Learning Adaptive Dynamical Features via Multi-τ Liquid-Mamba for All-in-one Image Restoration
Pith reviewed 2026-06-26 08:59 UTC · model grok-4.3
The pith
Multi-τ Liquid-Mamba adapts discretization steps across multiple branches to handle varied image degradations in all-in-one restoration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Multi-τ Liquid-Mamba modulates the effective discretization steps of multiple dynamical branches inside selective state space modeling and adaptively fuses their responses according to degradation-aware gating weights. This design captures both fast-varying local details and slowly evolving global structures while preserving the original selective parameterization and hardware-efficient selective scan mechanism, so the module integrates directly into prior Mamba-based restoration models.
What carries the argument
Multi-τ Liquid-Mamba: input-conditioned multi-timescale liquid discretization fused by degradation-aware gating weights inside selective state space modeling.
If this is right
- The model captures both fast local details and slow global structures in one forward pass.
- Linear scaling with sequence length is retained.
- The module can be inserted into existing Mamba restoration networks without redesigning the scan pipeline.
- Consistent state-of-the-art results appear across combined restoration tasks such as denoising, deblurring, and deraining.
Where Pith is reading between the lines
- The same multi-branch timescale modulation could be tested on video or 3D data where temporal or volumetric degradations also vary spatially.
- If the gating mechanism proves robust, it might reduce reliance on separate task-specific heads for different restoration problems.
- An ablation that fixes the τ values instead of making them input-conditioned would isolate how much of the reported gain comes from adaptivity versus the mere presence of multiple branches.
Load-bearing premise
That changing discretization steps across multiple input-dependent branches and fusing them with gating weights improves restoration quality without breaking the selective parameterization or hardware-efficient scan of the base Mamba model.
What would settle it
A controlled replacement test on standard all-in-one benchmarks in which a single-τ version of the same backbone produces equal or better PSNR/SSIM scores than the multi-τ version at identical or lower compute cost.
Figures
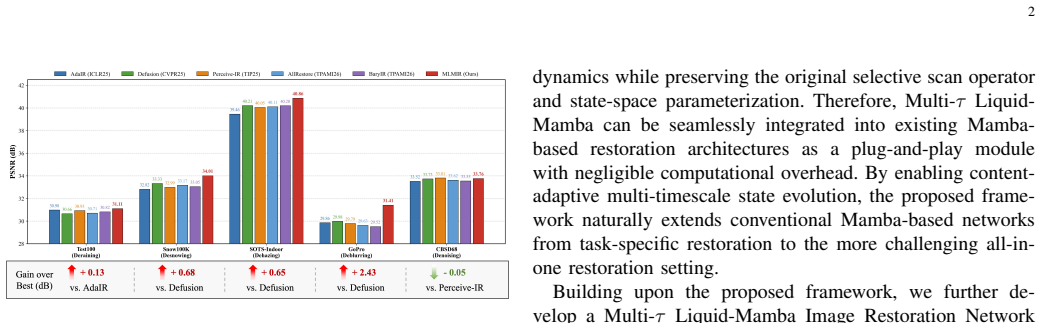





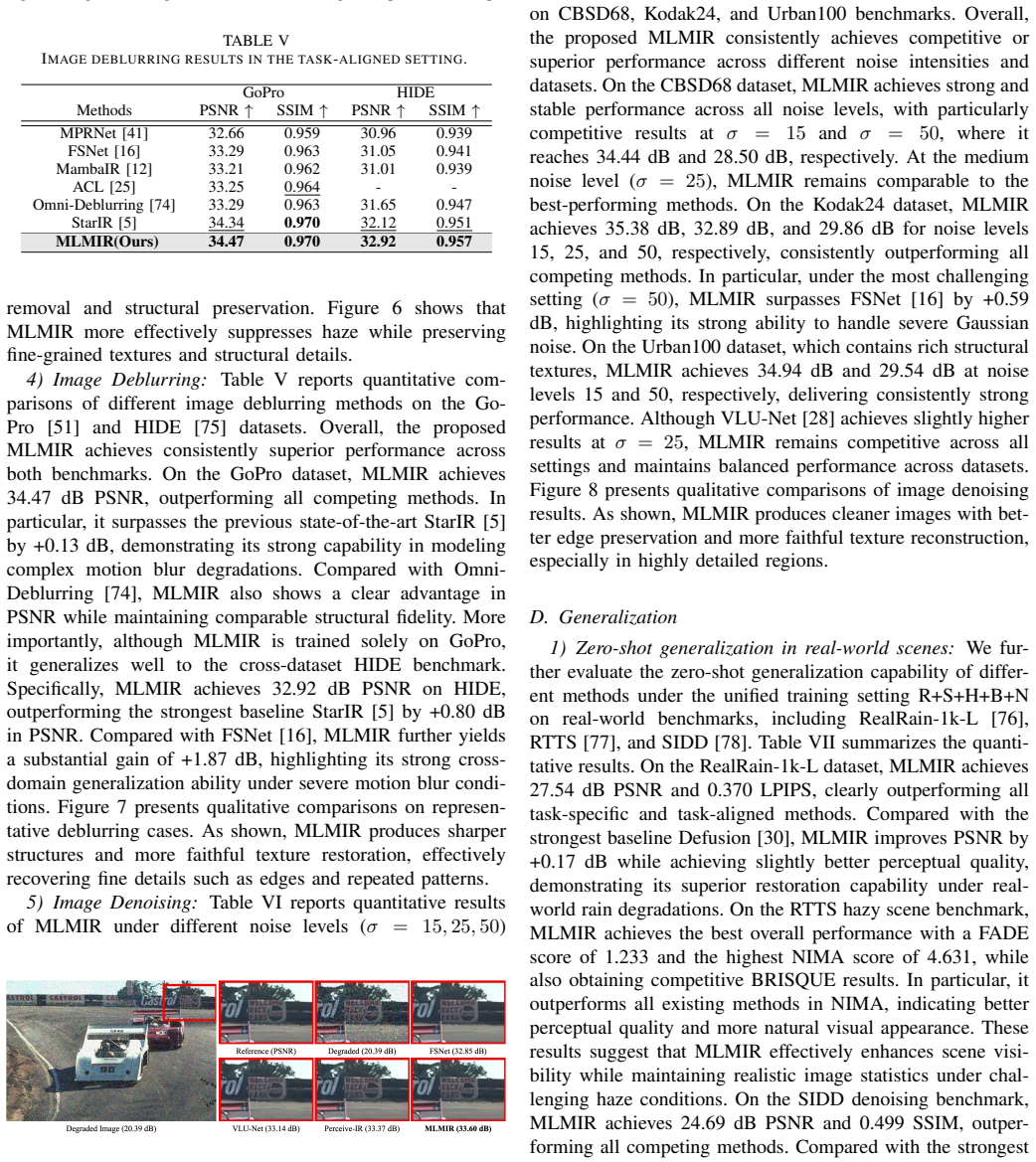
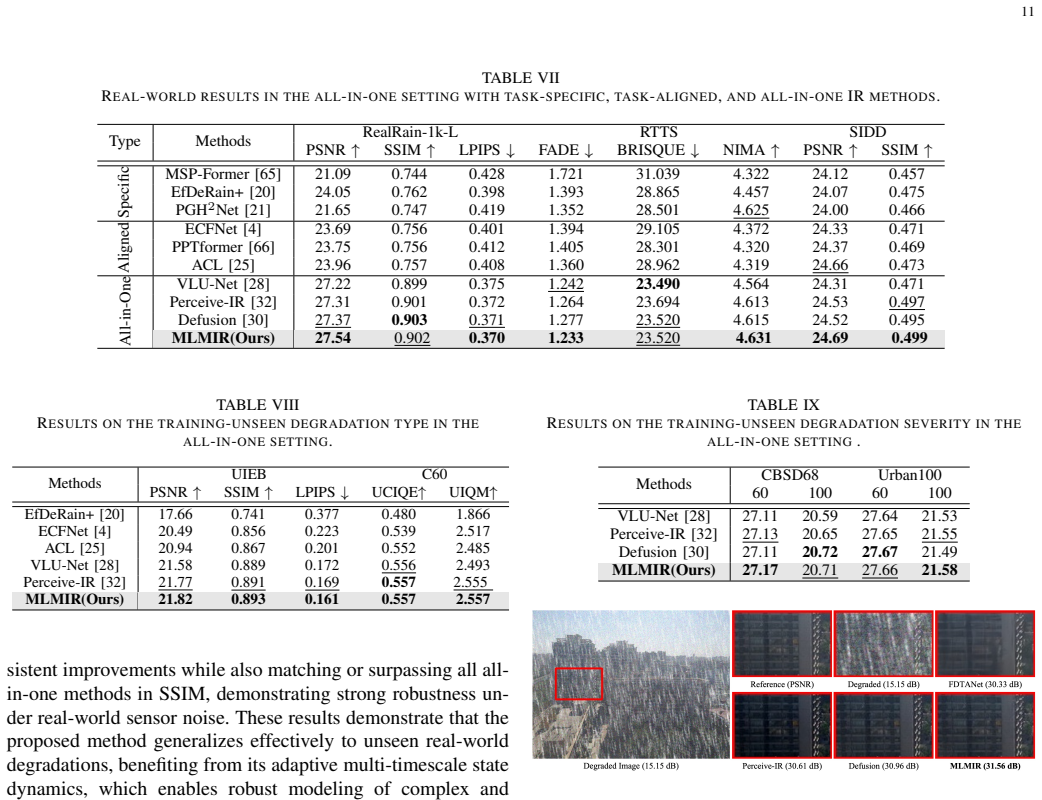
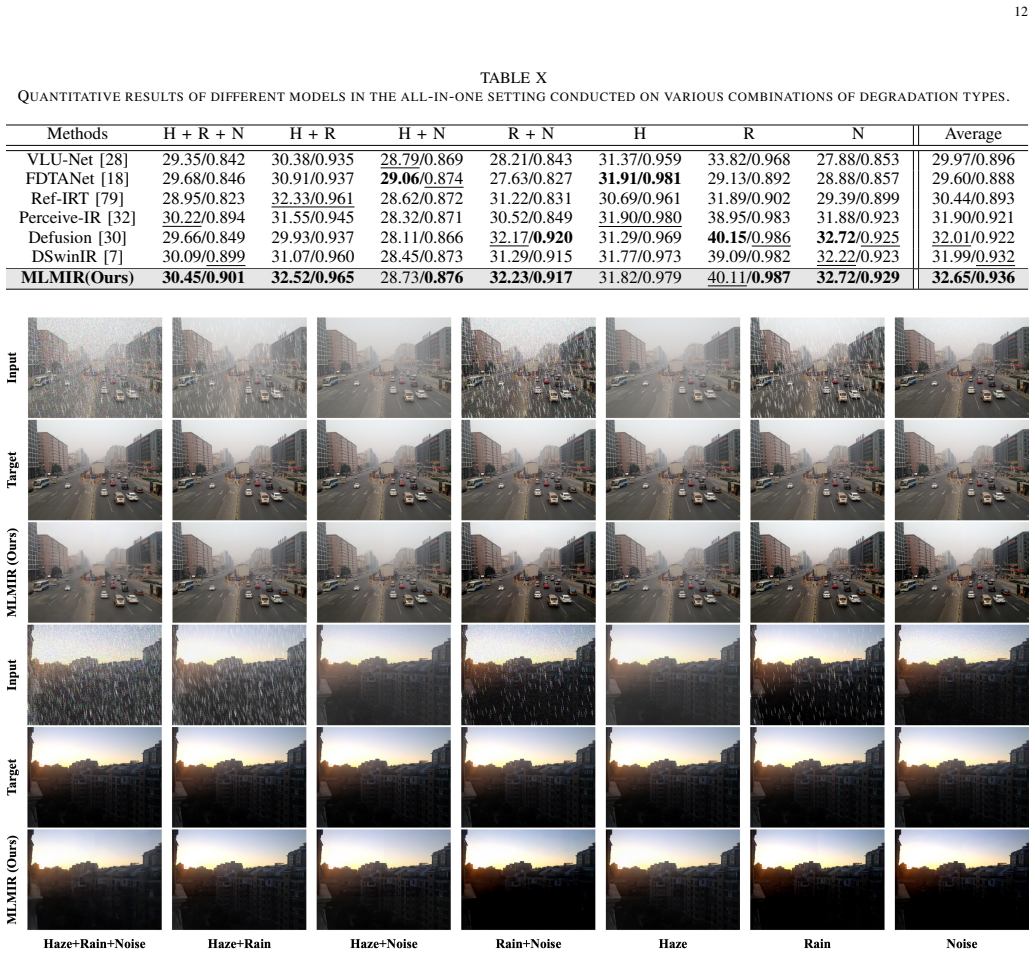
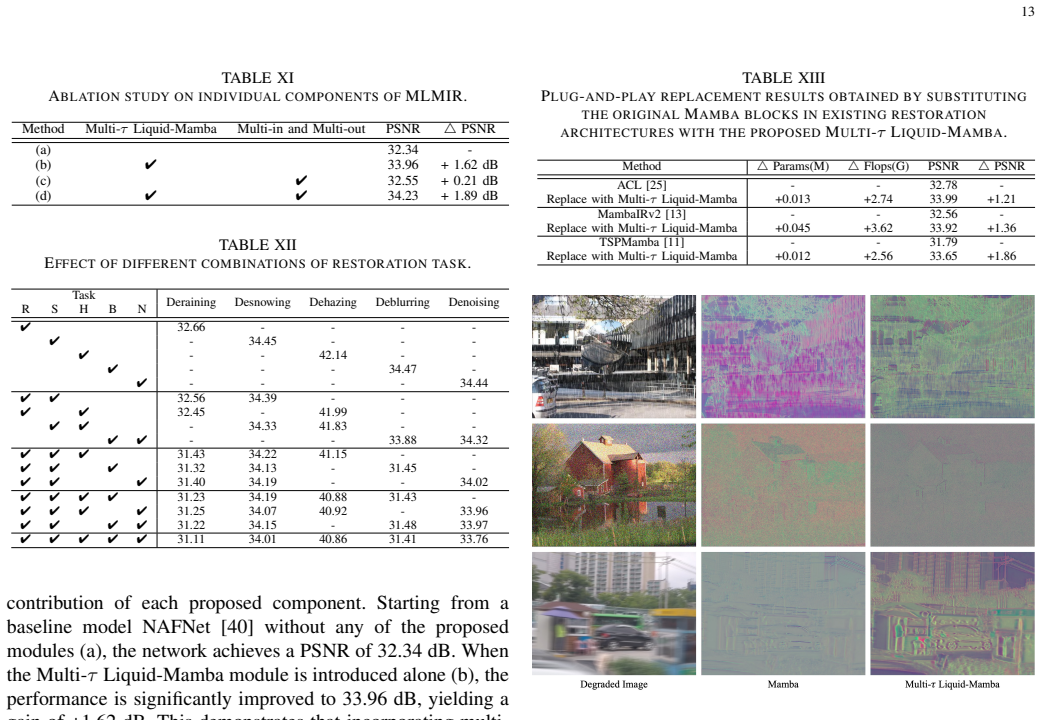
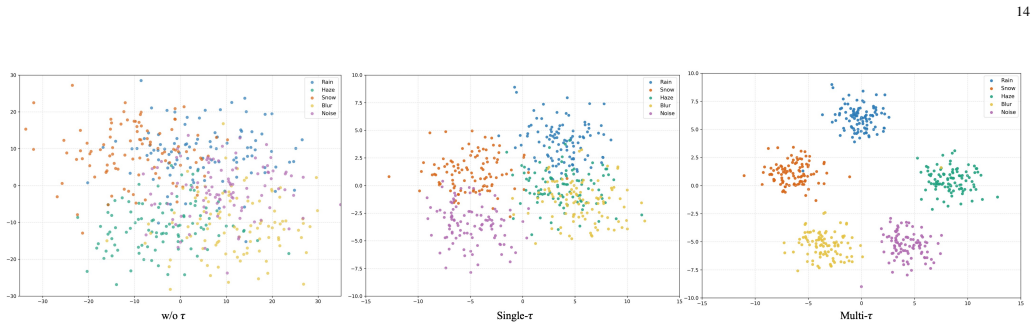
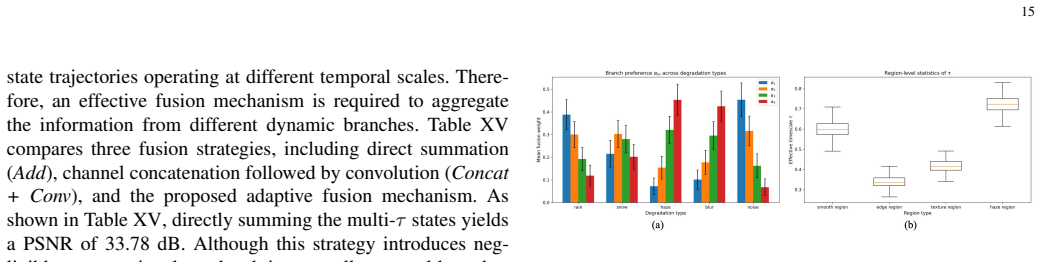
read the original abstract
Image restoration aims to recover high-quality images from degraded observations. Recent Mamba-based image restoration models have demonstrated strong potential in modeling long-range dependencies with linear complexity. However, most existing designs still rely on a single state-evolution timescale, which limits their adaptability to spatially heterogeneous and task-dependent degradation patterns in all-in-one image restoration. In this paper, we propose Multi-$\tau$ Liquid-Mamba, an adaptive state space module that introduces input-conditioned multi-timescale liquid discretization into selective state space modeling. Instead of changing the overall selective scan pipeline, the proposed module modulates the effective discretization steps of multiple dynamical branches and adaptively fuses their responses according to degradation-aware gating weights. This design allows the model to capture both fast-varying local details and slowly evolving global structures while preserving the linear scaling property of Mamba with respect to sequence length. Importantly, Multi-$\tau$ Liquid-Mamba modulates the effective transition dynamics while preserving the original selective parameterization and hardware-efficient selective scan mechanism, making it a plug-and-play module that can be seamlessly integrated into existing Mamba-based architectures. Built upon this framework, we develop a Multi-$\tau$ Liquid-Mamba Image Restoration Network (MLMIR) for all-in-one image restoration. Extensive experiments on a wide range of restoration benchmarks demonstrate that MLMIR consistently achieves state-of-the-art performance in all-in-one image restoration while remaining highly competitive in task-aligned restoration settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce Multi-τ Liquid-Mamba, an adaptive state space module that incorporates input-conditioned multi-timescale liquid discretization into selective state space modeling for all-in-one image restoration. By modulating the effective discretization steps of multiple dynamical branches and fusing their responses with degradation-aware gating weights, the module captures both fast-varying local details and slowly evolving global structures. The design is presented as preserving the linear scaling and the hardware-efficient selective scan of the base Mamba model, allowing it to be a plug-and-play addition to existing architectures. The resulting MLMIR network is reported to achieve state-of-the-art performance on a range of image restoration benchmarks.
Significance. Should the central technical claims regarding the preservation of linear complexity and the selective scan mechanism be verified through detailed equations and ablations, this work could provide a valuable extension to Mamba-based models in computer vision, particularly for tasks requiring adaptation to varying degradation patterns. The plug-and-play aspect and focus on all-in-one restoration are notable if the efficiency claims hold.
major comments (1)
- [Abstract (module design paragraph)] Abstract (module design paragraph): The assertion that Multi-τ Liquid-Mamba 'modulates the effective transition dynamics while preserving the original selective parameterization and hardware-efficient selective scan mechanism' is load-bearing for the linear-complexity claim. No explicit integration equation, pseudocode, or diagram is visible showing how input-conditioned multi-τ branches are folded into a single selective scan (e.g., via effective τ modulation of shared A/B/C parameters rather than separate state transitions). This leaves open the possibility that multiple scans are required, directly contradicting the 'instead of changing the overall selective scan pipeline' statement.
minor comments (1)
- The abstract would benefit from a brief quantitative statement on the number of τ branches, the form of the gating weights, or the specific restoration benchmarks used, to allow readers to assess the scope of the claimed gains.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the single major comment below and agree that additional clarification on the integration mechanism will strengthen the manuscript.
read point-by-point responses
-
Referee: The assertion that Multi-τ Liquid-Mamba 'modulates the effective transition dynamics while preserving the original selective parameterization and hardware-efficient selective scan mechanism' is load-bearing for the linear-complexity claim. No explicit integration equation, pseudocode, or diagram is visible showing how input-conditioned multi-τ branches are folded into a single selective scan (e.g., via effective τ modulation of shared A/B/C parameters rather than separate state transitions). This leaves open the possibility that multiple scans are required, directly contradicting the 'instead of changing the overall selective scan pipeline' statement.
Authors: We thank the referee for identifying this point of potential ambiguity. The abstract provides a concise summary; the full mathematical details appear in Section 3, where the input-conditioned multi-τ discretization is realized by modulating the effective Δ (discretization step) parameter inside the standard selective SSM recurrence while reusing the same selective A/B/C matrices. This permits all branches to be processed inside one selective scan, after which a degradation-aware gating fusion combines the outputs. No separate scans are introduced. We will add an explicit integration diagram and pseudocode to the revised manuscript (and, space permitting, a brief clarifying sentence in the abstract) to make the single-scan property unambiguous. revision: yes
Circularity Check
No circularity: architectural proposal with no self-referential derivations or fitted predictions
full rationale
The paper presents Multi-τ Liquid-Mamba as a plug-and-play architectural module that modulates discretization steps across branches and fuses via gating weights while preserving the base Mamba selective scan. No equations, parameter-fitting procedures, or derivation chains appear in the provided text. Claims rest on design description and external benchmark results rather than any quantity shown to equal its own inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems, and no renaming of known results or ansatz smuggling is evident. The central claim is therefore self-contained as an engineering addition whose validity is testable independently.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Single image haze removal using dark channel prior
K. He, J. Sun, and X. Tang, “Single image haze removal using dark channel prior.”TPAMI, 2011
2011
-
[2]
Imu-assisted accurate blur kernel re- estimation in non-uniform camera shake deblurring,
J. Rong, H. Huang, and J. Li, “Imu-assisted accurate blur kernel re- estimation in non-uniform camera shake deblurring,”IEEE Transactions on Image Processing, vol. 33, pp. 3823–3838, 2024
2024
-
[3]
Learning physics-informed noise models from dark frames for low-light raw image denoising,
H. Feng, L. Wang, Y . Huang, Y . Wang, L. Zhu, and H. Huang, “Learning physics-informed noise models from dark frames for low-light raw image denoising,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 48, no. 4, pp. 3952–3969, 2026
2026
-
[4]
Emphasizing crucial features for efficient image restoration,
H. Gao, B. Ma, Y . Zhang, J. Yang, J. Yang, X. Wang, and D. Dang, “Emphasizing crucial features for efficient image restoration,”Pattern Recognition, p. 113575, 2026
2026
-
[5]
Starir: Convolutional image restoration with spatial-frequency fusion,
Y . Cui, S. W. Zamir, M.-H. Yang, A. Knoll, F. S. Khan, and S. Khan, “Starir: Convolutional image restoration with spatial-frequency fusion,” IEEE Transactions on Pattern Analysis and Machine Intelligence, pp. 1–18, 2026
2026
-
[6]
Mixed hierarchy network for image restoration,
H. Gao, Y . Zhang, J. Yang, and D. Dang, “Mixed hierarchy network for image restoration,”Pattern Recognition, vol. 161, p. 111313, 2025
2025
-
[7]
Dswinir: Rethinking window-based attention for image restoration,
G. Wu, J. Jiang, K. Jiang, X. Liu, and L. Nie, “Dswinir: Rethinking window-based attention for image restoration,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 48, no. 4, pp. 4350– 4366, 2026
2026
-
[8]
Learning continuous wasser- stein barycenter space for generalized all-in-one image restoration,
X. Tang, X. He, J. Xu, X. Gu, and J. Sun, “Learning continuous wasser- stein barycenter space for generalized all-in-one image restoration,” IEEE Transactions on Pattern Analysis and Machine Intelligence, pp. 1–16, 2026
2026
-
[9]
All-in-one transformer for image restoration under adverse weather degradations,
J. Mao, Y . Yang, X. Yin, L. Shao, and H. Tang, “All-in-one transformer for image restoration under adverse weather degradations,”IEEE Trans- actions on Pattern Analysis and Machine Intelligence, vol. 48, no. 6, pp. 6628–6641, 2026
2026
-
[10]
Learning enriched features via selective state spaces model for efficient image deblurring,
H. Gao, B. Ma, Y . Zhang, J. Yang, J. Yang, and D. Dang, “Learning enriched features via selective state spaces model for efficient image deblurring,” inProceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 710–718
2024
-
[11]
Tsp-mamba: The travelling salesman problem meets mamba for image super-resolution and beyond,
K. Zhou, X. Lin, and J. Lu, “Tsp-mamba: The travelling salesman problem meets mamba for image super-resolution and beyond,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2025, pp. 28 134–28 143. 17
2025
-
[12]
Mambair: A simple baseline for image restoration with state-space model,
H. Guo, J. Li, T. Dai, Z. Ouyang, X. Ren, and S.-T. Xia, “Mambair: A simple baseline for image restoration with state-space model,” in European Conference on Computer Vision, 2024, pp. 222–241
2024
-
[13]
Mambairv2: Attentive state space restoration,
H. Guo, Y . Guo, Y . Zha, Y . Zhang, W. Li, T. Dai, S.-T. Xia, and Y . Li, “Mambairv2: Attentive state space restoration,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 28 124– 28 133
2025
-
[14]
Mbmamba: When memory buffer meets mamba for structure-aware image deblurring,
H. Gao, X. Lei, X. Xu, D. Dang, and L. Ma, “Mbmamba: When memory buffer meets mamba for structure-aware image deblurring,” arXiv preprint arXiv:2508.12346, 2025
arXiv 2025
-
[15]
Learn- ing optimal combination patterns for lightweight stereo image super- resolution,
H. Gao, J. Yang, Y . Zhang, J. Yang, B. Ma, and D. Dang, “Learn- ing optimal combination patterns for lightweight stereo image super- resolution,” inProceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 5566–5574
2024
-
[16]
Image restoration via frequency selection,
Y . Cui, W. Ren, X. Cao, and A. Knoll, “Image restoration via frequency selection,”TPAMI, pp. 1–16, 2023
2023
-
[17]
Prompt- based ingredient-oriented all-in-one image restoration,
H. Gao, J. Yang, Y . Zhang, N. Wang, J. Yang, and D. Dang, “Prompt- based ingredient-oriented all-in-one image restoration,”IEEE Transac- tions on Circuits and Systems for Video Technology, vol. 34, no. 10, pp. 9458–9471, 2024
2024
-
[18]
Frequency domain task-adaptive network for restoring images with combined degradations,
H. Gao, B. Ma, Y . Zhang, J. Yang, J. Yang, and D. Dang, “Frequency domain task-adaptive network for restoring images with combined degradations,”Pattern Recognition, vol. 158, p. 111057, 2025
2025
-
[19]
Xyscannet: An interpretable state space model for perceptual image deblurring,
H. Liu, C. Liu, J. Xu, P. Jiang, and M. Lu, “Xyscannet: An interpretable state space model for perceptual image deblurring,” inProceedings of the Computer Vision and Pattern Recognition Conference (CVPR), 2025, pp. 779–789
2025
-
[20]
Efficientderain+: Learning uncertainty-aware filtering via rainmix augmentation for high-efficiency deraining,
Q. Guo, H. Qi, J. Sun, F. Juefei-Xu, L. Ma, D. Lin, W. Feng, and S. Wang, “Efficientderain+: Learning uncertainty-aware filtering via rainmix augmentation for high-efficiency deraining,”International Journal of Computer Vision, vol. 133, no. 4, pp. 2111–2135, 2025
2025
-
[21]
Prior-guided hierarchical harmonization net- work for efficient image dehazing,
X. Su, S. Li, Y . Cui, M. Cao, Y . Zhang, Z. Chen, Z. Wu, Z. Wang, Y . Zhang, and X. Yuan, “Prior-guided hierarchical harmonization net- work for efficient image dehazing,” inProceedings of the AAAI Confer- ence on Artificial Intelligence, vol. 39, no. 7, 2025, pp. 7042–7050
2025
-
[22]
Unpaired photo-realistic image deraining with energy-informed diffusion model,
Y . Wen, T. Gao, and T. Chen, “Unpaired photo-realistic image deraining with energy-informed diffusion model,” inProceedings of the 32nd ACM International Conference on Multimedia, 2024, p. 360–369
2024
-
[23]
Unmix- ing diffusion for self-supervised hyperspectral image denoising,
H. Zeng, J. Cao, K. Zhang, Y . Chen, H. Luong, and W. Philips, “Unmix- ing diffusion for self-supervised hyperspectral image denoising,” in2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 27 820–27 830
2024
-
[24]
Selective frequency network for image restoration,
Y . Cui, Y . Tao, Z. Bing, W. Ren, X. Gao, X. Cao, K. Huang, and A. Knoll, “Selective frequency network for image restoration,” inICLR, 2023
2023
-
[25]
Acl: Activating capability of linear attention for image restoration,
Y . Gu, Y . Meng, J. Ji, and X. Sun, “Acl: Activating capability of linear attention for image restoration,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 17 913–17 923
2025
-
[26]
Promptir: Prompting for all-in-one blind image restoration,
V . Potlapalli, S. W. Zamir, S. Khan, and F. S. Khan, “Promptir: Prompting for all-in-one blind image restoration,”Advances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[27]
Neural degradation representation learning for all-in-one image restoration,
M. Yao, R. Xu, Y . Guan, J. Huang, and Z. Xiong, “Neural degradation representation learning for all-in-one image restoration,”IEEE Transac- tions on Image Processing, vol. 33, pp. 5408–5423, 2024
2024
-
[28]
Vision-language gradient descent-driven all-in-one deep unfolding networks,
H. Zeng, X. Wang, Y . Chen, J. Su, and J. Liu, “Vision-language gradient descent-driven all-in-one deep unfolding networks,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2025, pp. 7524–7533
2025
-
[29]
Autodir: Automatic all-in-one image restoration with latent diffusion,
Y . Jiang, Z. Zhang, T. Xue, and J. Gu, “Autodir: Automatic all-in-one image restoration with latent diffusion,” inComputer Vision – ECCV 2024: 18th European Conference, Milan, Italy, September 29–October 4, 2024, Proceedings, Part XL, 2024, p. 340–359
2024
-
[30]
Visual-instructed degradation diffusion for all-in-one image restoration,
W. Luo, H. Qin, Z. Chen, L. Wang, D. Zheng, Y . Li, Y . Liu, B. Li, and W. Hu, “Visual-instructed degradation diffusion for all-in-one image restoration,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2025, pp. 12 764–12 777
2025
-
[31]
AdaIR: Adaptive all-in-one image restoration via frequency mining and modulation,
Y . Cui, S. W. Zamir, S. Khan, A. Knoll, M. Shah, and F. S. Khan, “AdaIR: Adaptive all-in-one image restoration via frequency mining and modulation,” inThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[32]
Perceive-ir: Learning to perceive degradation better for all-in-one image restoration,
X. Zhang, J. Ma, G. Wang, Q. Zhang, H. Zhang, and L. Zhang, “Perceive-ir: Learning to perceive degradation better for all-in-one image restoration,”IEEE Transactions on Image Processing, pp. 1–1, 2025
2025
-
[33]
Combining recurrent, convolutional, and continuous-time models with linear state space layers,
A. Gu, I. Johnson, K. Goel, K. Saab, T. Dao, A. Rudra, and C. R ´e, “Combining recurrent, convolutional, and continuous-time models with linear state space layers,”Advances in neural information processing systems, vol. 34, pp. 572–585, 2021
2021
-
[34]
Simplified state space layers for sequence modeling,
J. T. Smith, A. Warrington, and S. W. Linderman, “Simplified state space layers for sequence modeling,”ICLR, 2023
2023
-
[35]
Transformers are SSMs: Generalized models and efficient algorithms through structured state space duality,
T. Dao and A. Gu, “Transformers are SSMs: Generalized models and efficient algorithms through structured state space duality,” inInterna- tional Conference on Machine Learning (ICML), 2024
2024
-
[36]
M2restore: Mixture-of-experts-based mamba-cnn fusion framework for all-in-one image restoration,
Y . Wang, Y . Li, Z. Zheng, X.-P. Zhang, and M. Wei, “M2restore: Mixture-of-experts-based mamba-cnn fusion framework for all-in-one image restoration,”IEEE Transactions on Image Processing, vol. 34, pp. 8086–8100, 2025
2025
-
[37]
Aim- vr: All-in-one video restoration via dual-path mamba with frequency adaptive fusion,
Z. Lu, T. Liu, Z. Chen, J. Huang, X. Li, B. Xiao, and W. Zhao, “Aim- vr: All-in-one video restoration via dual-path mamba with frequency adaptive fusion,” in2025 IEEE International Conference on Multimedia and Expo (ICME), 2025, pp. 1–6
2025
-
[38]
Liquid time- constant networks,
R. Hasani, M. Lechner, A. Amini, D. Rus, and R. Grosu, “Liquid time- constant networks,” inProceedings of the AAAI conference on artificial intelligence, vol. 35, no. 9, 2021, pp. 7657–7666
2021
-
[39]
Liquid structural state-space models,
R. Hasani, M. Lechner, T.-H. Wang, M. Chahine, A. Amini, and D. Rus, “Liquid structural state-space models,” inThe Eleventh International Conference on Learning Representations, 2023
2023
-
[40]
Simple baselines for image restoration,
L. Chen, X. Chu, X. Zhang, and J. Sun, “Simple baselines for image restoration,”ECCV, 2022
2022
-
[41]
Multi-stage progressive image restoration,
S. W. Zamir, A. Arora, S. Khan, M. Hayat, F. S. Khan, M.-H. Yang, and L. Shao, “Multi-stage progressive image restoration,” inCVPR, 2021
2021
-
[42]
Deep joint rain detection and removal from a single image,
W. Yang, R. T. Tan, J. Feng, J. Liu, Z. Guo, and S. Yan, “Deep joint rain detection and removal from a single image,”CVPR, pp. 1685–1694, 2016
2016
-
[43]
Image de-raining using a conditional generative adversarial network,
H. Zhang, V . A. Sindagi, and V . M. Patel, “Image de-raining using a conditional generative adversarial network,”TCSVT, vol. 30, pp. 3943– 3956, 2017
2017
-
[44]
Removing rain from single images via a deep detail network,
X. Fu, J. Huang, D. Zeng, Y . Huang, X. Ding, and J. Paisley, “Removing rain from single images via a deep detail network,” in2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 1715–1723
2017
-
[45]
Rain streak removal using layer priors,
Y . Li, R. T. Tan, X. Guo, J. Lu, and M. S. Brown, “Rain streak removal using layer priors,” in2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 2736–2744
2016
-
[46]
Density-aware single image de-raining using a multi-stream dense network,
H. Zhang and V . M. Patel, “Density-aware single image de-raining using a multi-stream dense network,”CVPR, pp. 695–704, 2018
2018
-
[47]
Desnownet: Context-aware deep network for snow removal,
Y .-F. Liu, D.-W. Jaw, S.-C. Huang, and J.-N. Hwang, “Desnownet: Context-aware deep network for snow removal,”IEEE Transactions on Image Processing, vol. 27, no. 6, pp. 3064–3073, 2018
2018
-
[48]
Jstasr: Joint size and transparency-aware snow removal algorithm based on modified partial convolution and veiling effect removal,
W.-T. Chen, H.-Y . Fang, J.-J. Ding, C.-C. Tsai, and S.-Y . Kuo, “Jstasr: Joint size and transparency-aware snow removal algorithm based on modified partial convolution and veiling effect removal,” inComputer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXI 16. Springer, 2020, pp. 754–770
2020
-
[49]
All snow removed: Single image desnowing algo- rithm using hierarchical dual-tree complex wavelet representation and contradict channel loss,
W.-T. Chen, H.-Y . Fang, C.-L. Hsieh, C.-C. Tsai, I. Chen, J.-J. Ding, S.-Y . Kuoet al., “All snow removed: Single image desnowing algo- rithm using hierarchical dual-tree complex wavelet representation and contradict channel loss,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 4196–4205
2021
-
[50]
Benchmarking single-image dehazing and beyond,
B. Li, W. Ren, D. Fu, D. Tao, D. Feng, W. Zeng, and Z. Wang, “Benchmarking single-image dehazing and beyond,”TIP, vol. 28, no. 1, pp. 492–505, 2018
2018
-
[51]
Deep multi-scale convolutional neural network for dynamic scene deblurring,
S. Nah, T. H. Kim, and K. M. Lee, “Deep multi-scale convolutional neural network for dynamic scene deblurring,”CVPR, pp. 257–265, 2016
2016
-
[52]
Ntire 2017 challenge on single image super-resolution: Dataset and study,
E. Agustsson and R. Timofte, “Ntire 2017 challenge on single image super-resolution: Dataset and study,” in2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2017, pp. 1122–1131
2017
-
[53]
Enhanced deep residual networks for single image super-resolution,
B. Lim, S. Son, H. Kim, S. Nah, and K. Mu Lee, “Enhanced deep residual networks for single image super-resolution,” inProceedings of the IEEE conference on computer vision and pattern recognition workshops, 2017, pp. 136–144
2017
-
[54]
Contour detection and hierarchical image segmentation,
P. Arbel ´aez, M. Maire, C. Fowlkes, and J. Malik, “Contour detection and hierarchical image segmentation,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 33, no. 5, pp. 898–916, 2011
2011
-
[55]
Waterloo exploration database: New challenges for image quality assessment models,
K. Ma, Z. Duanmu, Q. Wu, Z. Wang, H. Yong, H. Li, and L. Zhang, “Waterloo exploration database: New challenges for image quality assessment models,”IEEE Transactions on Image Processing, vol. 26, no. 2, pp. 1004–1016, 2016
2016
-
[56]
A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics,
D. Martin, C. Fowlkes, D. Tal, and J. Malik, “A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics,” inProceedings Eighth IEEE International Conference on Computer Vision. ICCV 2001, vol. 2, 2001, pp. 416–423 vol.2. 18
2001
-
[57]
Single image super-resolution from transformed self-exemplars,
J.-B. Huang, A. Singh, and N. Ahuja, “Single image super-resolution from transformed self-exemplars,” in2015 IEEE Conference on Com- puter Vision and Pattern Recognition (CVPR), 2015, pp. 5197–5206
2015
-
[58]
Kodak lossless true color image suite,
R. Franzen, “Kodak lossless true color image suite,”source: http://r0k. us/graphics/kodak, vol. 4, no. 2, p. 9, 1999
1999
-
[59]
The unreasonable effectiveness of deep features as a perceptual metric,
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a perceptual metric,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 586–595
2018
-
[60]
An underwater color image quality evaluation metric,
M. Yang and A. Sowmya, “An underwater color image quality evaluation metric,”IEEE transactions on image processing, vol. 24, no. 12, pp. 6062–6071, 2015
2015
-
[61]
Human-visual-system-inspired un- derwater image quality measures,
K. Panetta, C. Gao, and S. Agaian, “Human-visual-system-inspired un- derwater image quality measures,”IEEE journal of oceanic engineering, vol. 41, no. 3, pp. 541–551, 2015
2015
-
[62]
Referenceless prediction of per- ceptual fog density and perceptual image defogging,
L. K. Choi, J. You, and A. C. Bovik, “Referenceless prediction of per- ceptual fog density and perceptual image defogging,”IEEE Transactions on Image Processing, vol. 24, no. 11, pp. 3888–3901, 2015
2015
-
[63]
Blind/referenceless image spatial quality evaluator,
A. Mittal, A. K. Moorthy, and A. C. Bovik, “Blind/referenceless image spatial quality evaluator,” in2011 conference record of the forty fifth asilomar conference on signals, systems and computers (ASILOMAR). IEEE, 2011, pp. 723–727
2011
-
[64]
Nima: Neural image assessment,
H. Talebi and P. Milanfar, “Nima: Neural image assessment,”IEEE transactions on image processing, vol. 27, no. 8, pp. 3998–4011, 2018
2018
-
[65]
Msp- former: Multi-scale projection transformer for single image desnowing,
S. Chen, T. Ye, Y . Liu, T. Liao, J. Jiang, E. Chen, and P. Chen, “Msp- former: Multi-scale projection transformer for single image desnowing,” inICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023, pp. 1–5
2023
-
[66]
Intra and inter parser- prompted transformers for effective image restoration,
C. Wang, J. Pan, L. Wang, and W. Wang, “Intra and inter parser- prompted transformers for effective image restoration,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 7, 2025, pp. 7609–7618
2025
-
[67]
Adam: A method for stochastic optimization,
D. Kingma and J. Ba, “Adam: A method for stochastic optimization,” Computer Science, 2014
2014
-
[68]
Sgdr: Stochastic gradient descent with warm restarts,
I. Loshchilov and F. Hutter, “Sgdr: Stochastic gradient descent with warm restarts,” 2016
2016
-
[69]
Focal network for image restoration,
Y . Cui, W. Ren, X. Cao, and A. Knoll, “Focal network for image restoration,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 13 001–13 011
2023
-
[70]
Irnext: Rethinking convolutional network design for image restoration,
Y . Cui, W. Ren, S. Yang, X. Cao, and A. Knoll, “Irnext: Rethinking convolutional network design for image restoration,” inProceedings of the 40th International Conference on Machine Learning, 2023
2023
-
[71]
Deep unfolding network for image desnowing with snow shape prior,
X. Guo, X. Wang, X. Fu, and Z.-J. Zha, “Deep unfolding network for image desnowing with snow shape prior,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 35, no. 5, pp. 4740–4752, 2025
2025
-
[72]
Global modeling matters: A fast, lightweight, and effective baseline for efficient image restoration,
X. Jiang, N. Gao, H. Dou, X. Zhang, X. Zhong, Y . Deng, and H. Li, “Global modeling matters: A fast, lightweight, and effective baseline for efficient image restoration,”IEEE Transactions on Image Processing, vol. 35, pp. 2740–2754, 2026
2026
-
[73]
Dea-net: Single image dehazing based on detail-enhanced convolution and content-guided attention,
Z. Chen, Z. He, and Z.-M. Lu, “Dea-net: Single image dehazing based on detail-enhanced convolution and content-guided attention,”IEEE Transactions on Image Processing, 2024
2024
-
[74]
Omni-deblurring: Capturing omni-range context for image deblurring,
Y . Li, H. An, T. Zhang, X. Chen, B. Jiang, and J. Pan, “Omni-deblurring: Capturing omni-range context for image deblurring,”IEEE Transactions on Circuits and Systems for Video Technology, pp. 1–1, 2025
2025
-
[75]
Human- aware motion deblurring,
Z. Shen, W. Wang, X. Lu, J. Shen, H. Ling, T. Xu, and L. Shao, “Human- aware motion deblurring,”2019 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 5571–5580, 2019
2019
-
[76]
Toward real-world single image deraining: A new benchmark and beyond,
W. Li, Q. Zhang, J. Zhang, Z. Huang, X. Tian, and D. Tao, “Toward real-world single image deraining: A new benchmark and beyond,”arXiv preprint arXiv:2206.05514, 2022
arXiv 2022
-
[77]
Benchmarking single-image dehazing and beyond,
B. Li, W. Ren, D. Fu, D. Tao, D. Feng, W. Zeng, and Z. Wang, “Benchmarking single-image dehazing and beyond,”IEEE transactions on image processing, vol. 28, no. 1, pp. 492–505, 2018
2018
-
[78]
A high-quality denoising dataset for smartphone cameras,
A. Abdelhamed, S. Lin, and M. S. Brown, “A high-quality denoising dataset for smartphone cameras,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 1692–1700
2018
-
[79]
Reference-based multi-stage progressive restoration for multi-degraded images,
Y . Zhang, Q. Yang, D. M. Chandler, and X. Mou, “Reference-based multi-stage progressive restoration for multi-degraded images,”IEEE Transactions on Image Processing, vol. 33, pp. 4982–4997, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.