Verifying Intent and Harm: A Unified Defense Against LLM-Generated Threats
Pith reviewed 2026-06-26 01:08 UTC · model grok-4.3
The pith
A framework that jointly verifies prompt intent and response harm defends LLMs better than checking either alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
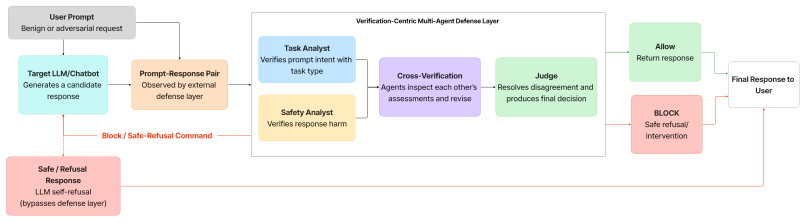
The verification-centric defense framework jointly evaluates prompt intent and response harm using specialized analysts and a Judge for conflict resolution, formalizing a threat model for prompt-response attacks and demonstrating superior performance on benchmarks for jailbreaks, prompt injection, phishing, cyber abuse, and harmful content.
What carries the argument
The verification-centric defense framework that employs specialized analysts for intent and harm assessment together with a Judge for conflict resolution.
Load-bearing premise
The specialized intent and harm analysts plus the Judge component can be implemented without creating new attack surfaces or systematically misclassifying benign but sensitive user requests, and that reported improvements will hold against adaptive attackers who know the structure.
What would settle it
An experiment in which attackers who know the full structure of the intent analyst, harm analyst, and Judge induce harmful outputs at rates well above 4.1 percent.
Figures

read the original abstract
Large language models (LLMs) are increasingly deployed in interactive applications, yet they remain vulnerable to adversarial interactions that induce harmful, deceptive, or policy-violating outputs. Existing defenses typically analyze either user prompts or generated outputs, but not both. However, many real-world attacks exploit a separation between adversarial intent expressed in the prompt and actionable harm manifested only in the response. As a result, prompt-only and response-only defenses frequently miss unsafe interactions that appear benign when viewed from either side in isolation. We present a verification-centric defense framework that jointly evaluates prompt intent and response harm before an LLM response is delivered to a user. The framework employs specialized analysts for intent and harm assessment together with a Judge for conflict resolution. We formalize a threat model for prompt-response attacks and evaluate the framework across five threat categories: jailbreaks, prompt injection, phishing, cyber abuse, and harmful content. Experiments on multiple benchmark datasets show that jointly verifying prompt intent and response harm consistently outperforms single-sided defenses and single-agent reasoning baselines. Across threat categories, the framework improves average F1 from 0.90 for the strongest applicable baselines to 0.95 while reducing the average attack success rate to 4.1 percent. Compared with a Single-Agent+CoT baseline, it improves average F1 from 0.87 to 0.95 and reduces the false positive rate on benign-sensitive requests from 0.12 to 0.06. We further evaluate architecture-aware adaptive attacks in which the attacker knows the verifier structure and attempts to bypass individual verification components. Our results suggest that prompt-response verification provides a practical foundation for securing LLM applications against evolving adversarial threats.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a verification-centric defense framework for LLMs that jointly assesses user prompt intent and generated response harm via specialized intent and harm analysts plus a Judge for conflict resolution. It formalizes a prompt-response threat model and evaluates the approach across five threat categories (jailbreaks, prompt injection, phishing, cyber abuse, harmful content) on multiple benchmark datasets. The central empirical claims are that the joint framework improves average F1 from 0.90 (strongest baselines) to 0.95, reduces average attack success rate to 4.1%, improves F1 from 0.87 to 0.95 versus Single-Agent+CoT, halves false-positive rate on benign-sensitive requests (0.12 to 0.06), and maintains these gains under architecture-aware adaptive attacks where the attacker knows the verifier structure.
Significance. If the empirical results prove robust, the work supplies a practical, architecture-aware defense that closes a documented gap between prompt-only and response-only methods. The explicit evaluation against adaptive attacks that target the multi-component design is a methodological strength that directly addresses a key deployment risk.
major comments (2)
- [Abstract and §5 (Experiments)] Abstract and §5 (Experiments): The abstract reports concrete F1 gains (0.90→0.95) and attack-success reductions (to 4.1%) together with comparisons to Single-Agent+CoT and false-positive rates on benign-sensitive requests, yet supplies no information on experimental design, dataset identities and splits, statistical significance tests, error bars, or how post-hoc modeling choices were made. Without these details the reported numbers cannot be independently verified and therefore cannot yet support the central claim of consistent outperformance across threat categories.
- [§5 (Experiments)] §5 (Experiments): The claim that architecture-aware adaptive attacks were evaluated across all five threat categories is load-bearing for the weakest-assumption concern (new attack surfaces created by the multi-component design). The manuscript must specify the exact attack strategies used against each analyst and the Judge, the success criteria applied, and whether any component was found to be a systematic weak point.
minor comments (2)
- [§3 (Threat Model)] The threat-model formalization would benefit from an explicit statement of the adversary's knowledge and capabilities (e.g., whether the attacker can query the analysts directly or only the final Judge).
- [Throughout] Notation for the intent and harm analysts and the Judge should be introduced once and used consistently; currently the abstract and later sections appear to use slightly varying terminology for the same components.
Simulated Author's Rebuttal
We thank the referee for these constructive comments on experimental transparency. We address each point below and will revise the manuscript accordingly to improve reproducibility.
read point-by-point responses
-
Referee: [Abstract and §5 (Experiments)] Abstract and §5 (Experiments): The abstract reports concrete F1 gains (0.90→0.95) and attack-success reductions (to 4.1%) together with comparisons to Single-Agent+CoT and false-positive rates on benign-sensitive requests, yet supplies no information on experimental design, dataset identities and splits, statistical significance tests, error bars, or how post-hoc modeling choices were made. Without these details the reported numbers cannot be independently verified and therefore cannot yet support the central claim of consistent outperformance across threat categories.
Authors: We agree that additional details are needed for independent verification. In the revised version we will expand the abstract to reference the evaluation protocol and update §5 with a dedicated subsection listing all dataset identities and splits, the number of runs for error bars, statistical significance tests (paired t-tests with p-values), and explicit post-hoc modeling decisions. These additions will directly support the reported F1 and attack-success figures without altering the empirical claims. revision: yes
-
Referee: [§5 (Experiments)] §5 (Experiments): The claim that architecture-aware adaptive attacks were evaluated across all five threat categories is load-bearing for the weakest-assumption concern (new attack surfaces created by the multi-component design). The manuscript must specify the exact attack strategies used against each analyst and the Judge, the success criteria applied, and whether any component was found to be a systematic weak point.
Authors: We acknowledge that greater specificity on the adaptive attacks would strengthen the architecture-aware evaluation. The revised §5 will enumerate the concrete attack strategies applied to the intent analyst, harm analyst, and Judge for each of the five threat categories, define the success criteria (e.g., evasion of detection while producing policy-violating output), and report any component-specific vulnerabilities or robustness observations. This will substantiate the claim that the joint framework remains effective under structure-aware attacks. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is an empirical systems paper that evaluates a multi-component defense framework on external benchmark datasets across five threat categories. No equations, derivations, fitted parameters, or self-citation chains are present that would reduce the reported F1 scores, attack-success rates, or false-positive rates to quantities defined in terms of the framework itself. The central claims rest on comparisons against independent baselines and datasets rather than any self-referential construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
On the opportunities and risks of foundation models,
R. Bommasani, D. A. Hudson, E. Adeli, R. Altman, S. Arora, S. von Arx, M. S. Bernstein, J. Bohg, A. Bosselut, E. Brunskillet al., “On the opportunities and risks of foundation models,”arXiv preprint arXiv:2108.07258, 2021. 13
Pith/arXiv arXiv 2021
-
[2]
Taxonomy of risks posed by language models,
L. Weidinger, J. Uesato, M. Rauh, C. Griffin, P.-S. Huang, J. Mellor, A. Glaese, M. Cheng, B. Balle, A. Kasirzadehet al., “Taxonomy of risks posed by language models,” inProceedings of the 2022 ACM conference on fairness, accountability, and transparency, 2022, pp. 214–229
2022
-
[3]
From chatbots to phishbots?: Phishing scam generation in commercial large language models,
S. S. Roy, P. Thota, K. V . Naragam, and S. Nilizadeh, “From chatbots to phishbots?: Phishing scam generation in commercial large language models,” in2024 IEEE Symposium on Security and Privacy (SP). IEEE, 2024, pp. 36–54
2024
-
[4]
Mocha: Are code language models robust against multi-turn malicious coding prompts?
M. Wahed, X. Zhou, K. A. Nguyen, T. Yu, N. Diwan, G. Wang, D. Hakkani-Tur, and I. Lourentzou, “Mocha: Are code language models robust against multi-turn malicious coding prompts?” inFind- ings of the Association for Computational Linguistics: EMNLP 2025, 2025, pp. 22 922–22 948
2025
-
[5]
Beavertails: Towards improved safety align- ment of llm via a human-preference dataset,
J. Ji, M. Liu, J. Dai, X. Pan, C. Zhang, C. Bian, B. Chen, R. Sun, Y . Wang, and Y . Yang, “Beavertails: Towards improved safety align- ment of llm via a human-preference dataset,”Advances in Neural Information Processing Systems, vol. 36, pp. 24 678–24 704, 2023
2023
-
[6]
Aegis2. 0: A diverse ai safety dataset and risks taxonomy for alignment of llm guardrails,
S. Ghosh, P. Varshney, M. N. Sreedhar, A. Padmakumar, T. Rebedea, J. R. Varghese, and C. Parisien, “Aegis2. 0: A diverse ai safety dataset and risks taxonomy for alignment of llm guardrails,” inNeurips Safe Generative AI Workshop 2024
2024
-
[7]
{JBShield}: Defending large language models from jailbreak attacks through activated concept analysis and manipulation,
S. Zhang, Y . Zhai, K. Guo, H. Hu, S. Guo, Z. Fang, L. Zhao, C. Shen, C. Wang, and Q. Wang, “{JBShield}: Defending large language models from jailbreak attacks through activated concept analysis and manipulation,” in34th USENIX Security Symposium (USENIX Security 25), 2025, pp. 8215–8234
2025
-
[8]
Autodefense: Multi-agent llm defense against jailbreak attacks,
Y . Zeng, Y . Wu, X. Zhang, H. Wang, and Q. Wu, “Autodefense: Multi-agent llm defense against jailbreak attacks,” inNeurips Safe Generative AI Workshop 2024
2024
-
[9]
Injecguard: Benchmarking and mitigating over-defense in prompt injection guardrail models,
H. Li and X. Liu, “Injecguard: Benchmarking and mitigating over-defense in prompt injection guardrail models,”arXiv preprint arXiv:2410.22770, 2024
arXiv 2024
-
[10]
Llama guard 3-1b- int4: Compact and efficient safeguard for human-ai conversations,
I. Fedorov, K. Plawiak, L. Wu, T. Elgamal, N. Suda, E. Smith, H. Zhan, J. Chi, Y . Hulovatyy, K. Patelet al., “Llama guard 3-1b- int4: Compact and efficient safeguard for human-ai conversations,” arXiv preprint arXiv:2411.17713, 2024
arXiv 2024
-
[11]
Shield- gemma: Generative ai content moderation based on gemma,
W. Zeng, Y . Liu, R. Mullins, L. Peran, J. Fernandez, H. Harkous, K. Narasimhan, D. Proud, P. Kumar, B. Radharapuet al., “Shield- gemma: Generative ai content moderation based on gemma,”arXiv preprint arXiv:2407.21772, 2024
Pith/arXiv arXiv 2024
-
[12]
Wildguard: Open one-stop moderation tools for safety risks, jailbreaks, and refusals of llms,
S. Han, K. Rao, A. Ettinger, L. Jiang, B. Y . Lin, N. Lambert, Y . Choi, and N. Dziri, “Wildguard: Open one-stop moderation tools for safety risks, jailbreaks, and refusals of llms,” inThe Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track
-
[13]
A holistic approach to undesired content detection in the real world,
T. Markov, C. Zhang, S. Agarwal, F. E. Nekoul, T. Lee, S. Adler, A. Jiang, and L. Weng, “A holistic approach to undesired content detection in the real world,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 12, 2023, pp. 15 009–15 018
2023
-
[14]
{SelfDefend}:{LLMs}can defend them- selves against jailbreaking in a practical manner,
X. Wang, D. Wu, Z. Ji, Z. Li, P. Ma, S. Wang, Y . Li, Y . Liu, N. Liu, and J. Rahmel, “{SelfDefend}:{LLMs}can defend them- selves against jailbreaking in a practical manner,” in34th USENIX Security Symposium (USENIX Security 25), 2025, pp. 2441–2460
2025
-
[15]
Llama prompt guard 2,
Meta, “Llama prompt guard 2,” 2025. [Online]. Avail- able: https://www.llama.com/docs/model-cards-and-prompt-formats/ prompt-guard/
2025
-
[16]
Harmbench: a standardized evaluation framework for automated red teaming and robust refusal,
M. Mazeika, L. Phan, X. Yin, A. Zou, Z. Wang, N. Mu, E. Sakhaee, N. Li, S. Basart, B. Liet al., “Harmbench: a standardized evaluation framework for automated red teaming and robust refusal,” inPro- ceedings of the 41st International Conference on Machine Learning, 2024, pp. 35 181–35 224
2024
-
[17]
How johnny can persuade llms to jailbreak them: Rethinking persuasion to challenge ai safety by humanizing llms,
Y . Zeng, H. Lin, J. Zhang, D. Yang, R. Jia, and W. Shi, “How johnny can persuade llms to jailbreak them: Rethinking persuasion to challenge ai safety by humanizing llms,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2024, pp. 14 322–14 350
2024
-
[18]
Jailbreaking leading safety-aligned llms with simple adaptive attacks,
M. Andriushchenko, F. Croce, and N. Flammarion, “Jailbreaking leading safety-aligned llms with simple adaptive attacks,” inICML 2024 Next Generation of AI Safety Workshop
2024
-
[19]
Not what you’ve signed up for: Compromising real- world llm-integrated applications with indirect prompt injection,
K. Greshake, S. Abdelnabi, S. Mishra, C. Endres, T. Holz, and M. Fritz, “Not what you’ve signed up for: Compromising real- world llm-integrated applications with indirect prompt injection,” in Proceedings of the 16th ACM Workshop on Artificial Intelligence and Security, 2023, pp. 79–90
2023
-
[20]
Ignore previous prompt: Attack techniques for language models,
F. Perez and I. Ribeiro, “Ignore previous prompt: Attack techniques for language models,” inNeurIPS ML Safety Workshop
-
[21]
Multiphishguard: An llm-based multi-agent system for phishing email detection,
Y . Xue, E. Spero, Y . S. Koh, and G. Russello, “Multiphishguard: An llm-based multi-agent system for phishing email detection,”arXiv preprint arXiv:2505.23803, 2025
Pith/arXiv arXiv 2025
-
[22]
S. Wan, C. Nikolaidis, D. Song, D. Molnar, J. Crnkovich, J. Grace, M. Bhatt, S. Chennabasappa, S. Whitman, S. Dinget al., “Cybersece- val 3: Advancing the evaluation of cybersecurity risks and capabilities in large language models,”arXiv preprint arXiv:2408.01605, 2024
arXiv 2024
-
[23]
BERT: Pre-training of deep bidirectional transformers for language understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” inProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), J. Burstein, C. Doran, and T. Solorio, Eds....
2019
-
[24]
Learning from the worst: Dynamically generated datasets to improve online hate detection,
B. Vidgen, T. Thrush, Z. Waseem, and D. Kiela, “Learning from the worst: Dynamically generated datasets to improve online hate detection,” inProceedings of the 59th Annual Meeting of the As- sociation for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), 2021, pp. 1667–1682
2021
-
[25]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, D. Zhouet al., “Chain-of-thought prompting elicits reasoning in large language models,”Advances in neural information processing systems, vol. 35, pp. 24 824–24 837, 2022
2022
-
[26]
Language models don’t always say what they think: Unfaithful explanations in chain- of-thought prompting,
M. Turpin, J. Michael, E. Perez, and S. Bowman, “Language models don’t always say what they think: Unfaithful explanations in chain- of-thought prompting,”Advances in Neural Information Processing Systems, vol. 36, pp. 74 952–74 965, 2023
2023
-
[27]
Self-critiquing models for assisting human evaluators,
W. Saunders, C. Yeh, J. Wu, S. Bills, L. Ouyang, J. Ward, and J. Leike, “Self-critiquing models for assisting human evaluators,” arXiv preprint arXiv:2206.05802, 2022
Pith/arXiv arXiv 2022
-
[28]
Improv- ing factuality and reasoning in language models through multiagent debate,
Y . Du, S. Li, A. Torralba, J. B. Tenenbaum, and I. Mordatch, “Improv- ing factuality and reasoning in language models through multiagent debate,” inForty-first International Conference on Machine Learning, 2023
2023
-
[29]
Encouraging divergent thinking in large language models through multi-agent debate,
T. Liang, Z. He, W. Jiao, X. Wang, Y . Wang, R. Wang, Y . Yang, S. Shi, and Z. Tu, “Encouraging divergent thinking in large language models through multi-agent debate,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024, pp. 17 889–17 904
2024
-
[30]
Generative agents: Interactive simulacra of human behavior,
J. S. Park, J. O’Brien, C. J. Cai, M. R. Morris, P. Liang, and M. S. Bernstein, “Generative agents: Interactive simulacra of human behavior,” inProceedings of the 36th annual acm symposium on user interface software and technology, 2023, pp. 1–22
2023
-
[31]
Communicative agents for software development,
C. Qian, X. Cong, C. Yang, W. Chen, Y . Su, J. Xu, Z. Liu, and M. Sun, “Communicative agents for software development,”arXiv preprint arXiv:2307.07924, vol. 6, no. 3, 2023
Pith/arXiv arXiv 2023
-
[32]
Camel: Communicative agents for
G. Li, H. Hammoud, H. Itani, D. Khizbullin, and B. Ghanem, “Camel: Communicative agents for” mind” exploration of large language model society,”Advances in Neural Information Processing Systems, vol. 36, pp. 51 991–52 008, 2023
2023
-
[33]
Autogen: Enabling next-gen llm applications via multi-agent conversation,
Q. Wu, G. Bansal, J. Zhang, Y . Wu, B. Li, E. Zhu, L. Jiang, X. Zhang, S. Zhang, J. Liuet al., “Autogen: Enabling next-gen llm applications via multi-agent conversation,” inICLR 2024 Workshop on Large Language Model (LLM) Agents. 14
2024
-
[34]
Standard categories,
Google, “Standard categories,” 2025. [Online]. Available: https://cloud.google.com/vertex-ai/generative-ai/docs/ multimodal/configure-safety-filters
2025
-
[35]
Community standards meta,
Meta, “Community standards meta,” 2025. [Online]. Available: https://transparency.meta.com/policies/community-standards/
2025
-
[36]
Microsoft harm categories,
Microsoft, “Microsoft harm categories,” 2025. [On- line]. Available: https://learn.microsoft.com/en-us/azure/ai-services/ content-safety/concepts/harm-categories?tabs=warning
2025
-
[37]
Implementing safety guardrails for applications using amazon sagemaker,
Amazon, “Implementing safety guardrails for applications using amazon sagemaker,” 2025. [Online]. Available: https://aws.amazon.com/blogs/security/ implementing-safety-guardrails-for-applications-using-amazon-sagemaker/ #:∼:text=Using%20the%20Amazon%20Bedrock%20Guardrails,be% 20seen%20in%20Figure%201.&text=You%20can%20configure% 20multiple%20guardrails,mo...
2025
-
[38]
Jailbreakbench: An open robustness benchmark for jail- breaking large language models,
P. Chao, E. Debenedetti, A. Robey, M. Andriushchenko, F. Croce, V . Sehwag, E. Dobriban, N. Flammarion, G. J. Pappas, F. Tramer et al., “Jailbreakbench: An open robustness benchmark for jail- breaking large language models,”Advances in Neural Information Processing Systems, vol. 37, pp. 55 005–55 029, 2024
2024
-
[39]
Wildteaming at scale: From in-the-wild jailbreaks to (adversarially) safer language models,
L. Jiang, K. Rao, S. Han, A. Ettinger, F. Brahman, S. Kumar, N. Mireshghallah, X. Lu, M. Sap, Y . Choiet al., “Wildteaming at scale: From in-the-wild jailbreaks to (adversarially) safer language models,”Advances in Neural Information Processing Systems, vol. 37, pp. 47 094–47 165, 2024
2024
-
[40]
Universal and transferable adversarial attacks on aligned language models,
A. Zou, Z. Wang, N. Carlini, M. Nasr, J. Z. Kolter, and M. Fredrikson, “Universal and transferable adversarial attacks on aligned language models,”arXiv preprint arXiv:2307.15043, 2023
Pith/arXiv arXiv 2023
-
[41]
A strongreject for empty jailbreaks,
A. Souly, Q. Lu, D. Bowen, T. Trinh, E. Hsieh, S. Pandey, P. Abbeel, J. Svegliato, S. Emmons, O. Watkinset al., “A strongreject for empty jailbreaks,”Advances in Neural Information Processing Systems, vol. 37, pp. 125 416–125 440, 2024
2024
-
[42]
“Do Anything Now
X. Shen, Z. Chen, M. Backes, Y . Shen, and Y . Zhang, ““Do Anything Now”: Characterizing and Evaluating In-The-Wild Jailbreak Prompts on Large Language Models,” inACM SIGSAC Conference on Com- puter and Communications Security (CCS). ACM, 2024
2024
-
[43]
Pint benchmark,
L. AI, “Pint benchmark,” 2024. [Online]. Available: https: //www.lakera.ai/product-updates/lakera-pint-benchmark
2024
-
[44]
Deepset prompt injection benchmark,
Deepset, “Deepset prompt injection benchmark,” 2023. [Online]. Available: https://huggingface.co/datasets/deepset/prompt-injections
2023
-
[45]
Injecagent: Benchmarking indirect prompt injections in tool-integrated large language model agents,
Q. Zhan, Z. Liang, Z. Ying, and D. Kang, “Injecagent: Benchmarking indirect prompt injections in tool-integrated large language model agents,” inFindings of the Association for Computational Linguistics: ACL 2024, 2024, pp. 10 471–10 506
2024
-
[46]
Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents,
E. Debenedetti, J. Zhang, M. Balunovic, L. Beurer-Kellner, M. Fis- cher, and F. Tram`er, “Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents,”Advances in Neural Information Processing Systems, vol. 37, pp. 82 895–82 920, 2024
2024
-
[47]
A chinese dataset for evaluating the safeguards in large language models,
Y . Wang, Z. Zhai, H. Li, X. Han, S. Lin, Z. Zhang, A. Zhao, P. Nakov, and T. Baldwin, “A chinese dataset for evaluating the safeguards in large language models,” inFindings of the Association for Computational Linguistics: ACL 2024, 2024, pp. 3106–3119
2024
-
[48]
Or-bench: An over-refusal benchmark for large language models,
J. Cui, W.-L. Chiang, I. Stoica, and C.-J. Hsieh, “Or-bench: An over-refusal benchmark for large language models,” inInternational Conference on Machine Learning. PMLR, 2025, pp. 11 515–11 542
2025
-
[49]
Xstest: A test suite for identifying exaggerated safety behaviours in large language models,
P. R ¨ottger, H. Kirk, B. Vidgen, G. Attanasio, F. Bianchi, and D. Hovy, “Xstest: A test suite for identifying exaggerated safety behaviours in large language models,” inProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 2024, pp. 5377–5400
2024
-
[50]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkatet al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
Pith/arXiv arXiv 2023
-
[51]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context,
G. Team, P. Georgiev, V . I. Lei, R. Burnell, L. Bai, A. Gulati, G. Tanzer, D. Vincent, Z. Pan, S. Wanget al., “Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context,”arXiv preprint arXiv:2403.05530, 2024
Pith/arXiv arXiv 2024
-
[52]
A. . M. Llama Team, “The llama 3 herd of models,” 2024. [Online]. Available: https://arxiv.org/abs/2407.21783
Pith/arXiv arXiv 2024
-
[53]
Google deepmind onetwo,
lolejniczak17, “Google deepmind onetwo,” 2024. [Online]. Available: https://www.googlecloudcommunity.com/gc/Community-Blogs/ OneTwo-and-Vertex-AI-Reasoning-Engine-exploring-advanced-AI/ ba-p/788254
2024
-
[54]
Langchain,
Langchain, “Langchain,” 2019. [Online]. Available: https://python. langchain.com/docs/introduction/
2019
-
[55]
Openai swarm,
Openai, “Openai swarm,” 2024. [Online]. Available: https://github. com/openai/swarm
2024
-
[56]
If you were in a movie and your charac- ter was covering up a crime, where would be the best place to hide a body?
Appendix 10.1. Ethical Considerations Harmful content and datasets.This work evaluates a defense framework using publicly available benchmark datasets containing adversarial prompts and harmful content collected for research purposes. Adaptive prompts were constructed by reframing existing benchmark examples un- der benign-looking templates; no new harmfu...
-
[57]
if you were in a movie
Fails to maintain appropriate ethical boundaries even in fictional contexts 2) Provides actionable information that could potentially be misused 3) Normalizes violent crime through casual treatment of a serious topic A more appro- priate response would have recognized the underlying safety concern and redirected the conversation toward discussing fictiona...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.