MF-UAVPose6D: A Model-Free Monocular 6-DoF Pose Estimation Framework for Fixed-Wing UAVs
Pith reviewed 2026-06-30 06:58 UTC · model grok-4.3
The pith
MF-UAVPose6D estimates 6-DoF poses of fixed-wing UAVs from single RGB images without CAD models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
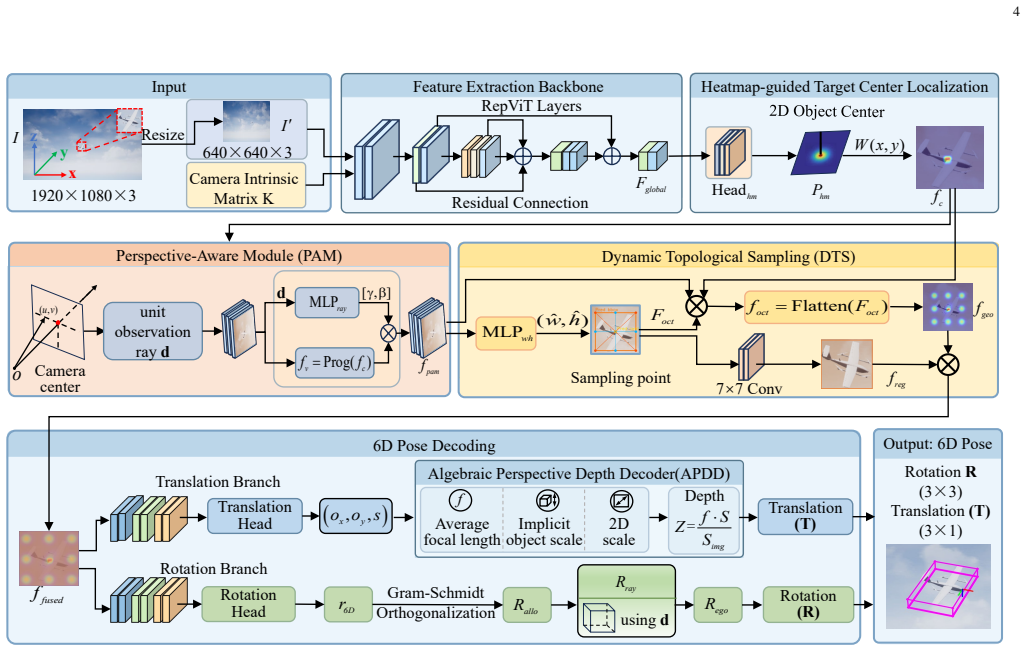
MF-UAVPose6D takes a single RGB image and camera intrinsics as input, applies heatmap-guided center localization to obtain a stable target anchor, uses a Perspective-Aware Module to model observation-ray priors, employs Dynamic Topological Sampling to complement weak structural cues, and adopts decoupled translation-rotation pose decoding to estimate the 6-DoF pose, achieving accurate and efficient results without CAD models.
What carries the argument
The MF-UAVPose6D framework consisting of heatmap-guided center localization, Perspective-Aware Module (PAM), Dynamic Topological Sampling (DTS), and decoupled translation-rotation pose decoding.
If this is right
- Supports pose estimation for UAVs that lack available CAD models or keypoint priors.
- Demonstrates robustness in long-range rotation estimation and depth recovery.
- Enables joint pose evaluation using only monocular RGB input.
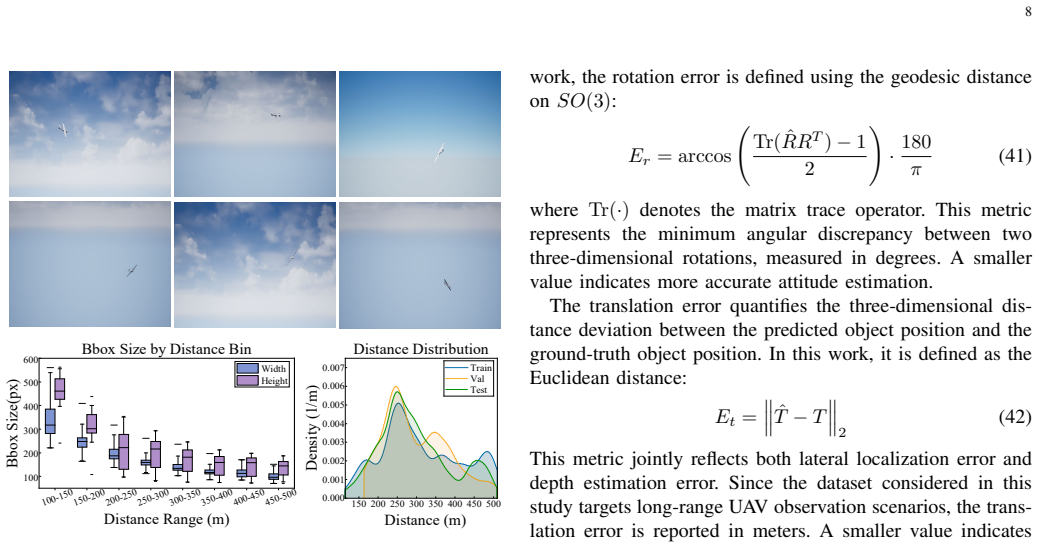
- Relies on the FW-UAV6DPose synthetic dataset for training across diverse conditions.
Where Pith is reading between the lines
- The method could be adapted for other types of aircraft by modifying the topological sampling to match different body structures.
- Combining this with multi-frame tracking might enhance performance in dynamic airspace scenarios.
- Validation on real captured images rather than synthetic ones would strengthen the claims for practical deployment.
Load-bearing premise
The described components and the synthetic dataset produce reliable results on real images even though no quantitative metrics or real-image validation details are provided.
What would settle it
Running the method on a set of real-world images of fixed-wing UAVs with known ground-truth poses and measuring the pose estimation errors would test the accuracy and robustness claims.
Figures

read the original abstract
For uncrewed aerial vehicles (UAVs), estimating six-degree-of-freedom (6-DoF) poses is essential for airspace situational awareness, target tracking, and counter-UAV operations. However, non-cooperative targets usually lack computer-aided design (CAD) models and keypoint priors, making existing model-based or keypoint-matching methods difficult to apply reliably. To address these challenges, this paper proposes MF-UAVPose6D, a model-free monocular 6-DoF pose estimation framework for fixed-wing UAVs. During inference, the method takes only a single red-green-blue (RGB) image and camera intrinsics as input. It first obtains a stable target anchor through heatmap-guided center localization, introduces a Perspective-Aware Module (PAM) to model observation-ray priors, exploits Dynamic Topological Sampling (DTS) to complement weak structural cues from the wings, fuselage, and tail, and adopts a decoupled translation-rotation pose decoding mechanism to estimate the 6-DoF pose. In addition, we construct the FW-UAV6DPose synthetic dataset, which covers fixed-wing UAV observations across diverse distances, viewpoints, and poses. Experimental results show that MF-UAVPose6D achieves accurate and efficient monocular 6-DoF pose estimation without requiring CAD models, and demonstrates strong robustness in long-range rotation estimation, depth recovery, and joint pose evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
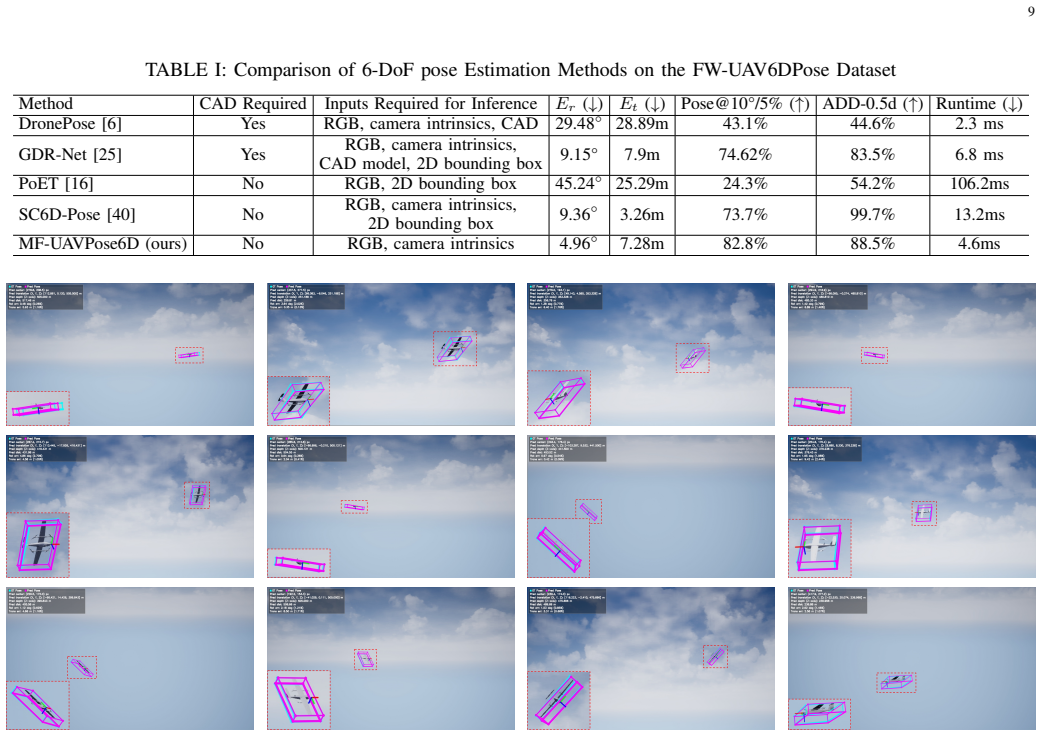
Summary. The paper proposes MF-UAVPose6D, a model-free monocular 6-DoF pose estimation framework for fixed-wing UAVs. It takes a single RGB image and camera intrinsics as input, using heatmap-guided center localization, a Perspective-Aware Module (PAM) to model observation-ray priors, Dynamic Topological Sampling (DTS) to complement structural cues, and decoupled translation-rotation decoding. The work also introduces the synthetic FW-UAV6DPose dataset spanning diverse distances, viewpoints, and poses, and claims that experimental results demonstrate accurate, efficient performance and strong robustness in long-range rotation estimation, depth recovery, and joint pose evaluation without requiring CAD models.
Significance. If the performance claims hold with supporting quantitative evidence, the model-free approach would address a practical gap in estimating poses of non-cooperative fixed-wing UAVs, with potential utility for airspace situational awareness, target tracking, and counter-UAV applications.
major comments (2)
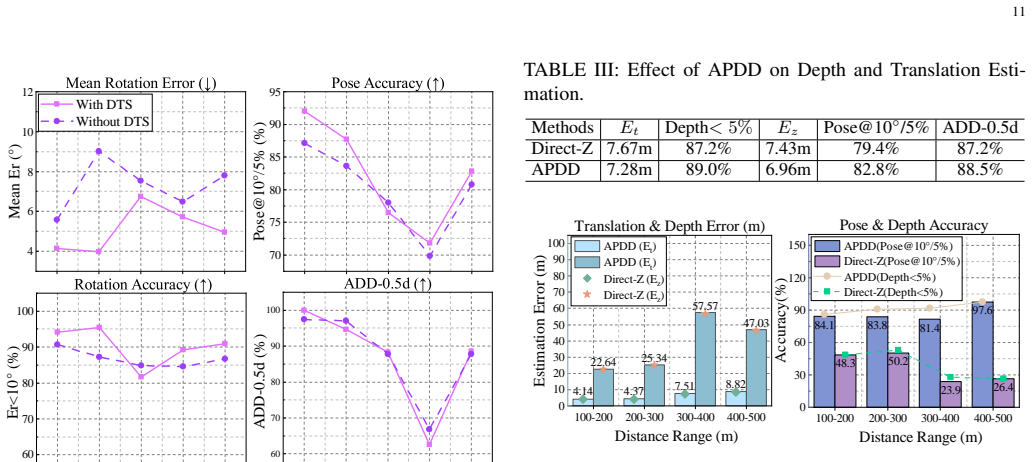
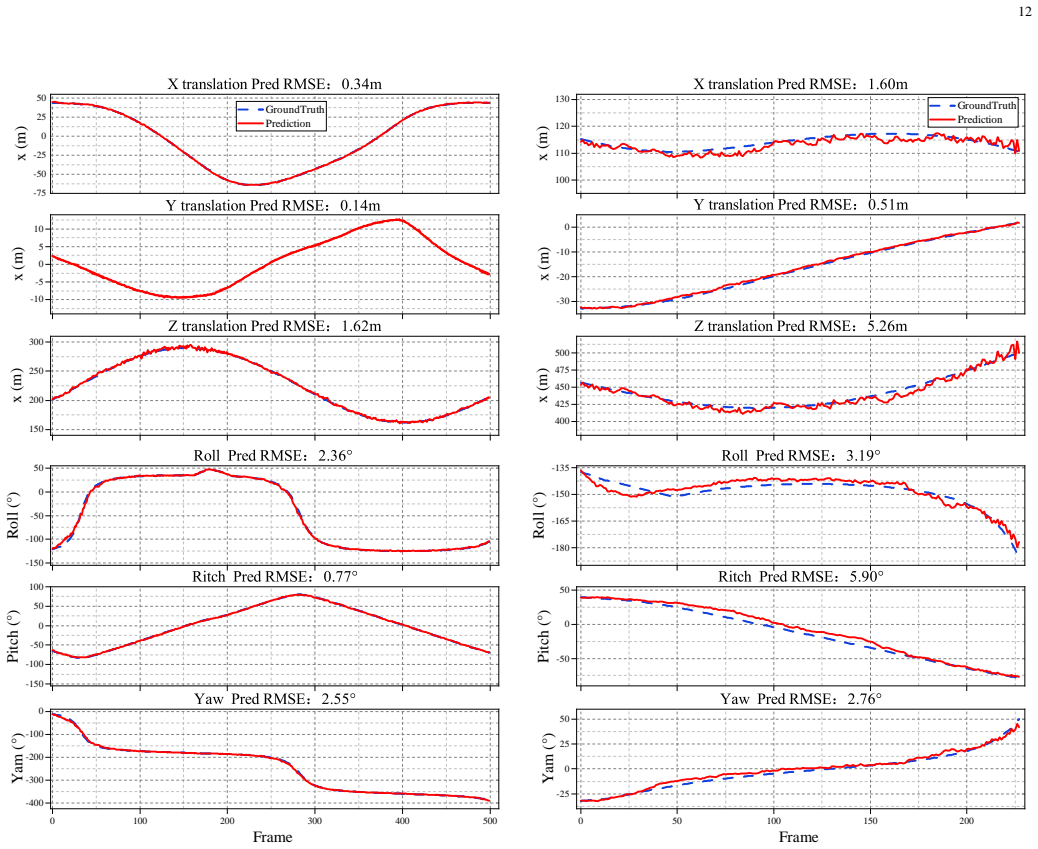
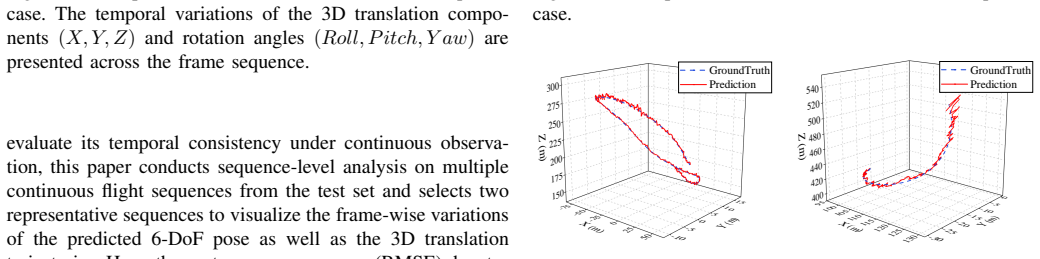
- [Abstract] Abstract: The central claim that 'experimental results show that MF-UAVPose6D achieves accurate and efficient monocular 6-DoF pose estimation' and 'demonstrates strong robustness' is unsupported, as the manuscript provides no quantitative metrics (e.g., rotation/translation errors, ADD scores, success rates), error bars, baseline comparisons, ablation studies, or dataset statistics.
- [Dataset and Experiments] Dataset and Experiments sections: The FW-UAV6DPose dataset is described as synthetic only; the manuscript reports no real-image validation or analysis of the sim-to-real gap, which is required to substantiate claims of robustness for real-world UAV applications.
minor comments (1)
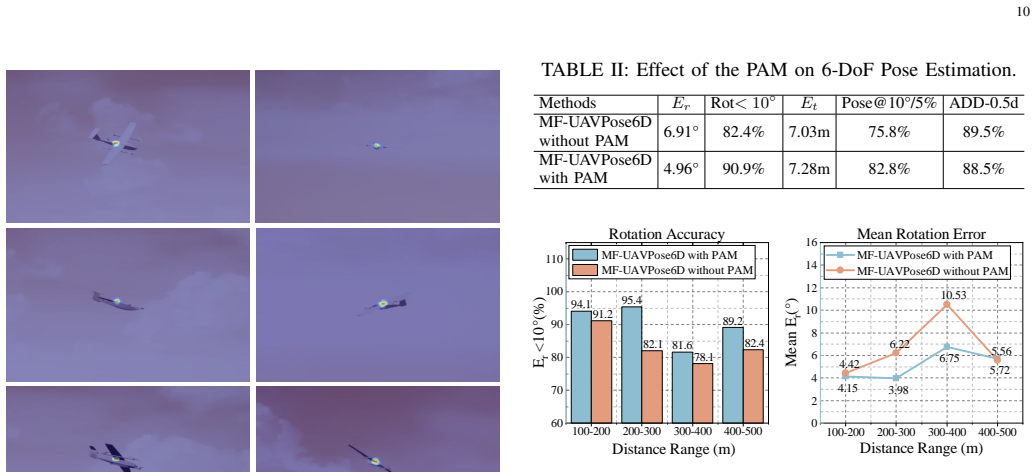
- [Methods] Methods section: The descriptions of PAM, DTS, and the decoupled decoding mechanism would benefit from explicit equations or algorithmic pseudocode to clarify implementation details.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive feedback. We address each major comment below and outline the planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'experimental results show that MF-UAVPose6D achieves accurate and efficient monocular 6-DoF pose estimation' and 'demonstrates strong robustness' is unsupported, as the manuscript provides no quantitative metrics (e.g., rotation/translation errors, ADD scores, success rates), error bars, baseline comparisons, ablation studies, or dataset statistics.
Authors: We agree that the abstract's claims require explicit quantitative backing. The current abstract makes general statements without citing specific numbers. We will revise the abstract to include key quantitative results from the Experiments section, such as rotation and translation errors, ADD scores where applicable, success rates, and references to baseline comparisons, ablation studies, and dataset statistics. Error bars will also be incorporated in the relevant figures and tables during revision. revision: yes
-
Referee: [Dataset and Experiments] Dataset and Experiments sections: The FW-UAV6DPose dataset is described as synthetic only; the manuscript reports no real-image validation or analysis of the sim-to-real gap, which is required to substantiate claims of robustness for real-world UAV applications.
Authors: We acknowledge that FW-UAV6DPose is a synthetic dataset constructed to enable controlled evaluation across varied distances, viewpoints, and poses. The manuscript does not include real-image experiments. We will add a dedicated discussion subsection analyzing the sim-to-real gap, including limitations of synthetic data for real-world robustness claims and potential mitigation strategies such as domain adaptation. This will temper the robustness claims accordingly while highlighting the value of the synthetic benchmark for initial method validation. revision: partial
- Real-image validation experiments on actual UAV imagery with ground-truth 6-DoF poses, as no such real dataset was collected or available for this study.
Circularity Check
No derivation chain or equations present; framework is descriptive only
full rationale
The provided abstract and text describe a model-free framework with components (heatmap-guided localization, PAM, DTS, decoupled decoding) and a synthetic dataset, claiming experimental results without any equations, mathematical derivations, fitted parameters renamed as predictions, or self-citations. No load-bearing steps reduce to inputs by construction, as there is no derivation chain to inspect. This is the common case of a methods paper without formal proofs or predictions that could exhibit circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
An oblique-robust absolute visual localization method for GPS-denied UA V with satellite imagery,
Y . Chen and J. Jiang, “An oblique-robust absolute visual localization method for GPS-denied UA V with satellite imagery,”IEEE Transactions on Geoscience and Remote Sensing, vol. 62, pp. 1–13, 2023
2023
-
[2]
Vision-based pose estimation of fixed-wing aircraft using You Only Look Once and Perspective-n- Points,
S. Kim, J. Kim, J. Park, and D. Lee, “Vision-based pose estimation of fixed-wing aircraft using You Only Look Once and Perspective-n- Points,”Journal of Aerospace Information Systems, vol. 18, no. 9, pp. 659–664, 2021
2021
-
[3]
UA V navigation with monocular visual inertial odometry under GNSS-denied environment,
H. Luo, G. Li, D. Zou, K. Li, X. Li, and Z. Yang, “UA V navigation with monocular visual inertial odometry under GNSS-denied environment,” IEEE Transactions on Geoscience and Remote Sensing, vol. 61, pp. 1– 15, 2023
2023
-
[4]
Deep learning for unambigu- ous pose estimation of a non-cooperative fixed-wing UA V,
L. Herrera, J. J. Kim, and B. N. Agrawal, “Deep learning for unambigu- ous pose estimation of a non-cooperative fixed-wing UA V,”Machine Vision and Applications, vol. 36, no. 1, 2025, Art. no. 5
2025
-
[5]
DroneKey: Drone 3D pose estimation in image sequences using gated key-representation and pose-adaptive learning,
S.-B. Hwang and Y .-J. Cho, “DroneKey: Drone 3D pose estimation in image sequences using gated key-representation and pose-adaptive learning,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2025, pp. 708–715
2025
-
[6]
DronePose: Photorealistic UA V-assistant dataset synthesis for 3D pose estimation via a smooth silhouette loss,
G. Albanis, N. Zioulis, A. Dimou, D. Zarpalas, and P. Daras, “DronePose: Photorealistic UA V-assistant dataset synthesis for 3D pose estimation via a smooth silhouette loss,” inComputer Vision – ECCV 2020 Workshops, ser. Lecture Notes in Computer Science, vol. 12536, 2020, pp. 703–719
2020
-
[7]
Enhanced real-time 6D pose estimation for automatic recovery of in-flight UA Vs using distance-aware keypoint heatmaps,
M. Jeong and A. J. Choi, “Enhanced real-time 6D pose estimation for automatic recovery of in-flight UA Vs using distance-aware keypoint heatmaps,”Scientific Reports, vol. 16, 2026, Art. no. 1909
2026
-
[8]
Fixed-wing UA V pose estimation using a self- organizing map and deep learning,
N. Pessanha Santos, “Fixed-wing UA V pose estimation using a self- organizing map and deep learning,”Robotics, vol. 13, no. 8, 2024, Art. no. 114
2024
-
[9]
PVNet: Pixel- wise voting network for 6DoF pose estimation,
S. Peng, Y . Liu, Q. Huang, X. Zhou, and H. Bao, “PVNet: Pixel- wise voting network for 6DoF pose estimation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2019
2019
-
[10]
Hybridpose: 6D object pose esti- mation under hybrid representations,
C. Song, J. Song, and Q. Huang, “Hybridpose: 6D object pose esti- mation under hybrid representations,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020, pp. 431–440
2020
-
[11]
Normalized object coordinate space for category-level 6D object pose and size estimation,
H. Wang, S. Sridhar, J. Huang, J. Valentin, S. Song, and L. J. Guibas, “Normalized object coordinate space for category-level 6D object pose and size estimation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2019, pp. 2642– 2651
2019
-
[12]
VI-Net: Boosting category-level 6D object pose estimation via learning decoupled rotations on the spher- ical representations,
J. Lin, Z. Wei, Y . Zhang, and K. Jia, “VI-Net: Boosting category-level 6D object pose estimation via learning decoupled rotations on the spher- ical representations,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Oct. 2023, pp. 14 001–14 011
2023
-
[13]
Self-supervised category-level 6D object pose estimation with deep implicit shape representation,
W. Peng, J. Yan, H. Wen, and Y . Sun, “Self-supervised category-level 6D object pose estimation with deep implicit shape representation,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 36, no. 2, 2022, pp. 2082–2090
2022
-
[14]
Gen6D: Generalizable model-free 6-DoF object pose estimation from RGB images,
Y . Liu, Y . Wen, S. Peng, C. Lin, X. Long, T. Komura, and W. Wang, “Gen6D: Generalizable model-free 6-DoF object pose estimation from RGB images,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 298–315
2022
-
[15]
Onepose++: Keypoint-free one-shot object pose estimation without CAD models,
X. He, J. Sun, Y . Wang, D. Huang, H. Bao, and X. Zhou, “Onepose++: Keypoint-free one-shot object pose estimation without CAD models,” Advances in Neural Information Processing Systems, vol. 35, pp. 35 103–35 115, 2022
2022
-
[16]
PoET: Pose estimation transformer for single-view, multi-object 6D pose estimation,
T. G. Jantos, M. A. Hamdad, W. Granig, S. Weiss, and J. Steinbrener, “PoET: Pose estimation transformer for single-view, multi-object 6D pose estimation,” inProceedings of The 6th Conference on Robot Learning, vol. 205, 2023, pp. 1060–1070
2023
-
[17]
MegaPose: 6D pose estimation of novel objects via render & compare,
Y . Labb ´e, L. Manuelli, A. Mousavian, S. Tyree, S. Birchfield, J. Trem- blay, J. Carpentier, M. Aubry, D. Fox, and J. Sivic, “MegaPose: 6D pose estimation of novel objects via render & compare,”arXiv:2212.06870, 2022
-
[18]
FoundationPose: Unified 6D pose estimation and tracking of novel objects,
B. Wen, W. Yang, J. Kautz, and S. Birchfield, “FoundationPose: Unified 6D pose estimation and tracking of novel objects,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, June 2024, pp. 17 868–17 879
2024
-
[19]
SAM-6D: Segment anything model meets zero-shot 6D object pose estimation,
J. Lin, L. Liu, D. Lu, and K. Jia, “SAM-6D: Segment anything model meets zero-shot 6D object pose estimation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2024, pp. 27 906–27 916
2024
-
[20]
Any6D: Model-free 6D pose estimation of novel objects,
T. Lee, B. Wen, M. Kang, G. Kang, I. S. Kweon, and K.-J. Yoon, “Any6D: Model-free 6D pose estimation of novel objects,” inPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2025, pp. 11 633–11 643
2025
-
[21]
GL-DT: Multi-UA V detec- tion and tracking with global–local integration,
J. Liu, L. Plotegher, E. Roura, and S. He, “GL-DT: Multi-UA V detec- tion and tracking with global–local integration,”IEEE Transactions on Geoscience and Remote Sensing, vol. 64, pp. 1–13, 2026
2026
-
[22]
A high accuracy and large-scale detection for fixed-wing UA V autonomous ground landing with gnss- denied,
B. Fang, Z. Zhong, and X. Jiang, “A high accuracy and large-scale detection for fixed-wing UA V autonomous ground landing with gnss- denied,”IEEE Access, vol. 13, pp. 45 898–45 911, 2025
2025
-
[23]
MMFW-UA V dataset: Multi-sensor and multi-view fixed-wing UA V dataset for air-to-air vision tasks,
Y . Liu, Z. Sun, L. Xi, L. Zhang, W. Dong, C. Chen, M. Lu, H. Fu, and F. Deng, “MMFW-UA V dataset: Multi-sensor and multi-view fixed-wing UA V dataset for air-to-air vision tasks,”Scientific Data, vol. 12, no. 1, 2025, Art. no. 185
2025
-
[24]
UEMM-Air: Make unmanned aerial vehicles perform more multi-modal tasks,
L. Yao, F. Liu, S. Xu, C. Zhang, X. Ma, J. Jiang, Z. Wang, S. Di, and J. Zhou, “UEMM-Air: Make unmanned aerial vehicles perform more multi-modal tasks,”arXiv:2406.06230, 2024
-
[25]
GDR-Net: Geometry- guided direct regression network for monocular 6D object pose estima- tion,
G. Wang, F. Manhardt, F. Tombari, and X. Ji, “GDR-Net: Geometry- guided direct regression network for monocular 6D object pose estima- tion,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, June 2021, pp. 16 611–16 621
2021
-
[26]
KeyPose: Category-level 6D object pose estimation with self-adaptive keypoints,
S. Yu, D.-H. Zhai, and Y . Xia, “KeyPose: Category-level 6D object pose estimation with self-adaptive keypoints,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 9, 2025, pp. 9653– 9661
2025
-
[27]
One2Any: One-reference 6D pose estimation for any object,
M. Liu, S. Li, A. Chhatkuli, P. Truong, L. Van Gool, and F. Tombari, “One2Any: One-reference 6D pose estimation for any object,” inPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2025, pp. 6457–6467
2025
-
[28]
Zs6d: Zero-shot 6D object pose estimation using vision 14 transformers,
P. Ausserlechner, D. Haberger, S. Thalhammer, J.-B. Weibel, and M. Vincze, “Zs6d: Zero-shot 6D object pose estimation using vision 14 transformers,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 463–469
2024
-
[29]
Learning-type anchors-driven pose estimation for the autolanding fixed-wing UA Vs,
D. Tang, L. Shen, X. Xiang, H. Zhou, and T. Hu, “Learning-type anchors-driven pose estimation for the autolanding fixed-wing UA Vs,” TechRxiv preprint, Nov. 2021
2021
-
[30]
A robust and real- time visual-inertial pose estimation for fixed-wing aircraft landing,
G. Yu, L. Zhang, C. Zou, Y . Liu, and Y . Cheng, “A robust and real- time visual-inertial pose estimation for fixed-wing aircraft landing,” inProceedings of 32nd Congress of the International Council of the Aeronautical Sciences (ICAS), Sep 2021, pp. 4398–4409
2021
-
[31]
Real-time vision-inertial landing navigation for fixed-wing aircraft with CFC-CKF,
G. Yu, L. Zhang, S. Shen, and Z. Zhai, “Real-time vision-inertial landing navigation for fixed-wing aircraft with CFC-CKF,”Complex & Intelligent Systems, vol. 10, no. 6, pp. 8079–8093, 2024
2024
-
[32]
N-cameras-enabled joint pose estimation for auto-landing fixed-wing UA Vs,
D. Tang, L. Shen, X. Xiang, H. Zhou, and J. Lai, “N-cameras-enabled joint pose estimation for auto-landing fixed-wing UA Vs,”Drones, vol. 7, no. 12, 2023, Art. no. 693
2023
-
[33]
Pose estimation for straight wing aircraft based on consistent line clustering and planes intersection,
X. Teng, Q. Yu, J. Luo, X. Zhang, and G. Wang, “Pose estimation for straight wing aircraft based on consistent line clustering and planes intersection,”Sensors, vol. 19, no. 2, 2019, Art. no. 342
2019
-
[34]
Aircraft pose esti- mation based on geometry structure features and line correspondences,
X. Teng, Q. Yu, J. Luo, G. Wang, and X. Zhang, “Aircraft pose esti- mation based on geometry structure features and line correspondences,” Sensors, vol. 19, no. 9, 2019, Art. no. 2165
2019
-
[35]
Research on aircraft pose estimation based on neural network feature line extraction,
C. Chen, D. Tang, H. Yu, A. Yang, and X. Pan, “Research on aircraft pose estimation based on neural network feature line extraction,”High Power Laser and Particle Beams, vol. 36, no. 6, pp. 161–169, 2024
2024
-
[36]
GPS-denied relative motion estimation for fixed-wing UA V using the variational pose esti- mator,
M. Izadi, A. K. Sanyal, R. Beard, and H. Bai, “GPS-denied relative motion estimation for fixed-wing UA V using the variational pose esti- mator,” inProc. 54th IEEE Conf. Decision and Control (CDC), Dec. 2015, pp. 2152–2157
2015
-
[37]
Relative navigation of fixed- wing aircraft in GPS-denied environments,
G. Ellingson, K. Brink, and T. McLain, “Relative navigation of fixed- wing aircraft in GPS-denied environments,”Navigation, vol. 67, no. 2, pp. 255–273, 2020
2020
-
[38]
3D bounding box estimation using deep learning and geometry,
A. Mousavian, D. Anguelov, J. Flynn, and J. Kosecka, “3D bounding box estimation using deep learning and geometry,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017, pp. 5632–5640
2017
-
[39]
An intriguing failing of convolutional neural networks and the CoordConv solution,
R. Liu, J. Lehman, P. Molino, F. Petroski Such, E. Frank, A. Sergeev, and J. Yosinski, “An intriguing failing of convolutional neural networks and the CoordConv solution,” inAdvances in Neural Information Processing Systems, vol. 31, 2018
2018
-
[40]
SC6D: Symmetry-agnostic and correspondence-free 6D object pose estimation,
D. Cai, J. Heikkil ¨a, and E. Rahtu, “SC6D: Symmetry-agnostic and correspondence-free 6D object pose estimation,” in2022 International Conference on 3D Vision (3DV), Sep. 2022, pp. 536–546
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.