Cross-Head Attention Uplift Network with Inverse Propensity Score under Unobserved Confounding
Pith reviewed 2026-06-26 05:12 UTC · model grok-4.3
The pith
True propensity scores identify individual treatment effects even with unobserved confounders using cross-head attention.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
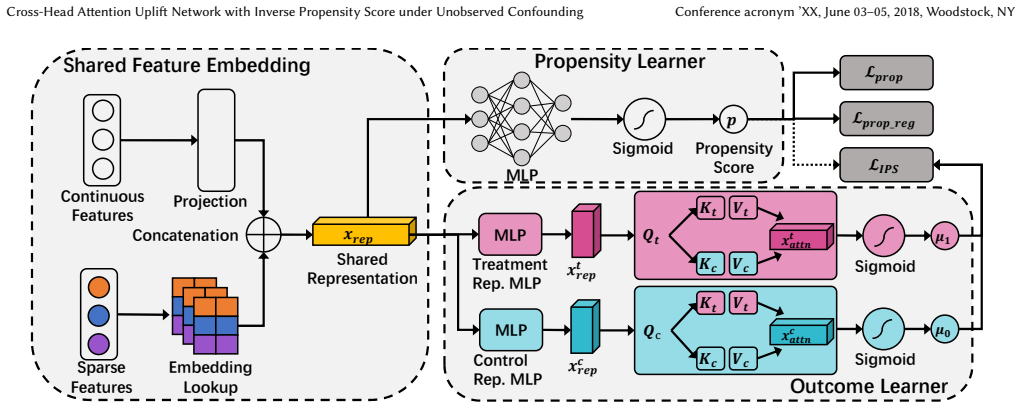
The paper establishes that the Cross-Head Attention Uplift Network with Robust Adversarial Inverse Propensity Score enables flexible inter-group correlation modeling and debiasing, with the key theoretical result that access to true propensity scores ensures identifiability of individual treatment effects even under unobserved confounding; RA-IPS performs adversarial optimization of propensity weights inside bounded uncertainty sets when true scores are unavailable.
What carries the argument
Cross-head attention operating on shared feature embeddings to integrate treatment-specific and control-specific representations, together with adversarial optimization of propensity weights inside constrained uncertainty sets.
If this is right
- Individual treatment effects remain identifiable when true propensity scores are known, even if unobserved confounders exist.
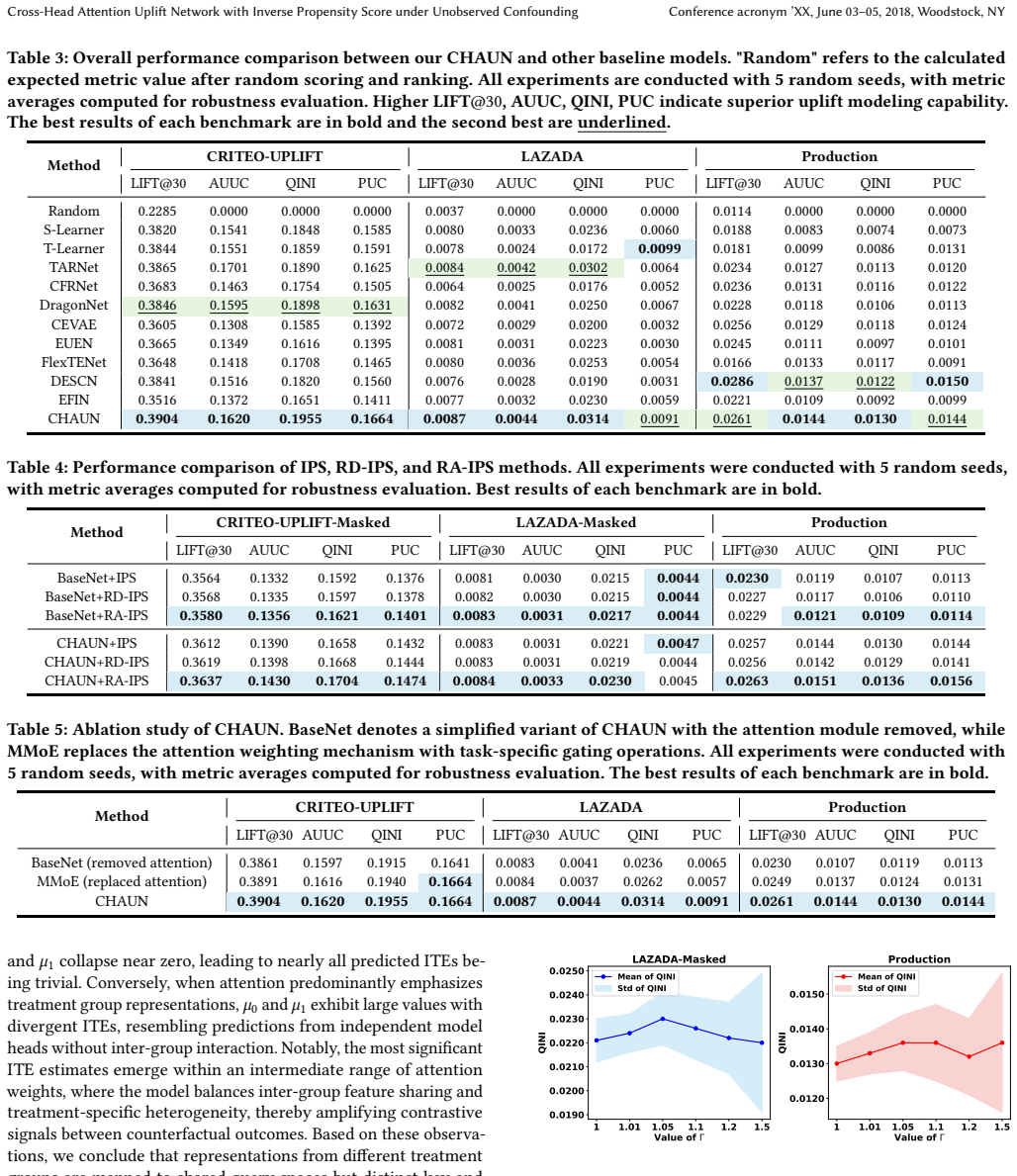
- The proposed network produces relative QINI score gains of up to 25.6 percent over prior uplift models on benchmark datasets.
- Robust Adversarial Inverse Propensity Score improves robustness by 5.4 percent over standard inverse propensity scoring under unobserved confounding.
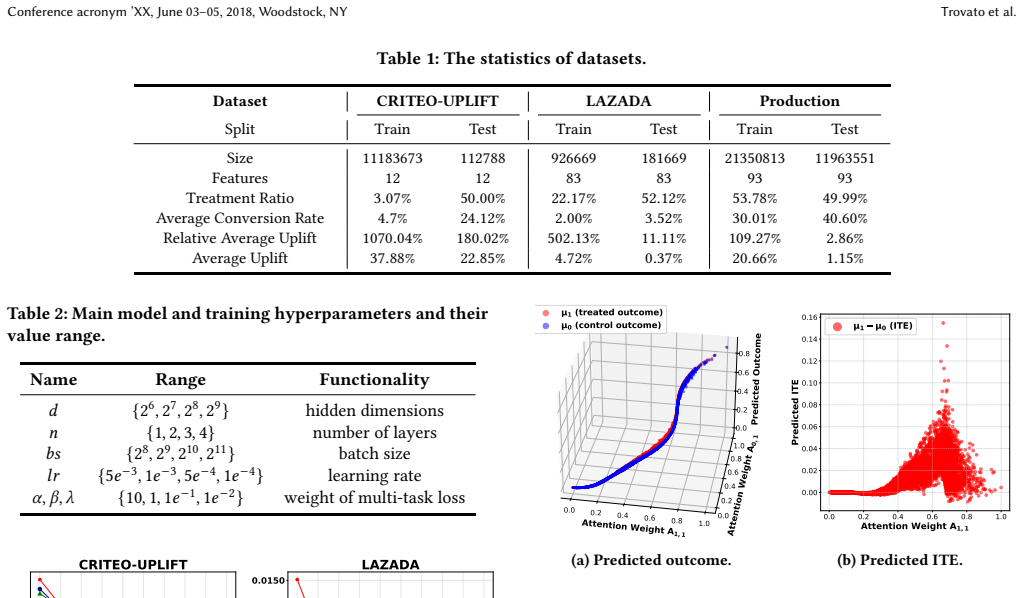
- The methods demonstrate effectiveness on both public uplift datasets and a large-scale e-commerce production dataset.
Where Pith is reading between the lines
- The cross-head attention component may transfer to multi-treatment or continuous-treatment causal settings beyond binary uplift.
- The identifiability result suggests testing the framework on domains such as medical treatment effects where hidden confounding is common.
- Combining the adversarial propensity component with other sensitivity-analysis techniques could further quantify remaining bias.
Load-bearing premise
The uncertainty sets used in adversarial propensity optimization are correctly specified and the cross-head attention recovers necessary inter-group correlations from observed covariates alone.
What would settle it
A controlled simulation supplying the true propensity scores yet showing that the network's individual treatment effect estimates fail to recover the known ground-truth effects when unobserved confounders are present would disprove the identifiability result.
Figures

read the original abstract
Uplift modeling, crucial for estimating individual treatment effects (ITE), faces dual challenges: flexibly leveraging inter-group similarity to enhance discriminative power and debiasing under unobserved confounding scenarios. In this paper, we propose the Cross-Head Attention Uplift Network (CHAUN) and Robust Adversarial Inverse Propensity Score (RA-IPS) method to address these limitations. CHAUN employs shared feature embeddings and cross-head attention mechanisms to dynamically integrate treatment-specific and control-specific representations, enhancing inter-group correlation modeling. Theoretically, we prove that access to the true propensity scores ensures ITE identifiability even with unobserved confounders. For practical scenarios lacking true propensity scores, RA-IPS adversarially optimizes propensity weights within constrained uncertainty sets to mitigate bias from unobserved variables. Experiments on public datasets (CRITEO-UPLIFT, LAZADA) and a production e-commerce dataset demonstrate CHAUN's superiority over state-of-the-art uplift models, achieving relative improvements of up to 25.6% in QINI scores. RA-IPS further enhances robustness, outperforming standard IPS by 5.4% under unobserved confounding. The results validate the effectiveness of our proposed methods in real-world causal inference tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Cross-Head Attention Uplift Network (CHAUN), which uses shared feature embeddings and cross-head attention to integrate treatment- and control-specific representations for improved inter-group correlation modeling in uplift/ITE estimation. It also introduces the Robust Adversarial Inverse Propensity Score (RA-IPS) method that adversarially optimizes propensity weights inside constrained uncertainty sets to reduce bias from unobserved confounders. The central theoretical claim is that access to true propensity scores guarantees ITE identifiability even under unobserved confounding; experiments on CRITEO-UPLIFT, LAZADA, and a production dataset report up to 25.6% relative QINI improvement over SOTA uplift models and 5.4% gain for RA-IPS over standard IPS.
Significance. If the identifiability result is non-circular and the uncertainty-set construction plus attention mechanism are correctly specified and recoverable from observed covariates, the work would offer a practical route to robust uplift modeling under partial observability. The reported numerical gains on public and production data would indicate utility for e-commerce applications. However, the manuscript provides no derivation steps, no explicit construction of the uncertainty sets or attention weights, and no error bars, so the significance cannot be assessed beyond the abstract-level claims.
major comments (3)
- [Abstract] Abstract: the claim of a 'theoretical proof' that true propensity scores ensure ITE identifiability under unobserved confounders is stated without any derivation steps, section reference, or equations, preventing verification of whether the result is load-bearing or reduces to a tautology.
- [Abstract] Abstract: the RA-IPS method is described as adversarially optimizing propensity weights 'within constrained uncertainty sets,' yet no definition, construction, or size of these sets is supplied; this is load-bearing for the robustness claim and the reported 5.4% gain over standard IPS.
- [Abstract] Abstract / Experiments: relative QINI improvements of up to 25.6% and the 5.4% RA-IPS gain are reported without error bars, variance estimates, or description of how the cross-head attention weights are computed from covariates alone, undermining the superiority claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and experimental presentation. We address each major comment below with references to the manuscript where applicable and indicate planned revisions for clarity.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of a 'theoretical proof' that true propensity scores ensure ITE identifiability under unobserved confounders is stated without any derivation steps, section reference, or equations, preventing verification of whether the result is load-bearing or reduces to a tautology.
Authors: The identifiability result is derived in Section 3.2 under the standard positivity and consistency assumptions, showing that true propensity scores allow recovery of the ITE via the cross-head attention structure even when unobserved confounders are present; the proof is not tautological because it explicitly uses the shared embedding and attention to bound the confounding bias. We will revise the abstract to include a reference to Section 3.2. revision: yes
-
Referee: [Abstract] Abstract: the RA-IPS method is described as adversarially optimizing propensity weights 'within constrained uncertainty sets,' yet no definition, construction, or size of these sets is supplied; this is load-bearing for the robustness claim and the reported 5.4% gain over standard IPS.
Authors: The uncertainty sets are constructed in Section 5.1 as ℓ_∞-balls of radius δ around the nominal propensity estimates, with δ chosen via cross-validation on a sensitivity parameter; the adversarial objective is the min-max problem in Equation (8). We will add a one-sentence definition and reference to Section 5.1 in the abstract. revision: yes
-
Referee: [Abstract] Abstract / Experiments: relative QINI improvements of up to 25.6% and the 5.4% RA-IPS gain are reported without error bars, variance estimates, or description of how the cross-head attention weights are computed from covariates alone, undermining the superiority claims.
Authors: The cross-head attention weights are obtained via scaled dot-product attention between the treatment and control heads as defined in Equation (3). We agree that error bars are needed and will report mean ± std over 5 random seeds for all QINI scores in the revised experiments section; the abstract will be updated to note this. revision: partial
Circularity Check
No significant circularity identified
full rationale
The abstract outlines a theoretical proof that true propensity scores ensure ITE identifiability under unobserved confounding, plus an empirical RA-IPS method and CHAUN architecture, but supplies no equations, proofs, or derivation steps. No self-definitional relations, fitted inputs renamed as predictions, or load-bearing self-citations are visible. The central claims therefore cannot be shown to reduce to their own inputs by construction; the derivation chain is not inspectable from the given text and appears self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Heejung Bang and James M. Robins. 2005. Doubly Robust Estimation in Missing Data and Causal Inference Models.Biometrics61 (2005)
2005
-
[2]
Min Cheng, Xinru Liao, Quanlian Liu, Bin Ma, Jian Xu, and Bo Zheng. 2022. Learning Disentangled Representations for Counterfactual Regression via Mutual Information Minimization.Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval(2022)
2022
-
[3]
Bénédicte Colnet, Imke Mayer, Guanhua Chen, Awa Dieng, Ruohong Li, Gaël Varoquaux, Jean-Philippe Vert, Julie Josse, and Shu Yang. 2024. Causal Inference Methods for Combining Randomized Trials and Observational Studies: A Review. Statist. Sci.39, 1 (2024), 165 – 191. doi:10.1214/23-STS889
-
[4]
Alicia Curth and Mihaela van der Schaar. 2021. On inductive biases for heteroge- neous treatment effect estimation(NIPS ’21). Curran Associates Inc., Red Hook, NY, USA, Article 1215, 12 pages
2021
-
[5]
Eustache Diemert, Artem Betlei, Christophe Renaudin, Massih-Reza Amini, Théo- phane Gregoir, and Thibaud Rahier. 2021. A Large Scale Benchmark for Individual Treatment Effect Prediction and Uplift Modeling. arXiv:2111.10106 [stat.ML]
arXiv 2021
-
[6]
Sihao Ding, Peng Wu, Fuli Feng, Yitong Wang, Xiangnan He, Yong Liao, and Yongdong Zhang. 2022. Addressing Unmeasured Confounder for Recommenda- tion with Sensitivity Analysis. InProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining(Washington DC, USA)(KDD ’22). Association for Computing Machinery, New York, NY, USA, 305–315
2022
-
[7]
Shuyang Du, James Lee, and Farzin Ghaffarizadeh. 2019. Improve User Retention with Causal Learning. InCD@KDD
2019
-
[8]
Jason Hartford, Greg Lewis, Kevin Leyton-Brown, and Matt Taddy. 2017. Deep IV: a flexible approach for counterfactual prediction(ICML’17). JMLR.org, 1414–1423
2017
-
[9]
Negar Hassanpour and Russell Greiner. 2020. Learning Disentangled Represen- tations for CounterFactual Regression. InInternational Conference on Learning Representations
2020
-
[10]
Miguel A. Hernan. 2024.Causal Inference: What If. Taylor & Francis, Boca Raton
2024
-
[11]
Yinqiu Huang, Shuli Wang, Min Gao, Xue Wei, Changhao Li, Chuan Luo, Yinhua Zhu, Xiong Xiao, and Yi Luo. 2024. Entire Chain Uplift Modeling with Context- Enhanced Learning for Intelligent Marketing. InCompanion Proceedings of the ACM Web Conference 2024(Singapore, Singapore)(WWW ’24). Association for Computing Machinery, New York, NY, USA, 226–234
2024
-
[12]
Imbens and Donald B
Guido W. Imbens and Donald B. Rubin. 2015.Causal Inference for Statistics, Social, and Biomedical Sciences: An Introduction. Cambridge University Press
2015
-
[13]
Johansson, Uri Shalit, and David Sontag
Fredrik D. Johansson, Uri Shalit, and David Sontag. 2016. Learning representations for counterfactual inference. InProceedings of the 33rd International Conference on International Conference on Machine Learning - Volume 48(New York, NY, USA) (ICML’16). JMLR.org, 3020–3029
2016
-
[14]
Nathan Kallus, Aahlad Manas Puli, and Uri Shalit. 2018. Removing hidden confounding by experimental grounding. InProceedings of the 32nd International Conference on Neural Information Processing Systems(Montréal, Canada)(NIPS’18). Curran Associates Inc., Red Hook, NY, USA, 10911–10920
2018
-
[15]
Yu, and Xiaoqiang Zhu
Wenwei Ke, Chuanren Liu, Xiangfu Shi, Yiqiao Dai, Philip S. Yu, and Xiaoqiang Zhu. 2021. Addressing Exposure Bias in Uplift Modeling for Large-scale Online Advertising. In2021 IEEE International Conference on Data Mining (ICDM). 1156– 1161
2021
-
[16]
Kingma and Jimmy Ba
Diederik P. Kingma and Jimmy Ba. 2015. Adam: A Method for Stochastic Opti- mization. In3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings. Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Trovato et al
2015
-
[17]
Künzel, Jasjeet S
Sören R. Künzel, Jasjeet S. Sekhon, Peter J. Bickel, and Bin Yu. 2017. Metalearners for estimating heterogeneous treatment effects using machine learning.Proceed- ings of the National Academy of Sciences of the United States of America116 (2017), 4156 – 4165
2017
-
[18]
Dugang Liu, Xing Tang, Han Gao, Fuyuan Lyu, and Xiuqiang He. 2023. Explicit Feature Interaction-aware Uplift Network for Online Marketing. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 4507–4515
2023
-
[19]
Christos Louizos, Uri Shalit, Joris Mooij, David Sontag, Richard Zemel, and Max Welling. 2017. Causal Effect Inference with Deep Latent-Variable Models. arXiv:1705.08821 [stat.ML]
Pith/arXiv arXiv 2017
-
[20]
Jiaqi Ma, Zhe Zhao, Xinyang Yi, Jilin Chen, Lichan Hong, and Ed H. Chi. 2018. Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture- of-Experts. InProceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining(London, United Kingdom)(KDD ’18). Association for Computing Machinery, 1930–1939
2018
-
[21]
Xiao Ma, Liqin Zhao, Guan Huang, Zhi Wang, Zelin Hu, Xiaoqiang Zhu, and Kun Gai. 2018. Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate(SIGIR ’18). Association for Computing Machinery, New York, NY, USA, 1137–1140
2018
-
[22]
Tchetgen Tchetgen
Wang Miao, Zhi Geng, and Eric J. Tchetgen Tchetgen. 2016. Identifying Causal Effects With Proxy Variables of an Unmeasured Confounder.Biometrika1054 (2016), 987–993
2016
-
[23]
2012.Foundations of Machine Learning
Mehryar Mohri, Afshin Rostamizadeh, and Ameet Talwalkar. 2012.Foundations of Machine Learning. The MIT Press
2012
-
[24]
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gre- gory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Kopf, Edward Yang, Zachary DeVito, Martin Rai- son, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. 2019. PyTorch: An Imperative Style, ...
2019
-
[25]
2009.Causality: Models, Reasoning and Inference
Judea Pearl. 2009.Causality: Models, Reasoning and Inference. Cambridge Univer- sity Press, USA
2009
-
[26]
2022.Detecting Latent Heterogeneity
Judea Pearl. 2022.Detecting Latent Heterogeneity. Association for Computing Machinery, New York, NY, USA
2022
-
[27]
Robins, Miguel A
James M. Robins, Miguel A. Hernán, and Babette A. Brumback. 2000. Marginal Structural Models and Causal Inference in Epidemiology.Epidemiology11 (2000), 550–560
2000
-
[28]
Rosenbaum and Donald B
Paul R. Rosenbaum and Donald B. Rubin. 1983. The Central Role of the Propensity Score in Observational Studies for Causal Effects.Biometrika70 (1983)
1983
-
[29]
Donald B Rubin. 2005. Causal Inference Using Potential Outcomes.J. Amer. Statist. Assoc.100, 469 (2005), 322–331
2005
-
[30]
Kara Rudolph, Nicholas Williams, and Ivan Diaz. 2024. Using instrumental vari- ables to address unmeasured confounding in causal mediation analysis.Biometrics 80 (01 2024)
2024
-
[31]
Yuta Saito, Suguru Yaginuma, Yuta Nishino, Hayato Sakata, and Kazuhide Nakata
-
[32]
InProceedings of the 13th International Conference on Web Search and Data Mining(Houston, TX, USA)(WSDM ’20)
Unbiased Recommender Learning from Missing-Not-At-Random Implicit Feedback. InProceedings of the 13th International Conference on Web Search and Data Mining(Houston, TX, USA)(WSDM ’20). Association for Computing Machinery, New York, NY, USA, 501–509
-
[33]
Tobias Schnabel, Adith Swaminathan, Ashudeep Singh, Navin Chandak, and Thorsten Joachims. 2016. Recommendations as treatments: debiasing learning and evaluation(ICML’16). JMLR.org, 1670–1679
2016
-
[34]
Shai Shalev-Shwartz and Shai Ben-David. 2013. Understanding Machine Learning: From Theory to Algorithms.Understanding Machine Learning: From Theory to Algorithms(01 2013). doi:10.1017/CBO9781107298019
-
[35]
Johansson, and David A
Uri Shalit, Fredrik D. Johansson, and David A. Sontag. 2016. Estimating indi- vidual treatment effect: generalization bounds and algorithms. InInternational Conference on Machine Learning
2016
-
[36]
Blei, and Victor Veitch
Claudia Shi, David M. Blei, and Victor Veitch. 2019.Adapting neural networks for the estimation of treatment effects. Curran Associates Inc., Red Hook, NY, USA
2019
-
[37]
Wei Sun, Pengyuan Wang, Dawei Yin, Jian Yang, and Yi Chang. 2015. Causal infer- ence via sparse additive models with application to online advertising(AAAI’15). 297–303
2015
-
[38]
Zexu Sun, Qiyu Han, Minqin Zhu, Hao Gong, Dugang Liu, and Chen Ma. 2025. Robust Uplift Modeling with Large-Scale Contexts for Real-time Marketing(KDD ’25). Association for Computing Machinery, New York, NY, USA, 1325–1336
2025
-
[39]
Eric J Tchetgen Tchetgen, Andrew Ying, Yifan Cui, Xu Shi, and Wang Miao. 2020. An Introduction to Proximal Causal Learning. arXiv:2009.10982 [stat.ME]
arXiv 2020
-
[40]
Thompson
Steven K. Thompson. 2012.Sampling. Wiley, Hoboken, N.J
2012
-
[41]
Anpeng Wu, Kun Kuang, Bo Li, and Fei Wu. 2022. Instrumental Variable Regres- sion with Confounder Balancing. InProceedings of the 39th International Confer- ence on Machine Learning (Proceedings of Machine Learning Research, Vol. 162), Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvari, Gang Niu, and Sivan Sabato (Eds.). PMLR, 24056–24075
2022
-
[42]
Zhiheng Zhang, Quanyu Dai, Xu Chen, Zhenhua Dong, and Ruiming Tang
-
[43]
InProceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval(Taipei, Taiwan)(SIGIR ’23)
Robust Causal Inference for Recommender System to Overcome Noisy Confounders. InProceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval(Taipei, Taiwan)(SIGIR ’23). Association for Computing Machinery, New York, NY, USA, 2349–2353
-
[44]
Kailiang Zhong, Fengtong Xiao, Yan Ren, Yaorong Liang, Wenqing Yao, Xiaofeng Yang, and Ling Cen. 2022. DESCN: Deep Entire Space Cross Networks for Individual Treatment Effect Estimation. InProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 4612–4620
2022
-
[45]
Dingyuan Zhu, Daixin Wang, Zhiqiang Zhang, Kun Kuang, Yan Zhang, Yulin Kang, and Jun Zhou. 2023. Graph Neural Network with Two Uplift Estimators for Label-Scarcity Individual Uplift Modeling. InProceedings of the ACM Web Conference 2023(Austin, TX, USA)(WWW ’23). Association for Computing Machinery, New York, NY, USA, 395–405
2023
-
[46]
Feng Zhu, Mingjie Zhong, Xinxing Yang, Longfei Li, Lu Yu, Tiehua Zhang, Jun Zhou, Chaochao Chen, Fei Wu, Guanfeng Liu, and Yan Wang. 2023. DCMT: A Direct Entire-Space Causal Multi-Task Framework for Post-Click Conversion Estimation.2023 IEEE 39th International Conference on Data Engineering (ICDE) (2023), 3113–3125
2023
-
[47]
Minqin Zhu, Zexu Sun, Ruoxuan Xiong, Anpeng Wu, Baohong Li, Caizhi Tang, Jun Zhou, Fei Wu, and Kun Kuang. 2025. Rethinking Causal Ranking: A Bal- anced Perspective on Uplift Model Evaluation. InProceedings of the 42nd In- ternational Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 267), Aarti Singh, Maryam Fazel, Daniel Hsu,...
2025
-
[48]
Yaochen Zhu, Yinhan He, Jing Ma, Mengxuan Hu, Sheng Li, and Jundong Li. 2024. Causal Inference with Latent Variables: Recent Advances and Future Prospectives. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining(Barcelona, Spain)(KDD ’24). Association for Computing Machinery, New York, NY, USA, 6677–6687. Received 20 Febr...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.