ROAD-VLA: Robust Online Adaptation via Self-Distillation for Vision-Language-Action Models
Pith reviewed 2026-06-25 20:20 UTC · model grok-4.3
The pith
ROAD-VLA adapts VLA models online by creating a proximal teacher through advantage-perturbed action logits for dense self-distillation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
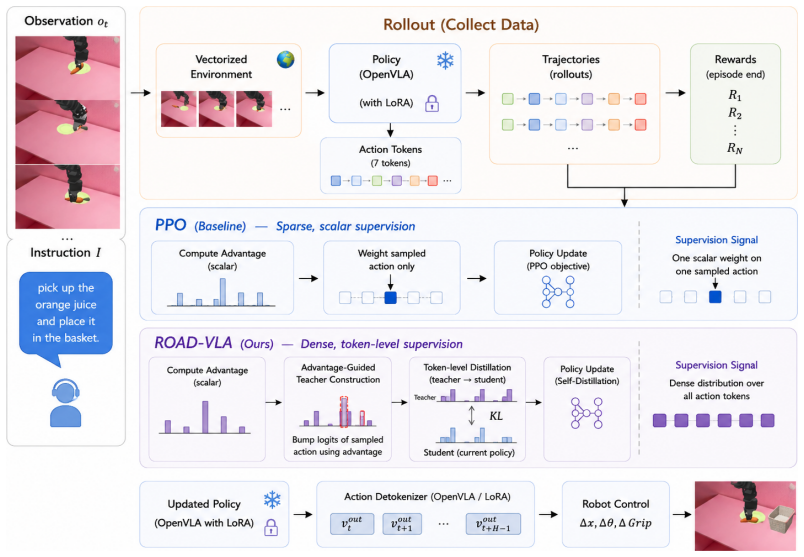
By perturbing action-token logits with calibrated advantage estimates, ROAD-VLA constructs a proximal teacher in action space that converts sparse rewards into dense token-level supervision for online VLA adaptation, supported by a derived policy-improvement lower bound.
What carries the argument
Advantage-guided self-distillation that perturbs action-token logits with calibrated advantage estimates to form a proximal teacher policy.
If this is right
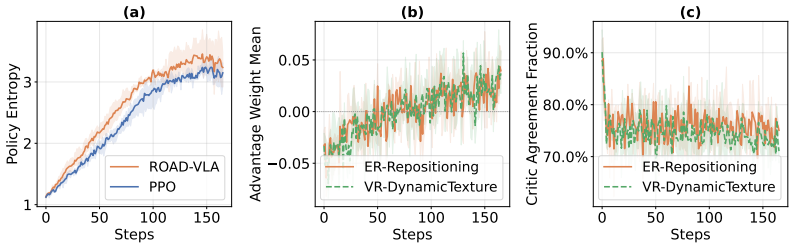
- Converts sparse rewards into dense token-level supervision for high-dimensional autoregressive policies.
- Maintains teacher proximity to the current policy for effective distillation.
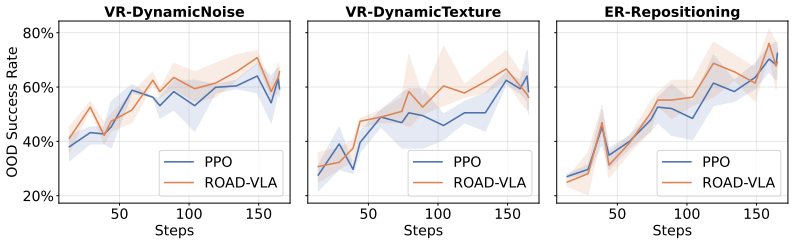
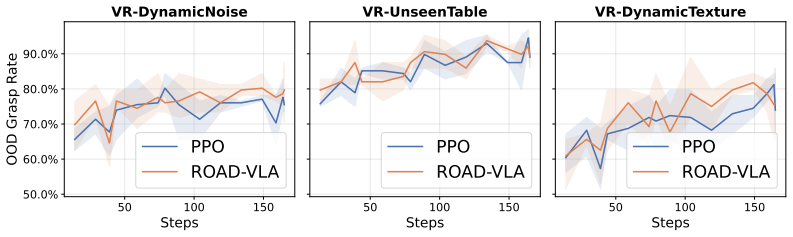
- Demonstrates robust performance across in-distribution and out-of-distribution robotic environments.
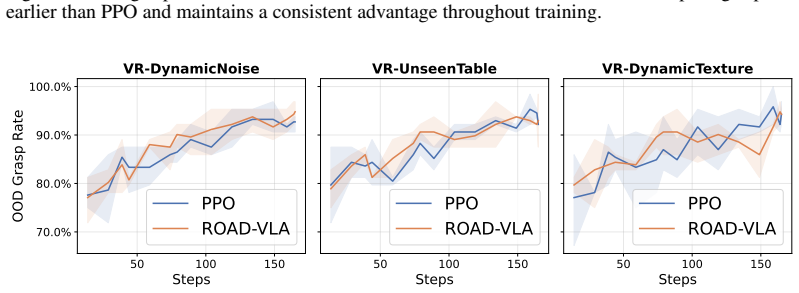
- Outperforms standard PPO in nearly all tested settings.
- Provides a theoretical policy-improvement lower bound based on calibrated advantages.
Where Pith is reading between the lines
- Action-space self-distillation may apply to other autoregressive control policies facing sparse rewards.
- Reducing reliance on symbolic or text-based teachers could simplify VLA training pipelines.
- Further validation in physical robot settings would test the calibration assumptions in real dynamics.
Load-bearing premise
Advantage estimates can be calibrated accurately enough that the resulting teacher stays close to the current policy and the improvement bound holds.
What would settle it
A controlled experiment where advantage calibration is intentionally poor, leading to no improvement or degradation compared to PPO, or direct measurement showing the teacher diverges from the policy.
Figures

read the original abstract
Effective online adaptation of vision-language-action (VLA) models remains challenging, as sparse rewards provide weak supervision for high-dimensional autoregressive action policies. Although self-distillation can in principle provide denser training signals, we find that text-based privileged teachers conditioned on demonstrations, retrieved experiences, or high-level plans are ineffective for VLA adaptation, exposing a modality gap between symbolic guidance and low-level robot actions. We propose ROAD-VLA, an advantage-guided self-distillation framework that constructs a proximal teacher directly in action space by perturbing action-token logits with calibrated advantage estimates. This converts sparse rewards into dense token-level supervision while keeping the teacher close to the current policy. We further derive a policy-improvement lower bound under calibrated advantages and accurate teacher matching. Across seven robotic manipulation environments with in-distribution and out-of-distribution shifts, ROADVLA outperforms PPO in nearly all settings, demonstrating robust online VLA adaptation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ROAD-VLA, an advantage-guided self-distillation method for online adaptation of vision-language-action (VLA) models. It constructs a proximal teacher in action space by perturbing action-token logits using calibrated advantage estimates to convert sparse rewards into dense token-level supervision, derives a policy-improvement lower bound under the assumptions of calibrated advantages and accurate teacher matching, and reports that the method outperforms PPO across seven robotic manipulation environments under both in-distribution and out-of-distribution shifts.
Significance. If the lower bound is valid and the assumptions hold, the framework could offer a principled approach to dense supervision for high-dimensional autoregressive VLA policies without relying on ineffective text-based teachers, potentially improving robustness to distribution shifts in robotic adaptation tasks.
major comments (3)
- [Abstract] Abstract: the policy-improvement lower bound is derived under the conditions of calibrated advantages and accurate teacher matching, yet no derivation steps, explicit assumptions, or independent verification (e.g., external benchmark or closed-form guarantee separate from the advantage-guided procedure) are supplied; this renders the theoretical justification circular with the method itself.
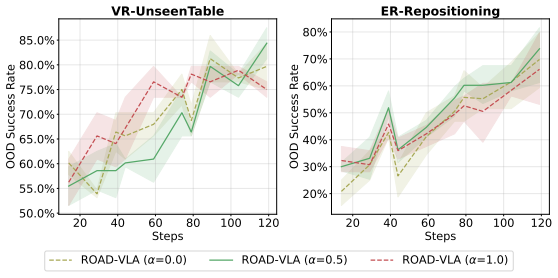
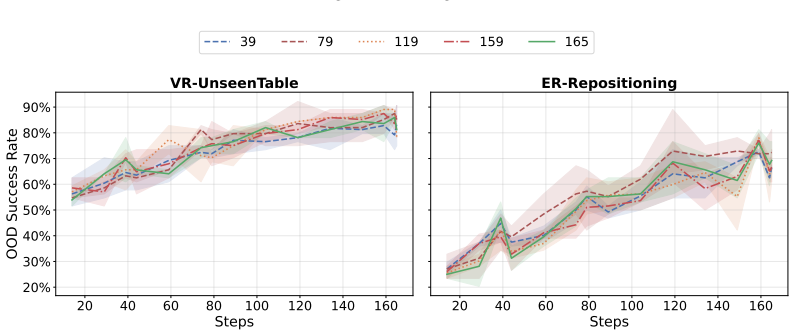
- [Abstract] Abstract: the central empirical claim of outperformance over PPO in nearly all settings supplies no error bars, statistical tests, or ablation on advantage calibration, leaving the robustness of the reported gains unassessable and the practical validity of the bound unverified.
- [Abstract] Abstract: no description is given of how advantages are estimated or how the teacher is ensured to remain proximal, which are load-bearing premises for both the lower bound and the conversion of sparse rewards to token-level supervision.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript accordingly to improve clarity on the theoretical derivation, empirical reporting, and methodological details.
read point-by-point responses
-
Referee: [Abstract] Abstract: the policy-improvement lower bound is derived under the conditions of calibrated advantages and accurate teacher matching, yet no derivation steps, explicit assumptions, or independent verification (e.g., external benchmark or closed-form guarantee separate from the advantage-guided procedure) are supplied; this renders the theoretical justification circular with the method itself.
Authors: The derivation steps and explicit assumptions (calibrated advantages and accurate teacher matching) are presented in Section 3.2. To address concerns of circularity, we will add an appendix containing an independent verification on a simplified MDP with closed-form analysis demonstrating the bound holds separately from the main procedure. revision: yes
-
Referee: [Abstract] Abstract: the central empirical claim of outperformance over PPO in nearly all settings supplies no error bars, statistical tests, or ablation on advantage calibration, leaving the robustness of the reported gains unassessable and the practical validity of the bound unverified.
Authors: We agree that error bars, statistical tests, and an ablation on advantage calibration are needed to assess robustness. The experiments used multiple seeds; we will add error bars to figures, include statistical significance tests, and provide the requested ablation in the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract: no description is given of how advantages are estimated or how the teacher is ensured to remain proximal, which are load-bearing premises for both the lower bound and the conversion of sparse rewards to token-level supervision.
Authors: Advantage estimation (via learned critic with TD updates) and proximal teacher construction (via bounded logit perturbation) are detailed in Sections 3.1 and 3.3. We will revise the abstract to briefly reference these elements and ensure the premises are highlighted more explicitly in the main text. revision: yes
Circularity Check
Policy-improvement lower bound conditioned on method-produced quantities
specific steps
-
self definitional
[Abstract]
"We further derive a policy-improvement lower bound under calibrated advantages and accurate teacher matching."
The bound is derived under assumptions (calibrated advantages, accurate teacher matching) that are generated by the paper's own advantage-guided self-distillation framework, which perturbs action-token logits with calibrated advantage estimates to construct the proximal teacher. The theoretical justification therefore reduces to assuming the method's success conditions hold.
full rationale
The abstract states a derivation of a policy-improvement lower bound under the conditions of calibrated advantages and accurate teacher matching. These conditions are exactly the outputs of the advantage-guided self-distillation procedure described in the same abstract (perturbing logits with calibrated advantage estimates to keep the teacher proximal). This creates a self-definitional dependence where the claimed guarantee holds only if the method already succeeds at producing those quantities, with no independent verification referenced. No other circular steps are identifiable from the provided text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
On-policy distillation of language models: Learning from self-generated mistakes
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos Garea, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self-generated mistakes. In The twelfth international conference on learning representations, 2024
2024
-
[2]
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. pi_0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[3]
Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alexander Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
Pith/arXiv arXiv 2022
-
[4]
Danny Driess, Fei Xia, Mehdi S. M. Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, et al. Palm-e: An embodied multimodal language model. InProceedings of the International Conference on Machine Learning (ICML), volume 202, 2023
2023
-
[5]
Foundation models in robotics: Applications, challenges, and the future.The International Journal of Robotics Research, 44(5):701–739, 2025
Roya Firoozi, Johnathan Tucker, Stephen Tian, Anirudha Majumdar, Jiankai Sun, Weiyu Liu, Yuke Zhu, Shuran Song, Ashish Kapoor, Karol Hausman, et al. Foundation models in robotics: Applications, challenges, and the future.The International Journal of Robotics Research, 44(5):701–739, 2025
2025
-
[6]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
Pith/arXiv arXiv 2025
-
[7]
Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531, 2015
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531, 2015
Pith/arXiv arXiv 2015
-
[8]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsc...
Pith/arXiv arXiv 2025
-
[9]
Prismatic vlms: Investigating the design space of visually-conditioned language models
Siddharth Karamcheti, Suraj Nair, Ashwin Balakrishna, Percy Liang, Thomas Kollar, and Dorsa Sadigh. Prismatic vlms: Investigating the design space of visually-conditioned language models. InProceedings of the International Conference on Machine Learning (ICML), 2024
2024
-
[10]
Openvla: An open-source vision-language- action model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan P Foster, Pannag R Sanketi, Quan Vuong, et al. Openvla: An open-source vision-language- action model. In8th Annual Conference on Robot Learning, 2024
2024
-
[11]
Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
Pith/arXiv arXiv 2025
-
[12]
Learning without forgetting
Zhizhong Li and Derek Hoiem. Learning without forgetting. InEuropean Conference on Computer Vision, pages 614–629, 2016
2016
-
[13]
On-the-fly vla adaptation via test-time reinforcement learning.arXiv preprint arXiv:2601.06748, 2026
Changyu Liu, Yiyang Liu, Taowen Wang, Qiao Zhuang, James Chenhao Liang, Wenhao Yang, Renjing Xu, Qifan Wang, Dongfang Liu, and Cheng Han. On-the-fly vla adaptation via test-time reinforcement learning.arXiv preprint arXiv:2601.06748, 2026
Pith/arXiv arXiv 2026
-
[14]
What can RL bring to VLA generalization? an empirical study
Jijia Liu, Feng Gao, Bingwen Wei, Xinlei Chen, Qingmin Liao, Yi Wu, Chao Yu, and Yu Wang. What can RL bring to VLA generalization? an empirical study. InAdvances in Neural Information Processing Systems (NeurIPS), 2026
2026
-
[15]
A survey on vision–language– action models for embodied ai.IEEE Transactions on Neural Networks and Learning Systems, 2026
Yueen Ma, Zixing Song, Yuzheng Zhuang, Jianye Hao, and Irwin King. A survey on vision–language– action models for embodied ai.IEEE Transactions on Neural Networks and Learning Systems, 2026
2026
-
[16]
Octo: An open-source generalist robot policy
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, et al. Octo: An open-source generalist robot policy. InRobotics: Science and Systems, 2024
2024
-
[17]
Dinov2: Learning robust visual features without supervision.Transactions on Machine Learning Research (TMLR) Journal, 2024
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.Transactions on Machine Learning Research (TMLR) Journal, 2024
2024
-
[18]
Privileged information distillation for language models.arXiv preprint arXiv:2602.04942, 2026
Emiliano Penaloza, Dheeraj Vattikonda, Nicolas Gontier, Alexandre Lacoste, Laurent Charlin, and Massimo Caccia. Privileged information distillation for language models.arXiv preprint arXiv:2602.04942, 2026
Pith/arXiv arXiv 2026
-
[19]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[20]
Andrei A. Rusu, Sergio Gomez Colmenarejo, Caglar Gulcehre, Guillaume Desjardins, James Kirkpatrick, Razvan Pascanu, V olodymyr Mnih, Koray Kavukcuoglu, and Raia Hadsell. Policy distillation.arXiv preprint arXiv:1511.06295, 2015
Pith/arXiv arXiv 2015
-
[21]
Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[22]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
Pith/arXiv arXiv 2024
-
[23]
Self-distillation enables continual learning.arXiv preprint arXiv:2601.19897, 2026
Idan Shenfeld, Mehul Damani, Jonas Hübotter, and Pulkit Agrawal. Self-distillation enables continual learning.arXiv preprint arXiv:2601.19897, 2026
Pith/arXiv arXiv 2026
-
[24]
MIT press Cambridge, 1998
Richard S Sutton, Andrew G Barto, et al.Reinforcement learning: An introduction, volume 1. MIT press Cambridge, 1998
1998
-
[25]
Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
Pith/arXiv arXiv 2023
-
[26]
Wencheng Ye, Tianshi Wang, Lei Zhu, Fengling Li, and Guoli Yang. Actdistill: General action-guided self-derived distillation for efficient vision-language-action models.arXiv preprint arXiv:2511.18082, 2025
Pith/arXiv arXiv 2025
-
[27]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InProceedings of the IEEE/CVF international conference on computer vision, pages 11975–11986, 2023. 12
2023
-
[28]
Hongyin Zhang, Shuo Zhang, Junxi Jin, Qixin Zeng, Runze Li, and Donglin Wang. Robustvla: Robustness- aware reinforcement post-training for vision-language-action models.arXiv preprint arXiv:2511.01331, 2025
arXiv 2025
-
[29]
Jianke Zhang, Yanjiang Guo, Xiaoyu Chen, Yen-Jen Wang, Yucheng Hu, Chengming Shi, and Jianyu Chen. Hirt: Enhancing robotic control with hierarchical robot transformers.arXiv preprint arXiv:2410.05273, 2024
arXiv 2024
-
[30]
Grape: Generalizing robot policy via preference alignment.arXiv preprint arXiv:2411.19309, 2024
Zijian Zhang, Kaiyuan Zheng, Zhaorun Chen, Joel Jang, Yi Li, Siwei Han, Chaoqi Wang, Mingyu Ding, Dieter Fox, and Huaxiu Yao. Grape: Generalizing robot policy via preference alignment.arXiv preprint arXiv:2411.19309, 2024
arXiv 2024
-
[31]
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. Self- distilled reasoner: On-policy self-distillation for large language models.arXiv preprint arXiv:2601.18734, 2026
Pith/arXiv arXiv 2026
-
[32]
Zhide Zhong, Haodong Yan, Junfeng Li, Junjie He, Tianran Zhang, and Haoang Li. Vla-opd: Bridging offline sft and online rl for vision-language-action models via on-policy distillation.arXiv preprint arXiv:2603.26666, 2026
arXiv 2026
-
[33]
Rt-2: Vision-language-action models transfer web knowledge to robotic control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InProceedings of The 7th Conference on Robot Learning, volume 229 ofProceedings of Machine Learning Research, pages 2165–2183, 2023. 13 A More Theo...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.