Rethinking Transfer Learning for Industrial Inspection: DINOv3 vs. ImageNet Pretraining Across RGB and X-ray Tasks
Pith reviewed 2026-05-25 04:33 UTC · model grok-4.3
The pith
DINOv3 pretraining outperforms ImageNet after full finetuning on RGB industrial inspection but not on X-ray or in frozen transfer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
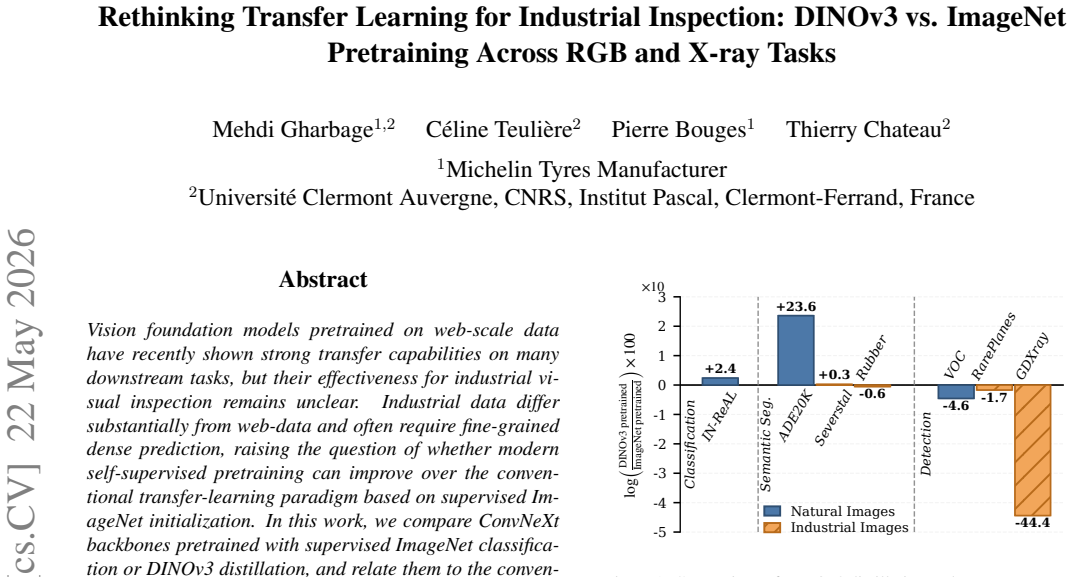
The paper claims that DINOv3 offers no clear advantage in frozen transfer, but provides a stronger initialization after full finetuning on RGB tasks, yielding faster convergence and better final performance. Under X-ray modality shift, however, supervised ImageNet pretraining remains more effective in both frozen and finetuned settings.
What carries the argument
ConvNeXt backbone initialized by either supervised ImageNet classification or DINOv3 distillation, transferred to downstream segmentation and detection tasks under frozen versus full-finetuning adaptation.
If this is right
- Full finetuning with DINOv3 initialization is preferable for RGB surface-defect inspection.
- Supervised ImageNet initialization should be retained for X-ray defect detection in both frozen and finetuned regimes.
- Frozen transfer shows comparable results between the two pretraining approaches across modalities.
- The value of modern vision foundation models for industrial inspection depends on both the target modality and the adaptation method used.
Where Pith is reading between the lines
- Industrial pipelines could select pretraining source according to whether the input modality matches the pretraining data distribution.
- The reported finetuning gains might shrink if training epochs or learning-rate schedules are constrained by compute budgets.
- Repeating the protocol on additional dense-prediction tasks outside defect detection would test whether the modality dependence generalizes.
Load-bearing premise
Observed performance differences are caused primarily by the pretraining choice rather than differences in hyperparameter tuning, exact dataset statistics, or backbone implementation details.
What would settle it
Running the same four datasets with identical hyperparameters, random seeds, and training schedules for both pretraining methods and finding no accuracy gap on RGB finetuning tasks would falsify the central claim.
Figures



read the original abstract
Vision foundation models pretrained on web-scale data have recently shown strong transfer capabilities on many downstream tasks, but their effectiveness for industrial visual inspection remains unclear. Industrial data differ substantially from web-data and often require fine-grained dense prediction, raising the question of whether modern self-supervised pretraining can improve over the conventional transfer-learning paradigm based on supervised ImageNet initialization. In this work, we compare ConvNeXt backbones pretrained with supervised ImageNet classification or DINOv3 distillation, and relate them to the conventional ResNet-50 baseline. We evaluate semantic segmentation, instance segmentation, and object detection across four downstream datasets spanning RGB surface-defect inspection and X-ray defect detection. We further study both frozen and fully finetuned adaptation regimes. Our results show that DINOv3 offers no clear advantage in frozen transfer, but provides a stronger initialization after full finetuning on RGB tasks, yielding faster convergence and better final performance. Under X-ray modality shift, however, supervised ImageNet pretraining remains more effective in both frozen and finetuned settings. Overall, our findings suggest that modern vision foundation models are promising for supervised RGB industrial inspection, but their transferability is strongly conditioned by downstream adaptation and target modality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript empirically compares ConvNeXt backbones initialized from DINOv3 self-supervised pretraining versus supervised ImageNet classification (plus a ResNet-50 baseline) for transfer to industrial inspection. It evaluates semantic segmentation, instance segmentation, and object detection on four datasets spanning RGB surface-defect and X-ray defect detection tasks, under both frozen-feature and full-finetuning regimes. The central claim is that DINOv3 yields no advantage in frozen transfer but provides faster convergence and higher final performance after finetuning on RGB tasks, while supervised ImageNet pretraining remains superior under X-ray modality shift in both regimes.
Significance. If the reported performance gaps are attributable to pretraining choice rather than uncontrolled experimental factors, the work supplies practical, modality-conditioned guidance for practitioners selecting initializations in industrial visual inspection. It usefully qualifies the transferability of recent web-scale self-supervised models to domain-shifted, fine-grained industrial settings.
major comments (2)
- [§4] §4 (Experimental Setup) and the associated tables: the manuscript does not state that identical optimizer schedules, learning-rate scaling, augmentation pipelines, and backbone implementation details were used for the ConvNeXt-DINOv3 and ConvNeXt-ImageNet variants. Without such controls, the attribution of RGB finetuning gains and X-ray deficits to the pretraining objective is not isolated from confounding implementation differences.
- [Table 2, Table 3] Table 2 (RGB finetuning results) and Table 3 (X-ray results): the reported margins (e.g., mIoU or AP deltas) lack error bars or statistical significance tests across multiple random seeds. This weakens the claim that DINOv3 is “stronger” or ImageNet “more effective” when the differences could be within run-to-run variance.
minor comments (2)
- [§1] The abstract and §1 refer to “four downstream datasets” without a table or paragraph justifying their coverage of defect size, imaging geometry, and class imbalance typical of industrial inspection.
- [§3] Notation for the two ConvNeXt variants is introduced inconsistently between §3 and the figure captions; a single consistent label (e.g., “ConvNeXt-DINOv3”) would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and have made revisions to improve clarity and transparency where possible.
read point-by-point responses
-
Referee: [§4] §4 (Experimental Setup) and the associated tables: the manuscript does not state that identical optimizer schedules, learning-rate scaling, augmentation pipelines, and backbone implementation details were used for the ConvNeXt-DINOv3 and ConvNeXt-ImageNet variants. Without such controls, the attribution of RGB finetuning gains and X-ray deficits to the pretraining objective is not isolated from confounding implementation differences.
Authors: We confirm that identical optimizer schedules, learning-rate scaling factors, augmentation pipelines, and backbone implementation details (including the ConvNeXt architecture configuration) were used for both the DINOv3 and ImageNet-initialized ConvNeXt variants; the sole difference was the source of the pretrained weights. We will revise §4 to explicitly document these shared controls, thereby isolating the effect of the pretraining objective. revision: yes
-
Referee: [Table 2, Table 3] Table 2 (RGB finetuning results) and Table 3 (X-ray results): the reported margins (e.g., mIoU or AP deltas) lack error bars or statistical significance tests across multiple random seeds. This weakens the claim that DINOv3 is “stronger” or ImageNet “more effective” when the differences could be within run-to-run variance.
Authors: We agree that multi-seed statistics would strengthen the claims. Due to the substantial computational cost of full finetuning on the industrial datasets, experiments were conducted with single random seeds. However, the observed margins are consistent in direction and magnitude across four datasets and three task types. We will add a limitations paragraph acknowledging the single-run reporting and noting that the trends hold across diverse modalities and tasks. revision: partial
Circularity Check
No circularity: direct empirical comparisons only
full rationale
The paper reports measured performance of ConvNeXt backbones under different pretraining regimes on four downstream datasets for segmentation and detection tasks. It contains no derivations, equations, fitted parameters renamed as predictions, uniqueness theorems, or ansatzes. All claims rest on observed metrics (convergence speed, final mAP/mIoU) rather than quantities defined by the paper's own formalism or reduced to self-citations. The work is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
https://www.kaggle.com/c/severstal-steel-defect-detection
Severstal: Steel Defect Detection. https://www.kaggle.com/c/severstal-steel-defect-detection. 4
-
[2]
Samet Akcay and Toby Breckon. Towards automatic threat detection: A survey of advances of deep learning within X-ray security imaging.Pattern Recognition, 122:108245,
-
[3]
Kundegorski, Michael Devereux, and Toby P
Samet Akc ¸ay, Mikolaj E. Kundegorski, Michael Devereux, and Toby P. Breckon. Transfer learning using convolutional neural networks for object classification within X-ray bag- gage security imagery. InICIP, pages 1057–1061. IEEE,
-
[4]
Self-Supervised Learning From Images With a Joint-Embedding Predictive Architecture
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bo- janowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-Supervised Learning From Images With a Joint-Embedding Predictive Architecture. InCVPR, pages 15619–15629, 2023. 2
work page 2023
-
[5]
VISION Datasets: A Benchmark for Vision-based InduStrial InspectiON, 2023
Haoping Bai, Shancong Mou, Tatiana Likhomanenko, Ra- mazan Gokberk Cinbis, Oncel Tuzel, Ping Huang, Jiulong Shan, Jianjun Shi, and Meng Cao. VISION Datasets: A Benchmark for Vision-based InduStrial InspectiON, 2023. 3
work page 2023
-
[6]
AdaCLIP: Adapt- ing CLIP with Hybrid Learnable Prompts for Zero-Shot Anomaly Detection
Yunkang Cao, Jiangning Zhang, Luca Frittoli, Yuqi Cheng, Weiming Shen, and Giacomo Boracchi. AdaCLIP: Adapt- ing CLIP with Hybrid Learnable Prompts for Zero-Shot Anomaly Detection. InECCV, pages 55–72, Cham, 2025. Springer Nature Switzerland. 3
work page 2025
-
[7]
Unsupervised Learning of Visual Features by Contrasting Cluster Assignments
Mathilde Caron, Ishan Misra, Julien Mairal, Priya Goyal, Pi- otr Bojanowski, and Armand Joulin. Unsupervised Learning of Visual Features by Contrasting Cluster Assignments. In NeurIPS, pages 9912–9924. Curran Associates, Inc., 2020. 2
work page 2020
-
[8]
Emerg- ing Properties in Self-Supervised Vision Transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv ´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerg- ing Properties in Self-Supervised Vision Transformers. In ICCV, pages 9650–9660, 2021. 2
work page 2021
-
[9]
A Simple Framework for Contrastive Learn- ing of Visual Representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Ge- offrey Hinton. A Simple Framework for Contrastive Learn- ing of Visual Representations. InProceedings of the 37th In- ternational Conference on Machine Learning, pages 1597–
-
[10]
Improved Baselines with Momentum Contrastive Learning,
Xinlei Chen, Haoqi Fan, Ross Girshick, and Kaiming He. Improved Baselines with Momentum Contrastive Learning,
-
[11]
Schwing, Alexan- der Kirillov, and Rohit Girdhar
Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexan- der Kirillov, and Rohit Girdhar. Masked-Attention Mask Transformer for Universal Image Segmentation. InCVPR, pages 1290–1299, 2022. 4
work page 2022
-
[12]
Yuqi Cheng, Yunkang Cao, Haiming Yao, Wei Luo, Cheng Jiang, Hui Zhang, and Weiming Shen. A comprehensive sur- vey for real-world industrial surface defect detection: Chal- lenges, approaches, and prospects.Journal of Manufacturing Systems, 84:152–172, 2026. 3
work page 2026
-
[13]
AnomalyDINO: Boosting Patch-based Few- Shot Anomaly Detection with DINOv2
Simon Damm, Mike Laszkiewicz, Johannes Lederer, and Asja Fischer. AnomalyDINO: Boosting Patch-based Few- Shot Anomaly Detection with DINOv2. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 1319–1329, 2025. 3
work page 2025
-
[14]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. InICLR, 2020. 4
work page 2020
-
[15]
Are Large-scale Datasets Necessary for Self-Supervised Pre-training?, 2021
Alaaeldin El-Nouby, Gautier Izacard, Hugo Touvron, Ivan Laptev, Herv´e Jegou, and Edouard Grave. Are Large-scale Datasets Necessary for Self-Supervised Pre-training?, 2021. 2, 7
work page 2021
-
[16]
Max Ferguson, Ronay Ak, Yung-Tsun Tina Lee, and Kin- cho H. Law. Automatic localization of casting defects with convolutional neural networks. In2017 IEEE International Conference on Big Data (Big Data), pages 1726–1735, 2017. 1, 5
work page 2017
- [17]
-
[18]
Bootstrap Your Own Latent - A New Approach to Self-Supervised Learning
Jean-Bastien Grill, Florian Strub, Florent Altch ´e, Corentin Tallec, Pierre Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Guo, Mohammad Ghesh- laghi Azar, Bilal Piot, koray kavukcuoglu, Remi Munos, and Michal Valko. Bootstrap Your Own Latent - A New Approach to Self-Supervised Learning. InNeurIPS, pages 21271–21284. Curran Ass...
work page 2020
-
[19]
De- tecting prohibited items in X-ray images: A contour proposal learning approach
Taimur Hassan, Meriem Bettayeb, Samet Akc ¸ay, Salman Khan, Mohammed Bennamoun, and Naoufel Werghi. De- tecting prohibited items in X-ray images: A contour proposal learning approach. InICIP, pages 2016–2020. IEEE, 2020. 3
work page 2016
-
[20]
Kaiming He, Georgia Gkioxari, Piotr Dollar, and Ross Gir- shick. Mask R-CNN. InICCV, pages 2961–2969, 2017. 4
work page 2017
-
[21]
Rethinking ImageNet Pre-Training
Kaiming He, Ross Girshick, and Piotr Dollar. Rethinking ImageNet Pre-Training. InICCV, pages 4918–4927, 2019. 1, 2, 3, 4, 5
work page 2019
-
[22]
Masked Autoencoders Are Scal- able Vision Learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Doll´ar, and Ross Girshick. Masked Autoencoders Are Scal- able Vision Learners. InCVPR, pages 16000–16009, 2022. 1, 2
work page 2022
-
[23]
AlignDet: Aligning Pre-training and Fine-tuning in Object Detection
Ming Li, Jie Wu, Xionghui Wang, Chen Chen, Jie Qin, Xue- feng Xiao, Rui Wang, Min Zheng, and Xin Pan. AlignDet: Aligning Pre-training and Fine-tuning in Object Detection. InICCV, pages 6866–6876, 2023. 7
work page 2023
-
[24]
Tongkun Liu, Bing Li, Xiao Jin, Yupeng Shi, Qiuying Li, and Xiang Wei. Exploring few-shot defect segmentation in general industrial scenarios with metric learning and vi- sion foundation models.Optics & Laser Technology, 192: 114078, 2025. 3, 4
work page 2025
-
[25]
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feicht- enhofer, Trevor Darrell, and Saining Xie. A ConvNet for the 2020s. InCVPR, pages 11976–11986, 2022. 2, 4, 5
work page 2022
-
[26]
GDXray: The Database of X-ray Images for Nondestructive Testing.J Nondestruct Eval, 34(4):42,
Domingo Mery, Vladimir Riffo, Uwe Zscherpel, German Mondrag´on, Iv ´an Lillo, Irene Zuccar, Hans Lobel, and Miguel Carrasco. GDXray: The Database of X-ray Images for Nondestructive Testing.J Nondestruct Eval, 34(4):42,
-
[27]
Maxime Oquab, Timoth ´ee Darcet, Th´eo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mido Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rab- bat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herve Jegou, Julien Mairal, Patr...
work page 2023
-
[28]
Learning Transferable Visual Models From Natural Language Supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning Transferable Visual Models From Natural Language Supervision. InProceedings of the 38th International Conference on Machine Learning, pages 8748–8763. PMLR, 2021
work page 2021
-
[29]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junt- ing Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao- Yuan Wu, Ross Girshick, Piotr Dollar, and Christoph Feicht- enhofer. SAM 2: Segment Anything in Images and Videos. InICLR, 2024. 1
work page 2024
-
[30]
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, San- jeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, and Li Fei-Fei. ImageNet Large Scale Visual Recognition Chal- lenge.Int J Comput Vis, 115(3):211–252, 2015. 1, 2, 3
work page 2015
-
[31]
RarePlanes: Synthetic Data Takes Flight
Jacob Shermeyer, Thomas Hossler, Adam Van Etten, Daniel Hogan, Ryan Lewis, and Daeil Kim. RarePlanes: Synthetic Data Takes Flight. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 207– 217, 2021. 4
work page 2021
-
[32]
Oriane Sim ´eoni, Huy V . V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Micha ¨el Ramamonjisoa, Francisco Massa, Daniel Haziza, Luca Wehrstedt, Jianyuan Wang, Timoth´ee Darcet, Th´eo Moutakanni, Leonel Sentana, Claire Roberts, Andrea Vedaldi, Jamie Tolan, John Brandt, Camille Couprie,...
work page 2025
-
[33]
Dense Contrastive Learning for Self-Supervised Visual Pre-Training
Xinlong Wang, Rufeng Zhang, Chunhua Shen, Tao Kong, and Lei Li. Dense Contrastive Learning for Self-Supervised Visual Pre-Training. InCVPR, pages 3024–3033, 2021. 2
work page 2021
-
[34]
Zihao Wang and Lei Wu. Theoretical Analysis of the Induc- tive Biases in Deep Convolutional Networks.NeurIPS, 36: 74289–74338, 2023. 4, 7
work page 2023
-
[35]
Yuxin Wu, Alexander Kirillov, Francisco Massa, Wan-Yen Lo, and Ross Girshick. Detectron2.https://github. com/facebookresearch/detectron2, 2019. 5
work page 2019
-
[36]
Hui-Yue Yang, Hui Chen, Ao Wang, Kai Chen, Zijia Lin, Yongliang Tang, Pengcheng Gao, Yuming Quan, Jungong Han, and Guiguang Ding. Promptable Anomaly Segmen- tation with SAM Through Self-Perception Tuning.AAAI, 39 (12):13017–13025, 2025. 3
work page 2025
-
[37]
Shuxuan Zhao, Sichao Liu, Yishuo Jiang, Bo Zhao, Youlong Lv, Jie Zhang, Lihui Wang, and Ray Y . Zhong. Industrial Foundation Models (IFMs) for intelligent manufacturing: A systematic review.Journal of Manufacturing Systems, 82: 420–448, 2025. 3
work page 2025
-
[38]
Image BERT Pre-training with Online Tokenizer
Jinghao Zhou, Chen Wei, Huiyu Wang, Wei Shen, Cihang Xie, Alan Yuille, and Tao Kong. Image BERT Pre-training with Online Tokenizer. InICLR, 2021. 2
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.