Partially Observable Adversarial Patch Attacks on Vision-Language-Action Models in Robotics
Pith reviewed 2026-06-28 09:58 UTC · model grok-4.3
The pith
Adversarial patches generated from a short trajectory prefix can still cause long-horizon failures in vision-language-action robot models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
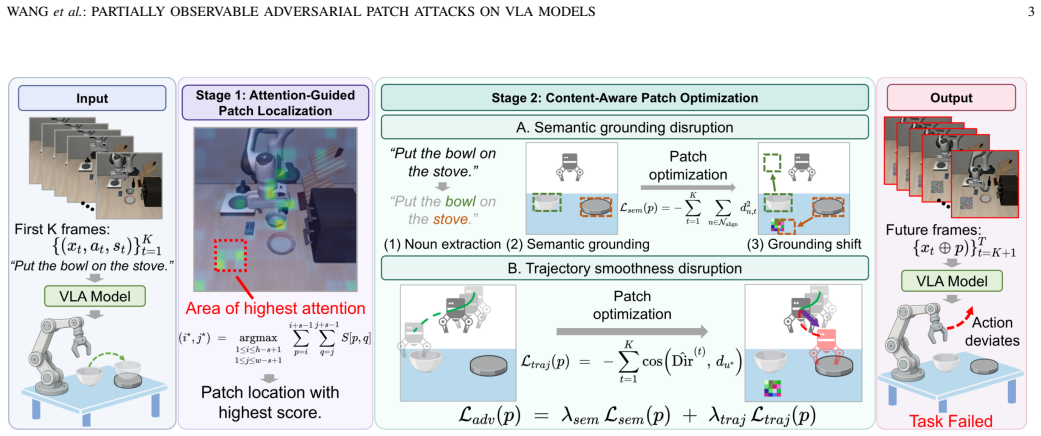
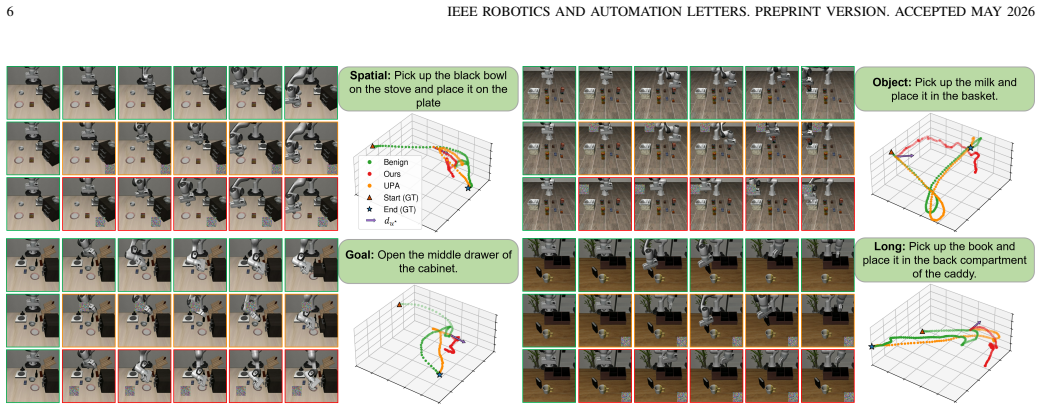
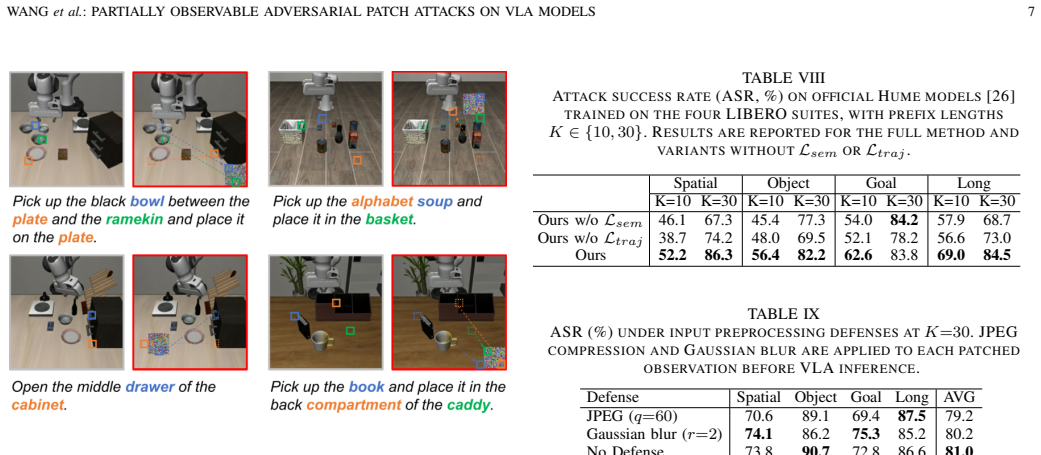
The paper claims that under a threat model limited to a short prefix of the trajectory, a single fixed patch can be produced via attention-map localization of instruction-critical regions followed by optimization that simultaneously disrupts target-object semantic grounding and raises action-trajectory curvature, thereby producing compounding perception and control errors that persist across subsequent frames and measurably lower task success rates in simulation and real-world robot trials.
What carries the argument
The two-phase framework that localizes the patch with attention maps corresponding to the full instruction and then optimizes it to break semantic grounding while increasing action curvature.
If this is right
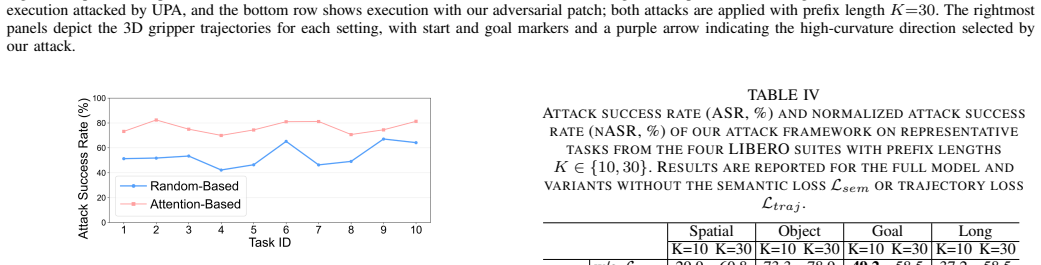
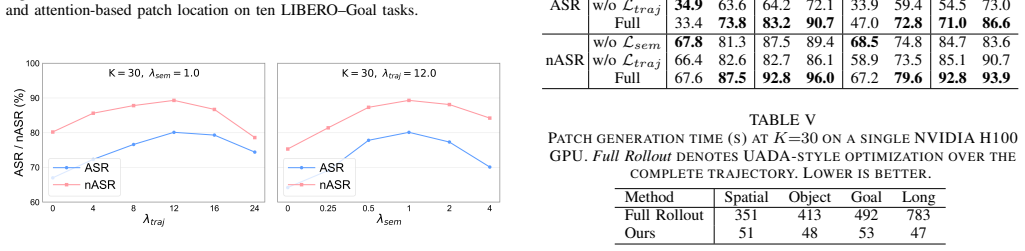
- Task success rates fall substantially when the fixed patch is applied throughout execution.
- Disruptions compound over long horizons even though the patch never changes after the prefix.
- Failures arise from simultaneous breaks in object perception and in the smoothness of generated actions.
- The attack succeeds without requiring access to the complete future trajectory.
Where Pith is reading between the lines
- Robot safety testing may need to include early-trajectory patch injection as a standard evaluation case.
- Attention-map inspection during deployment could serve as an early-warning signal for ongoing attacks.
- The same localization-plus-curvature approach might transfer to other multimodal control models that rely on visual-language grounding.
Load-bearing premise
The attacker is restricted to a short initial segment of the trajectory yet must produce one unchanging patch that affects every later frame.
What would settle it
A controlled trial in which patches generated from the short-prefix method produce no measurable drop in task success rates compared with clean runs, either in simulation or on physical robots, would falsify the central claim.
Figures


read the original abstract
Vision-language-action (VLA) models are gaining attention in robotics, yet their robustness to adversarial attacks remains largely unexplored. Existing work shows that adversarial patches can mislead VLA-based robots but assumes full access to the entire execution trajectory, an unrealistic requirement in practice. We address this limitation by formulating a partially observable threat model, where the adversary can exploit only a short prefix of the trajectory to generate a fixed patch applied to all subsequent frames. Under this setting, we propose a two-phase framework. First, we localize the patch using the model's attention maps to identify visually critical regions that correspond to the full instruction. Then, we optimize the patch to disrupt the semantic grounding of target objects and increase the curvature of action trajectories, thereby compounding failures in both perception and control. Extensive experiments in simulation and real-world robotic environments show that our method sustains adversarial effects under partial observability, inducing long-horizon disruptions and significantly reducing task success rates.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that existing adversarial patch attacks on VLA models assume full trajectory access, which is unrealistic. It introduces a partially observable threat model limited to a short prefix of the trajectory for generating a fixed patch applied to subsequent frames. A two-phase framework is proposed: attention-map localization of the patch to critical regions, followed by optimization to disrupt semantic grounding of target objects and increase action-trajectory curvature to compound long-horizon failures. Extensive simulation and real-world experiments are said to show sustained adversarial effects and significantly reduced task success rates under this constraint.
Significance. If the central claim holds under the stated threat model, the work is significant for identifying practical vulnerabilities in emerging VLA-based robotic systems and for proposing a concrete attack construction that respects partial observability. The attention-based localization combined with curvature-driven optimization represents a technical contribution that could inform both attack and defense research in embodied AI.
major comments (2)
- [Abstract] Abstract and threat-model description: the optimization objective of increasing the curvature of action trajectories is a long-horizon property of the closed-loop action sequence. It is unclear how this loss can be computed or differentiated from only a short prefix without additional forward passes, unrolled simulation, or future-state queries. This directly affects whether the reported success under partial observability is consistent with the stated threat model.
- [Abstract] Abstract: the claim of 'significantly reducing task success rates' and 'extensive experiments' is asserted without any quantitative metrics, baselines, error bars, or statistical details. Because the central empirical claim cannot be evaluated from the provided text, the strength of evidence for the partial-observability result remains unevaluable.
minor comments (1)
- [Abstract] Abstract would be strengthened by inclusion of at least one key quantitative result (e.g., success-rate drop and comparison to full-observability baseline) to allow readers to gauge effect size immediately.
Simulated Author's Rebuttal
Thank you for the detailed review. We appreciate the opportunity to clarify the consistency of our threat model and to strengthen the presentation of our empirical results. We address each major comment below and will make the necessary revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and threat-model description: the optimization objective of increasing the curvature of action trajectories is a long-horizon property of the closed-loop action sequence. It is unclear how this loss can be computed or differentiated from only a short prefix without additional forward passes, unrolled simulation, or future-state queries. This directly affects whether the reported success under partial observability is consistent with the stated threat model.
Authors: We thank the referee for highlighting this important point. In our two-phase framework, the curvature loss is approximated during optimization by performing a limited number of unrolled forward passes through the VLA model itself, using the model's predicted actions to simulate subsequent states within the known prefix context. This does not require access to real future states from the environment or additional trajectory data beyond the initial prefix, thereby preserving the partial observability constraint. We will revise the manuscript to explicitly describe this model-based unrolling procedure in the methods section to ensure clarity. revision: yes
-
Referee: [Abstract] Abstract: the claim of 'significantly reducing task success rates' and 'extensive experiments' is asserted without any quantitative metrics, baselines, error bars, or statistical details. Because the central empirical claim cannot be evaluated from the provided text, the strength of evidence for the partial-observability result remains unevaluable.
Authors: We agree that the abstract would benefit from including key quantitative results to better support our claims. The full paper contains detailed experimental results with metrics, baselines, and statistical analysis in Sections 4 and 5. In the revised manuscript, we will update the abstract to include specific quantitative findings, such as the reduction in task success rates along with mention of baselines and error bars. revision: yes
Circularity Check
No circularity: new threat model and two-phase framework presented as independent construction
full rationale
The paper formulates a partially observable threat model (short prefix only) and proposes a two-phase attack (attention-based localization then optimization for semantic disruption and trajectory curvature) without any equations, fitted parameters, or self-citations that reduce the central claims to their own inputs by construction. No derivation chain is claimed that loops back; the method is explicitly positioned as addressing a limitation of prior full-trajectory work. This matches the default expectation of a self-contained new construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Openvla: An open- source vision-language-action model,
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi,et al., “Openvla: An open- source vision-language-action model,” inCoRL, 2024
2024
-
[2]
π0: A vision-language-action flow model for general robot control,
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter,et al., “π0: A vision-language-action flow model for general robot control,” inRSS, 2025
2025
-
[3]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huang,et al., “Gr00t n1: An open foundation model for generalist humanoid robots,”arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Are we ready for service robots? the openloris- scene datasets for lifelong slam,
X. Shi, D. Li, P. Zhao, Q. Tian, Y . Tian, Q. Long, C. Zhu, J. Song, F. Qiao, L. Song,et al., “Are we ready for service robots? the openloris- scene datasets for lifelong slam,” inICRA, 2020, pp. 3139–3145
2020
-
[5]
A framework for end-user instruction of a robot assistant for manufacturing,
K. R. Guerin, C. Lea, C. Paxton, and G. D. Hager, “A framework for end-user instruction of a robot assistant for manufacturing,” inICRA, 2015, pp. 6167–6174
2015
-
[6]
Intriguing properties of neural networks,
C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus, “Intriguing properties of neural networks,” inICLR, 2014
2014
-
[7]
Explaining and harnessing adversarial examples,
I. J. Goodfellow, J. Shlens, and C. Szegedy, “Explaining and harnessing adversarial examples,” inICLR, 2015
2015
-
[8]
Exploring the adversarial vulnerabilities of vision- language-action models in robotics,
T. Wang, C. Han, J. C. Liang, W. Yang, D. Liu, L. X. Zhang, Q. Wang, J. Luo, and R. Tang, “Exploring the adversarial vulnerabilities of vision- language-action models in robotics,” inICCV, 2025
2025
-
[9]
Robotics cyber security: Vulnerabilities, attacks, countermeasures, and recommen- dations,
J.-P. A. Yaacoub, H. N. Noura, O. Salman, and A. Chehab, “Robotics cyber security: Vulnerabilities, attacks, countermeasures, and recommen- dations,”International Journal of Information Security, vol. 21, no. 1, pp. 115–158, 2022
2022
-
[10]
De- tection of cyber-attacks to indoor real time localization systems for autonomous robots,
´A. M. Guerrero-Higueras, N. DeCastro-Garc ´ıa, and V . Matell´an, “De- tection of cyber-attacks to indoor real time localization systems for autonomous robots,”Robotics and Autonomous Systems, vol. 99, pp. 75–83, 2018
2018
-
[11]
Security for the robot operating system,
B. Dieber, B. Breiling, S. Taurer, S. Kacianka, S. Rass, and P. Schartner, “Security for the robot operating system,”Robotics and Autonomous Systems, vol. 98, pp. 192–203, 2017
2017
-
[12]
Tros: Protecting humanoids ros from privileged attackers,
G. Mazzeo and M. Staffa, “Tros: Protecting humanoids ros from privileged attackers,”International Journal of Social Robotics, vol. 12, no. 3, pp. 827–841, 2020
2020
-
[13]
Characterizing physical adversarial attacks on robot motion planners,
W. Wu, F. Pierazzi, Y . Du, and M. Brand ˜ao, “Characterizing physical adversarial attacks on robot motion planners,” inICRA, 2024, pp. 14 319–14 325
2024
-
[14]
Physical and digital adversarial attacks on grasp quality networks,
N. W. Alharthi and M. Brand ˜ao, “Physical and digital adversarial attacks on grasp quality networks,” inICRA, 2024, pp. 1907–1912
2024
-
[15]
Adversarial grasp objects,
D. Wang, D. Tseng, P. Li, Y . Jiang, M. Guo, M. Danielczuk, J. Mahler, J. Ichnowski, and K. Goldberg, “Adversarial grasp objects,” inCASE, 2019, pp. 241–248
2019
-
[16]
Advgrasp: Adversarial attacks on robotic grasping from a physical perspective,
X. Wang, M. Han, T. Hao, C. Li, Y . Zhao, and K. Tang, “Advgrasp: Adversarial attacks on robotic grasping from a physical perspective,” in IJCAI, 2025, pp. 547–555
2025
-
[17]
Adversary is on the road: Attacks on visual SLAM using unnoticeable adversarial patch,
B. Chen, W. Wang, P. Sikorski, and T. Zhu, “Adversary is on the road: Attacks on visual SLAM using unnoticeable adversarial patch,” inUSENIX Security, 2024, pp. 6345–6362
2024
-
[18]
Adversarial attacks on robotic vision language action models,
E. K. Jones, A. Robey, A. Zou, Z. Ravichandran, G. J. Pappas, H. Hassani, M. Fredrikson, and J. Z. Kolter, “Adversarial attacks on robotic vision language action models,” inRSS Workshop, 2025
2025
-
[19]
Badrobot: Jailbreaking embodied llm agents in the physical world,
H. Zhang, C. Zhu, X. Wang, Z. Zhou, C. Yin, M. Li, L. Xue, Y . Wang, S. Hu, A. Liu,et al., “Badrobot: Jailbreaking embodied llm agents in the physical world,” inICLR, 2025
2025
-
[20]
Exploring the robustness of decision-level through adversarial attacks on llm-based embodied models,
S. Liu, J. Chen, S. Ruan, H. Su, and Z. Yin, “Exploring the robustness of decision-level through adversarial attacks on llm-based embodied models,” inACM MM, 2024, pp. 8120–8128
2024
-
[21]
Badvla: To- wards backdoor attacks on vision-language-action models via objective- decoupled optimization,
X. Zhou, G. Tie, G. Zhang, H. Wang, P. Zhou, and L. Sun, “Badvla: To- wards backdoor attacks on vision-language-action models via objective- decoupled optimization,” inNeurIPS, 2025
2025
-
[22]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly,et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” inICLR, 2021
2021
-
[23]
The coordination of arm movements: An exper- imentally confirmed mathematical model,
T. Flash and N. Hogan, “The coordination of arm movements: An exper- imentally confirmed mathematical model,”The Journal of Neuroscience, vol. 5, no. 7, pp. 1688–1703, 1985
1985
-
[24]
A technique for time-jerk optimal planning of robot trajectories,
A. Gasparetto and V . Zanotto, “A technique for time-jerk optimal planning of robot trajectories,”Robotics and Computer-Integrated Man- ufacturing, vol. 24, no. 3, pp. 415–426, 2008
2008
-
[25]
Libero: Benchmarking knowledge transfer for lifelong robot learning,
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone, “Libero: Benchmarking knowledge transfer for lifelong robot learning,”NeurIPS, vol. 36, pp. 44 776–44 791, 2023
2023
-
[26]
Hume: Introducing system-2 thinking in visual-language-action model,
H. Song, D. Qu, Y . Yao, Q. Chen, X. Ye, Q. Lv, X. Gao, G. Ren, M. Yao, B. Zhao, D. Wang, and X. Li, “Hume: Introducing system-2 thinking in visual-language-action model,” inCVPR, 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.