OCELOT: Inference-Leakage Budgets for Privacy-Preserving LLM Agents
Pith reviewed 2026-06-27 09:10 UTC · model grok-4.3
The pith
OCELOT budgets how much an adversary's belief about a secret may improve across an LLM agent trajectory by charging certified min-entropy costs to each release.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
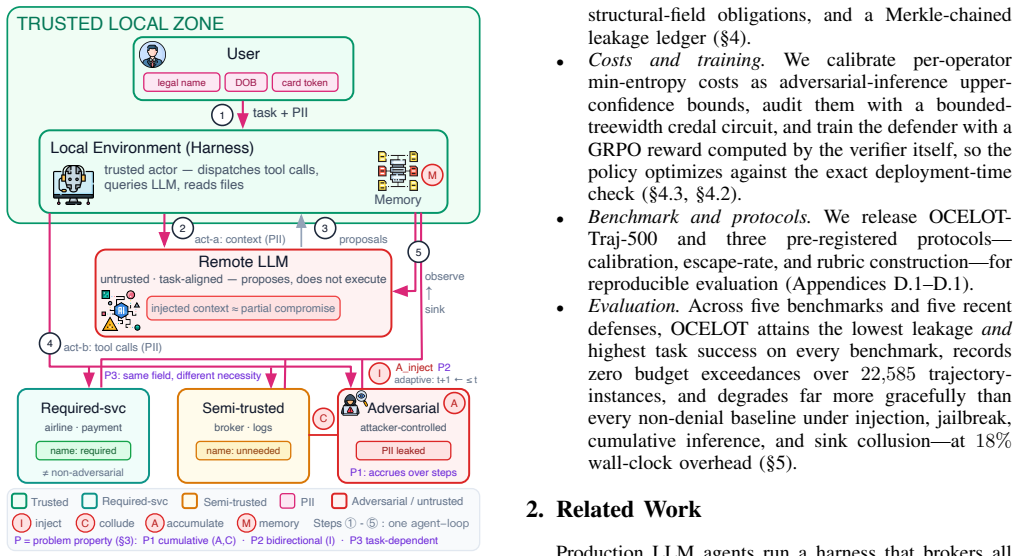
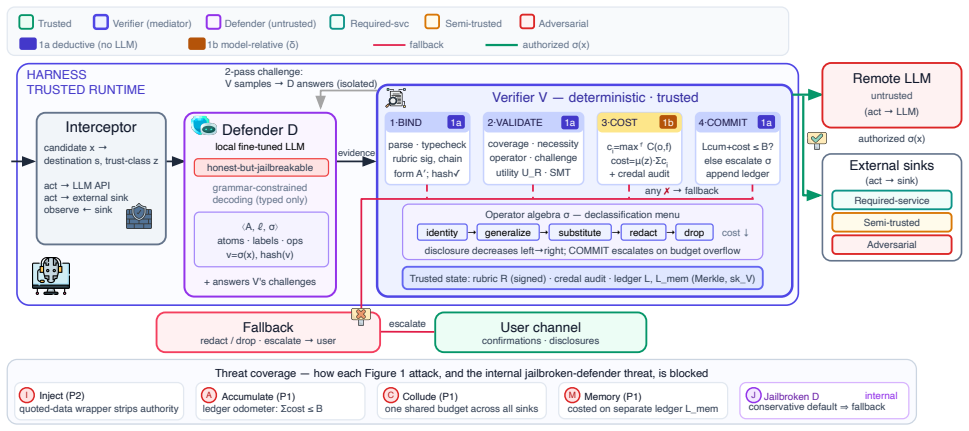
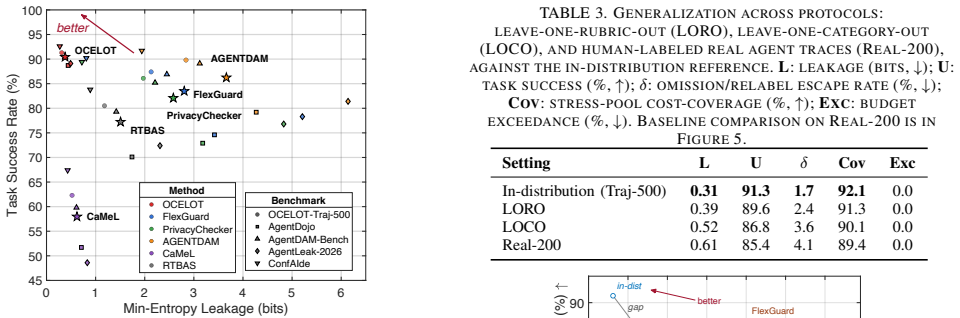
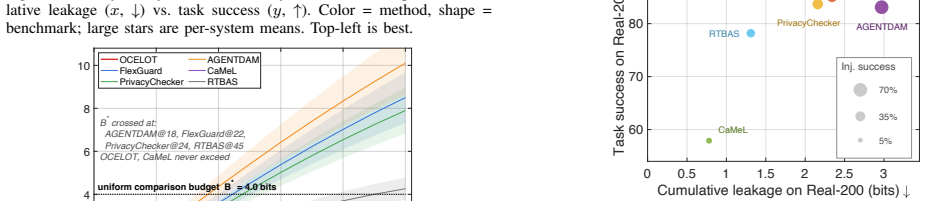
OCELOT recasts agent privacy as posterior-risk control and presents Witness-Verified Declassification: an untrusted locally fine-tuned defender model inspects each candidate release and emits structured evidence of labeled atoms and proposed declassification operators; a deterministic verifier audits the evidence, charges a certified min-entropy cost for the chosen variant, and authorizes the release only if it fits the remaining budget. Across diverse agent benchmarks the system produces significantly lower leakage at higher task utility than recent defenses while resisting adaptive injection, jailbreak, cumulative inference, and sink collusion attacks and incurring only modest overhead.
What carries the argument
Witness-Verified Declassification, which separates judgment from trust by letting an untrusted defender emit structured evidence that a deterministic verifier audits and charges against a tamper-evident min-entropy budget ledger.
If this is right
- OCELOT attains significantly lower leakage at higher task utility than recent defenses across diverse agent benchmarks.
- The system resists adaptive injection, jailbreak, cumulative inference, and sink collusion attacks.
- Overhead remains modest while the tamper-evident ledger records every authorized release.
- The same release can be declassified for one sink but withheld from another according to the trust-weighted budget.
Where Pith is reading between the lines
- The separation of an untrusted fine-tuned model from a deterministic verifier could let users run privacy logic locally without exposing the full model to external auditors.
- Recording min-entropy costs on a ledger opens the possibility of post-hoc audits of entire agent trajectories by third parties who never see the raw data.
- If the structured evidence format can be standardized, the same verifier could be reused across different defender models or even non-LLM agent frameworks.
Load-bearing premise
The deterministic verifier can correctly and completely audit the structured evidence emitted by the defender model and assign accurate min-entropy costs without missing attacks or over-approximating safety.
What would settle it
An experiment in which an adversary forces the release of information that allows belief about a protected secret to improve by more than the remaining budget, yet the verifier still authorizes the release.
Figures

read the original abstract
Large language model (LLM) agents increasingly act on a user's behalf -- reading personal files, calling tools, transacting with external services -- possibly leaking personally identifiable information (PII) across trust boundaries at every step. Privacy here is a property not of a single output but of an entire trajectory, and three properties make it hard: leakage is cumulative, as individually innocuous releases accumulate across honest-but-curious or colluding sinks into inferences about a protected secret; bidirectional, as a malicious observation can inject instructions that turn the agent's own reasoning model against the user; and task-dependent, as the same field is necessary for one recipient yet gratuitous for another. Per-release contextual-integrity filters, information-flow controls, and posterior-leakage monitors each address part of this but none controls cumulative, inference-based leakage at runtime. We recast agent privacy as \emph{posterior-risk control} and present OCELOT, a runtime mediator that budgets how much an adversary's belief about a secret may improve across a trajectory, rather than filtering outputs. Its mechanism, \emph{Witness-Verified Declassification}, separates judgment from trust: an untrusted, locally fine-tuned defender model inspects each candidate release and emits structured evidence -- labeled atoms and proposed declassification operators -- which a deterministic verifier audits, charging a certified min-entropy cost for the chosen variant and authorizing the least-disclosing useful release under a sink-trust-weighted budget recorded on a tamper-evident ledger. Across diverse agent benchmarks and recent defenses, OCELOT attains significantly lower leakage at higher task utility, resists adaptive injection, jailbreak, cumulative inference, and sink collusion, and adds only modest overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents OCELOT, a runtime mediator for LLM agents that recasts privacy as posterior-risk control. It introduces Witness-Verified Declassification: an untrusted locally fine-tuned defender model emits labeled atoms and proposed declassification operators for each candidate release; a deterministic verifier audits them, assigns certified min-entropy costs, and authorizes the least-disclosing useful release under a sink-trust-weighted budget maintained on a tamper-evident ledger. The system is evaluated across agent benchmarks against recent defenses and claims significantly lower leakage at higher task utility while resisting adaptive injection, jailbreak, cumulative inference, and sink collusion with only modest overhead.
Significance. If the verifier is shown to be complete and the min-entropy accounting sound, the work would provide a principled runtime mechanism for controlling cumulative, bidirectional, and task-dependent leakage in agent trajectories, separating judgment from trust in a way that prior per-release filters and information-flow controls do not. The tamper-evident ledger and budget formulation are concrete strengths that could support reproducible evaluation.
major comments (2)
- [Witness-Verified Declassification mechanism] The soundness of the posterior-risk budget and all resistance claims (cumulative inference, sink collusion) rests on the deterministic verifier correctly enumerating every inference path enabled by the emitted atoms and never under-charging their min-entropy cost. The mechanism description provides no formal argument, enumeration procedure, or completeness proof for this step, especially given that atoms are produced by a fine-tuned LLM that could omit subtle inference chains.
- [Evaluation section] The evaluation claims resistance to adaptive injection, jailbreak, and cumulative inference across benchmarks, yet the reported results appear to rely on the verifier's correctness without an ablation or adversarial test that deliberately constructs omitted inference paths to check whether the budget is violated. This makes the empirical support conditional on the unverified verifier property.
minor comments (2)
- Notation for the budget ledger and sink-trust weights should be defined with explicit equations rather than prose descriptions to allow independent verification of the min-entropy accounting.
- The abstract and mechanism overview would benefit from a small illustrative example showing one atom, its declassification operator, the verifier's cost assignment, and the resulting budget update.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for highlighting the need for stronger formal grounding and empirical validation of the verifier in Witness-Verified Declassification. We address each major comment below and will incorporate the suggested additions in the revised manuscript.
read point-by-point responses
-
Referee: [Witness-Verified Declassification mechanism] The soundness of the posterior-risk budget and all resistance claims (cumulative inference, sink collusion) rests on the deterministic verifier correctly enumerating every inference path enabled by the emitted atoms and never under-charging their min-entropy cost. The mechanism description provides no formal argument, enumeration procedure, or completeness proof for this step, especially given that atoms are produced by a fine-tuned LLM that could omit subtle inference chains.
Authors: We agree that the current manuscript does not supply an explicit completeness argument or enumeration procedure for the verifier. The design treats the verifier as a deterministic function that, given the labeled atoms and proposed operators, exhaustively computes the min-entropy cost over all inference paths consistent with those atoms; the budget is then decremented by the certified cost of the chosen release. To strengthen this, the revision will add (i) a precise description of the enumeration algorithm, (ii) a proof sketch establishing completeness relative to the emitted atom set, and (iii) a discussion of the conservative nature of the accounting when the fine-tuned model may miss subtle chains. These additions will make the soundness claims explicit rather than implicit. revision: yes
-
Referee: [Evaluation section] The evaluation claims resistance to adaptive injection, jailbreak, and cumulative inference across benchmarks, yet the reported results appear to rely on the verifier's correctness without an ablation or adversarial test that deliberately constructs omitted inference paths to check whether the budget is violated. This makes the empirical support conditional on the unverified verifier property.
Authors: The existing experiments measure end-to-end leakage and utility under adaptive attacks, but they do not include a dedicated ablation that injects synthetic omitted paths to test budget violation. We will add such an ablation in the revised evaluation section: we will construct controlled cases where the defender model is forced to emit incomplete atom sets, run the verifier on the resulting releases, and report whether the budget is ever under-charged. This will directly address the conditional nature of the current empirical support. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and mechanism description contain no equations, self-referential definitions, fitted parameters presented as predictions, or load-bearing self-citations. The Witness-Verified Declassification approach is described at a high level with an untrusted model emitting evidence audited by a deterministic verifier, but no derivation chain reduces the posterior-risk budget or performance claims to inputs by construction. Empirical results across benchmarks are presented separately from any formal reduction. This is a standard non-finding for a system-design paper without visible mathematical self-reference.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
React: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “React: Synergizing reasoning and acting in language models,”arXiv preprint arXiv:2210.03629, 2022
Pith/arXiv arXiv 2022
-
[2]
Effective Harnesses for Long-Running Agents,
J. Young, “Effective Harnesses for Long-Running Agents,” https://www.anthropic.com/engineering/ effective-harnesses-for-long-running-agents, Nov. 2025, anthropic Engineering blog. Accessed: Jun. 1, 2026
2025
-
[3]
Harness Engineering: Leveraging Codex in an Agent-First World,
R. Lopopolo, “Harness Engineering: Leveraging Codex in an Agent-First World,” https://openai.com/index/harness-engineering/, Feb. 2026, openAI blog. Accessed: Jun. 1, 2026
2026
-
[4]
Natural- language agent harnesses,
L. Pan, L. Zou, S. Guo, J. Ni, and H.-T. Zheng, “Natural- language agent harnesses,” 2026. [Online]. Available: https: //arxiv.org/abs/2603.25723
Pith/arXiv arXiv 2026
-
[5]
Extracting training data from large language models,
N. Carlini, F. Tramer, E. Wallace, M. Jagielski, A. Herbert-V oss, K. Lee, A. Roberts, T. Brown, D. Song, U. Erlingsson, A. Oprea, and C. Raffel, “Extracting training data from large language models,”
-
[6]
Available: https://arxiv.org/abs/2012.07805
[Online]. Available: https://arxiv.org/abs/2012.07805
arXiv 2012
-
[7]
Beyond memorization: Violating privacy via inference with large language models,
R. Staab, M. Vero, M. Balunovi ´c, and M. Vechev, “Beyond memorization: Violating privacy via inference with large language models,” 2024. [Online]. Available: https://arxiv.org/abs/2310.07298
arXiv 2024
-
[8]
Agentleak: A full-stack benchmark for privacy leakage in multi-agent llm systems,
F. E. Yagoubi, G. Badu-Marfo, and R. A. Mallah, “Agentleak: A full-stack benchmark for privacy leakage in multi-agent llm systems,” 2026. [Online]. Available: https://arxiv.org/abs/2602.11510
arXiv 2026
-
[9]
Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents,
E. Debenedetti, J. Zhang, M. Balunovi ´c, L. Beurer-Kellner, M. Fischer, and F. Tram `er, “Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents,” 2024. [Online]. Available: https://arxiv.org/abs/2406.13352
Pith/arXiv arXiv 2024
-
[10]
N. Mireshghallah, H. Kim, X. Zhou, Y . Tsvetkov, M. Sap, R. Shokri, and Y . Choi, “Can llms keep a secret? testing privacy implications of language models via contextual integrity theory,” 2024. [Online]. Available: https://arxiv.org/abs/2310.17884
arXiv 2024
-
[11]
Privacy as contextual integrity,
H. Nissenbaum, “Privacy as contextual integrity,”Wash. L. Rev., vol. 79, p. 119, 2004
2004
-
[12]
Flexguard: Continuous risk scoring for strictness-adaptive llm content moderation,
Z. Ding, J. Li, Z. Lu, and J. Shi, “Flexguard: Continuous risk scoring for strictness-adaptive llm content moderation,” 2026. [Online]. Available: https://arxiv.org/abs/2602.23636
Pith/arXiv arXiv 2026
-
[13]
Privacy in action: Towards realistic privacy mitigation and evaluation for llm-powered agents,
S. Wang, F. Yu, X. Liu, X. Qin, J. Zhang, Q. Lin, D. Zhang, and S. Rajmohan, “Privacy in action: Towards realistic privacy mitigation and evaluation for llm-powered agents,” 2025. [Online]. Available: https://arxiv.org/abs/2509.17488
arXiv 2025
-
[14]
Defeating prompt injections by design,
E. Debenedetti, I. Shumailov, T. Fan, J. Hayes, N. Carlini, D. Fabian, C. Kern, C. Shi, A. Terzis, and F. Tram `er, “Defeating prompt injections by design,” 2025. [Online]. Available: https: //arxiv.org/abs/2503.18813
Pith/arXiv arXiv 2025
-
[15]
Rtbas: Defending llm agents against prompt injection and privacy leakage,
P. Y . Zhong, S. Chen, R. Wang, M. McCall, B. L. Titzer, H. Miller, and P. B. Gibbons, “Rtbas: Defending llm agents against prompt injection and privacy leakage,” 2025. [Online]. Available: https://arxiv.org/abs/2502.08966
arXiv 2025
-
[16]
AgentDAM: Privacy leakage evaluation for autonomous web agents,
A. Zharmagambetov, C. Guo, I. Evtimov, M. Pavlova, R. Salakhutdinov, and K. Chaudhuri, “AgentDAM: Privacy leakage evaluation for autonomous web agents,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2026. [Online]. Available: https://openreview.net/forum?id=qaxf7q41aK
2026
-
[17]
Information-theoretic privacy control for sequential multi-agent llm systems,
S. Asif and M. M. Amiri, “Information-theoretic privacy control for sequential multi-agent llm systems,” 2026. [Online]. Available: https://arxiv.org/abs/2603.05520
arXiv 2026
-
[18]
On the foundations of quantitative information flow,
G. Smith, “On the foundations of quantitative information flow,” in International Conference on Foundations of Software Science and Computational Structures. Springer, 2009, pp. 288–302
2009
-
[19]
An information-theoretic model for adaptive side-channel attacks,
B. K ¨opf and D. Basin, “An information-theoretic model for adaptive side-channel attacks,” inProceedings of the 14th ACM conference on Computer and communications security, 2007, pp. 286–296
2007
-
[20]
The algorithmic foundations of differential privacy,
C. Dwork and A. Roth, “The algorithmic foundations of differential privacy,”Foundations and trends® in theoretical computer science, vol. 9, no. 3-4, pp. 211–487, 2014
2014
-
[21]
Darwiche,Modeling and reasoning with Bayesian networks
A. Darwiche,Modeling and reasoning with Bayesian networks. Cambridge university press, 2009
2009
-
[22]
Probabilistic inference in credal networks: new complexity results,
D. D. Mau ´a, C. P. de Campos, A. Benavoli, and A. Antonucci, “Probabilistic inference in credal networks: new complexity results,” Journal of Artificial Intelligence Research, vol. 50, pp. 603–637, 2014
2014
-
[23]
The smt-lib standard: Version 2.0,
C. Barrett, A. Stump, C. Tinelliet al., “The smt-lib standard: Version 2.0,” inProceedings of the 8th international workshop on satisfiability modulo theories (Edinburgh, UK), vol. 13, 2010, p. 14
2010
-
[24]
Z3: An efficient smt solver,
L. De Moura and N. Bjørner, “Z3: An efficient smt solver,” inIn- ternational conference on Tools and Algorithms for the Construction and Analysis of Systems. Springer, 2008, pp. 337–340
2008
-
[25]
D. Melcer, N. Fulton, S. K. Gouda, and H. Qian, “Constrained decoding for fill-in-the-middle code language models via efficient left and right quotienting of context-sensitive grammars,” 2024. [Online]. Available: https://arxiv.org/abs/2402.17988
arXiv 2024
-
[26]
Deepseekmath: Pushing the limits of mathematical reasoning in open language models,
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . K. Li, Y . Wu, and D. Guo, “Deepseekmath: Pushing the limits of mathematical reasoning in open language models,”
-
[27]
Available: https://arxiv.org/abs/2402.03300
[Online]. Available: https://arxiv.org/abs/2402.03300
-
[28]
Satisfiability modulo theories,
C. Barrett and C. Tinelli, “Satisfiability modulo theories,” inHand- book of model checking. Springer, 2018, pp. 305–343
2018
-
[29]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al- Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughanet al., “The llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024
Pith/arXiv arXiv 2024
-
[30]
Qwen3.5: Accelerating productivity with native multimodal agents,
Q. Team, “Qwen3.5: Accelerating productivity with native multimodal agents,” February 2026. [Online]. Available: https://qwen.ai/blog?id=qwen3.5
2026
-
[31]
The minimax-m2 series: Mini activations unleashing max real-world intelligence,
A. Chen, A. Li, B. Zhou, B. Gong, B. Jiang, B. Dan, C. Yu, C. Wang, C. Ma, C. Zhonget al., “The minimax-m2 series: Mini activations unleashing max real-world intelligence,”arXiv preprint arXiv:2605.26494, 2026
Pith/arXiv arXiv 2026
-
[32]
Deepseek-v4: Towards highly efficient million-token context intelligence,
DeepSeek-AI, “Deepseek-v4: Towards highly efficient million-token context intelligence,” 2026
2026
-
[33]
Simplification by cooperating decision procedures,
G. Nelson and D. C. Oppen, “Simplification by cooperating decision procedures,”ACM Transactions on Programming Languages and Systems (TOPLAS), vol. 1, no. 2, pp. 245–257, 1979
1979
-
[34]
High-speed high-security signatures,
D. J. Bernstein, N. Duif, T. Lange, P. Schwabe, and B.-Y . Yang, “High-speed high-security signatures,”Journal of cryptographic en- gineering, vol. 2, no. 2, pp. 77–89, 2012
2012
-
[35]
Secure hash standard (shs),
F. Pub, “Secure hash standard (shs),”Fips pub, vol. 180, no. 4, p. 2012, 2012. Appendix A. Lemmas and Their Proofs We prove the three body lemmas. All are model-relative: they bound quantities under Pre-Reg. A’s calibration model and the verifier’s construction, not true adversarial inference (Layer-2, §3.4). Lemma 1 (model-relative sub-additivity).Letσ= ...
2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.