Matching Markets meet Cumulative Prospect Theory: Towards Optimal and Adversarially Robust Learning
Pith reviewed 2026-06-26 18:35 UTC · model grok-4.3
The pith
In matching markets under cumulative prospect theory, selecting a judicious active set of arms during exploration removes the linear dependence on the number of arms K from the leading regret term when K greatly exceeds the number of player
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that, for CPT-weighted preferences in competitive matching markets, an active-set exploration procedure produces an optimal player regret of order log T times (1/Δ) to the power 2/α without a multiplicative K when K ≫ N, and that logarithmic player-optimal regret continues to hold in both known-budget and unknown-budget adversarial corruption models.
What carries the argument
The active-set selection mechanism that restricts exploration to arms that remain plausible stable matches under the CPT weight function, thereby pruning the dependence on total arm count K.
If this is right
- The leading regret term changes from O(K log T (1/Δ)^{2/α}) to O(log T (1/Δ)^{2/α}) precisely when the active set is used and K ≫ N.
- Logarithmic player-optimal regret holds for both known and unknown total corruption budgets in the adversarial setting.
- All regret exponents are governed by the Hölder exponent α of the CPT weight function.
- The improvement applies whenever the number of arms substantially exceeds the number of players under Hölder-continuous CPT preferences.
Where Pith is reading between the lines
- The same active-set pruning idea may transfer to other behavioral preference models that admit a comparable continuity modulus.
- If the number of players N grows with the horizon, the benefit of removing K may require a revised analysis.
- Empirical tests on human-subject preference data could check whether observed regret scales with the predicted power 2/α.
- The robust algorithms indicate that CPT-based matching can tolerate limited reward manipulation while preserving logarithmic regret.
Load-bearing premise
The CPT weight function must be α-Hölder continuous; if this regularity fails to hold, the derived exponents and the optimality of the active-set improvement no longer apply.
What would settle it
Construct a market instance in which the true weighting function violates α-Hölder continuity and measure whether the observed per-player regret exceeds the claimed O(log T (1/Δ)^{2/α}) scaling.
Figures
read the original abstract
We study a multi-agent multi-armed bandit problem in the competitive setup with two-sided matching markets under a human centric decision making model. To capture human preferences, we use cumulative prospect theory (CPT) that weighs the actions of the agent in a nonlinear fashion using a ($\alpha$-H\"older continuous) weight function. CPT has been widely used in behavioral economics and risk sensitive machine learning to emulate human preferences. We analyze the state-of-the-art learning algorithm with CPT weight distorted rewards and obtain a player optimal regret of $\mathcal{O}(K\log T \left(\frac{1}{\Delta}\right)^{2/\alpha})$, where $K$ denotes the number of arms, $T$ is the learning horizon, and $\Delta$ represents (suitably defined) players' minimum preference gap. Noticing the dependence on $\Delta$ to be sub-optimal, we further improve this regret by judiciously selecting the active set of arms during exploration, which removes the dependence on $K$ in the dominant term and achieves an improved (optimal) regret guarantees in the setting where the number of arms $K$ is significantly larger than the number of players $N$. In addition, we consider adversarial markets where the observed rewards of the agents may be corrupted. We propose and analyze algorithms for robust markets with CPT as risk sensitive measure in both settings where the total corruption budget is known and where it is unknown, and establish logarithmic player-optimal regret guarantees in both cases.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies a multi-agent multi-armed bandit problem in two-sided matching markets under cumulative prospect theory (CPT) with α-Hölder continuous weight functions to model human preferences. It derives a player-optimal regret of O(K log T (1/Δ)^{2/α}) for standard algorithms with CPT-distorted rewards, improves this via active-set arm selection during exploration to remove K dependence when K ≫ N, and extends the analysis to adversarial corruption of rewards, establishing logarithmic regret bounds for both known and unknown corruption budgets.
Significance. If the derivations hold, the work is significant for incorporating realistic behavioral models from prospect theory into competitive matching settings and for providing the first regret guarantees with adversarial robustness in this domain. The active-set improvement addressing the K ≫ N regime and the dual treatment of known/unknown corruption budgets represent concrete advances over standard bandit analyses.
major comments (3)
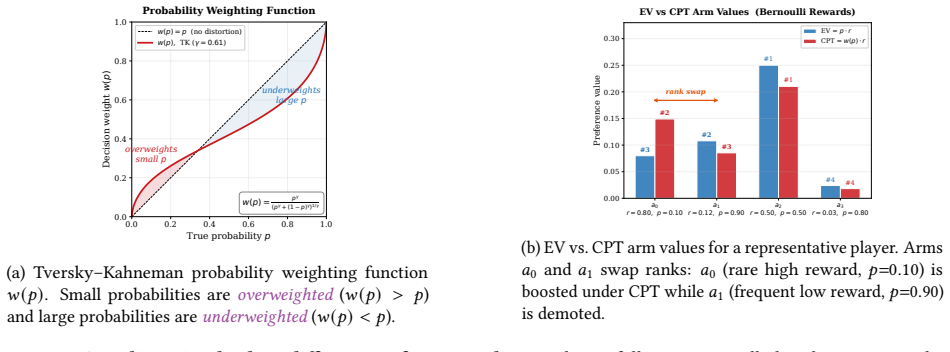
- [Abstract / CPT model definition] Abstract and CPT assumption: the exponent 2/α in the regret bound O(K log T (1/Δ)^{2/α}) is derived from α-Hölder continuity of the weight function; the manuscript must include an explicit lemma or reference verifying that standard CPT weighting functions (e.g., Prelec or Tversky-Kahneman) satisfy this regularity for some α > 0, as this regularity is load-bearing for both the standard bound and the claimed optimality after active-set selection.
- [Active-set exploration analysis] Active-set selection (improved regret claim): the argument that judicious active-set selection removes the K factor in the dominant term when K ≫ N requires an explicit step showing how the construction preserves the minimum preference gap Δ under CPT distortion and the matching constraint; without this, the optimality claim relative to the standard O(K log T (1/Δ)^{2/α}) bound cannot be verified.
- [Robust markets section] Adversarial corruption analysis: the logarithmic regret guarantees for both known and unknown corruption budgets rely on the same CPT regularity; the manuscript should state the precise corruption model (additive or multiplicative) and the corruption-budget dependence in the regret expression, as this is central to the robust-market claims.
minor comments (2)
- [Notation / regret definitions] The abstract refers to Δ as 'suitably defined'; provide the precise definition of the minimum preference gap Δ (including how it incorporates CPT distortion) in the main text near the first regret statement.
- [References] Ensure all prior work on CPT in bandits and on matching-market bandits is cited; the current reference list appears incomplete on the behavioral-economics side.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work on CPT-weighted matching market bandits. We address each major comment below and will revise the manuscript to incorporate clarifications and additional details where needed.
read point-by-point responses
-
Referee: [Abstract / CPT model definition] Abstract and CPT assumption: the exponent 2/α in the regret bound O(K log T (1/Δ)^{2/α}) is derived from α-Hölder continuity of the weight function; the manuscript must include an explicit lemma or reference verifying that standard CPT weighting functions (e.g., Prelec or Tversky-Kahneman) satisfy this regularity for some α > 0, as this regularity is load-bearing for both the standard bound and the claimed optimality after active-set selection.
Authors: We agree this verification strengthens the paper. In the revision we will add Lemma 3.1 (in Section 3) proving that the Prelec weighting function w(p) = exp(−(−ln p)^γ) is 1-Hölder continuous (Lipschitz) on [δ,1−δ] for δ>0 with explicit constant, citing Prelec (1998). The Tversky-Kahneman inverse-S function is likewise Lipschitz on the same domain. This directly supports the 2/α exponent with α=1. revision: yes
-
Referee: [Active-set exploration analysis] Active-set selection (improved regret claim): the argument that judicious active-set selection removes the K factor in the dominant term when K ≫ N requires an explicit step showing how the construction preserves the minimum preference gap Δ under CPT distortion and the matching constraint; without this, the optimality claim relative to the standard O(K log T (1/Δ)^{2/α}) bound cannot be verified.
Authors: The current proof sketch in Appendix B.3 implicitly uses monotonicity of the CPT weight function to preserve Δ, but we acknowledge an explicit step is missing. We will insert a new paragraph after Definition 4.2 and before Theorem 4.3 that shows: (i) the active-set construction selects only arms whose CPT-distorted value differs from the optimum by at least Δ/2, (ii) the bipartite matching constraint is maintained by the same Gale-Shapley ordering used in the original algorithm, and (iii) the minimum gap remains Δ because the weight function is strictly increasing. This yields the K-independent dominant term when K≫N. revision: yes
-
Referee: [Robust markets section] Adversarial corruption analysis: the logarithmic regret guarantees for both known and unknown corruption budgets rely on the same CPT regularity; the manuscript should state the precise corruption model (additive or multiplicative) and the corruption-budget dependence in the regret expression, as this is central to the robust-market claims.
Authors: We will revise Section 5 to explicitly state that corruption is additive (standard model: observed reward = true CPT value + corruption term with total budget C). For known C the regret is O(K log T (1/Δ)^{2/α} + C); for unknown C it is O(K log T (1/Δ)^{2/α} + C log T). The same α-Hölder assumption is used, and we will add the exact dependence on C in Theorems 5.1 and 5.2. revision: yes
Circularity Check
No circularity: regret bounds derived from standard analysis under explicit Hölder assumption on CPT weights
full rationale
The abstract presents the O(K log T (1/Δ)^{2/α}) bound and active-set improvement as results of analyzing a state-of-the-art algorithm under the CPT model with the α-Hölder continuity of the weight function stated as an explicit modeling assumption. No equations, definitions, or self-citations are shown that reduce the claimed regret or optimality to a fitted input, self-referential construction, or load-bearing prior result by the same authors. The derivation chain is therefore independent of its own outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption CPT weight function is α-Hölder continuous
Reference graph
Works this paper leans on
-
[1]
Spectral measures of risk: A coherent representation of subjective risk aversion
Carlo Acerbi. “Spectral measures of risk: A coherent representation of subjective risk aversion”. In:Journal of Banking & Finance26.7 (2002), pp. 1505–1518.doi: https://doi.org/10.1016/S0378-4266(02)00281-9. url:https://www.sciencedirect.com/science/article/pii/S0378426602002819
-
[2]
Online Bandit Learning against an Adaptive Adversary: from Regret to Policy Regret
Raman Arora, Ofer Dekel, and Ambuj Tewari. “Online bandit learning against an adaptive adversary: from regret to policy regret”. In:arXiv preprint arXiv:1206.6400(2012)
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[3]
Philippe Artzner et al. “Coherent Measures of Risk”. In:Mathematical Finance9.3 (1999), pp. 203–228.doi: https://doi.org/10.1111/1467- 9965.00068 . eprint: https://onlinelibrary.wiley.com/doi/ pdf/10.1111/1467-9965.00068 .url: https://onlinelibrary.wiley.com/doi/abs/10.1111/1467- 9965.00068
-
[4]
Beyondlog2(𝑇) regret for decen- tralized bandits in matching markets
Soumya Basu, Karthik Abinav Sankararaman, and Abishek Sankararaman. “Beyondlog2(𝑇) regret for decen- tralized bandits in matching markets”. In:International Conference on Machine Learning. PMLR. 2021, pp. 705– 715
2021
-
[5]
College admissions and the stability of marriage
David Gale and Lloyd S Shapley. “College admissions and the stability of marriage”. In:The American mathe- matical monthly69.1 (1962), pp. 9–15
1962
-
[6]
Competing Bandits in Non-Stationary Matching Markets
Avishek Ghosh et al. “Competing Bandits in Non-Stationary Matching Markets”. In:IEEE Transactions on Information Theory70.4 (2024), pp. 2831–2850.doi:10.1109/TIT.2024.3352228
-
[8]
Utility-based shortfall risk: Efficient computations via Monte Carlo
Zhaolin Hu and Dali Zhang. “Utility-based shortfall risk: Efficient computations via Monte Carlo”. In:Naval Research Logistics (NRL)65 (2018), pp. 378–392.url: https : / / api . semanticscholar . org / CorpusID : 126005263
2018
-
[9]
Learning Equilibria in Matching Markets with Bandit Feedback
Meena Jagadeesan et al. “Learning Equilibria in Matching Markets with Bandit Feedback”. In:J. ACM70.3 (May 2023).doi:10.1145/3583681.url:https://doi.org/10.1145/3583681
work page doi:10.1145/3583681.url:https://doi.org/10.1145/3583681 2023
-
[10]
New York: New York: Farrar, Straus and Giroux, 2011
Daniel Kahneman.Thinking, Fast and Slow. New York: New York: Farrar, Straus and Giroux, 2011
2011
-
[11]
Bandit algorithms to emulate human decision making using probabilistic distortions
Ravi Kumar Kolla et al. “Bandit algorithms to emulate human decision making using probabilistic distortions”. In:arXiv preprint arXiv:1611.10283(2016)
-
[12]
Player-optimal stable regret for bandit learning in matching markets
Fang Kong and Shuai Li. “Player-optimal stable regret for bandit learning in matching markets”. In:Proceedings of the 2023 Annual ACM-SIAM Symposium on Discrete Algorithms (SODA). SIAM. 2023, pp. 1512–1522
2023
-
[13]
Improved analysis for bandit learning in matching markets
Fang Kong, Zilong Wang, and Shuai Li. “Improved analysis for bandit learning in matching markets”. In: Advances in Neural Information Processing Systems37 (2024), pp. 91904–91929. 12
2024
-
[14]
Cumulative Prospect Theory Meets Reinforcement Learning: Prediction and Control
Prashanth L.A. et al. “Cumulative Prospect Theory Meets Reinforcement Learning: Prediction and Control”. In:Proceedings of The 33rd International Conference on Machine Learning. Ed. by Maria Florina Balcan and Kilian Q. Weinberger. Vol. 48. Proceedings of Machine Learning Research. New York, New York, USA: PMLR, 20–22 Jun 2016, pp. 1406–1415.url:https://p...
2016
-
[15]
Asymptotically efficient adaptive allocation rules
T.L Lai and Herbert Robbins. “Asymptotically efficient adaptive allocation rules”. In:Advances in Applied Mathematics6.1 (1985), pp. 4–22.doi: https : / / doi . org / 10 . 1016 / 0196 - 8858(85 ) 90002 - 8.url: https://www.sciencedirect.com/science/article/pii/0196885885900028
-
[16]
Adversarial Bandits with Corruptions: Regret Lower Bound and No-regret Algorithm
lin yang lin et al. “Adversarial Bandits with Corruptions: Regret Lower Bound and No-regret Algorithm”. In: Advances in Neural Information Processing Systems. Ed. by H. Larochelle et al. Vol. 33. Curran Associates, Inc., 2020, pp. 19943–19952
2020
-
[17]
Competing bandits in matching markets
Lydia T Liu, Horia Mania, and Michael Jordan. “Competing bandits in matching markets”. In:International Conference on Artificial Intelligence and Statistics. PMLR. 2020, pp. 1618–1628
2020
-
[18]
Bandit learning in decentralized matching markets
Lydia T Liu et al. “Bandit learning in decentralized matching markets”. In:Journal of Machine Learning Research 22.211 (2021), pp. 1–34
2021
-
[19]
Harry Markowitz. “Portfolio Selection”. In:The Journal of Finance7.1 (1952), pp. 77–91.url: http://www. jstor.org/stable/2975974(visited on 01/25/2026)
-
[20]
What You See May Not Be What You Get: UCB Bandit Algorithms Robust to epsilon Contamination
Laura Niss and Ambuj Tewari. “What You See May Not Be What You Get: UCB Bandit Algorithms Robust to epsilon Contamination”. In:Conference on Uncertainty in Artificial Intelligence. PMLR. 2020, pp. 450–459
2020
-
[21]
Detecting click fraud in online advertising: a data mining approach
Richard Oentaryo et al. “Detecting click fraud in online advertising: a data mining approach”. In:J. Mach. Learn. Res.15.1 (Jan. 2014), pp. 99–140
2014
-
[22]
Explore-then-commit algorithms for decentralized two-sided matching markets
Tejas Pagare and Avishek Ghosh. “Explore-then-commit algorithms for decentralized two-sided matching markets”. In:2024 IEEE International Symposium on Information Theory (ISIT). IEEE. 2024, pp. 2092–2097
2024
-
[23]
Optimization of conditional value-at risk
R. Tyrrell Rockafellar and Stanislav Uryasev. “Optimization of conditional value-at risk”. In:Journal of Risk3 (2000), pp. 21–41.url:https://api.semanticscholar.org/CorpusID:854622
2000
-
[24]
Dominate or Delete: Decentralized Competing Bandits in Serial Dictatorship
Abishek Sankararaman, Soumya Basu, and Karthik Abinav Sankararaman. “Dominate or Delete: Decentralized Competing Bandits in Serial Dictatorship”. In:Proceedings of The 24th International Conference on Artificial Intelligence and Statistics. Ed. by Arindam Banerjee and Kenji Fukumizu. Vol. 130. Proceedings of Machine Learning Research. PMLR, 13–15 Apr 2021...
2021
-
[25]
Online robust non-stationary estimation
Abishek Sankararaman and Balakrishnan (Murali) Narayanaswamy. “Online robust non-stationary estimation”. In:Proceedings of the 37th International Conference on Neural Information Processing Systems. NIPS ’23. New Orleans, LA, USA: Curran Associates Inc., 2023
2023
-
[26]
FITNESS: (Fine Tune on New and Similar Samples) to detect anomalies in streams with drift and outliers
Abishek Sankararaman et al. “FITNESS: (Fine Tune on New and Similar Samples) to detect anomalies in streams with drift and outliers”. In:Proceedings of the 39th International Conference on Machine Learning. Ed. by Kamalika Chaudhuri et al. Vol. 162. Proceedings of Machine Learning Research. PMLR, 17–23 Jul 2022, pp. 19153–19177. url:https://proceedings.ml...
2022
- [27]
-
[28]
Risk-sensitive Bandits: Arm Mixture Optimality and Regret-efficient Algorithms
Meltem Tatlı et al. “Risk-sensitive Bandits: Arm Mixture Optimality and Regret-efficient Algorithms”. In: Proceedings of The 28th International Conference on Artificial Intelligence and Statistics. Ed. by Yingzhen Li et al. Vol. 258. Proceedings of Machine Learning Research. PMLR, Mar. 2025, pp. 3871–3879.url: https : //proceedings.mlr.press/v258/tatli25a.html
2025
-
[29]
Advances in prospect theory: Cumulative representation of uncertainty
Amos Tversky and Daniel Kahneman. “Advances in prospect theory: Cumulative representation of uncertainty”. In:Journal of Risk and uncertainty5.4 (1992), pp. 297–323
1992
-
[30]
Bandit Learning in Matching Markets Robust to Adversarial Corruptions
Zheshun Wu et al. “Bandit Learning in Matching Markets Robust to Adversarial Corruptions”. In:The Fourteenth International Conference on Learning Representations. 2026.url: https://openreview.net/forum?id= CoWJc5ofDO. 13
2026
-
[31]
Detecting Click Fraud in Pay-Per-Click Streams of Online Advertising Networks
Linfeng Zhang and Yong Guan. “Detecting Click Fraud in Pay-Per-Click Streams of Online Advertising Networks”. In:Proceedings of the 2008 The 28th International Conference on Distributed Computing Systems. ICDCS ’08. USA: IEEE Computer Society, 2008, pp. 77–84.doi: 10 . 1109 / ICDCS . 2008 . 98.url: https : //doi.org/10.1109/ICDCS.2008.98. 14 A Additional ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.