a coarse-to-fine evolutionary framework that first uses a genetic algorithm to search the combinatorial space of model subsets and then CMA-ES optimization of architecture-adaptive routing over the selected task vectors, with optional module-level scaling, achieving the best four-benchmark average under the same checkpoint pool while requiring only 2.7--3.7% of joint-retraining wall-clock time.
What carries the argument
The two-stage evolutionary process of genetic-algorithm subset selection followed by CMA-ES optimization of module-level routing over task vectors.
Load-bearing premise
The genetic algorithm search for model subsets and the subsequent CMA-ES optimization of module-level routing will generalize beyond the specific validation data used during the search without introducing selection bias or overfitting.
What would settle it
Running the merged models on a new stereo matching benchmark withheld from the search process and finding that the error reduction disappears or reverses relative to the strongest baseline would falsify the central performance claim.
Figures

read the original abstract
Stereo matching has advanced through foundation models trained on large-scale datasets, yet this paradigm suffers from a scalability bottleneck: incorporating new data requires costly joint retraining. Model merging offers a scalable post-hoc alternative by integrating knowledge from specialized models after source checkpoints are available. However, existing merging methods typically retain all available models or rely on greedy inclusion, which can preserve harmful task-vector interference. We propose StereoFactory, a coarse-to-fine evolutionary framework for adaptive model merging. Stage~1 employs a genetic algorithm to search the combinatorial space of model subsets, determining which models should participate. Stage~2 addresses module-level knowledge specialization (different functional modules exhibit distinct preferences for knowledge sources) through CMA-ES optimization of architecture-adaptive routing over the selected task vectors, with optional module-level scaling. Experiments across two architectures and four benchmarks demonstrate that StereoFactory consistently achieves the best four-benchmark average under the same checkpoint pool, reducing the average error from 3.80 to 3.30 on NMRF and from 2.88 to 2.19 on FoundationStereo relative to the strongest controlled baseline. The post-hoc search requires only 2.7--3.7\% of the corresponding joint-retraining wall-clock time. Analysis reveals that knowledge contributions are inherently module-specific, and selected subsets can transfer across architectures with minimal degradation. Code will be publicly released upon acceptance at: https://github.com/XiandaGuo/StereoFactory.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
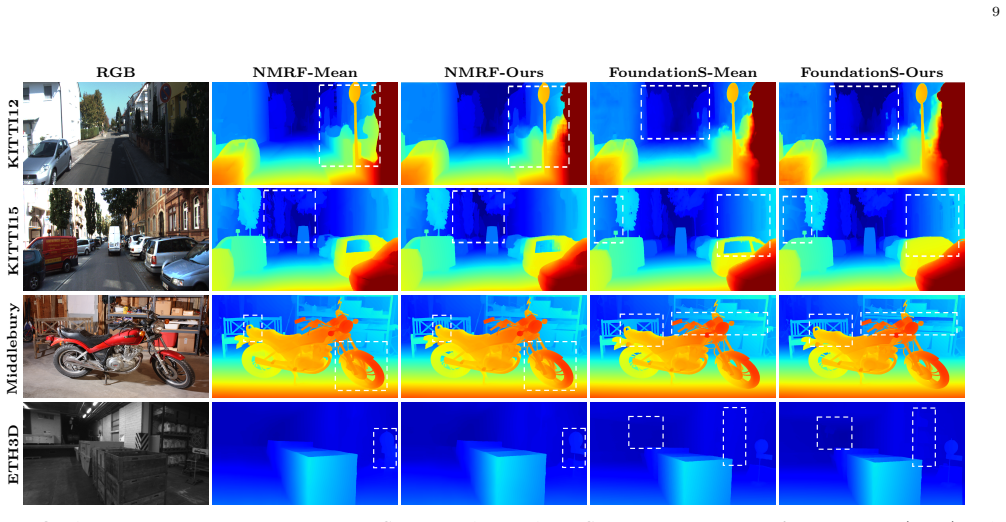
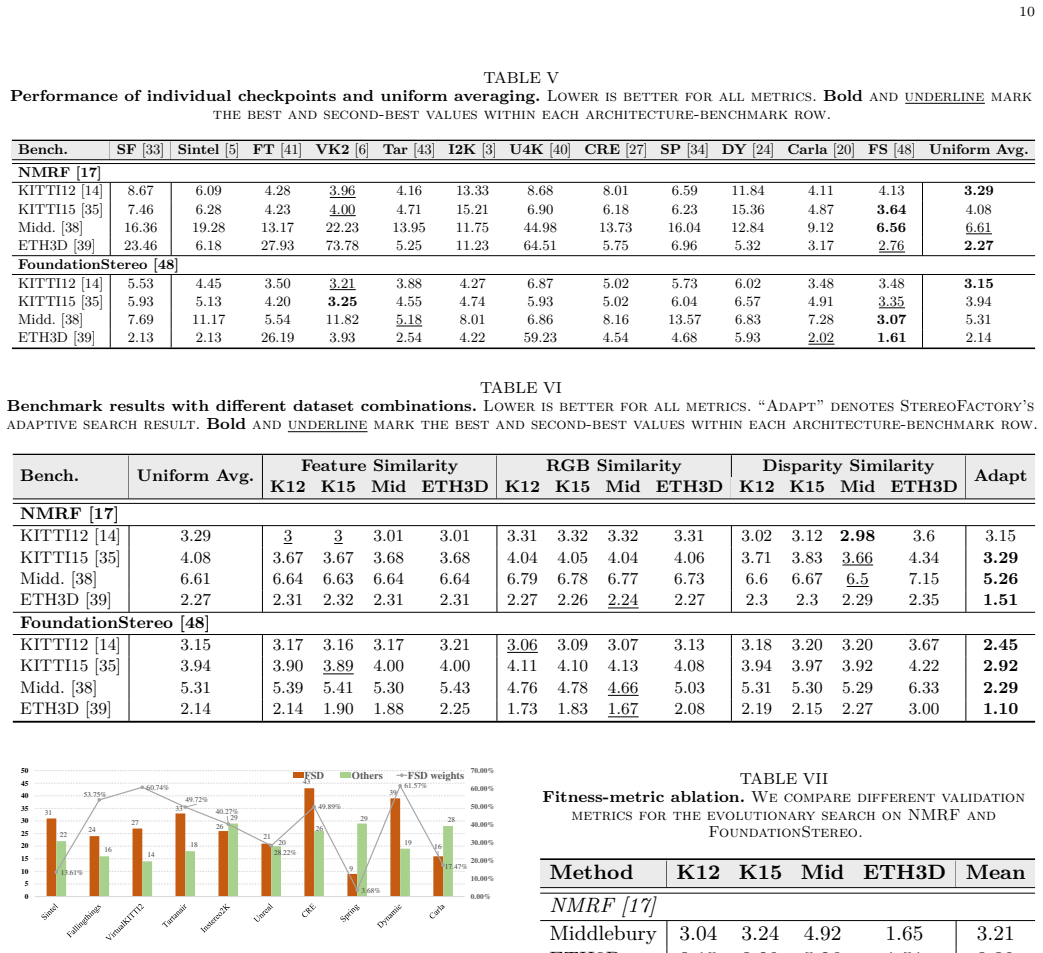
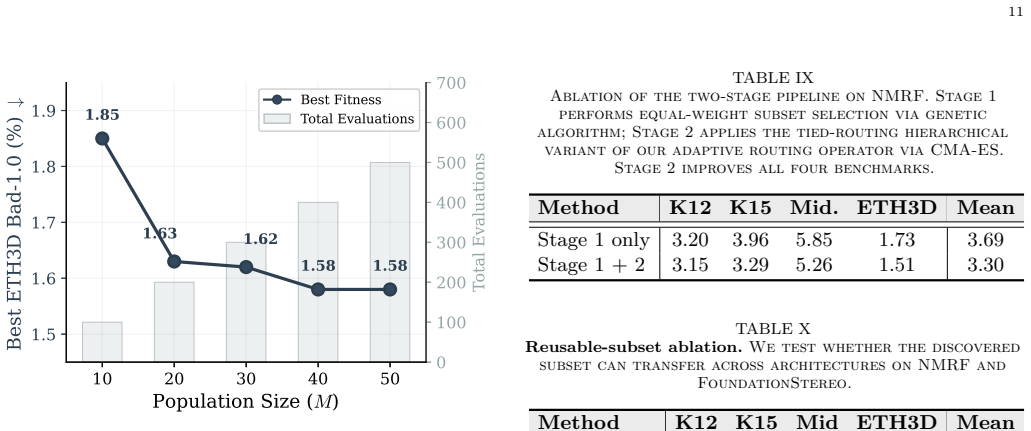
Summary. The paper presents StereoFactory, a coarse-to-fine evolutionary model-merging framework for stereo matching. Stage 1 applies a genetic algorithm to search over subsets of available checkpoints; Stage 2 applies CMA-ES to optimize module-level routing (and optional scaling) over the selected task vectors. The central empirical claim is that the resulting merged models achieve the best four-benchmark average under a fixed checkpoint pool, reducing average error from 3.80 to 3.30 (NMRF) and from 2.88 to 2.19 (FoundationStereo) relative to the strongest controlled baseline, while requiring only 2.7–3.7 % of the wall-clock time of joint retraining. Additional claims include module-specific knowledge contributions and limited degradation when subsets transfer across architectures.
Significance. If the reported gains survive proper controls for search overfitting, the work supplies a practical post-hoc route to incorporating new stereo data without full retraining of foundation models. The planned public code release and the explicit analysis of module-level specialization are concrete strengths that would aid reproducibility and further research.
major comments (2)
- [Experiments] Experiments section: the manuscript provides no description of held-out validation splits used during the genetic-algorithm subset search or the subsequent CMA-ES routing optimization. Because the four reported benchmarks supply both the checkpoint pool and the final metrics, the absence of such splits leaves open the possibility that the discovered configurations exploit benchmark-specific statistics rather than generalizing.
- [Abstract and Experiments] Abstract and Experiments: the quantitative claims (e.g., error reductions to 3.30 and 2.19) are presented without reporting the number of independent search runs, standard deviations, or statistical significance tests, and without explicit controls for post-hoc selection bias in the evolutionary procedure. These omissions directly affect the load-bearing claim that StereoFactory “consistently achieves the best four-benchmark average.”
minor comments (1)
- [Abstract] The abstract states that code “will be publicly released upon acceptance” yet already supplies a GitHub link; the repository should include the precise search seeds, validation splits (if any), and configuration files used to produce the reported numbers.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on experimental validation and statistical reporting. We address each major comment below and will incorporate revisions to strengthen these aspects of the manuscript.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the manuscript provides no description of held-out validation splits used during the genetic-algorithm subset search or the subsequent CMA-ES routing optimization. Because the four reported benchmarks supply both the checkpoint pool and the final metrics, the absence of such splits leaves open the possibility that the discovered configurations exploit benchmark-specific statistics rather than generalizing.
Authors: We agree this is a valid concern: the manuscript does not describe held-out splits, and direct optimization on the reported benchmarks could in principle allow exploitation of benchmark-specific statistics. In the original experiments the searches operated on the standard benchmark evaluation protocols to identify merging configurations. For the revision we will add an explicit held-out validation protocol (reserving one benchmark or a data subset exclusively for search and CMA-ES, with final metrics reported on the remaining benchmarks) and update the Experiments section accordingly to demonstrate generalization. revision: yes
-
Referee: [Abstract and Experiments] Abstract and Experiments: the quantitative claims (e.g., error reductions to 3.30 and 2.19) are presented without reporting the number of independent search runs, standard deviations, or statistical significance tests, and without explicit controls for post-hoc selection bias in the evolutionary procedure. These omissions directly affect the load-bearing claim that StereoFactory “consistently achieves the best four-benchmark average.”
Authors: We acknowledge that the current presentation lacks multiple-run statistics, standard deviations, significance tests, and explicit bias controls, which weakens the “consistently” claim. The reported numbers reflect single-run searches performed under computational constraints. In the revised manuscript we will rerun the genetic algorithm and CMA-ES for multiple independent trials (minimum 5 runs), report means and standard deviations in the tables, add statistical significance tests (e.g., paired t-tests against baselines), and include additional controls such as random-subset and greedy baselines to quantify post-hoc selection effects. The abstract and Experiments section will be updated to reflect these results. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes an empirical post-hoc optimization procedure (genetic algorithm for subset selection followed by CMA-ES for module routing) applied to existing model checkpoints. Performance numbers are reported as direct outcomes of this optimization on the evaluation benchmarks, but the derivation chain does not reduce any claimed result to its inputs by construction, nor does it rely on self-citations, ansatzes smuggled via prior work, or renaming of known results. The method is self-contained as a standard evolutionary search whose outputs are compared against controlled baselines; no load-bearing step equates the final metric to the search objective by definition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Akiba, M
T. Akiba, M. Shing, Y. Tang, Q. Sun, and D. Ha. Evolution- ary optimization of model merging recipes.Nature Machine Intelligence, 2025
2025
-
[2]
T. H. W. B¨ ack, A. V. Kononova, B. van Stein, H. Wang, K. A. Antonov, R. T. Kalkreuth, J. de Nobel, D. Vermetten, R. de Winter, and F. Ye. Evolutionary algorithms for parameter optimization—thirty years later.Evolutionary Computation, 2023
2023
-
[3]
W. Bao, W. Wang, Y. Xu, Y. Guo, S. Hong, and X. Zhang. Instereo2k: a large real dataset for stereo matching in indoor scenes.Science China Information Sciences, 2020
2020
-
[4]
Y. Bi, B. Xue, P. Mesejo, S. Cagnoni, and M. Zhang. A survey on evolutionary computation for computer vision and image analysis: Past, present, and future trends.IEEE Transactions on Evolutionary Computation, 2023
2023
-
[5]
D. J. Butler, J. Wulff, G. B. Stanley, and M. J. Black. A naturalistic open source movie for optical flow evaluation. In ECCV, 2012
2012
-
[6]
Y. Cabon, N. Murray, and M. Humenberger. Virtual kitti 2. arXiv preprint arXiv:2001.10773, 2020
Pith/arXiv arXiv 2001
-
[7]
Chang and Y.-S
J.-R. Chang and Y.-S. Chen. Pyramid stereo matching network. InCVPR, 2018
2018
-
[8]
Chang, X
T. Chang, X. Yang, T. Zhang, and M. Wang. Domain generalized stereo matching via hierarchical visual transformation. InCVPR, 2023
2023
-
[9]
Cheng, H
C. Cheng, H. Li, and L. Zhang. Two-branch deconvolutional network with application in stereo matching.TIP, 2022
2022
-
[10]
Z. Dai, Z. Tang, H. Zhang, and Y. Xie. Mgs-stereo: Multi-scale geometric-structure-enhanced stereo matching for complex real- world scenes.TIP, 2025
2025
-
[11]
Y. Deng, J. Xiao, S. Z. Zhou, and J. Feng. Detail preserving coarse-to-fine matching for stereo matching and optical flow. TIP, 2021
2021
-
[12]
T. G. Dietterich. Ensemble methods in machine learning. In Multiple Classifier Systems, 2000
2000
-
[13]
Z. Gao, Y. Li, J. Zhang, R. Zhao, T. Wu, H. Tang, Z. Yu, H. Dong, G. Chen, and T. Huang. Spikestereonet: A brain-inspired framework for stereo depth estimation from spike streams. In ICLR, 2026
2026
-
[14]
Geiger, P
A. Geiger, P. Lenz, and R. Urtasun. Are we ready for autonomous driving? the kitti vision benchmark suite. InCVPR, 2012
2012
-
[15]
J. L. Gray, A. T. Naman, and D. S. Taubman. Multi-view disparity estimation using the gradient consistency model.TIP, 2025
2025
-
[16]
T. Guan, J. Guo, T. Huang, J. Dong, C. Wang, and Y.-H. Liu. DispViT: Direct Stereo Disparity Regression with a Single- Stream Vision Transformer. InICLR, 2026
2026
-
[17]
T. Guan, C. Wang, and Y.-H. Liu. Neural markov random field for stereo matching. InCVPR, 2024
2024
-
[18]
X. Guo, J. Lu, C. Zhang, Y. Wang, Y. Duan, T. Yang, Z. Zhu, and L. Chen. Openstereo: A comprehensive benchmark for stereo matching and strong baseline.arXiv preprint arXiv:2312.00343, 2023
arXiv 2023
-
[19]
X. Guo, K. Yang, W. Yang, X. Wang, and H. Li. Group-wise correlation stereo network. InCVPR, 2019
2019
-
[20]
X. Guo, C. Zhang, R. Wang, Y. Zhang, W. Zheng, M. Poggi, H. Zhao, Q. Zou, and L. Chen. Stereocarla: A high-fidelity driving dataset for generalizable stereo.arXiv preprint arXiv:2509.12683, 2025
arXiv 2025
-
[21]
X. Guo, C. Zhang, Y. Zhang, R. Wang, D. Nie, W. Zheng, M. Poggi, H. Zhao, M. Ye, Q. Zou, et al. Stereo anything: Unifying zero-shot stereo matching with large-scale mixed data. arXiv preprint arXiv:2411.14053, 2024
arXiv 2024
-
[22]
Hansen and A
N. Hansen and A. Ostermeier. Completely derandomized self- adaptation in evolution strategies.Evolutionary Computation, 2001
2001
-
[23]
Ilharco, M
G. Ilharco, M. T. Ribeiro, M. Wortsman, L. Schmidt, H. Ha- jishirzi, and A. Farhadi. Editing models with task arithmetic. InProceedings of the International Conference on Learning Representations, 2023
2023
-
[24]
Karaev, I
N. Karaev, I. Rocco, B. Graham, N. Neverova, A. Vedaldi, and C. Rupprecht. Dynamicstereo: Consistent dynamic depth from stereo videos. InIROS, 2023
2023
-
[25]
Kendall, H
A. Kendall, H. Martirosyan, S. Dasgupta, P. Henry, R. Kennedy, A. Bachrach, and A. Bry. End-to-end learning of geometry and context for deep stereo regression. InICCV, 2017
2017
-
[26]
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y. Chen, K. Ellis, et al. Droid: A large-scale in-the-wild robot manipulation dataset. arXiv preprint arXiv:2403.12945, 2024
Pith/arXiv arXiv 2024
-
[27]
J. Li, P. Wang, P. Xiong, T. Cai, Z. Yan, L. Yang, J. Liu, H. Fan, and S. Liu. Practical stereo matching via cascaded recurrent network with adaptive correlation. InCVPR, 2022
2022
-
[28]
N. Li, L. Ma, G. Yu, B. Xue, M. Zhang, and Y. Jin. Survey on evolutionary deep learning: Principles, algorithms, applications and open issues.ACM Computing Surveys, 2024
2024
-
[29]
Lipson, Z
L. Lipson, Z. Teed, and J. Deng. Raft-stereo: Multilevel recurrent field transforms for stereo matching. In3DV, 2021
2021
-
[30]
Y. Liu, Y. Sun, B. Xue, M. Zhang, G. G. Yen, and K. C. Tan. A survey on evolutionary neural architecture search.TNNLS, 2023
2023
-
[31]
I. Loshchilov and F. Hutter. CMA-ES for hyperparame- ter optimization of deep neural networks.arXiv preprint arXiv:1604.07269, 2016
Pith/arXiv arXiv 2016
-
[32]
M. S. Matena and C. A. Raffel. Merging models with fisher- weighted averaging. InNeurIPS, 2022
2022
-
[33]
Mayer, E
N. Mayer, E. Ilg, P. Hausser, P. Fischer, D. Cremers, A. Doso- vitskiy, and T. Brox. A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation. InCVPR, 2016
2016
-
[34]
L. Mehl, J. Schmalfuss, A. Jahedi, Y. Nalivayko, and A. Bruhn. Spring: A high-resolution high-detail dataset and benchmark for scene flow, optical flow and stereo. InCVPR, 2023
2023
-
[35]
Menze and A
M. Menze and A. Geiger. Object scene flow for autonomous vehicles. InCVPR, 2015
2015
-
[36]
Ranftl, K
R. Ranftl, K. Lasinger, D. Hafner, K. Schindler, and V. Koltun. Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer.IEEE transactions on pattern analysis and machine intelligence, 2020
2020
-
[37]
Z. Rao, B. Xiong, M. He, Y. Dai, R. He, Z. Shen, and X. Li. Masked representation learning for domain generalized stereo matching. InCVPR, 2023
2023
-
[38]
Scharstein, H
D. Scharstein, H. Hirschm¨ uller, Y. Kitajima, G. Krathwohl, N. Neˇ si´ c, X. Wang, and P. Westling. High-resolution stereo 13 datasets with subpixel-accurate ground truth. InGCPR, 2014
2014
-
[39]
Sch¨ ops, J
T. Sch¨ ops, J. L. Sch¨ onberger, S. Galliani, T. Sattler, K. Schindler, M. Pollefeys, and A. Geiger. A multi-view stereo benchmark with high-resolution images and multi-camera videos. InCVPR, 2017
2017
-
[40]
F. Tosi, Y. Liao, C. Schmitt, and A. Geiger. Smd-nets: Stereo mixture density networks. InCVPR, 2021
2021
-
[41]
Tremblay, T
J. Tremblay, T. To, and S. Birchfield. Falling things: A synthetic dataset for 3d object detection and pose estimation. InCVPRW, 2018
2018
-
[42]
S. Wang, J. Sun, B. Fan, Q. Wang, B. Lu, and Y. Dai. Ec-mvsnet: Enhanced cascaded multi-view stereo with cross-scale relevance integration. InAAAI, 2026
2026
-
[43]
W. Wang, D. Zhu, X. Wang, Y. Hu, Y. Qiu, C. Wang, Y. Hu, A. Kapoor, and S. Scherer. Tartanair: A dataset to push the limits of visual slam. InIROS, 2020
2020
-
[44]
X. Wang, G. Xu, H. Jia, and X. Yang. Selective-stereo: Adaptive frequency information selection for stereo matching. InCVPR, 2024
2024
-
[45]
Y. Wang, K. Li, L. Wang, J. Hu, D. Oliver Wu, and Y. Guo. Adstereo: Efficient stereo matching with adaptive downsampling and disparity alignment.TIP, 2025
2025
-
[46]
Y. Wang, Z. Yang, J. Zheng, Z. Zhang, D. O. Wu, and Y. Guo. Smformer: Empowering self-supervised stereo matching via foundation models and data augmentation.TIP, 2026
2026
-
[47]
B. Wen, S. Dewan, and S. Birchfield. Fast-foundationstereo: Real-time zero-shot stereo matching. InCVPR, 2026
2026
-
[48]
B. Wen, M. Trepte, J. Aribido, J. Kautz, O. Gallo, and S. Birch- field. FoundationStereo: Zero-shot stereo matching. InCVPR, 2025
2025
-
[49]
Wortsman, G
M. Wortsman, G. Ilharco, S. Y. Gadre, R. Roelofs, R. Gontijo- Lopes, A. S. Morcos, H. Namkoong, A. Farhadi, Y. Carmon, S. Kornblith, and L. Schmidt. Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time. InICML, 2022
2022
-
[50]
G. Xu, X. Wang, X. Ding, and X. Yang. Iterative geometry encoding volume for stereo matching. InCVPR, 2023
2023
-
[51]
G. Xu, X. Wang, Z. Zhang, J. Cheng, C. Liao, and X. Yang. Igev++: iterative multi-range geometry encoding volumes for stereo matching.TPAMI, 2025
2025
-
[52]
Xu and J
H. Xu and J. Zhang. Aanet: Adaptive aggregation network for efficient stereo matching. InCVPR, 2020
2020
-
[53]
P. Xu, Z. Xiang, C. Qiao, J. Fu, and T. Pu. Adaptive multi-modal cross-entropy loss for stereo matching. InCVPR, 2024
2024
- [54]
-
[55]
Yadav, D
P. Yadav, D. Tam, L. Choshen, C. Raffel, and M. Bansal. Ties-merging: Resolving interference when merging models. In NeurIPS, 2023
2023
-
[56]
E. Yang, L. Shen, G. Guo, X. Wang, X. Cao, J. Zhang, and D. Tao. Model merging in LLMs, MLLMs, and beyond: Methods, theories, applications and opportunities.arXiv preprint arXiv:2408.07666, 2024
Pith/arXiv arXiv 2024
-
[57]
E. Yang, Z. Wang, L. Shen, S. Liu, G. Guo, X. Wang, and D. Tao. Adamerging: Adaptive model merging for multi-task learning. InICLR, 2024
2024
-
[58]
L. Yang, B. Kang, Z. Huang, X. Xu, J. Feng, and H. Zhao. Depth anything: Unleashing the power of large-scale unlabeled data. In CVPR, 2024
2024
-
[59]
L. Yang, B. Kang, Z. Huang, Z. Zhao, X. Xu, J. Feng, and H. Zhao. Depth anything v2.arXiv preprint arXiv:2406.09414, 2024
Pith/arXiv arXiv 2024
-
[60]
M. Yang, F. Wu, and W. Li. Rlstereo: Real-time stereo matching based on reinforcement learning.TIP, 2021
2021
-
[61]
L. Yu, B. Yu, H. Yu, F. Huang, and Y. Li. Language models are super mario: Absorbing abilities from homologous models as a free lunch. InICML, 2024
2024
-
[62]
K. Zeng, Y. Wang, J. Mao, C. Liu, W. Peng, and Y. Yang. Deep stereo matching with hysteresis attention and supervised cost volume construction.TIP, 2022
2022
-
[63]
Zhang, X
F. Zhang, X. Qi, R. Yang, V. Prisacariu, B. Wah, and P. Torr. Domain-invariant stereo matching networks. InECCV, 2020
2020
-
[64]
Zhang, L
J. Zhang, L. Jing, Y. Wang, X. Li, G. Yang, S. Jin, and C. Qiu. Geometry-aware stereo matching via monocular disparity distribution prior and gradient enhancement. InAAAI, 2026
2026
-
[65]
Zhang, L
Y. Zhang, L. Wang, K. Li, Y. Wang, and Y. Guo. Learning representations from foundation models for domain generalized stereo matching. InECCV, 2024
2024
-
[66]
Zheng, Q
J. Zheng, Q. Liu, H. Xu, and Z. Chen. Pip-stereo: Progressive iterations pruner for iterative optimization based stereo matching. InCVPR, 2026. Xianda Guois currently a Ph.D. student at the School of Computer Science, Wuhan University. Before that, he received a mas- ter’s degree from the Dalian University of Technology in 2019. His work is mainly in comp...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.