FLM-Occ: Feed-forward Likelihood Maximization for Efficient Indoor Occupancy Prediction
Pith reviewed 2026-06-26 14:32 UTC · model grok-4.3
The pith
FLM-Occ predicts indoor occupancy by maximizing the likelihood of a mixture model over ground-truth occupied voxels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
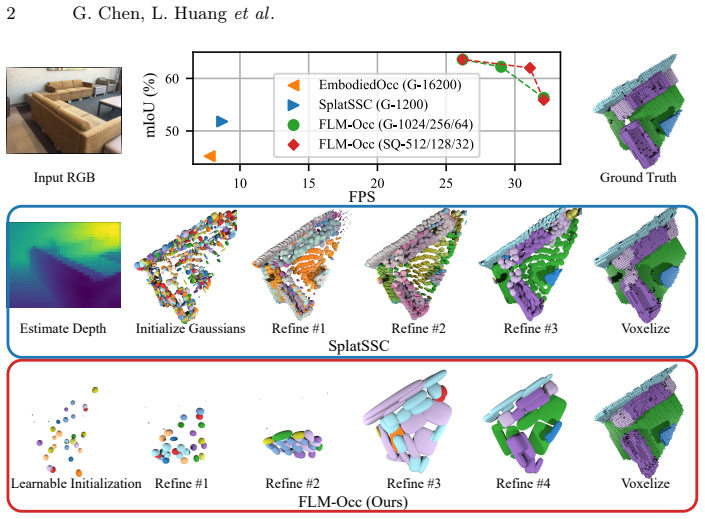
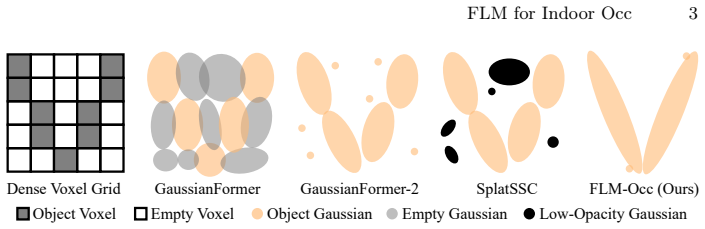
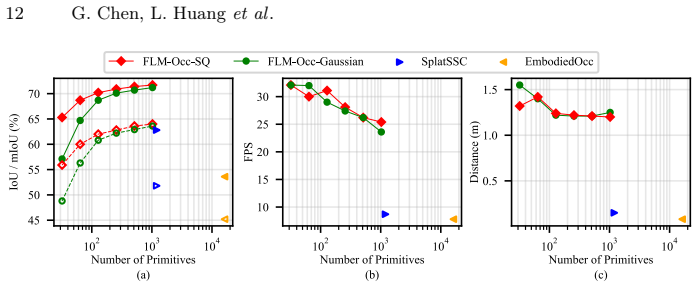
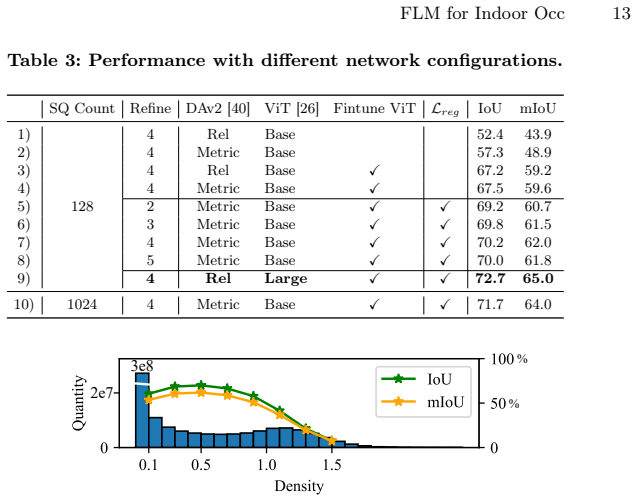
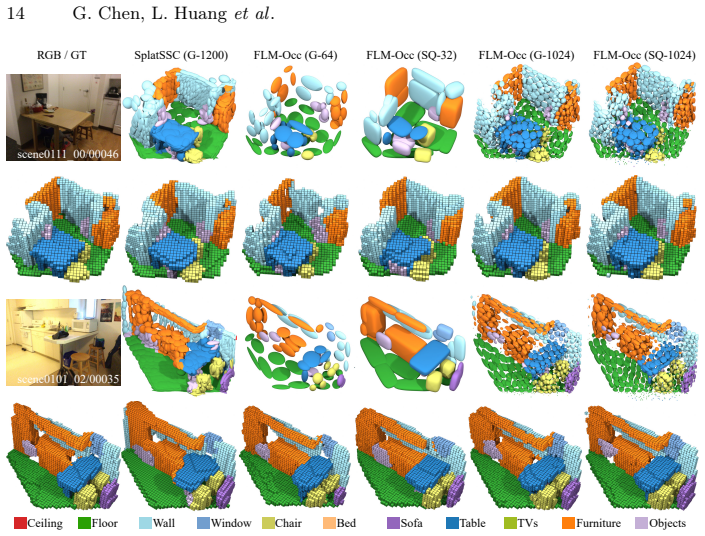
FLM-Occ is a method based on Feed-forward Likelihood Maximization that trains a network to predict a mixture model maximizing the likelihood over ground-truth occupied voxels. It uses only 32 superquadrics to achieve superior accuracy on Occ-ScanNet compared to prior state-of-the-art, representing just 2.7% of the primitives used before, and runs 3.7 times faster by avoiding spurious primitives in empty regions.
What carries the argument
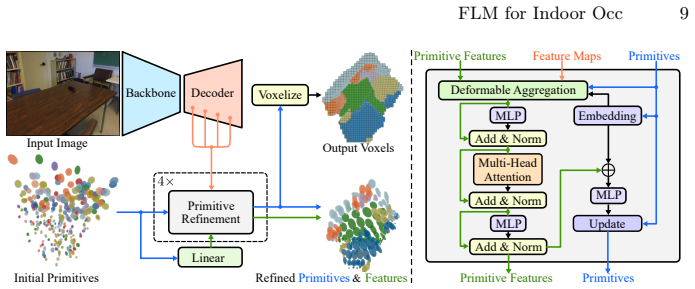
Feed-forward Likelihood Maximization (FLM), which reformulates occupancy prediction as voxel distribution estimation and uses normalized primitive volumes as mixture weights with derived voxelization formulas to enable end-to-end training.
If this is right
- Networks can be trained end-to-end to predict mixture models for occupancy without local-only constraints.
- Primitive count can be reduced dramatically while maintaining or improving accuracy by eliminating empty-space predictions.
- Primitives are able to relocate over long distances during optimization to model the scene effectively.
- The approach provides global supervision that previous voxel classification methods lacked.
Where Pith is reading between the lines
- Similar likelihood maximization could improve efficiency in other sparse 3D representation tasks beyond indoor occupancy.
- Testing FLM with different primitive types like Gaussians or other shapes might yield further gains.
- Applying the framework to dynamic scenes or real-time applications could leverage the speed improvements.
- The reduced primitive count suggests potential for scaling to larger environments without proportional compute increase.
Load-bearing premise
That defining mixture weights as normalized primitive volumes and deriving the corresponding voxelization formulas will allow stable end-to-end training while providing sufficient global supervision to eliminate spurious primitives in empty space.
What would settle it
Running FLM-Occ on Occ-ScanNet and checking if it achieves higher accuracy than prior methods with 32 superquadrics or if the number of predicted primitives in empty regions remains high compared to ground truth.
Figures


read the original abstract
Recent indoor occupancy prediction methods adopt Gaussian primitives as a sparse 3D representation for computational efficiency. However, their training relies on voxel classification, which imposes only local constraints and lacks global supervision on the distribution of the primitives. Therefore, they inevitably predict spurious primitives in empty regions, undermining both representational and computational efficiency. To address this, we propose Feed-forward Likelihood Maximization (FLM), a novel framework that reformulates occupancy prediction as voxel distribution estimation. In FLM, a network is trained to predict a mixture model that maximizes the likelihood over ground-truth occupied voxels in a feed-forward manner. To enable end-to-end training of networks and voxelization of a standard mixture model, we define mixture weights as normalized primitive volumes to implicitly enforce simplex constraints and derive novel voxelization formulas. Based on FLM, our FLM-Occ, a novel method that is capable of relocating randomly initialized primitives over long distances to model a scene. On Occ-ScanNet, FLM-Occ achieves superior accuracy using only 32 superquadrics, 2.7% of the prior SoTA, while running 3.7 times faster.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Feed-forward Likelihood Maximization (FLM) to reformulate indoor occupancy prediction as voxel distribution estimation. A network predicts a mixture of superquadrics whose weights are defined as normalized primitive volumes; novel voxelization formulas are derived to enable end-to-end likelihood maximization over ground-truth occupied voxels. The central claim is that this supplies global supervision sufficient to eliminate spurious primitives in empty space. On Occ-ScanNet the resulting FLM-Occ method reportedly achieves superior accuracy with only 32 superquadrics (2.7 % of prior SoTA) while running 3.7 imes faster.
Significance. If the likelihood objective with the stated volume-normalized weights and voxelization formulas does in fact deliver global supervision that suppresses empty-space primitives, the approach would constitute a concrete improvement in the efficiency of sparse 3D representations for indoor scenes.
major comments (1)
- [Abstract (FLM definition)] Abstract (FLM definition paragraph): the claim that normalized primitive volumes plus the derived voxelization formulas supply global supervision sufficient to eliminate spurious primitives is load-bearing for the efficiency result. Because superquadrics overlap, the sum of individual volumes exceeds the measure of the occupied set; the manuscript must show that the voxelization formulas incorporate an explicit overlap correction (e.g., inclusion-exclusion, soft union, or proper density integration) so that the likelihood penalizes non-zero mass in empty regions. Absent such a correction the objective remains local and the 32-primitive claim is not supported.
minor comments (1)
- [Abstract] Abstract: reported accuracy and runtime figures are given without error bars, statistical significance, or reference to the precise evaluation protocol (e.g., voxel resolution, train/val split).
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. Below we respond point-by-point to the single major comment.
read point-by-point responses
-
Referee: Abstract (FLM definition paragraph): the claim that normalized primitive volumes plus the derived voxelization formulas supply global supervision sufficient to eliminate spurious primitives is load-bearing for the efficiency result. Because superquadrics overlap, the sum of individual volumes exceeds the measure of the occupied set; the manuscript must show that the voxelization formulas incorporate an explicit overlap correction (e.g., inclusion-exclusion, soft union, or proper density integration) so that the likelihood penalizes non-zero mass in empty regions. Absent such a correction the objective remains local and the 32-primitive claim is not supported.
Authors: The volume normalization defines mixture weights that sum exactly to one, yielding a valid probability distribution whose integral over all space equals one. The voxelization formulas compute the probability mass of each voxel under this mixture density (i.e., the integral of the weighted sum of primitive densities over the voxel). Because the total probability mass is constrained to one, any mass placed in empty space necessarily reduces the mass available to occupied voxels; the likelihood objective is therefore global by construction. Overlaps are already accounted for by the additive mixture density; no separate inclusion-exclusion term is required. The derivation appears in Section 3.2. We will add a clarifying sentence in the abstract and in Section 3.2 to make this explicit. revision: partial
Circularity Check
No significant circularity; derivation uses external GT voxels and independent modeling choices
full rationale
The paper's core step defines mixture weights as normalized primitive volumes to enforce simplex constraints and derives voxelization formulas for end-to-end training. This is an explicit modeling ansatz, not a self-definition or fitted quantity renamed as prediction. The likelihood objective is maximized over external ground-truth occupied voxels, providing an independent training signal. No self-citations appear in the provided text, and no step reduces the claimed accuracy or efficiency result to a tautology by construction. The 32-primitive result is presented as an empirical outcome on Occ-ScanNet, not forced by the weight definition alone.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mixture weights defined as normalized primitive volumes implicitly enforce simplex constraints
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Cao, A.Q., De Charette, R.: Monoscene: Monocular 3d semantic scene completion. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3991–4001 (2022)
2022
-
[2]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Charatan,D.,Li,S.L.,Tagliasacchi,A.,Sitzmann,V.:pixelsplat:3dgaussiansplats from image pairs for scalable generalizable 3d reconstruction. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 19457– 19467 (2024)
2024
-
[3]
In: European Conference on Computer Vision
Chen, Y., Xu, H., Zheng, C., Zhuang, B., Pollefeys, M., Geiger, A., Cham, T.J., Cai, J.: Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images. In: European Conference on Computer Vision. pp. 370–386. Springer (2024)
2024
-
[4]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Dai,A.,Chang,A.X.,Savva,M.,Halber,M.,Funkhouser,T.,Nießner,M.:Scannet: Richly-annotated 3d reconstructions of indoor scenes. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 5828–5839 (2017)
2017
-
[5]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Gan, W., Liu, F., Xu, H., Mo, N., Yokoya, N.: Gaussianocc: Fully self-supervised and efficient 3d occupancy estimation with gaussian splatting. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 28980–28990 (2025)
2025
-
[6]
In: 2024 IEEE International Conference on Robotics and Automation (ICRA)
Hou, J., Li, X., Guan, W., Zhang, G., Feng, D., Du, Y., Xue, X., Pu, J.: Fastocc: Accelerating 3d occupancy prediction by fusing the 2d bird’s-eye view and perspec- tive view. In: 2024 IEEE International Conference on Robotics and Automation (ICRA). pp. 16425–16431. IEEE (2024)
2024
-
[7]
In: Proceedings of the IEEE/CVF International Con- ference on Computer Vision
Huang, R., Mikolajczyk, K.: No pose at all: Self-supervised pose-free 3d gaussian splatting from sparse views. In: Proceedings of the IEEE/CVF International Con- ference on Computer Vision. pp. 27947–27957 (2025)
2025
-
[8]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Huang, Y., Thammatadatrakoon, A., Zheng, W., Zhang, Y., Du, D., Lu, J.: Gaussianformer-2: Probabilistic gaussian superposition for efficient 3d occupancy prediction. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 27477–27486 (June 2025)
2025
-
[9]
Huang, Y., Zheng, W., Zhang, B., Zhou, J., Lu, J.: SelfOcc: Self-Supervised Vision-Based 3D Occupancy Prediction . In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 19946–19956. IEEE Computer Society, Los Alamitos, CA, USA (Jun 2024).https : / / doi . org / 10.1109/CVPR52733.2024.01885,https://doi.ieeecomputersociety.org/...
-
[10]
In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition
Huang, Y., Zheng, W., Zhang, Y., Zhou, J., Lu, J.: Tri-perspective view for vision- based 3d semantic occupancy prediction. In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition. pp. 9223–9232 (2023) 16 G. Chen, L. Huanget al
2023
-
[11]
In: Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G
Huang, Y., Zheng, W., Zhang, Y., Zhou, J., Lu, J.: Gaussianformer: Scene as gaus- sians for vision-based 3d semantic occupancy prediction. In: Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G. (eds.) Computer Vision – ECCV 2024. pp. 376–393. Springer Nature Switzerland, Cham (2025)
2024
-
[12]
In: European Conference on Computer Vision
Iwase, S., Liu, K., Guizilini, V., Gaidon, A., Kitani, K., Ambruş, R., Zakharov, S.: Zero-shot multi-object scene completion. In: European Conference on Computer Vision. pp. 96–113. Springer (2024)
2024
-
[13]
In: IEEE/CVF International Conference on Computer Vision (ICCV) (2025)
Jevtić, A., Reich, C., Wimbauer, F., Hahn, O., Rupprecht, C., Roth, S., Cre- mers, D.: Feed-forward SceneDINO for unsupervised semantic scene completion. In: IEEE/CVF International Conference on Computer Vision (ICCV) (2025)
2025
-
[14]
ACM Trans
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. ACM Trans. Graph.42(4), 139–1 (2023)
2023
-
[15]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Li, H., Hou, Y., Xing, X., Ma, Y., Sun, X., Zhang, Y.: Occmamba: Semantic occu- pancy prediction with state space models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 11949–11959 (2025)
2025
-
[16]
In: 2025 IEEE International Conference on Robotics and Automation (ICRA)
Li, J., Lu, M., Liu, J., Wang, H., Gu, C., Zheng, W., Du, L., Zhang, S.: Sliceocc: Indoor 3d semantic occupancy prediction with vertical slice representation. In: 2025 IEEE International Conference on Robotics and Automation (ICRA). pp. 15762–15768. IEEE (2025)
2025
-
[17]
IEEE Robotics and Automation Letters10(11), 11690–11697 (2025)
Li, X., Zheng, Y., Li, P., Chen, Y., Zhang, Y.Q., Ding, W.: Enhancing indoor occupancy prediction via sparse query-based multi-level consistent knowledge dis- tillation. IEEE Robotics and Automation Letters10(11), 11690–11697 (2025). https://doi.org/10.1109/LRA.2025.3615532
-
[18]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2023)
Li, Y., Yu, Z., Choy, C., Xiao, C., Alvarez, J.M., Fidler, S., Feng, C., Anandkumar, A.: Voxformer: Sparse voxel transformer for camera-based 3d semantic scene com- pletion. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2023)
2023
-
[19]
Lin,X.,Lin,T.,Pei,Z.,Huang,L.,Su,Z.:Sparse4d:Multi-view3dobjectdetection with sparse spatial-temporal fusion (2022)
2022
-
[20]
In: International Conference on Learning Representations (2019)
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. In: International Conference on Learning Representations (2019)
2019
-
[21]
Advances in Neural Information Processing Systems37, 79618–79641 (2024)
Lu, Y., Zhu, X., Wang, T., Ma, Y.: Octreeocc: Efficient and multi-granularity occu- pancy prediction using octree queries. Advances in Neural Information Processing Systems37, 79618–79641 (2024)
2024
-
[22]
In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition
Matsuki, H., Murai, R., Kelly, P.H., Davison, A.J.: Gaussian splatting slam. In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition. pp. 18039–18048 (2024)
2024
-
[23]
Commu- nications of the ACM65(1), 99–106 (2021)
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. Commu- nications of the ACM65(1), 99–106 (2021)
2021
-
[24]
Journal of mathematical Psychology47(1), 90–100 (2003)
Myung, I.J.: Tutorial on maximum likelihood estimation. Journal of mathematical Psychology47(1), 90–100 (2003)
2003
-
[25]
National Institute of Standards and Technology: Gamma function (2025),https: //dlmf.nist.gov/5, nIST Digital Library of Mathematical Functions, Release 1.1.10
2025
-
[26]
Oquab, M., Darcet, T., Moutakanni, T., Vo, H.V., Szafraniec, M., Khalidov, V., Fernandez,P.,Haziza,D.,Massa,F.,El-Nouby,A.,Howes,R.,Huang,P.Y.,Xu,H., Sharma, V., Li, S.W., Galuba, W., Rabbat, M., Assran, M., Ballas, N., Synnaeve, G., Misra, I., Jegou, H., Mairal, J., Labatut, P., Joulin, A., Bojanowski, P.: Dinov2: Learning robust visual features without ...
2023
-
[27]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Qian, R., Cao, H., Deng, T., Yuan, S., Xie, L.: Splatssc: Decoupled depth-guided gaussian splatting for semantic scene completion. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 40, pp. 8520–8528 (2026)
2026
-
[28]
In: European conference on computer vision
Silberman, N., Hoiem, D., Kohli, P., Fergus, R.: Indoor segmentation and support inference from rgbd images. In: European conference on computer vision. pp. 746–
-
[29]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Song, S., Yu, F., Zeng, A., Chang, A.X., Savva, M., Funkhouser, T.: Semantic scene completion from a single depth image. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 1746–1754 (2017)
2017
-
[30]
Neurocomputing568, 127063 (2024)
Su, J., Ahmed, M., Lu, Y., Pan, S., Bo, W., Liu, Y.: Roformer: Enhanced trans- former with rotary position embedding. Neurocomputing568, 127063 (2024)
2024
-
[31]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Szymanowicz, S., Rupprecht, C., Vedaldi, A.: Splatter image: Ultra-fast single- view 3d reconstruction. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10208–10217 (2024)
2024
-
[32]
In: Interna- tional conference on machine learning
Tan, M., Le, Q.: Efficientnetv2: Smaller models and faster training. In: Interna- tional conference on machine learning. pp. 10096–10106. PMLR (2021)
2021
-
[33]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
Tang, P., Wang, Z., Wang, G., Zheng, J., Ren, X., Feng, B., Ma, C.: Sparseocc: Rethinking sparse latent representation for vision-based semantic occupancy pre- diction. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
2024
-
[34]
Advances in neural information pro- cessing systems30(2017)
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, Ł., Polosukhin, I.: Attention is all you need. Advances in neural information pro- cessing systems30(2017)
2017
-
[35]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Wang, H., Wei, X., Zhang, X., Li, J., Bai, C., Li, Y., Lu, M., Zheng, W., Zhang, S.: Embodiedocc++: Boosting embodied 3d occupancy prediction with plane regular- ization and uncertainty sampler. In: Proceedings of the 33rd ACM International Conference on Multimedia. pp. 925–934 (2025)
2025
-
[36]
In: Advances in Neural Information Processing Systems (2024)
Wang, J., Liu, Z., Meng, Q., Yan, L., Wang, K., Yang, J., Liu, W., Hou, Q., Cheng, M.: Opus: occupancy prediction using a sparse set. In: Advances in Neural Information Processing Systems (2024)
2024
-
[37]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Wang, X., Zhu, Z., Xu, W., Zhang, Y., Wei, Y., Chi, X., Ye, Y., Du, D., Lu, J., Wang, X.: Openoccupancy: A large scale benchmark for surrounding semantic occupancy perception. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 17850–17859 (2023)
2023
-
[38]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wimbauer, F., Yang, N., Rupprecht, C., Cremers, D.: Behind the scenes: Density fields for single view reconstruction. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9076–9086 (2023)
2023
-
[39]
In: Proceed- ings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Wu, Y., Zheng, W., Zuo, S., Huang, Y., Zhou, J., Lu, J.: Embodiedocc: Embodied 3d occupancy prediction for vision-based online scene understanding. In: Proceed- ings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 26360–26370 (October 2025)
2025
-
[40]
Advances in Neural Information Processing Systems37, 21875–21911 (2024)
Yang, L., Kang, B., Huang, Z., Zhao, Z., Xu, X., Feng, J., Zhao, H.: Depth anything v2. Advances in Neural Information Processing Systems37, 21875–21911 (2024)
2024
-
[41]
In: 2023 IEEE/CVF International Conference on Computer Vision (ICCV)
Yao, J., Li, C., Sun, K., Cai, Y., Li, H., Ouyang, W., Li, H.: Ndc-scene: Boost monocular 3d semantic scene completion in normalized device coordinates space. In: 2023 IEEE/CVF International Conference on Computer Vision (ICCV). pp. 9421–9431. IEEE Computer Society (2023)
2023
-
[42]
Quantum optics with giant atoms—the first five years
Yu, H., Wang, Y., Chen, Y., Zhang, Z.: Monocular occupancy prediction for scal- able indoor scenes. In: Computer Vision – ECCV 2024: 18th European Conference, Milan, Italy, September 29–October 4, 2024, Proceedings, Part XXX. p. 38–54. 18 G. Chen, L. Huanget al. Springer-Verlag, Berlin, Heidelberg (2024).https://doi.org/10.1007/978- 3- 031-73404-5_3,https...
-
[43]
Yu, Z., Shu, C., Deng, J., Lu, K., Liu, Z., Yu, J., Yang, D., Li, H., Chen, Y.: Flashocc: Fast and memory-efficient occupancy prediction via channel-to-height plugin (2023)
2023
-
[44]
Advances in Neural Information Processing Systems37, 81489–81509 (2024)
Zhang, G., Fan, L., He, C., Lei, Z., Zhang, Z., Zhang, L.: Voxel mamba: Group-free state space models for point cloud based 3d object detection. Advances in Neural Information Processing Systems37, 81489–81509 (2024)
2024
-
[45]
In: European Conference on Computer Vision
Zhang, K., Bi, S., Tan, H., Xiangli, Y., Zhao, N., Sunkavalli, K., Xu, Z.: Gs-lrm: Large reconstruction model for 3d gaussian splatting. In: European Conference on Computer Vision. pp. 1–19. Springer (2024)
2024
-
[46]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2025), to appear
Zhu, Z., Wang, S., Xie, J., Liu, J.J., Wang, J., Yang, J.: Voxelsplat: Dynamic gaus- sian splatting as an effective loss for occupancy and flow prediction. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2025), to appear
2025
-
[47]
In: Advances in Neural Information Processing Systems (2025)
Zuo, S., Zheng, W., Han, X., Yang, L., Pan, Y., Lu, J.: Quadricformer: Scene as superquadrics for 3d semantic occupancy prediction. In: Advances in Neural Information Processing Systems (2025)
2025
-
[48]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Zuo, S., Zheng, W., Huang, Y., Zhou, J., Lu, J.: Gaussianworld: Gaussian world model for streaming 3d occupancy prediction. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 6772–6781 (2025) FLM for Indoor Occ 19 Supplementary Material A Discussion A.1 Limitations Bilinear Complexity of the FLM Loss. The computational cost of ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.