Viral Proteins Reveal Geometry of Protein Language Models
Pith reviewed 2026-06-27 10:00 UTC · model grok-4.3
The pith
Protein language model embeddings contain a dominant nativeness axis aligned with reconstruction perplexity while retaining linearly separable signals specific to viral proteins.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
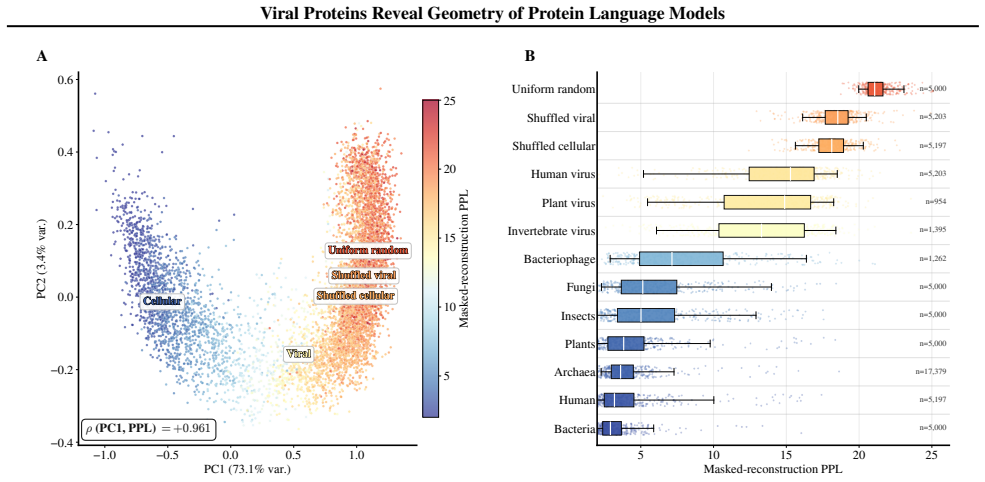
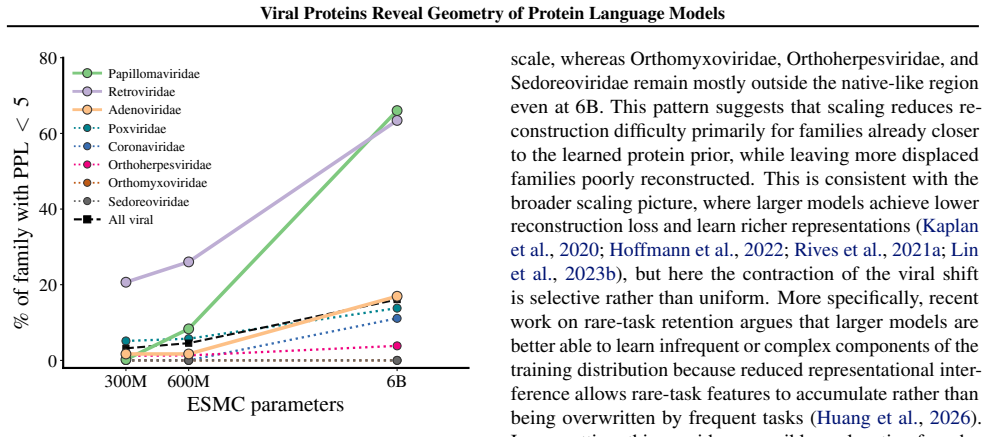
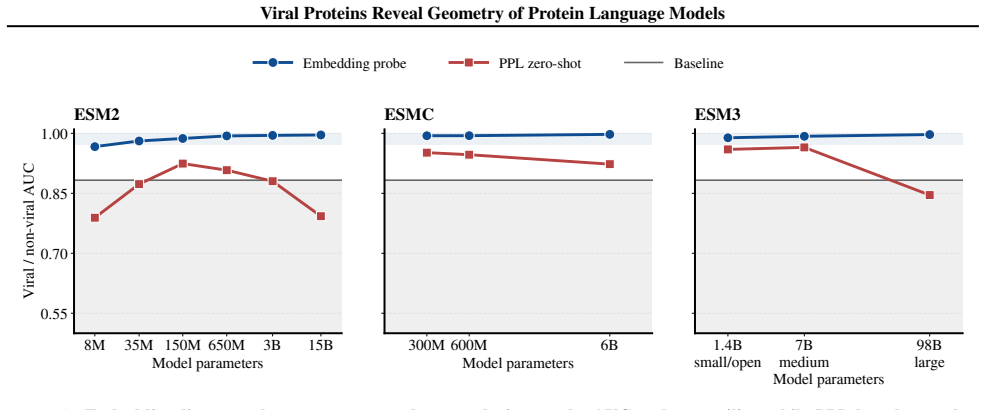
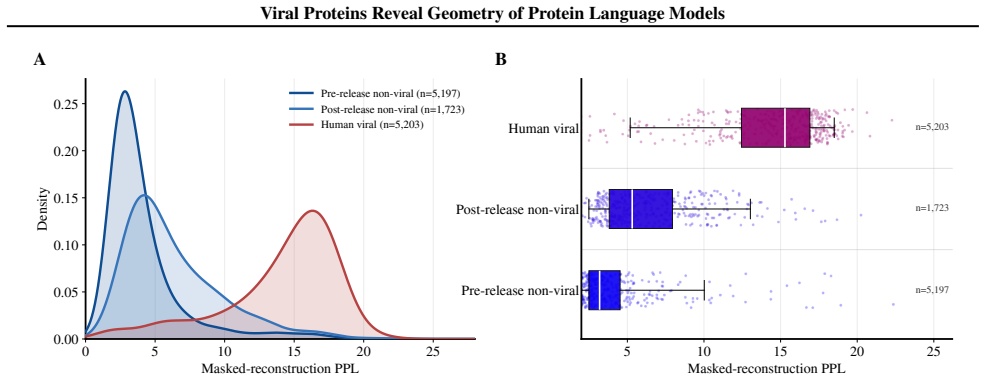
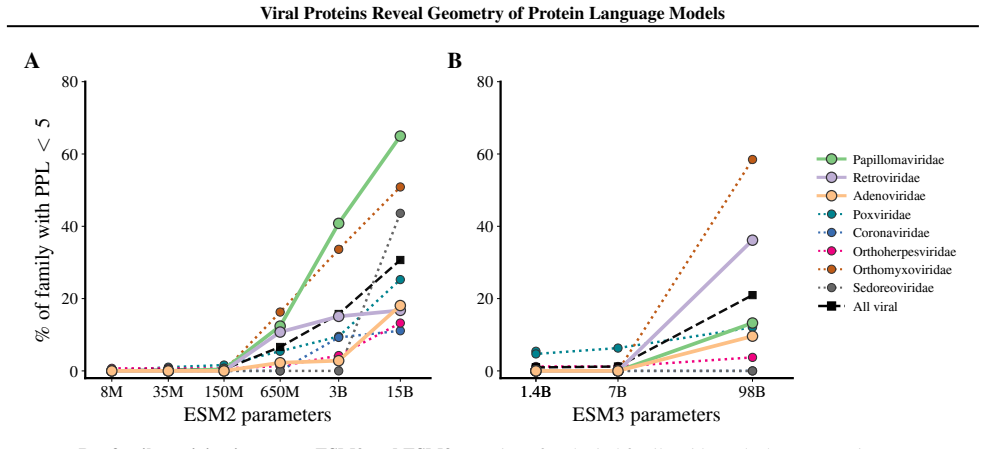
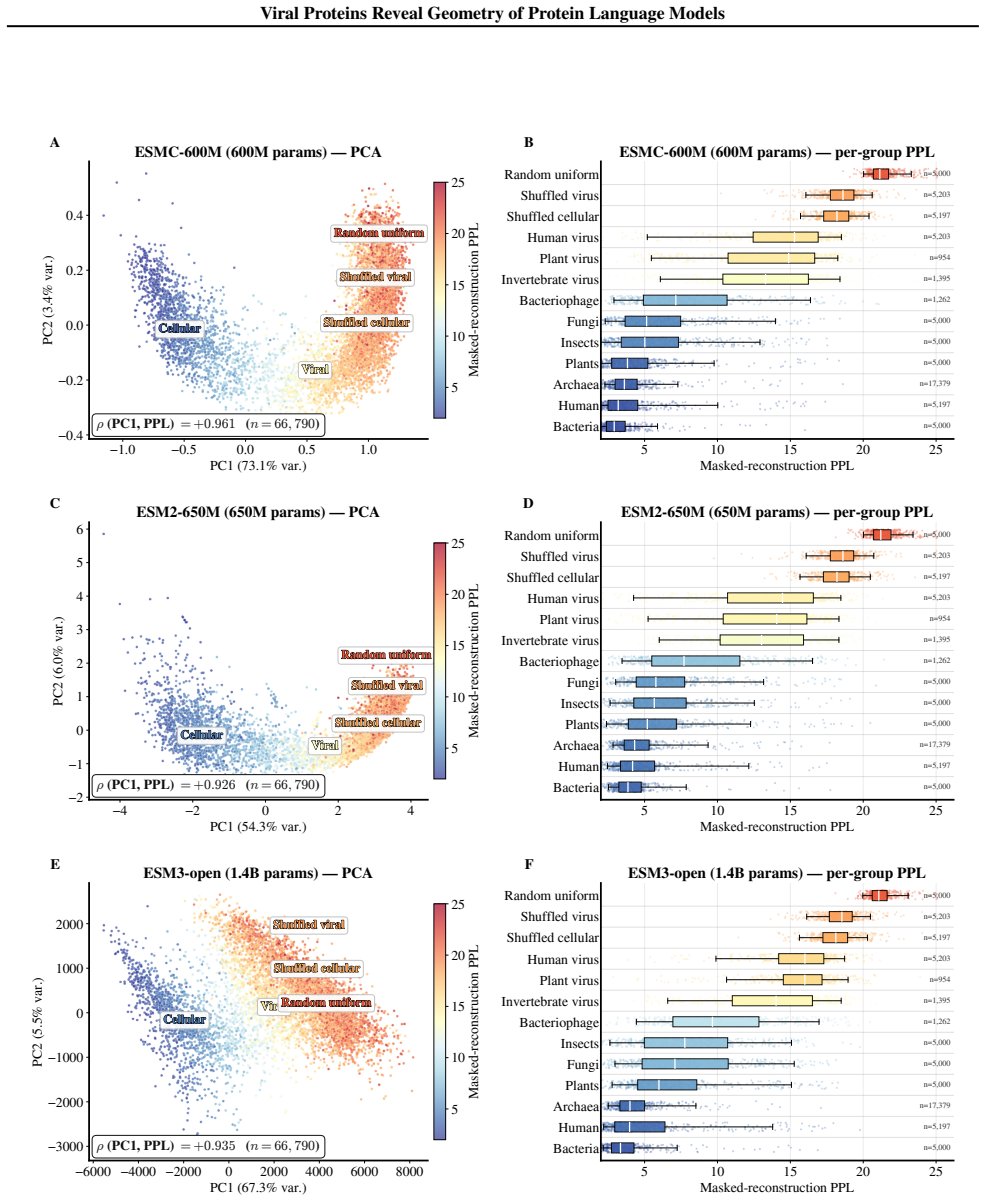
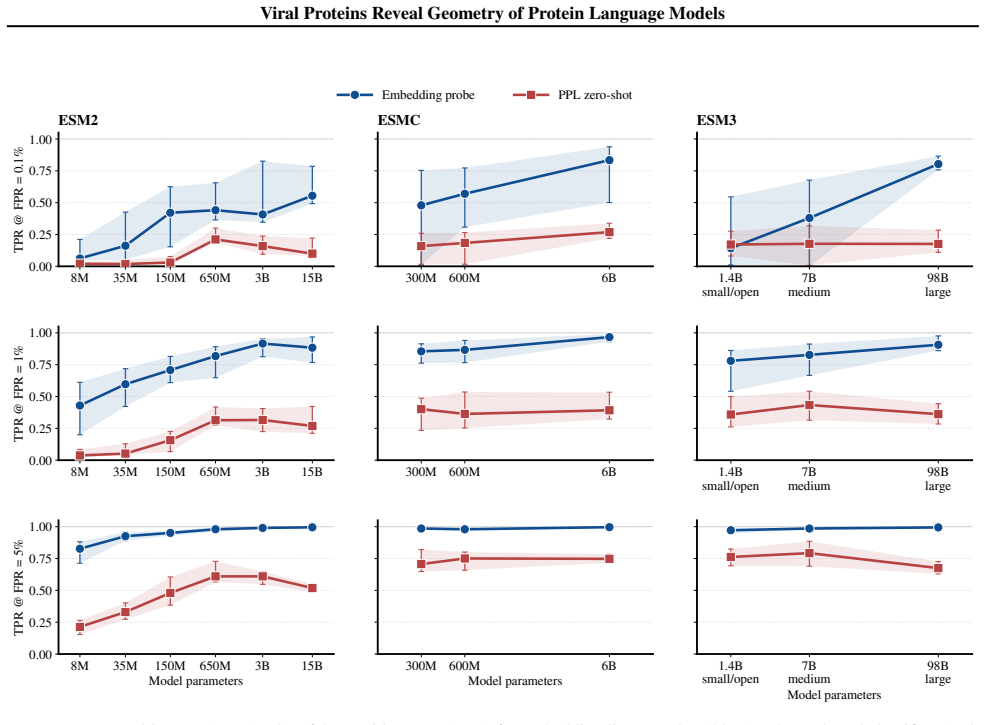
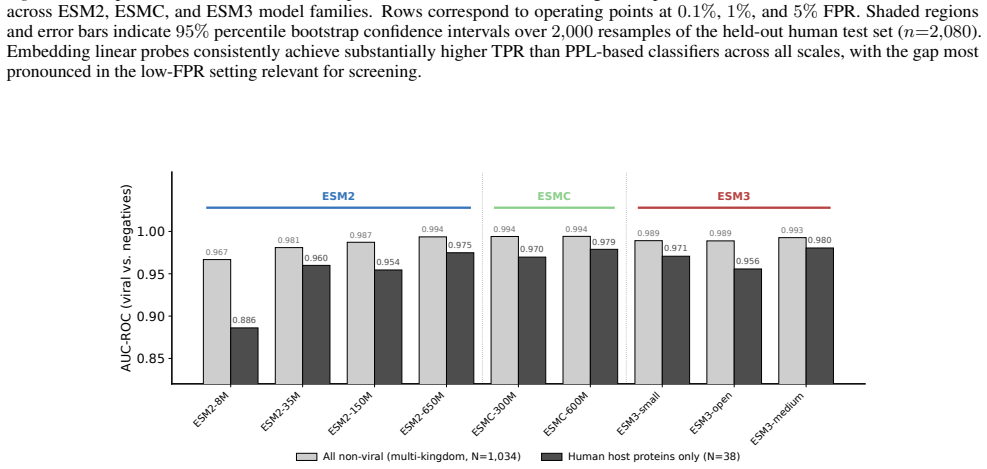
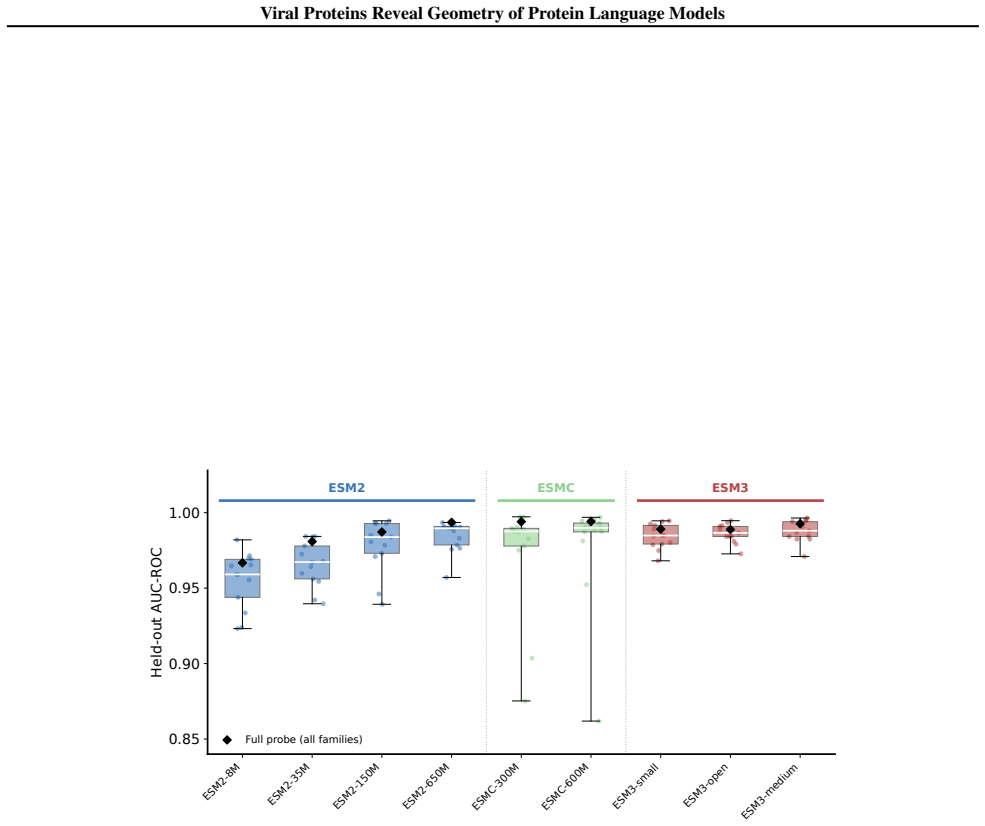
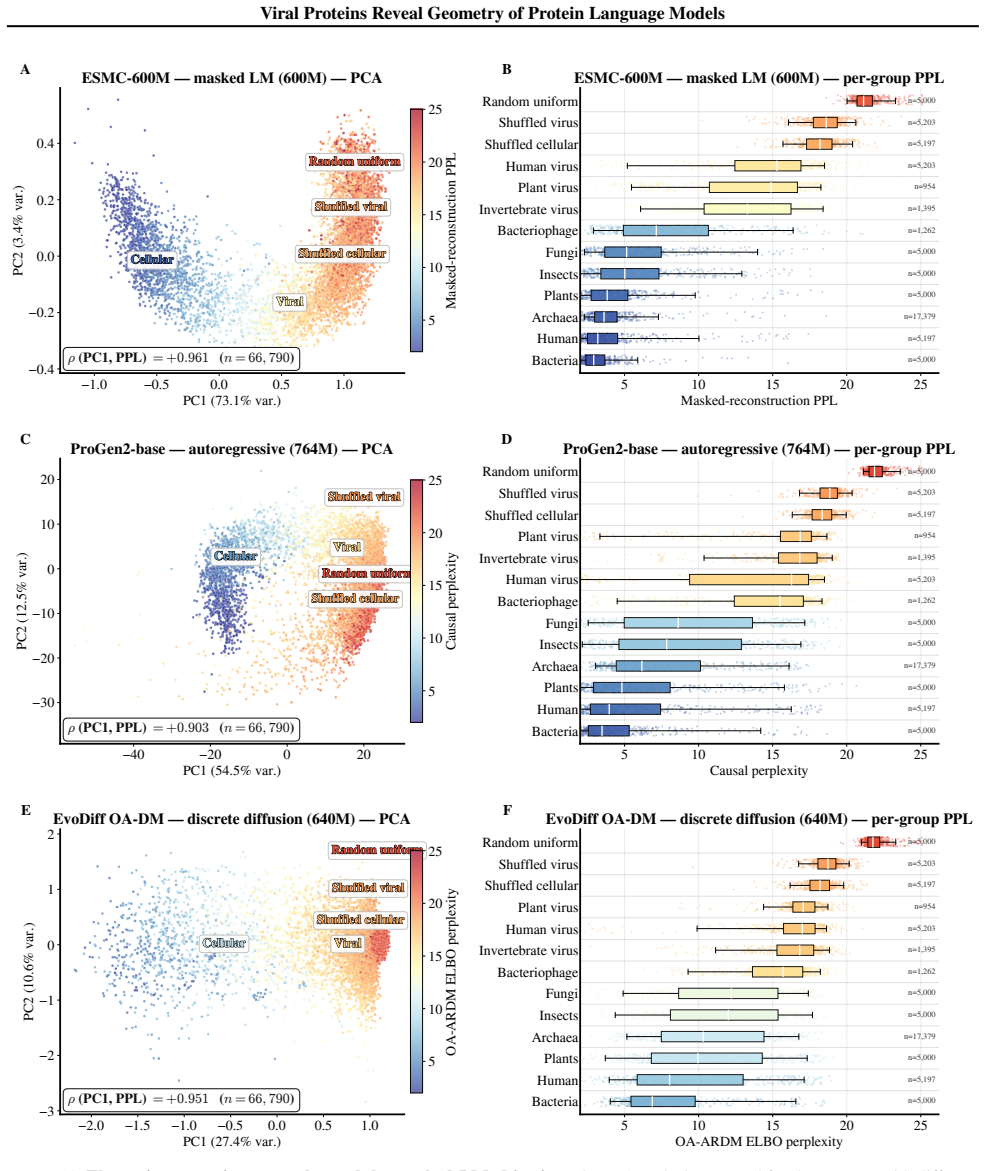
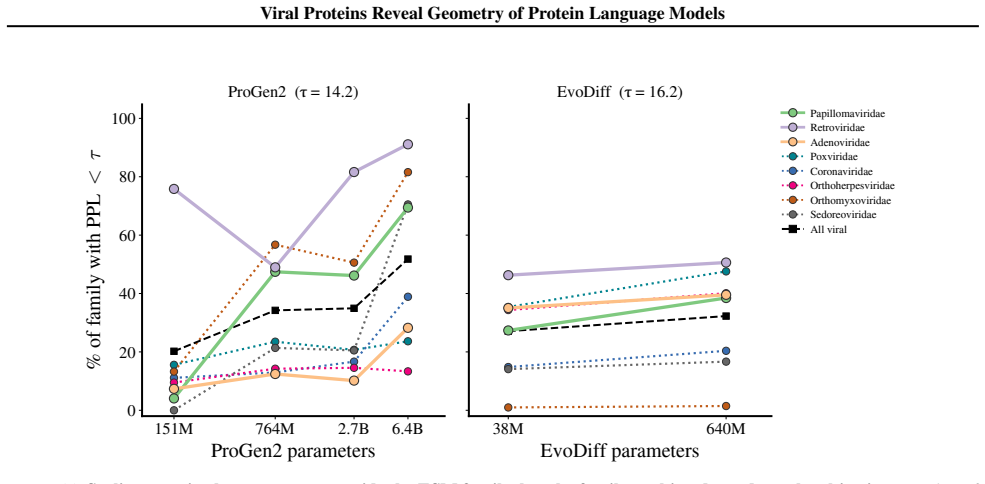
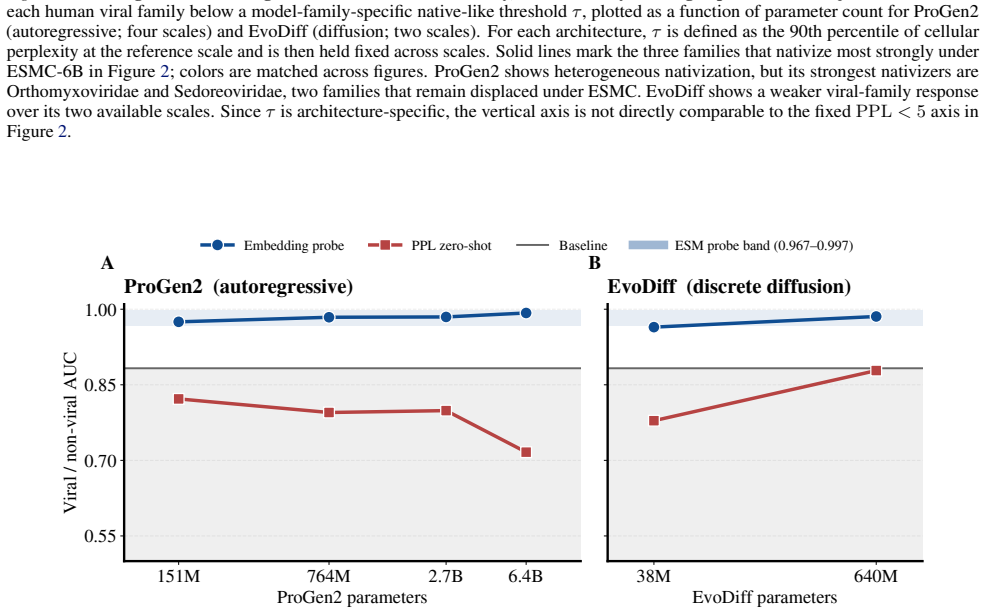
Across ESM model families, viral proteins as a case study reveal a dominant nativeness axis in embedding space that aligns with masked reconstruction perplexity and orders sequences from well-modeled cellular proteins through viral proteins to shuffled and random sequences. Model scaling contracts this axis unevenly across viral families. Despite the axis, protein language model embeddings retain viral-specific signal such that viral proteins remain linearly separable beyond zero-shot perplexity and shallow sequence features.
What carries the argument
The dominant nativeness axis in embedding space, aligned with masked reconstruction perplexity, that structures the ordering of sequences by how native they appear to the model.
If this is right
- Scaling model size contracts the nativeness axis at different rates for different viral families.
- Viral proteins stay linearly separable in embedding space after zero-shot perplexity and shallow sequence features are accounted for.
- Embeddings are structured by a general notion of nativeness while still preserving information specific to distinct biological groups.
Where Pith is reading between the lines
- The axis could be used as a built-in score for how far any new sequence lies from the model's training distribution.
- Similar geometric structure may appear when other underrepresented sequence classes are examined in the same models.
- Training procedures that explicitly balance the nativeness axis might reduce uneven effects across biological groups.
Load-bearing premise
The observed dominant axis truly reflects a general notion of nativeness rather than other dataset imbalances or model-specific artifacts not controlled for in the analysis.
What would settle it
A test in which viral proteins lose linear separability once embeddings are projected to remove the component aligned with perplexity or once sequence composition and length are explicitly matched would show the retained viral-specific signal does not exist beyond the nativeness axis.
Figures
read the original abstract
Protein language models are trained on highly imbalanced datasets, raising the question of how they represent underrepresented biological sequences. Using viral proteins as a case study across ESM model families, we identify a dominant nativeness axis in embedding space, aligned with masked reconstruction perplexity, that orders sequences from well-modeled cellular proteins through viral proteins to shuffled and random sequences. Scaling contracts this axis unevenly across viral families. Despite this, protein language model embeddings retain viral-specific signal: viral proteins remain linearly separable beyond zero-shot perplexity and shallow sequence features. Together, these results suggest that pLM representations are structured by a general notion of nativeness while preserving information specific to distinct biological groups.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript uses viral proteins as a case study across ESM model families to probe the geometry of protein language model embeddings. It reports a dominant nativeness axis in embedding space, aligned with masked reconstruction perplexity, that orders cellular proteins above viral proteins above shuffled and random sequences. Model scaling contracts this axis unevenly across viral families. The central empirical claim is that pLM embeddings nonetheless retain viral-specific signal, with viral proteins remaining linearly separable beyond zero-shot perplexity and shallow sequence features.
Significance. If the results hold after controls, the work provides concrete empirical insight into how pLMs trained on imbalanced data represent underrepresented sequences, documenting both a global nativeness structure and residual group-specific information. The explicit comparison of embedding separability against perplexity and shallow-feature baselines is a methodological strength that grounds the claim of retained viral signal.
major comments (2)
- [Results] Results section: the claim that viral proteins remain linearly separable beyond zero-shot perplexity and shallow sequence features is presented without quantitative details on statistical controls, sample sizes, effect sizes, or explicit ablations for confounds such as sequence length and amino-acid composition biases. These controls are load-bearing for validating the residual viral-specific signal.
- [Results] The identification and validation of the dominant nativeness axis (its alignment with perplexity and ordering of sequence classes) lacks reported metrics such as correlation coefficients, variance explained, or robustness checks against alternative axes; without these, it is difficult to confirm the axis reflects a general notion of nativeness rather than dataset imbalances.
minor comments (1)
- [Methods] Notation for the nativeness axis and the linear separability metric should be defined more explicitly in the main text or a methods subsection to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify opportunities to strengthen the quantitative support for our claims. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Results] Results section: the claim that viral proteins remain linearly separable beyond zero-shot perplexity and shallow sequence features is presented without quantitative details on statistical controls, sample sizes, effect sizes, or explicit ablations for confounds such as sequence length and amino-acid composition biases. These controls are load-bearing for validating the residual viral-specific signal.
Authors: We agree that these details are necessary to substantiate the claim of retained viral-specific signal. In the revised manuscript we will report exact sample sizes for all classification experiments, effect sizes including accuracies or AUC values with bootstrap confidence intervals, and explicit ablations that control for sequence length and amino-acid composition (e.g., length-matched subsampling and composition-matched controls, or regression-based adjustment for these covariates). revision: yes
-
Referee: [Results] The identification and validation of the dominant nativeness axis (its alignment with perplexity and ordering of sequence classes) lacks reported metrics such as correlation coefficients, variance explained, or robustness checks against alternative axes; without these, it is difficult to confirm the axis reflects a general notion of nativeness rather than dataset imbalances.
Authors: We accept that additional metrics are required to characterize the axis. The revision will include the correlation (Pearson or Spearman) between the dominant axis coordinates and masked perplexity, the fraction of variance explained by the first principal component, and robustness checks such as repeating the analysis across embedding layers and comparing the nativeness axis against axes derived from length or composition features alone. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper presents purely empirical measurements: identification of a dominant nativeness axis in pLM embeddings (aligned with masked perplexity), ordering of sequences, uneven contraction under scaling, and residual linear separability of viral proteins after controlling for perplexity and shallow features. No equations, derivations, or 'predictions' are claimed that reduce to fitted parameters defined from the same data, self-citations, or ansatzes. The central claim rests on direct comparisons in embedding space that are falsifiable against external benchmarks and do not invoke uniqueness theorems or load-bearing self-citations. This matches the default case of a self-contained empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
bioRxiv , pages=
Intrinsic dataset features drive mutational effect prediction by protein language models , author=. bioRxiv , pages=. 2026 , publisher=
2026
-
[2]
Proceedings of the National Academy of Sciences , volume=
Predicting high-fitness viral protein variants with Bayesian active learning and biophysics , author=. Proceedings of the National Academy of Sciences , volume=. 2025 , publisher=
2025
-
[3]
Shakhnovich , title =
Dianzhuo Wang and Marian Huot and Vaibhav Mohanty and Eugene I. Shakhnovich , title =. Proceedings of the National Academy of Sciences , volume =. 2024 , doi =
2024
-
[4]
2026 , eprint=
Deterministic access to global viral sequence data enables robust agentic scientific discovery , author=. 2026 , eprint=
2026
-
[5]
bioRxiv , pages=
Biophysically Grounded Deep Learning Improves Protein--Protein G Prediction , author=. bioRxiv , pages=. 2025 , publisher=
2025
-
[6]
Frontiers in Microbiology , volume=
Without safeguards, AI-Biology integration risks accelerating future pandemics , author=. Frontiers in Microbiology , volume=. 2026 , publisher=
2026
-
[7]
Science , volume=
Strengthening nucleic acid biosecurity screening against generative protein design tools , author=. Science , volume=. 2025 , publisher=
2025
-
[8]
Frontiers in Bioengineering and Biotechnology , volume =
Beyond Sequence Similarity: Toward Function-Based Screening of Nucleic Acid Synthesis , author =. Frontiers in Bioengineering and Biotechnology , volume =. 2026 , doi =
2026
-
[9]
Proceedings of the National Academy of Sciences , year =
Alexander Rives and Joshua Meier and Tom Sercu and Siddharth Goyal and Zeming Lin and Jason Liu and Demi Guo and Myle Ott and C.\ Lawrence Zitnick and Jerry Ma and Rob Fergus , title =. Proceedings of the National Academy of Sciences , year =
-
[10]
Science , year =
Zeming Lin and Halil Akin and Roshan Rao and Brian Hie and Zhongkai Zhu and Wenting Lu and Nikita Smetanin and Robert Verkuil and Ori Kabeli and Yaniv Shmueli and Allan dos Santos Costa and Maryam Fazel-Zarandi and Tom Sercu and Salvatore Candido and Alexander Rives , title =. Science , year =
-
[11]
Nature Reviews Microbiology , year =
Peter Simmonds and Pakorn Aiewsakun and Aris Katzourakis , title =. Nature Reviews Microbiology , year =
-
[12]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Joshua Meier and Roshan Rao and Robert Verkuil and Jason Liu and Tom Sercu and Alexander Rives , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[13]
Proceedings of the 39th International Conference on Machine Learning (ICML) , year =
Chloe Hsu and Robert Verkuil and Jason Liu and Zeming Lin and Brian Hie and Tom Sercu and Adam Lerer and Alexander Rives , title =. Proceedings of the 39th International Conference on Machine Learning (ICML) , year =
-
[14]
and Oktay, Deniz and Lin, Zeming and Verkuil, Robert and Tran, Vincent Q
Hayes, Thomas and Rao, Roshan and Akin, Halil and Sofroniew, Nicholas J. and Oktay, Deniz and Lin, Zeming and Verkuil, Robert and Tran, Vincent Q. and Deaton, Jonathan and Wiggert, Marius and Badkundri, Rohil and Shafkat, Irhum and Gong, Jun and Derry, Alexander and Molina, Rafael S. and Thomas, Neil and Khan, Yousuf A. and Mishra, Chaitanya and Kim, Caro...
-
[15]
Bioinformatics , year =
Baris E.\ Suzek and Yuqi Wang and Hongzhan Huang and Peter B.\ McGarvey and Cathy H.\ Wu and. Bioinformatics , year =
-
[16]
Viruses , year =
Mihara, Tomoko and Nishimura, Yosuke and Shimizu, Yugo and Nishiyama, Hiroki and Yoshikawa, Genki and Uehara, Hideya and Hingamp, Pascal and Goto, Susumu and Ogata, Hiroyuki , title =. Viruses , year =
-
[17]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Pascal Notin and Aaron W.\ Kollasch and Daniel Ritter and Lood van Niekerk and Steffan Paul and Han Spinner and Nathan Rollins and Ada Shaw and Rose Orenbuch and Ruben Weitzman and Jonathan Frazer and Mafalda Dias and Dinko Franceschi and Rose Gal and Debora Marks , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[18]
bioRxiv , year =
Christian Dallago and Jody Mou and Kadina E.\ Johnston and Bruce J.\ Wittmann and Nicholas Bhattacharya and Samuel Goldman and Ali Madani and Kevin K.\ Yang , title =. bioRxiv , year =
-
[19]
Nature , year =
Ivan Anishchenko and Samuel J.\ Pellock and Tamuka M.\ Chidyausiku and Theresa A.\ Ramelot and Sergey Ovchinnikov and Jingzhou Hao and Khushboo Bafna and Christoffer Norn and Alex Kang and Asim K.\ Bera and Frank DiMaio and Lauren Carter and Cameron M.\ Chow and Gaetano T.\ Montelione and David Baker , title =. Nature , year =
-
[20]
bioRxiv , year =
Robert Verkuil and Ori Kabeli and Yilun Du and Basile I.\ M.\ Wicky and Lukas F.\ Milles and Justas Dauparas and David Baker and Sergey Ovchinnikov and Tom Sercu and Alexander Rives , title =. bioRxiv , year =
-
[21]
International Conference on Learning Representations (ICLR) , year =
Jesse Vig and Ali Madani and Lav R.\ Varshney and Caiming Xiong and Richard Socher and Nazneen Fatema Rajani , title =. International Conference on Learning Representations (ICLR) , year =
-
[22]
Association for Computational Linguistics (ACL) , year =
Shauli Ravfogel and Yanai Elazar and Hila Gonen and Michael Twiton and Yoav Goldberg , title =. Association for Computational Linguistics (ACL) , year =
-
[23]
bioRxiv , year =
Jake Silberg and Elana Simon and James Zou , title =. bioRxiv , year =
-
[24]
Nature Microbiology , year =
Zachary H.\ Flamholz and Steven J.\ Biller and Libusha Kelly , title =. Nature Microbiology , year =
-
[25]
Nature Methods , year =
Elana Simon and James Zou , title =. Nature Methods , year =
-
[26]
Proceedings of the National Academy of Sciences , year =
Zhidian Zhang and Hannah K.\ Wayment-Steele and Garyk Brixi and Haobo Wang and Dorothee Kern and Sergey Ovchinnikov , title =. Proceedings of the National Academy of Sciences , year =
-
[27]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Roshan Rao and Nicholas Bhattacharya and Neil Thomas and Yan Duan and Xi Chen and John Canny and Pieter Abbeel and Yun S.\ Song , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[28]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[29]
Nucleic Acids Research , year =
-
[30]
Nature Biotechnology , year =
Martin Steinegger and Johannes S\". Nature Biotechnology , year =
-
[31]
Kodali and Shashikant Pujar and Vyacheslav Brover and Barbara Robbertse and Catherine M
Tamara Goldfarb and Vamsi K. Kodali and Shashikant Pujar and Vyacheslav Brover and Barbara Robbertse and Catherine M. Farrell and Daniel H. Oh and Alexey Astashyn and Olga Ermolaeva and Dana Haddad and Wratko Hlavina and Jennifer Hoffman and John D. Jackson and Vinita S. Joardar and David Kristensen and Patrick Masterson and Kelly M. McGarvey and Richard ...
-
[32]
Rodney Brister and Danso Ako-adjei and Yiming Bao and Olga Blinkova , title =
J. Rodney Brister and Danso Ako-adjei and Yiming Bao and Olga Blinkova , title =. Nucleic Acids Research , year =
-
[33]
Bacteriological Reviews , year =
David Baltimore , title =. Bacteriological Reviews , year =
-
[34]
Vieira and Morgan L
Luiz C. Vieira and Morgan L. Handojo and Claus O. Wilke , title =. Scientific Reports , year =
-
[35]
International Conference on Learning Representations (ICLR) , year =
Jiaqi Mu and Pramod Viswanath , title =. International Conference on Learning Representations (ICLR) , year =
-
[36]
Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
Kawin Ethayarajh , title =. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
2019
-
[37]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
William Timkey and Marten van Schijndel , title =. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
2021
-
[38]
Viruses , year =
Dan Ofer and Michal Linial , title =. Viruses , year =
-
[39]
Language modelling for biological sequences -- curated datasets and baselines , journal =
Jos. Language modelling for biological sequences -- curated datasets and baselines , journal =. 2020 , note =
2020
-
[40]
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL) , year =
Julian Salazar and Davis Liang and Toan Q.\ Nguyen and Katrin Kirchhoff , title =. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[41]
Science , year =
Brian Hie and Ellen D.\ Zhong and Bonnie Berger and Bryan Bryson , title =. Science , year =
-
[42]
Nature Biotechnology , year =
Ali Madani and Ben Krause and Eric R.\ Greene and Subu Subramanian and Benjamin P.\ Mohr and James M.\ Holton and Jose Luis Olmos Jr and Caiming Xiong and Zachary Z.\ Sun and Richard Socher and James S.\ Fraser and Nikhil Naik , title =. Nature Biotechnology , year =
-
[43]
Pseudo-perplexity in one fell swoop for protein fitness estimation , author =. PRX Life , volume =. 2025 , month =. doi:10.1103/zhx7-hcmm , url =
-
[44]
Scaling Laws for Neural Language Models
Scaling Laws for Neural Language Models , author =. arXiv preprint arXiv:2001.08361 , year =. 2001.08361 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[45]
Training Compute-Optimal Large Language Models
Training Compute-Optimal Large Language Models , author =. arXiv preprint arXiv:2203.15556 , year =. 2203.15556 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
Proceedings of the National Academy of Sciences , volume =
Biological Structure and Function Emerge from Scaling Unsupervised Learning to 250 Million Protein Sequences , author =. Proceedings of the National Academy of Sciences , volume =. 2021 , doi =
2021
-
[47]
Science , volume =
Evolutionary-Scale Prediction of Atomic-Level Protein Structure with a Language Model , author =. Science , volume =. 2023 , doi =
2023
-
[48]
Cell Systems , volume =
ProGen2: Exploring the Boundaries of Protein Language Models , author =. Cell Systems , volume =. 2023 , doi =
2023
-
[49]
and Oktay, Deniz and Lin, Zeming and Verkuil, Robert and Tran, Vincent Q
Hayes, Thomas and Rao, Roshan and Akin, Halil and Sofroniew, Nicholas J. and Oktay, Deniz and Lin, Zeming and Verkuil, Robert and Tran, Vincent Q. and Deaton, Jonathan and Wiggert, Marius and Badkundri, Rohil and Shafkat, Irhum and Gong, Jun and Derry, Alexander and Molina, Rafael S. and Thomas, Neil and Khan, Yousuf A. and Mishra, Chaitanya and Kim, Caro...
-
[50]
International Conference on Learning Representations , year =
Transformer Protein Language Models Are Unsupervised Structure Learners , author =. International Conference on Learning Representations , year =
-
[51]
Advances in Neural Information Processing Systems , volume =
Language Models Enable Zero-Shot Prediction of the Effects of Mutations on Protein Function , author =. Advances in Neural Information Processing Systems , volume =
-
[52]
Proceedings of the 42nd International Conference on Machine Learning , series =
From Mechanistic Interpretability to Mechanistic Biology: Training, Evaluating, and Interpreting Sparse Autoencoders on Protein Language Models , author =. Proceedings of the 42nd International Conference on Machine Learning , series =. 2025 , url =
2025
-
[53]
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages =
Masked Language Model Scoring , author =. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages =. 2020 , doi =
2020
-
[54]
Science , volume =
Learning the Language of Viral Evolution and Escape , author =. Science , volume =. 2021 , doi =
2021
-
[55]
Nature Biotechnology , volume =
Large Language Models Generate Functional Protein Sequences Across Diverse Families , author =. Nature Biotechnology , volume =. 2023 , doi =
2023
-
[56]
PRX Life , volume =
Pseudo-Perplexity in One Fell Swoop for Protein Fitness Estimation , author =. PRX Life , volume =. 2025 , doi =
2025
-
[57]
Nature Microbiology , volume =
Large Language Models Improve Annotation of Prokaryotic Viral Proteins , author =. Nature Microbiology , volume =. 2024 , doi =
2024
-
[58]
and Robertson, David L
Liu, Dan and Young, Francesca and Lamb, Kieran D. and Robertson, David L. and Yuan, Ke , title =. PLOS Computational Biology , year =
-
[59]
NAR Genomics and Bioinformatics , volume =
Phage Evolutionary Relationships Emerge from Protein Language Model-Based Proteome Representation , author =. NAR Genomics and Bioinformatics , volume =. 2025 , doi =
2025
-
[60]
Virus Research , volume =
Viral reverse transcriptases , author =. Virus Research , volume =. 2017 , doi =
2017
-
[61]
The ISME Journal , volume =
Reverse transcriptase genes are highly abundant and transcriptionally active in marine plankton assemblages , author =. The ISME Journal , volume =. 2016 , doi =
2016
-
[62]
Virus Research , volume =
The diversity of retrotransposons and the properties of their reverse transcriptases , author =. Virus Research , volume =. 2008 , doi =
2008
-
[63]
Evaluating Variant Effect Prediction Across Viruses , url =
Gurev, Sarah and Youssef, Noor and Jain, Navami and Mehrotra, Aarushi and Leung, Sarrah Rose Mikhail and Jackson, Abigail and Marks, Debora , doi =. Evaluating Variant Effect Prediction Across Viruses , url =. 2026 , bdsk-url-1 =. https://www.biorxiv.org/content/early/2026/01/12/2025.08.04.668549.1.full.pdf , journal =
2026
-
[64]
Trends in Biochemical Sciences , volume =
Do viral proteins possess unique biophysical features? , author =. Trends in Biochemical Sciences , volume =. 2009 , doi =
2009
-
[65]
and Lin, Sophia and Wilke, Claus O
Vieira, Luiz C. and Lin, Sophia and Wilke, Claus O. , title =. 2026 , doi =. https://www.biorxiv.org/content/early/2026/03/10/2026.03.08.710389.full.pdf , journal =
2026
-
[66]
bioRxiv , year =
Protein generation with evolutionary diffusion: sequence is all you need , author =. bioRxiv , year =
-
[67]
International Conference on Learning Representations (ICLR) , year =
Autoregressive Diffusion Models , author =. International Conference on Learning Representations (ICLR) , year =
-
[68]
Scientific Reports , volume =
Protein language models enable accurate viral host range prediction , author =. Scientific Reports , volume =. 2026 , doi =
2026
-
[69]
PLOS ONE , volume =
Protein embeddings improve phage-host interaction prediction , author =. PLOS ONE , volume =. 2023 , doi =
2023
-
[70]
2026 , eprint=
Why Larger Models Learn More: Effects of Capacity, Interference, and Rare-Task Retention , author=. 2026 , eprint=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.