DOTRAG: Retrieval-Time Reasoning Along Paths
Pith reviewed 2026-05-21 09:07 UTC · model grok-4.3
The pith
DotRAG reformulates graph retrieval as a reasoning process over paths using query-conditioned constraints.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DotRAG is a training-free GraphRAG framework that reformulates retrieval as a reasoning process over paths. It generates query-conditioned constraints to guide graph exploration, prune irrelevant regions, and discover relational paths without explicit step-by-step reasoning chains. Division of Thought decomposes retrieval into localized search spaces and adapts the search strategy to each query, leading to state-of-the-art performance on MetaQA and UltraDomain with gains on multi-hop tasks.
What carries the argument
Division of Thought (DOT), an abstraction that decomposes retrieval into localized search spaces and adapts the search strategy to each query through query-conditioned constraints.
If this is right
- Improves accuracy on multi-hop question answering over graphs by focusing on relevant paths.
- Reduces irrelevant context accumulation compared to heuristic-based retrieval.
- Enables effective retrieval without model training or predefined reasoning steps.
- Achieves state-of-the-art results on standard benchmarks like MetaQA and UltraDomain.
Where Pith is reading between the lines
- The constraint generation approach might extend to non-graph retrieval tasks that involve structured data.
- Combining this with other reasoning techniques could further enhance performance on varied query types.
- Testing on larger or more diverse knowledge graphs would reveal the scalability of the path reasoning method.
Load-bearing premise
The assumption that generating query-conditioned constraints can reliably guide graph exploration, prune irrelevant regions, and discover correct relational paths without explicit step-by-step reasoning chains or any model training.
What would settle it
An experiment showing that on new multi-hop queries, the constraints do not lead to higher path discovery accuracy than standard retrieval methods would falsify the central claim.
Figures












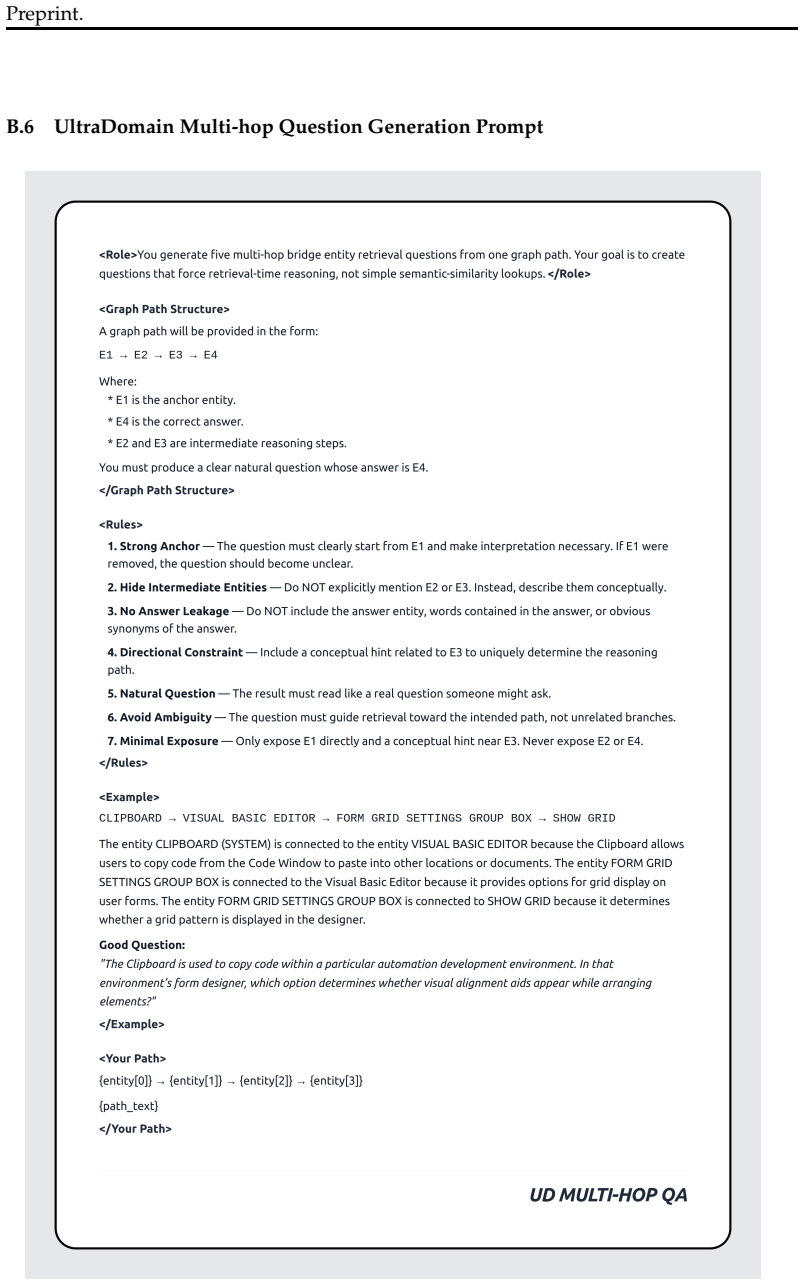
read the original abstract
Graph Retrieval-Augmented Generation (GraphRAG) is dominated by a retrieve-then-reason paradigm, where context is retrieved using heuristics and then reasoned over. Such methods struggle to adapt to the query-specific logic required for complex multi-hop tasks, often accumulating irrelevant context or missing correct relational paths. We propose DotRAG, a training-free GraphRAG framework that reformulates retrieval as a reasoning process over paths. Our approach generates query-conditioned constraints that guide graph exploration, prune irrelevant regions, and iteratively discover relational paths without relying on explicit step-by-step reasoning chains. We introduce Division of Thought (DOT), an abstraction that decomposes retrieval into localized search spaces and adapts the search strategy to each query. DotRAG achieves SOTA performance on MetaQA and UltraDomain, with consistent gains on multi-hop tasks, demonstrating the effectiveness of reasoning-guided retrieval.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DotRAG, a training-free GraphRAG framework that reformulates retrieval as a reasoning process over paths. It introduces Division of Thought (DOT) to generate query-conditioned constraints that guide graph exploration, prune irrelevant regions, and iteratively discover relational paths without explicit step-by-step reasoning chains or model training. The central claim is that this approach achieves SOTA performance on MetaQA and UltraDomain, with consistent gains on multi-hop tasks.
Significance. If the performance claims are substantiated, the work would be significant for cs.IR by offering a training-free alternative to retrieve-then-reason GraphRAG paradigms. The integration of query-specific constraint generation directly into path-based retrieval could improve adaptability for multi-hop reasoning while avoiding accumulation of irrelevant context. The emphasis on a parameter-free, reasoning-guided search strategy is a clear strength if empirically validated.
major comments (2)
- [Abstract and §5] Abstract and §5 (Experiments): The abstract asserts SOTA results on MetaQA and UltraDomain with gains on multi-hop tasks, yet the provided manuscript text supplies no experimental details, baselines, error bars, pseudocode, or ablation studies. This directly undermines assessment of whether the data support the central performance claim.
- [§3.2] §3.2 (Division of Thought): The claim that LLM-generated query-conditioned constraints can reliably decompose retrieval, prune irrelevant graph regions, and surface correct relational paths without explicit chains or training is load-bearing for the method. No concrete validation (e.g., constraint quality metrics or failure-case analysis) is shown, leaving the zero-shot inference assumption untested against the skeptic concern that omitted relations or over-pruning would degrade multi-hop accuracy.
minor comments (2)
- [§3] The notation for localized search spaces in the DOT abstraction could be illustrated with a small worked example to improve clarity.
- [§5] Ensure all dataset splits and evaluation metrics (e.g., exact match vs. F1) are explicitly defined in the experimental section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our submission. The comments highlight important areas for strengthening the empirical support and methodological transparency. We respond to each major comment below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Abstract and §5] Abstract and §5 (Experiments): The abstract asserts SOTA results on MetaQA and UltraDomain with gains on multi-hop tasks, yet the provided manuscript text supplies no experimental details, baselines, error bars, pseudocode, or ablation studies. This directly undermines assessment of whether the data support the central performance claim.
Authors: We agree that the experimental details must be presented more explicitly to allow proper evaluation of the SOTA claims. The full manuscript contains Section 5 with results on MetaQA and UltraDomain, but we acknowledge that the version reviewed may have omitted full tables, baseline descriptions, error bars from repeated runs, algorithm pseudocode, and ablation studies. In the revised version we will expand both the abstract (with a brief mention of key metrics and baselines) and §5 to include complete experimental details, comparisons against retrieve-then-reason GraphRAG methods and other multi-hop baselines, standard deviations, pseudocode for the DOT-guided path search, and ablations isolating the contribution of query-conditioned constraints. revision: yes
-
Referee: [§3.2] §3.2 (Division of Thought): The claim that LLM-generated query-conditioned constraints can reliably decompose retrieval, prune irrelevant graph regions, and surface correct relational paths without explicit chains or training is load-bearing for the method. No concrete validation (e.g., constraint quality metrics or failure-case analysis) is shown, leaving the zero-shot inference assumption untested against the skeptic concern that omitted relations or over-pruning would degrade multi-hop accuracy.
Authors: We recognize that the reliability of the LLM-generated constraints is central to the approach and that additional evidence would address potential concerns about over-pruning or missed relations. The current §3.2 provides the algorithmic description and illustrative examples, but does not report quantitative constraint-quality metrics. In the revision we will add a dedicated analysis subsection that reports (1) statistics on the fraction of graph edges pruned by the generated constraints across queries, (2) manual or automated checks of constraint fidelity on a sample of MetaQA and UltraDomain instances, and (3) qualitative failure-case analysis showing both successful path discovery and cases where constraints were too restrictive or omitted key relations. These additions will directly test the zero-shot assumption. revision: yes
Circularity Check
No circularity: DotRAG is a self-contained training-free proposal
full rationale
The paper introduces DotRAG and Division of Thought (DOT) as a new training-free GraphRAG approach that generates query-conditioned constraints to guide path-based retrieval. No load-bearing step reduces by construction to a fitted parameter, self-citation chain, or renamed prior result. The method is explicitly presented as independent of explicit reasoning chains or model training, with performance claims framed as empirical outcomes on MetaQA and UltraDomain rather than derived predictions. The derivation chain relies on LLM zero-shot inference for constraints, which does not loop back to the paper's own inputs or definitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Relational paths in the graph can be discovered and pruned using query-generated constraints without step-by-step explicit reasoning
invented entities (1)
-
Division of Thought (DOT)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
generates query-conditioned constraints that guide graph exploration, prune irrelevant regions, and iteratively discover relational paths without relying on explicit step-by-step reasoning chains
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Division of Thought (DOT) ... decomposes retrieval into localized search spaces
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[2]
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
URLhttps://arxiv.org/abs/2310.11511. Boyu Chen, Zirui Guo, Zidan Yang, Yuluo Chen, Junze Chen, Zhenghao Liu, Chuan Shi, and Cheng Yang. Pathrag: Pruning graph-based retrieval augmented generation with relational paths. arXiv preprint arXiv:2502.14902,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. From Local to Global: A Graph RAG Approach to Query-Focused Summarization. arXiv e-prints, art. arXiv:2404.16130, April
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
doi: 10.48550/arXiv.2404.16130. Sander Es, Jack James, Luis Espinosa-Anke, and Steven Schockaert. Ragas: Automated evaluation of retrieval augmented generation. arXiv preprint arXiv:2309.15217,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2404.16130
-
[5]
Ragas: Automated Evaluation of Retrieval Augmented Generation
URLhttps://arxiv.org/abs/2309.15217. Zirui Guo, Lianghao Xia, Yanhua Yu, Tu Ao, and Chao Huang. Lightrag: Simple and fast retrieval-augmented generation. CoRR, abs/2410.05779,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
LightRAG: Simple and Fast Retrieval-Augmented Generation
URL https://doi.org/10. 48550/arXiv.2410.05779. Shubham Gupta, Rishabh Ranjan, and S. N. Singh. A comprehensive survey of retrieval- augmented generation (rag): Evolution, current landscape and future directions. arXiv preprint arXiv:2410.12837,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
URLhttps://arxiv.org/abs/2410.12837. Bernal Jim´enez Guti´errez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, and Yu Su. Hipporag: Neurobiologically inspired long-term memory for large language models. arXiv preprint arXiv:2405.14831,
-
[8]
doi: 10.1145/3774904. 3792684. arXiv:2510.07484. Haoyu Huang, Yongfeng Huang, Junjie Yang, Zhenyu Pan, Yongqiang Chen, Kaili Ma, Hongzhi Chen, and James Cheng. Retrieval-augmented generation with hierarchical knowledge. arXiv preprint arXiv:2503.10150,
-
[9]
Dantanarayana, Kriszti´an Flautner, Lingjia Tang, and Jason Mars
Savini Kashmira, Jayanaka L. Dantanarayana, Kriszti´an Flautner, Lingjia Tang, and Jason Mars. Graphrunner: A multi-stage framework for efficient and accurate graph-based retrieval. arXiv preprint arXiv:2507.08945,
-
[10]
Jintao Liang, Sugang, Huifeng Lin, You Wu, Rui Zhao, and Ziyue Li. Reasoning RAG via system 1 or system 2: A survey on reasoning agentic retrieval-augmented gener- ation for industry challenges. In Kentaro Inui, Sakriani Sakti, Haofen Wang, Derek F. Wong, Pushpak Bhattacharyya, Biplab Banerjee, Asif Ekbal, Tanmoy Chakraborty, and Dhirendra Pratap Singh (e...
work page 1954
-
[11]
The Asian Federation of Natural Language Processing and The Association for Computational Linguistics. ISBN 979-8-89176-303-6. URL https://aclanthology.org/ 2025.findings-ijcnlp.122/. Hao Liu, Zhengren Wang, Xi Chen, Zhiyu Li, Feiyu Xiong, Qinhan Yu, and Wentao Zhang. Hoprag: Multi-hop reasoning for logic-aware retrieval-augmented generation. arXiv preprint,
work page 2025
-
[12]
Linhao Luo, Zicheng Zhao, Gholamreza Haffari, Chen Gong, Dinh Phung, and Shirui Pan. Gfm-rag: Graph foundation model for retrieval augmented generation. arXiv preprint arXiv:2502.01113,
-
[13]
Costas Mavromatis and George Karypis. Gnn-rag: Graph neural retrieval for large language model reasoning. arXiv preprint arXiv:2405.20139,
-
[14]
Stepchain graphrag: Reasoning over knowledge graphs for multi-hop question answering
Tengjun Ni, Xin Yuan, Shenghong Li, Kai Wu, Ren Ping Liu, Wei Ni, and Wenjie Zhang. Stepchain graphrag: Reasoning over knowledge graphs for multi-hop question answering. arXiv preprint arXiv:2510.02827,
-
[15]
Graph retrieval-augmented generation: A survey.arXiv preprint arXiv:2408.08921,
Boci Peng, Yun Zhu, Yongchao Liu, Xiaohe Bo, Haizhou Shi, Chuntao Hong, Yan Zhang, and Siliang Tang. Graph retrieval-augmented generation: A survey. arXiv preprint arXiv:2408.08921,
-
[17]
arXiv preprint arXiv:2409.05591 (2024)
URLhttps://arxiv.org/abs/2409.05591. Aditi Singh, Abul Ehtesham, Saket Kumar, and Tala Talaei Khoei. Agentic retrieval- augmented generation: A survey on agentic rag. arXiv preprint arXiv:2501.09136,
-
[18]
Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG
URLhttps://arxiv.org/abs/2501.09136. Zhiwen Tan, Jiaming Huang, Qintong Wu, Hongxuan Zhang, Chenyi Zhuang, and Jinjie Gu. Rag-r1: Incentivizing the search and reasoning capabilities of llms through multi-query parallelism. arXiv preprint arXiv:2507.02962,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
doi: 10.54097/h21fky45. 10 Preprint. Junde Wu, Jiayuan Zhu, Yunli Qi, Jingkun Chen, Min Xu, Filippo Menolascina, and Vicente Grau. Medical graph rag: Towards safe medical large language model via graph retrieval- augmented generation. arXiv preprint arXiv:2408.04187,
-
[20]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
doi: 10.1287/mnsc.17.11.712. Chuanyue Yu, Kuo Zhao, Yuhan Li, Heng Chang, Mingjian Feng, Xiangzhe Jiang, Yufei Sun, Jia Li, Yuzhi Zhang, Jianxin Li, and Ziwei Zhang. Graphrag-r1: Graph retrieval- augmented generation with process-constrained reinforcement learning. In Proceedings of the ACM Web Conference (WWW),
-
[22]
A Appendix In this section, we elaborate on the experimental settings, benchmarks, pre-processing steps, and prompt templates of the DOTRAG framework. Additionally, we describe in greater depth the evaluation criteria used to assess DotRAG’s performance against baseline methods. A.1 Experimental Settings Backbone Models.Following prior work such as (Edge ...
work page 2024
-
[23]
uses 125 questions per dataset across two datasets (250 total). In contrast, our study evaluates a total of 1,100 questions, providing a substantially larger evaluation scale. This is consistent with prior RAG and GraphRAG work, where evaluation sets are typically limited in size due to the cost of LLM-based judgment and pairwise comparison protocols. 12 ...
work page 2020
-
[24]
The model first infers the entity type (e.g.,movie, person, genre) and then produces a concise, self-contained description. This process synthesizes essential informa- tion while remaining strictly grounded in the Stage 1 text, yielding the normalized entity representations expected by GraphRAG indexing systems. Stage 3: Relational Textualization.Finally,...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.