Generic Expert Coverage for Pruning SparseMixture-of-Experts Language Models
Pith reviewed 2026-07-03 14:17 UTC · model grok-4.3
The pith
Profiling expert utility separately on two generic corpora and enforcing cross-corpus coverage yields better MoE pruning than single-score methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
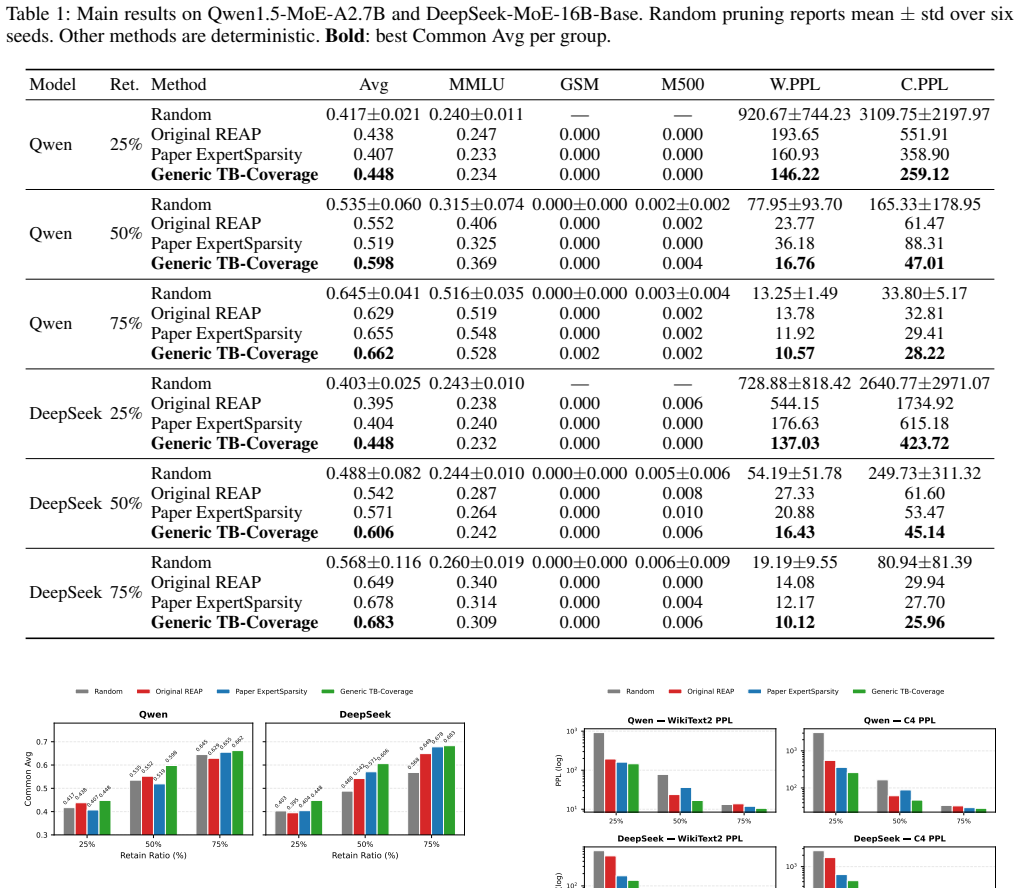
Generic TB-Coverage, which profiles per-expert utility on WikiText2 and C4 separately and then enforces a fixed-budget coverage rule that preserves high-utility experts from each corpus, improves average zero-shot accuracy over random pruning, REAP, and ExpertSparsity on Qwen1.5-MoE-A2.7B and DeepSeek-MoE-16B-Base at 25 %, 50 %, and 75 % retention budgets while also reducing perplexity degradation on the calibration corpora.
What carries the argument
Generic TB-Coverage: a pruning mask constructed by separate per-corpus utility profiles followed by a fixed-budget coverage rule that retains high-utility experts from each corpus.
If this is right
- The retained expert sets outperform random, REAP, and ExpertSparsity on the six zero-shot benchmarks at every tested retention budget.
- Perplexity degradation on WikiText2 and C4 is smaller than under the compared baselines.
- The accuracy advantage is largest at the most aggressive budgets (25 % and 50 % retention).
- The same fixed-budget coverage rule works without any task-specific calibration data.
Where Pith is reading between the lines
- Expert utility appears corpus-dependent rather than universal, so single-corpus scoring can discard experts that would have been useful on other distributions.
- A coverage rule may be a lightweight way to inject diversity into any expert-selection procedure that otherwise optimizes a single aggregate score.
- The approach could be tested on additional generic corpora or on models with different expert counts to check whether the coverage benefit scales.
Load-bearing premise
Utility rankings computed on generic corpora will identify experts that remain useful for downstream zero-shot tasks even though the pruning process never sees any downstream data.
What would settle it
Apply the method to the two models at 25 % retention and measure whether average zero-shot accuracy falls below the best baseline on the same six benchmarks.
Figures
read the original abstract
Sparsely activated Mixture-of-Experts (MoE) language models contain substantial structured redundancy among routed experts, but pruning them without downstream calibration data remains challenging. Existing expert-pruning methods typically rely on a single aggregated importance score, which can bias the retained set toward experts favored by dominant calibration patterns. We propose \textbf{Generic TB-Coverage}, a coverage-aware expert pruning method that uses only generic text corpora (WikiText2 and C4) for calibration. Instead of collapsing expert utility into one score, our method profiles per-expert utility separately on each corpus and enforces a fixed-budget coverage rule that preserves high-utility experts from each corpus before constructing the final pruning mask. Across Qwen1.5-MoE-A2.7B and DeepSeek-MoE-16B-Base at 25\%, 50\%, and 75\% retention budgets, our method improves average accuracy on six common zero-shot benchmarks over random pruning, REAP, and ExpertSparsity, while also reducing perplexity degradation on WikiText2 and C4. The gains are largest under aggressive pruning (25\% and 50\% retain), suggesting that preserving cross-corpus expert coverage is an effective generic-data prior for MoE pruning. Our improvements hold with fixed pruning budgets and no downstream calibration data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Generic TB-Coverage, a pruning method for sparse MoE language models that profiles per-expert utility separately on generic corpora (WikiText2 and C4) and applies a fixed-budget coverage rule to retain high-utility experts from each before forming the mask. It reports that this yields higher average accuracy on six zero-shot benchmarks and lower perplexity degradation on the calibration corpora than random pruning, REAP, and ExpertSparsity, for Qwen1.5-MoE-A2.7B and DeepSeek-MoE-16B-Base at 25%, 50%, and 75% retention budgets, all without access to downstream calibration data.
Significance. If the central claim holds under rigorous controls, the result would be significant for practical MoE deployment: it supplies a generic-data prior that avoids task-specific calibration while still outperforming existing pruning baselines, with the largest reported gains at aggressive sparsity levels. The approach is internally consistent with the stated axioms (no free parameters fitted to benchmarks) and could generalize to other routed architectures.
major comments (3)
- [Abstract] Abstract: the claim of 'consistent gains' and 'improvements hold' is presented without error bars, standard deviations, number of runs, or any statistical test; this directly affects the load-bearing assertion that the coverage rule outperforms the three baselines across retention budgets.
- [Method and Experimental Results] Method and Experimental Results: no analysis is provided showing that the per-expert utility scores computed on WikiText2/C4 correlate with (or even overlap with) the experts activated on the six zero-shot tasks; without such evidence the coverage rule's advantage over single-score methods remains an untested assumption rather than a demonstrated mechanism.
- [Experimental Results] Table reporting zero-shot accuracies (presumably Table 2 or 3): the manuscript states average accuracy improvements but does not report per-task breakdowns or variance across the six benchmarks, making it impossible to determine whether the aggregate gain is driven by a subset of tasks or is uniform.
minor comments (2)
- [Abstract] Notation: the acronym 'TB-Coverage' is introduced without an explicit expansion on first use.
- [Abstract] The abstract states 'six common zero-shot benchmarks' but does not name them; this should be stated explicitly for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas for improving statistical transparency, mechanistic insight, and result detail. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'consistent gains' and 'improvements hold' is presented without error bars, standard deviations, number of runs, or any statistical test; this directly affects the load-bearing assertion that the coverage rule outperforms the three baselines across retention budgets.
Authors: We agree that the abstract would be strengthened by statistical context. In the revision we will specify the number of runs (3 random seeds for both pruning mask generation and evaluation), report standard deviations with all average accuracies, include error bars on figures, and add a brief statement on statistical significance testing (e.g., paired t-tests against baselines) where improvements are claimed. These changes will also appear in the experimental results section and will qualify the abstract language accordingly. revision: yes
-
Referee: [Method and Experimental Results] Method and Experimental Results: no analysis is provided showing that the per-expert utility scores computed on WikiText2/C4 correlate with (or even overlap with) the experts activated on the six zero-shot tasks; without such evidence the coverage rule's advantage over single-score methods remains an untested assumption rather than a demonstrated mechanism.
Authors: The method is deliberately task-agnostic, relying only on generic corpora to produce a prior that empirically outperforms single-score baselines on downstream zero-shot tasks. Nevertheless, the referee's point is valid: an explicit link between generic utility scores and task-specific expert usage would strengthen the mechanistic claim. In the revision we will add a post-hoc analysis that extracts expert activation frequencies on the six zero-shot benchmarks (possible because the models were already evaluated on them) and reports overlap statistics and rank correlations between the generic utility profiles and task-activated experts. Results will be presented transparently, including cases of limited overlap. revision: yes
-
Referee: [Experimental Results] Table reporting zero-shot accuracies (presumably Table 2 or 3): the manuscript states average accuracy improvements but does not report per-task breakdowns or variance across the six benchmarks, making it impossible to determine whether the aggregate gain is driven by a subset of tasks or is uniform.
Authors: We accept that aggregate averages alone are insufficient. The revised manuscript will include an expanded table (or supplementary table) showing per-task accuracies for all six benchmarks under each method and retention budget, together with per-task standard deviations across the three runs. This will make clear whether gains are uniform or concentrated on particular tasks while preserving the average as a summary statistic. revision: yes
Circularity Check
No circularity: utility profiles and coverage rule are independent of reported benchmarks
full rationale
The method computes per-expert utility on WikiText2 and C4 only, applies a fixed-budget coverage rule to build the pruning mask, and then measures downstream accuracy on six zero-shot tasks plus perplexity on the same generic corpora. No equation, parameter, or coverage rule is fitted to the zero-shot benchmarks; the reported gains are therefore an external test rather than a quantity defined by the inputs. No self-citation chain, ansatz smuggling, or renaming of known results is visible in the provided text that would collapse the central claim to its own calibration data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Journal of Machine Learning Research , volume=
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity , author=. Journal of Machine Learning Research , volume=
-
[2]
Mixtral of Experts , author=. arXiv preprint arXiv:2401.04088 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
arXiv preprint arXiv:2401.11340 , year=
Qwen1.5-MoE: Matching 7B Model Performance with 1/3 Activated Parameters , author=. arXiv preprint arXiv:2401.11340 , year=
-
[4]
Dai, Damai and Deng, Chengqi and Zhao, Chenggang and Xu, R. X. and Gao, Huazuo and Chen, Deli and Li, Jie and Zeng, Wangding and Zhang, Xing and Wang, Yu and others , booktitle=. DeepSeek-
-
[5]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , year=
Not All Experts are Equal: Efficient Expert Pruning and Skipping for Mixture of Experts Large Language Models , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , year=
2024
-
[6]
Ashkboos, Saleh and Croci, Max and Nascimento, Marcelo Gennari do and Hensman, James and James, Dan and Hoeche, Stefan , booktitle=. Slice
-
[7]
Men, Xin and He, Mingyu and Xu, Qingyu and Wang, Yujin and Luo, Bingbing and Zhang, Min , booktitle=. Short
-
[8]
Advances in Neural Information Processing Systems , year=
LLM-Pruner: On the Structural Pruning of Large Language Models , author=. Advances in Neural Information Processing Systems , year=
-
[9]
Proceedings of the 5th International Conference on Learning Representations , year=
Pointer Sentinel Mixture Models , author=. Proceedings of the 5th International Conference on Learning Representations , year=
-
[10]
Journal of Machine Learning Research , volume=
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer , author=. Journal of Machine Learning Research , volume=
-
[11]
Think You Have Solved Question Answering? Try
Clark, Peter and Cowhey, Isaac and Etzioni, Oren and Khot, Tushar and Sabharwal, Ashish and Schoenick, Carissa and Tafjord, Oyvind , journal=. Think You Have Solved Question Answering? Try
-
[12]
Zellers, Rowan and Holtzman, Ari and Bisk, Yonatan and Farhadi, Ali and Choi, Yejin , booktitle=
-
[13]
Bisk, Yonatan and Zellers, Rowan and Gao, Jianfeng and Choi, Yejin , booktitle=
-
[14]
Sakaguchi, Keisuke and Le Bras, Ronan and Bhagavatula, Chandra and Choi, Yejin , journal=
-
[15]
Clark, Christopher and Lee, Kenton and Chang, Ming-Wei and Kwiatkowski, Tom and Collins, Michael and Toutanova, Kristina , booktitle=
-
[16]
Proceedings of the International Conference on Learning Representations , year=
Measuring Massive Multitask Language Understanding , author=. Proceedings of the International Conference on Learning Representations , year=
-
[17]
Training Verifiers to Solve Math Word Problems
Training Verifiers to Solve Math Word Problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Let's Verify Step by Step , author=. arXiv preprint arXiv:2305.20050 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Zoph, Barret and Bello, Irwan and Kumar, Sameer and Du, Nan and Huang, Yanping and Dean, Jeffrey and Shazeer, Noam and Fedus, William , journal=
-
[20]
Lepikhin, Dmitry and Lee, HyoukJoong and Xu, Yuanzhong and Chen, Dehao and Firat, Orhan and Huang, Yanping and Krikun, Maxim and Shazeer, Noam and Chen, Zhifeng , booktitle=
-
[21]
Go Beyond the Impossible:
Fu, Zhengxiao and Zhang, Qingqing and Liu, Xiao and Liu, Zhiyuan and others , journal=. Go Beyond the Impossible:
-
[22]
Proceedings of the International Conference on Learning Representations , year=
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer , author=. Proceedings of the International Conference on Learning Representations , year=
-
[23]
arXiv preprint arXiv:2202.09368 , year=
Mixture-of-Experts with Expert Choice Routing , author=. arXiv preprint arXiv:2202.09368 , year=
-
[24]
Frantar, Elias and Alistarh, Dan , booktitle=. Sparse
-
[25]
Proceedings of the International Conference on Learning Representations , year=
A Simple and Effective Pruning Approach for Large Language Models , author=. Proceedings of the International Conference on Learning Representations , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.