FastDSAC: Enhancing Policy Plasticity via Constrained Exploration for Scalable Humanoid Locomotion
Pith reviewed 2026-07-01 05:26 UTC · model grok-4.3
The pith
FastDSAC stabilizes training and accelerates convergence in humanoid locomotion by approximating policies with a truncated Gaussian that preserves network plasticity under high update rates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FastDSAC replaces the standard policy in Distributional Actor-Critic with a truncated Gaussian that excludes actions lying outside the support of the current value function. This constraint functions as implicit regularization against the plasticity degradation induced by aggressive gradient steps at high update-to-data ratios. A continuous Gaussian representation with adaptive variance further refines value estimates by focusing on confident transitions, in contrast to discrete distribution methods. On MuJoCo Playground and HumanoidBench the resulting algorithm stabilizes training, reaches higher asymptotic performance, and converges faster than prior state-of-the-art methods.
What carries the argument
Truncated Gaussian policy approximation that excludes out-of-distribution actions to provide implicit regularization while retaining exploration noise.
If this is right
- Training remains stable when data volume and update frequency both increase.
- Asymptotic performance exceeds that of current baselines on MuJoCo Playground and HumanoidBench.
- Convergence occurs in fewer environment steps under high update-to-data conditions.
- Sample efficiency rises because fewer updates are wasted on out-of-distribution actions.
- Value estimates become more accurate by preferentially sampling confident transitions from the continuous distribution.
Where Pith is reading between the lines
- The same truncation idea could be ported to other actor-critic algorithms that suffer plasticity loss in large-scale parallel training.
- Explicit regularization schedules might become less necessary if the policy distribution itself supplies the constraint.
- The continuous representation may transfer to non-locomotion continuous-control domains where value estimation accuracy limits scaling.
Load-bearing premise
Truncating the Gaussian removes enough harmful actions to protect value estimation without stripping away the stochasticity required for effective exploration and that this truncation reliably serves as regularization against plasticity loss.
What would settle it
A controlled ablation that keeps every other component identical but removes the truncation (i.e., samples from the full Gaussian) at the same high update-to-data ratio; instability or slower convergence in that run would falsify the claim that truncation is the key stabilizer.
Figures
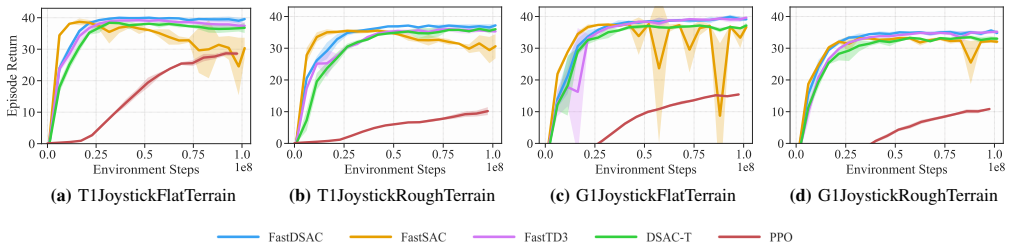
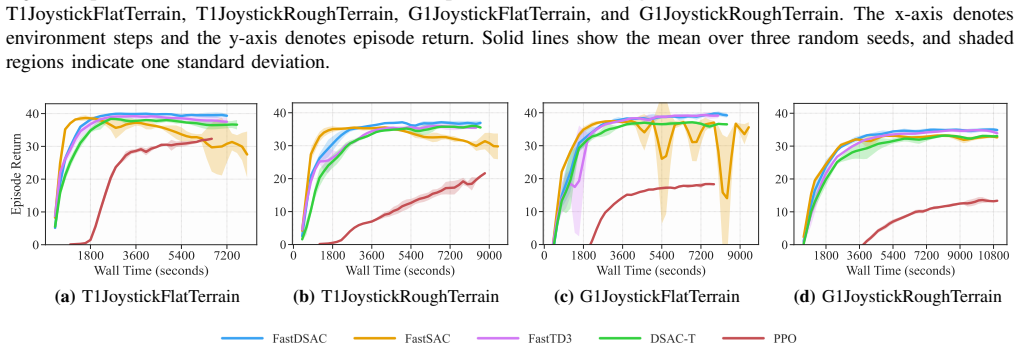
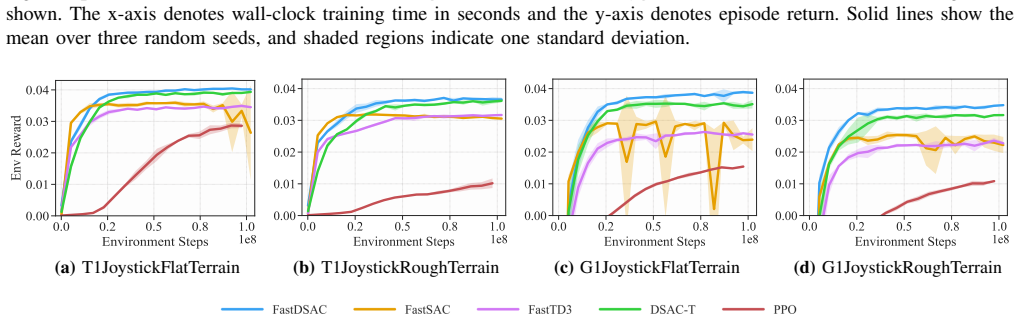
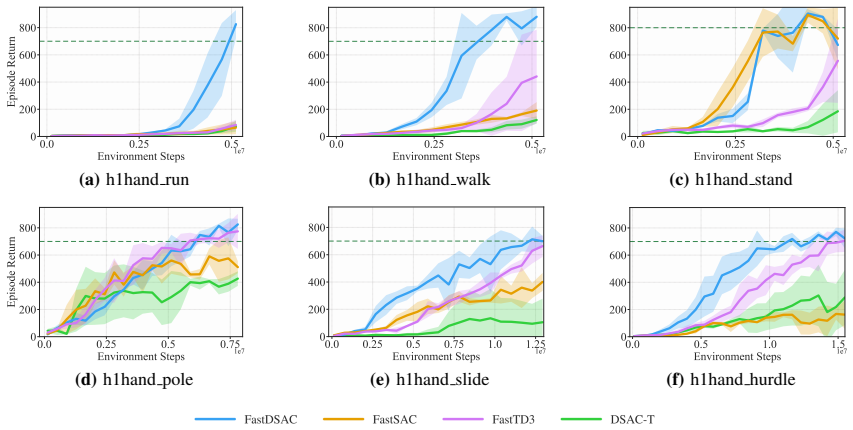




read the original abstract
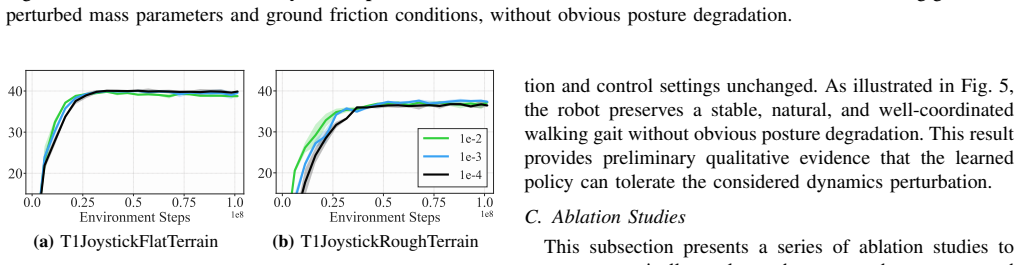
Scalable reinforcement learning has popularized high-throughput sampling architectures, which significantly compresses the training time for off-policy methods in robotic locomotion. However, the rapid increase of data volume and update frequency undermines the stability of value-based methods and diminishes the plasticity of policy networks. To address these challenges, this work presents FastDSAC, a fast and high-performance variant of the Distributional Actor-Critic algorithm designed for parallel sampling scenarios. Specifically, we introduce a truncated Gaussian distribution to approximate the learned policy, which effectively excludes out-of-distribution actions that strain target value estimation while keeping necessary stochasticity for exploration. The proposed action constraint functions as an implicit regularization, which counteracts the plasticity loss typically caused by aggressive gradient updates. This preservation of network adaptability enhances sample efficiency, particularly in scenarios with a high update-to-data ratio, and accelerates the early training process. In contrast to prior fast reinforcement learning approaches that rely on discrete value distributions, our method utilizes a continuous Gaussian representation equipped with adaptive variance regulation, which improves value estimation accuracy by sampling confident and informative transitions. Extensive experiments on MuJoCo Playground and HumanoidBench demonstrate that FastDSAC not only stabilizes the overall training process but also achieves superior asymptotic performance and faster convergence compared to state-of-the-art baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FastDSAC, a variant of Distributional Actor-Critic for high-throughput off-policy RL in humanoid locomotion. It replaces the standard Gaussian policy with a truncated Gaussian (bounded support) paired with adaptive variance regulation; the truncation is argued to exclude OOD actions that destabilize target-value estimation while retaining exploration stochasticity, thereby acting as implicit regularization that preserves policy-network plasticity at high update-to-data ratios. Experiments on MuJoCo Playground and HumanoidBench are reported to show improved training stability, faster convergence, and superior asymptotic performance relative to prior fast RL baselines.
Significance. If the reported gains hold under controlled UTD ratios and the truncation mechanism is shown to be the causal factor, the approach offers a lightweight, continuous-distribution alternative to discrete-value-distribution methods for scaling sample-efficient locomotion learning. The explicit linkage of bounded policy support to plasticity preservation under aggressive gradient updates is a concrete contribution that could be adopted in other high-throughput robotic RL pipelines.
minor comments (2)
- [§4.2] §4.2 and Algorithm 1: the precise truncation bounds (e.g., how many standard deviations) and the adaptive-variance update rule are described only at a high level; adding the explicit functional form and a short derivation of why the resulting distribution remains a valid policy would improve reproducibility.
- [Table 2] Table 2 and Figure 4: the ablation isolating the truncation operator from the adaptive-variance component is not shown; a single additional row or panel would strengthen the claim that truncation is the primary source of plasticity preservation.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. The report correctly captures the core idea of using a truncated Gaussian policy as implicit regularization to preserve plasticity under high update-to-data ratios. No specific major comments were raised in the report.
Circularity Check
No significant circularity detected
full rationale
The paper introduces a truncated Gaussian policy as an action constraint that acts as implicit regularization to preserve plasticity under high UTD ratios. No equations, derivations, or self-citations are present in the provided abstract or description that reduce any central claim to a fitted input, self-definition, or prior author work by construction. The method is presented as a bounded-support modification paired with adaptive variance, with performance claims resting on external benchmark comparisons rather than internal re-labeling of inputs. The derivation chain is therefore self-contained against the stated assumptions and experiments.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Deepmimic: Example-guided deep reinforcement learning of physics-based char- acter skills,
X. B. Peng, P. Abbeel, S. Levine, and M. Van de Panne, “Deepmimic: Example-guided deep reinforcement learning of physics-based char- acter skills,”ACM Transactions On Graphics (TOG), vol. 37, no. 4, pp. 1–14, 2018
2018
-
[2]
Towards robust motion control in multi- source uncertain scenarios by robust policy iteration,
J. Li, L. Tao, W. Zou, Y . Zhang, B. Shuai, J. Duan, S. E. Li, H. Sun, Y . Wang, Y . Gaoet al., “Towards robust motion control in multi- source uncertain scenarios by robust policy iteration,”Communications in Transportation Research, vol. 5, p. 100191, 2025
2025
-
[3]
Isaac gym: High performance gpu-based physics simulation for robot learning,
V . Makoviychuk, L. Wawrzyniak, Y . Guo, M. Lu, K. Storey, M. Mack- lin, D. Hoeller, N. Rudin, A. Allshire, A. Handa, and G. State, “Isaac gym: High performance gpu-based physics simulation for robot learning,” inProceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks, 2021
2021
-
[4]
Learning to walk in minutes using massively parallel deep reinforcement learning,
N. Rudin, D. Hoeller, P. Reist, and M. Hutter, “Learning to walk in minutes using massively parallel deep reinforcement learning,” in Conference on robot learning. PMLR, 2022, pp. 91–100
2022
-
[5]
Parallelq- learning: Scaling off-policy reinforcement learning under massively parallel simulation,
Z. Li, T. Chen, Z.-W. Hong, A. Ajay, and P. Agrawal, “Parallelq- learning: Scaling off-policy reinforcement learning under massively parallel simulation,” inInternational Conference on Machine Learn- ing. PMLR, 2023, pp. 19 440–19 459
2023
-
[6]
Randomized ensembled double q-learning: Learning fast without a model,
X. Chen, C. Wang, Z. Zhou, and K. W. Ross, “Randomized ensembled double q-learning: Learning fast without a model,” inInternational Conference on Learning Representations, 2021
2021
-
[7]
Understanding and preventing capacity loss in reinforcement learning,
C. Lyle, M. Rowland, and W. Dabney, “Understanding and preventing capacity loss in reinforcement learning,” inInternational Conference on Learning Representations, 2022
2022
-
[8]
The primacy bias in deep reinforcement learning,
E. Nikishin, M. Schwarzer, P. D’Oro, P.-L. Bacon, and A. Courville, “The primacy bias in deep reinforcement learning,” inInternational Conference on Machine Learning. PMLR, 2022, pp. 16 828–16 847
2022
-
[9]
Deep reinforcement learning with plasticity injection,
E. Nikishin, J. Oh, G. Ostrovski, C. Lyle, R. Pascanu, W. Dabney, and A. Barreto, “Deep reinforcement learning with plasticity injection,” in Advances in Neural Information Processing Systems, 2023
2023
-
[10]
Human-level control through deep reinforcement learning,
V . Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski et al., “Human-level control through deep reinforcement learning,” nature, vol. 518, no. 7540, pp. 529–533, 2015
2015
-
[11]
Continuous control with deep reinforcement learning,
T. P. Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T. Erez, Y . Tassa, D. Sil- ver, and D. Wierstra, “Continuous control with deep reinforcement learning,” inInternational Conference on Learning Representations, 2016
2016
-
[12]
Off-policy deep reinforcement learning without exploration,
S. Fujimoto, D. Meger, and D. Precup, “Off-policy deep reinforcement learning without exploration,” inInternational conference on machine learning. PMLR, 2019, pp. 2052–2062
2019
-
[13]
Addressing function approxi- mation error in actor-critic methods,
S. Fujimoto, H. Hoof, and D. Meger, “Addressing function approxi- mation error in actor-critic methods,” inInternational conference on machine learning. PMLR, 2018, pp. 1587–1596
2018
-
[14]
Smoothed action value functions for learning gaussian policies,
O. Nachum, M. Norouzi, G. Tucker, and D. Schuurmans, “Smoothed action value functions for learning gaussian policies,” inProceedings of the 35th International Conference on Machine Learning (ICML), 2018
2018
-
[15]
Stabilizing off-policy q-learning via bootstrapping error reduction,
A. Kumar, J. Fu, G. Tucker, and S. Levine, “Stabilizing off-policy q-learning via bootstrapping error reduction,” inAdvances in Neural Information Processing Systems (NeurIPS), 2019
2019
-
[16]
Demonstrating MuJoCo playground,
K. Zakka, B. Tabanpour, Q. Liao, M. Haiderbhai, S. Holt, J. Y . Luo, A. Allshire, E. Frey, K. Sreenath, L. A. Kahrs, C. Sferrazza, Y . Tassa, and P. Abbeel, “Demonstrating MuJoCo playground,” inProceedings of Robotics: Science and Systems, Los Angeles, CA, USA, Jun. 2025
2025
-
[17]
Humanoid- Bench: Simulated humanoid benchmark for whole-body locomotion and manipulation,
C. Sferrazza, D.-M. Huang, X. Lin, Y . Lee, and P. Abbeel, “Humanoid- Bench: Simulated humanoid benchmark for whole-body locomotion and manipulation,” inProceedings of Robotics: Science and Systems, Delft, Netherlands, Jul. 2024
2024
-
[18]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[19]
Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor,
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor,” inInternational conference on machine learning. PMLR, 2018, pp. 1861–1870
2018
-
[20]
A distributional per- spective on reinforcement learning,
M. G. Bellemare, W. Dabney, and R. Munos, “A distributional per- spective on reinforcement learning,” inInternational conference on machine learning. PMLR, 2017, pp. 449–458
2017
-
[21]
Fasttd3: Simple, fast, and capable reinforcement learning for hu- manoid control,
Y . Seo, C. Sferrazza, H. Geng, M. Nauman, Z.-H. Yin, and P. Abbeel, “Fasttd3: Simple, fast, and capable reinforcement learning for hu- manoid control,”arXiv preprint arXiv:2505.22642, 2025
-
[22]
Learning sim-to-real humanoid locomotion in 15 minutes, 2025a
Y . Seo, C. Sferrazza, J. Chen, G. Shi, R. Duan, and P. Abbeel, “Learning sim-to-real humanoid locomotion in 15 minutes,”arXiv preprint arXiv:2512.01996, 2025
-
[23]
Understanding plasticity in neural networks,
C. Lyle, Z. Zheng, E. Nikishin, B. Avila Pires, R. Pascanu, and W. Dabney, “Understanding plasticity in neural networks,” inInterna- tional Conference on Machine Learning. PMLR, 2023, pp. 23 190– 23 211
2023
-
[24]
Dropout q-functions for doubly efficient reinforcement learning,
T. Hiraoka, T. Imagawa, T. Hashimoto, T. Onishi, and Y . Tsuruoka, “Dropout q-functions for doubly efficient reinforcement learning,” in International Conference on Learning Representations, 2022
2022
-
[25]
Distributional soft actor-critic with three refinements,
J. Duan, W. Wang, L. Xiao, J. Gao, S. E. Li, C. Liu, Y .-Q. Zhang, B. Cheng, and K. Li, “Distributional soft actor-critic with three refinements,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 5, pp. 3935–3946, 2025
2025
-
[26]
Controlling overestimation bias with truncated mixture of continuous distributional quantile critics,
A. Kuznetsov, P. Shvechikov, A. Grishin, and D. Vetrov, “Controlling overestimation bias with truncated mixture of continuous distributional quantile critics,” inInternational conference on machine learning. PMLR, 2020, pp. 5556–5566
2020
-
[27]
Improving deep reinforcement learning by reducing the chain effect of value and policy churn,
H. Tang and G. Berseth, “Improving deep reinforcement learning by reducing the chain effect of value and policy churn,” inAdvances in Neural Information Processing Systems (NeurIPS), 2024, neurIPS 2024 Poster. [Online]. Available: https://arxiv.org/abs/2409.04792
-
[28]
Stop regressing: Training value functions via classification for scalable deep rl,
J. Farebrother, J. Orbay, Q. Vuong, A. Ali Ta ¨ıga, Y . Chebotar, T. Xiao, A. Irpan, S. Levine, P. S. Castro, A. Faust, A. Kumar, and R. Agarwal, “Stop regressing: Training value functions via classification for scalable deep rl,” inProceedings of the 41st International Conference on Machine Learning (ICML), ser. Proceedings of Machine Learning Research (...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.