CLAP: Closed-Loop Training, Evaluation, and Release Control for Domain Agent Post-training
Pith reviewed 2026-07-03 13:24 UTC · model grok-4.3
The pith
CLAP converts business data into structured samples and uses multiple diagnostic gates plus replay to decide domain-agent adapter release.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
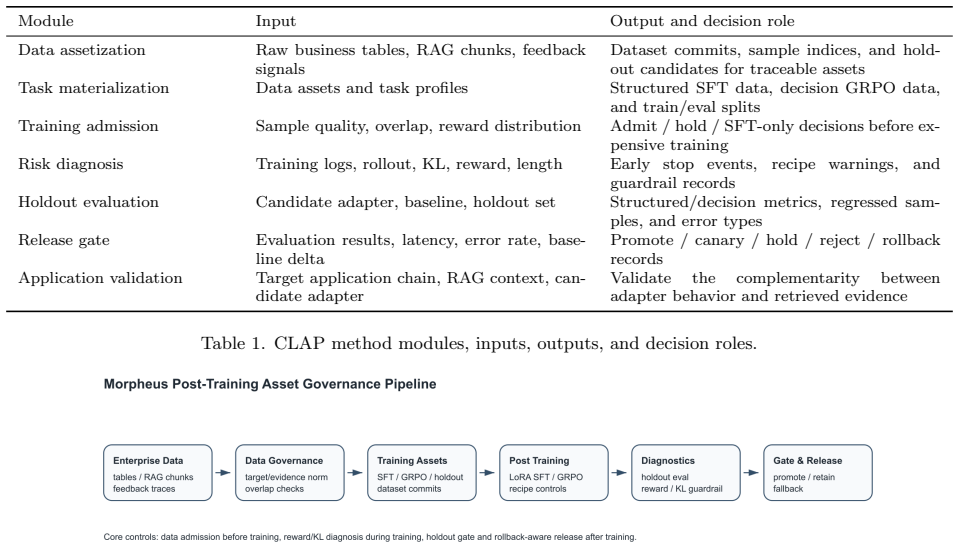
CLAP converts business data into structured SFT samples, decision-preference samples, holdout sets, risk diagnostics, and release-gate records. It combines data validation, target/evidence normalization, reward/KL diagnosis, offline gates, and application-chain replay to decide whether an adapter is suitable for the target application chain. On five anonymized manufacturing-scenario batches, QLoRA-style LoRA-SFT yields modest average gains in overall score, pass rate, and evidence accuracy while reducing hallucination and wrong facts, though only three of five batches improve and GRPO shows high KL risks. Application-chain replay further shows that RAG is necessary for factual extraction, an
What carries the argument
The CLAP closed loop that structures business data into training and evaluation artifacts while running validation, normalization, diagnosis, gates, and application replay to control adapter release.
If this is right
- Overall score rises by 0.0098, pass rate by 0.0240, and evidence accuracy by 0.0280 on average.
- Hallucination and wrong facts decrease across the batches.
- Only three of the five batches improve; some batches regress.
- GRPO training exposes high KL risks that the loop can flag.
- An application-RAG-oriented adapter improves matching metrics but raises latency under the same backbone and replay cases.
Where Pith is reading between the lines
- The loop could be applied to post-training in domains other than manufacturing where business data is similarly noisy.
- Single offline scores are likely insufficient for safe release decisions in most domain-agent settings.
- Methods that deliver consistent gains across all batches rather than average gains would strengthen the loop's utility.
Load-bearing premise
The five manufacturing batches sufficiently represent the range of challenges that arise in domain-agent post-training.
What would settle it
A larger collection of batches or a different domain in which adapters that pass all CLAP gates still produce failures or missed value when deployed in their target application chains.
Figures
read the original abstract
Domain agents often face noisy business data, uncertain post-training gains, offline/application mismatch, and adapter-release risk. This paper presents CLAP (Closed-Loop Agent Post-training), a closed-loop method that converts business data into structured SFT samples, decision-preference samples, holdout sets, risk diagnostics, and release-gate records. CLAP combines data validation, target/evidence normalization, reward/KL diagnosis, offline gates, and application-chain replay to decide whether an adapter is suitable for the target application chain. On five anonymized manufacturing-scenario batches, QLoRA-style LoRA-SFT yields modest average gains: overall score increases by 0.0098, pass rate by 0.0240, and evidence accuracy by 0.0280, while hallucination and wrong facts decrease. Yet only 3 of 5 batches improve, some batches regress, and GRPO exposes high KL risks. Application-chain replay further shows that RAG is necessary for factual extraction; under the same 3B backbone and 100 replay cases, an application-RAG-oriented LoRA-SFT adapter improves value, core fields, and answer-evidence doc/page matching over base+RAG, but increases latency. These results support managing domain-agent post-training through an integrated data-training-evaluation-release loop rather than relying on training completion or a single offline score.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CLAP, a closed-loop framework for domain agent post-training that converts business data into structured SFT samples, decision-preference samples, holdout sets, risk diagnostics, and release-gate records. It integrates data validation, target/evidence normalization, reward/KL diagnosis, offline gates, and application-chain replay to determine adapter suitability for target application chains. On five anonymized manufacturing batches, QLoRA-style LoRA-SFT yields modest average gains (overall score +0.0098, pass rate +0.0240, evidence accuracy +0.0280) with reductions in hallucination and wrong facts, though only 3/5 batches improve and some regress; GRPO shows high KL risks. Application-chain replay under a 3B backbone and 100 cases indicates RAG is necessary for factual extraction, with an application-RAG-oriented adapter improving value/core fields/matching over base+RAG but increasing latency. The results are presented as supporting integrated loop-based management over single-score or training-completion approaches.
Significance. If the closed-loop components can be shown to produce reliable, correlated decisions on adapter release, the work would offer a practical methodology for handling noisy data, uncertain gains, and release risk in domain-specific agents. The emphasis on end-to-end data-to-release control and the inclusion of application-chain replay diagnostics are strengths that could inform deployment pipelines, though the narrow empirical base (five batches, mixed outcomes, no statistical detail) limits broader claims at present.
major comments (3)
- [Experimental evaluation on manufacturing batches] Experimental results (five-batch evaluation): the central claim that the combination of data validation, normalization, reward/KL diagnosis, offline gates, and replay produces decisions that reliably determine adapter suitability is not supported by the reported evidence. Only 3/5 batches improve, two regress, and no per-batch gate outcomes, replay diagnostics, decision thresholds, or correlation between loop components and observed deltas are provided; the modest averages (+0.0098 score, +0.0240 pass rate, +0.0280 evidence accuracy) therefore do not demonstrate control over noisy data and release risk.
- [Experimental evaluation on manufacturing batches] Experimental results (five-batch evaluation): the abstract and results report concrete deltas without statistical details, error bars, full baseline comparisons, or significance tests. This absence makes it impossible to assess whether the mixed per-batch outcomes reflect reliable loop behavior or simply noise, directly undermining the recommendation for closed-loop control.
- [Application-chain replay experiments] Application-chain replay experiments: the claim that RAG is necessary and that the application-RAG-oriented LoRA-SFT adapter improves value, core fields, and doc/page matching is presented under a fixed 3B backbone and 100 cases, yet no ablation isolating the contribution of the full CLAP loop (versus training alone) or comparison against alternative post-training methods is shown, leaving the necessity of the integrated pipeline unestablished.
minor comments (2)
- The term 'GRPO' is used when discussing high KL risks but is not defined or expanded in the provided text, reducing clarity of the risk-diagnosis component.
- [Experimental evaluation on manufacturing batches] The five batches are described as 'anonymized manufacturing-scenario' without any characterization of their diversity, size, or noise characteristics, which limits assessment of how representative they are for the claimed domain-agent challenges.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below, agreeing where revisions are needed to better support the claims and clarifying the scope of the presented experiments.
read point-by-point responses
-
Referee: Experimental results (five-batch evaluation): the central claim that the combination of data validation, normalization, reward/KL diagnosis, offline gates, and replay produces decisions that reliably determine adapter suitability is not supported by the reported evidence. Only 3/5 batches improve, two regress, and no per-batch gate outcomes, replay diagnostics, decision thresholds, or correlation between loop components and observed deltas are provided; the modest averages (+0.0098 score, +0.0240 pass rate, +0.0280 evidence accuracy) therefore do not demonstrate control over noisy data and release risk.
Authors: We agree that the mixed per-batch outcomes (explicitly noted in the manuscript) limit the strength of claims about reliable control, and that additional details on gate outcomes and correlations would strengthen the evidence. In the revision we will add per-batch gate outcomes, replay diagnostics, and decision thresholds to illustrate how loop components inform release decisions despite uncertain gains. revision: yes
-
Referee: Experimental results (five-batch evaluation): the abstract and results report concrete deltas without statistical details, error bars, full baseline comparisons, or significance tests. This absence makes it impossible to assess whether the mixed per-batch outcomes reflect reliable loop behavior or simply noise, directly undermining the recommendation for closed-loop control.
Authors: We acknowledge the absence of statistical details, error bars, and significance tests in the current version. We will incorporate error bars, expanded baseline comparisons, and significance testing in the revised manuscript. Due to the anonymized nature of the manufacturing batches, some granular per-batch statistics remain constrained, but we will clarify this limitation. revision: partial
-
Referee: Application-chain replay experiments: the claim that RAG is necessary and that the application-RAG-oriented LoRA-SFT adapter improves value, core fields, and doc/page matching is presented under a fixed 3B backbone and 100 cases, yet no ablation isolating the contribution of the full CLAP loop (versus training alone) or comparison against alternative post-training methods is shown, leaving the necessity of the integrated pipeline unestablished.
Authors: The replay experiments serve as a diagnostic step within the CLAP loop rather than a comprehensive ablation of the full pipeline. We will revise the text to explicitly distinguish the diagnostic role and discuss why the integrated loop enables these checks. A full ablation isolating the loop versus training alone is not present in the current experiments; we will note this as a limitation and outline directions for future work. revision: partial
Circularity Check
No significant circularity; empirical method with no derivations or self-referential reductions
full rationale
The paper describes a closed-loop engineering process (CLAP) for domain agent post-training and reports empirical results on five anonymized manufacturing batches. No equations, mathematical derivations, fitted parameters, or predictions appear in the provided text. The central claim rests on observed average gains (score +0.0098, pass rate +0.0240, evidence accuracy +0.0280) and mixed per-batch outcomes rather than any reduction of outputs to inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing steps. This is a standard non-finding for a systems paper whose value is in the described workflow and experimental observations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Retrieval-augmented generation for knowledge-intensive NLP tasks,
P. Lewis et al., “Retrieval-augmented generation for knowledge-intensive NLP tasks,”NeurIPS33, 9459– 9474 (2020)
2020
-
[2]
LoRA: Low-rank adaptation of large language models,
E. J. Hu et al., “LoRA: Low-rank adaptation of large language models,”ICLR(2022)
2022
-
[3]
Training language models to follow instructions with human feedback,
L. Ouyang et al., “Training language models to follow instructions with human feedback,”NeurIPS35, 27730–27744 (2022)
2022
-
[4]
Direct preference optimization: Your language model is secretly a reward model,
R. Rafailov et al., “Direct preference optimization: Your language model is secretly a reward model,” NeurIPS36 (2023)
2023
-
[5]
QLoRA: Efficient finetuning of quantized LLMs,
T. Dettmers et al., “QLoRA: Efficient finetuning of quantized LLMs,”NeurIPS36 (2023)
2023
-
[6]
Self-RAG,
A. Asai et al., “Self-RAG,”ICLR(2024)
2024
-
[7]
RAFT: Adapting Language Model to Domain Specific RAG,
T. Zhang et al., “RAFT: Adapting Language Model to Domain Specific RAG,”COLM(2024)
2024
-
[8]
A Comprehensive Overview of Large Language Models,
S. Naveed et al., “A Comprehensive Overview of Large Language Models,”ACM Transactions on Intelligent Systems and Technology16(5), 1–72 (2025). DOI: 10.1145/3744746
-
[9]
A Survey on Retrieval-Augmented Text Generation for Large Language Models,
Y. Huang and J. X. Huang, “A Survey on Retrieval-Augmented Text Generation for Large Language Models,”ACM Computing Surveys58(12), Article 300, 1–38 (2026). DOI: 10.1145/3805774
-
[10]
Survey of Hallucination in Natural Language Generation,
Z. Ji et al., “Survey of Hallucination in Natural Language Generation,”ACM Computing Surveys55(12), Article 248, 1–38 (2023). DOI: 10.1145/3571730
-
[11]
ACM Transactions on Information Systems 43, 1–55
L. Huang et al., “A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Chal- lenges, and Open Questions,”ACM Transactions on Information Systems43(2), 1–55 (2025). DOI: 10.1145/3703155
-
[12]
Parameter-efficient fine-tuning in large language models: A survey of methodologies,
L. Wang et al., “Parameter-efficient fine-tuning in large language models: A survey of methodologies,” Artificial Intelligence Review58, Article 227 (2025). DOI: 10.1007/s10462-025-11236-4
-
[13]
C. O. Retzlaff et al., “Human-in-the-Loop Reinforcement Learning: A Survey and Position on Require- ments, Challenges, and Opportunities,”Journal of Artificial Intelligence Research79, 359–415 (2024). DOI: 10.1613/jair.1.15348
-
[14]
RLHF Deciphered: A Critical Analysis of Reinforcement Learning from Human Feedback for LLMs,
S. Chaudhari et al., “RLHF Deciphered: A Critical Analysis of Reinforcement Learning from Human Feedback for LLMs,”ACM Computing Surveys58(2), Article 53 (2026). DOI: 10.1145/3743127
-
[15]
ReAct: Synergizing reasoning and acting in language models,
S. Yao et al., “ReAct: Synergizing reasoning and acting in language models,”ICLR(2023)
2023
-
[16]
AgentBench: Evaluating LLMs as agents,
X. Liu et al., “AgentBench: Evaluating LLMs as agents,”ICLR(2024)
2024
-
[17]
ToolLLM,
Y. Qin et al., “ToolLLM,”ICLR(2024)
2024
-
[18]
LaMDAgent: An autonomous framework for post-training pipeline optimization via LLM agents,
T. Yano et al., “LaMDAgent: An autonomous framework for post-training pipeline optimization via LLM agents,”EMNLP(2025)
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.